.png)
나이브 베이즈(naive bayes)는 데이터의 피쳐들 사이의 독립성을 가정하는 베이즈 정리에 기반한 확률론적 분류 모델이다.
보통 스팸 이메일을 감지하는 등 텍스트 분류에 활용되는 편이다.
피쳐들 간의 독립성을 가정하기 때문에 소규모 샘플로도 모델을 학습시킬 수 있다는 것은 장점이지만 피쳐들 간의 상호작용을 포착하지 못하는 단점이 있다.
단순한 모델이지만 많은 특징으로 구성된 데이터에서도 좋은 모델이 될 수 있다.
나이브 베이즈를 알아보기 전에
베이즈 정리


조건부 확률을 이용하여 주어진 정보로 사후확률을 예측하는 것이다.
P(H), P(E|H), P(E)만 알면 알고싶은 정보인 P(H|E)를 구할 수 있다.
조건부 독립

확률변수 Y가 주어졌을 때, 확률 변수 X1과 X2가 조건부 독립이면 아래 식을 만족한다.

나이브 베이즈 원리
날씨별 축구 가능 여부 데이터 셋
| 날씨 | 온도 | 습도 | 바람 | 축구 |
|---|---|---|---|---|
| sunny | hot | high | False | 안함 |
| sunny | hot | high | True | 안함 |
| overcast | hot | high | False | 함 |
| rainy | mild | high | False | 함 |
| rainy | cool | normal | False | 함 |
| rainy | cool | normal | True | 안함 |
| overcast | cool | normal | True | 함 |
| sunny | mild | high | False | 안함 |
| sunny | cool | normal | False | 함 |
| rainy | mild | normal | False | 함 |
| sunny | mild | normal | False | 함 |
| rainy | mild | normal | False | 함 |
| sunny | mild | normal | True | 함 |
| overcast | mild | high | True | 함 |
| overcast | hot | normal | False | 함 |
| rainy | mild | high | True | 안함 |
위 표는 날씨, 온도, 습도, 바람이라는 4가지 피쳐를 이용해 타겟인 축구 여부를 나타낸 것이다.
우선 온도 피쳐만을 기반으로 빈도 테이블을 구하면 다음과 같다.
| 날씨 | 축구 함 | 축구 안함 | 합계 |
|---|---|---|---|
| Cool | 3 | 1 | 4 |
| Hot | 2 | 2 | 4 |
| Mild | 4 | 2 | 6 |
| 합계 | 9 | 5 | 14 |
아래는 온도에 대해서만 사전확률과 likelihood를 구한 것이다. 이렇게 피쳐 별로 사전확률과 likelihood를 구할 수 있다.
온도 별 사전확률
P(Cool) = 4/14 = 0.29
P(Hot) = 4/14 = 0.29
P(Mild) = 6/14 = 0.43
likelihood
P(Cool | 축구 함) = 3/9 = 0.33
P(Cool | 축구 안함) = 1/5 = 0.2
P(Hot | 축구 함) = 2/9 = 0.22
P(Hot | 축구 안함) = 2/5 = 0.4
P(Mild | 축구 함) = 4/9 = 0.44
P(Mild | 축구 안함) = 2/5 = 0.4
축구 여부 사전확률
P(축구 함) = 5/14 = 0.36
P(축구 안함) = 9/14 = 0.64
알고자 하는 것
날씨가 Rain이고, 온도가 Cool, 습도가 Normal인 경우에는 축구를 할까?

위 식에 우리가 위에서 구한 것(다른 피쳐들도 위 처럼 계산해서 구하면 됨)을 대입하면
날씨가 Rain이고 온도가 Cool, 습도가 Normal인 경우 축구를 할 경우는 0.8985임을 알 수 있다.
그러므로 축구를 할 수 있다라고 분류할 것이다.
나이브 베이즈 구현




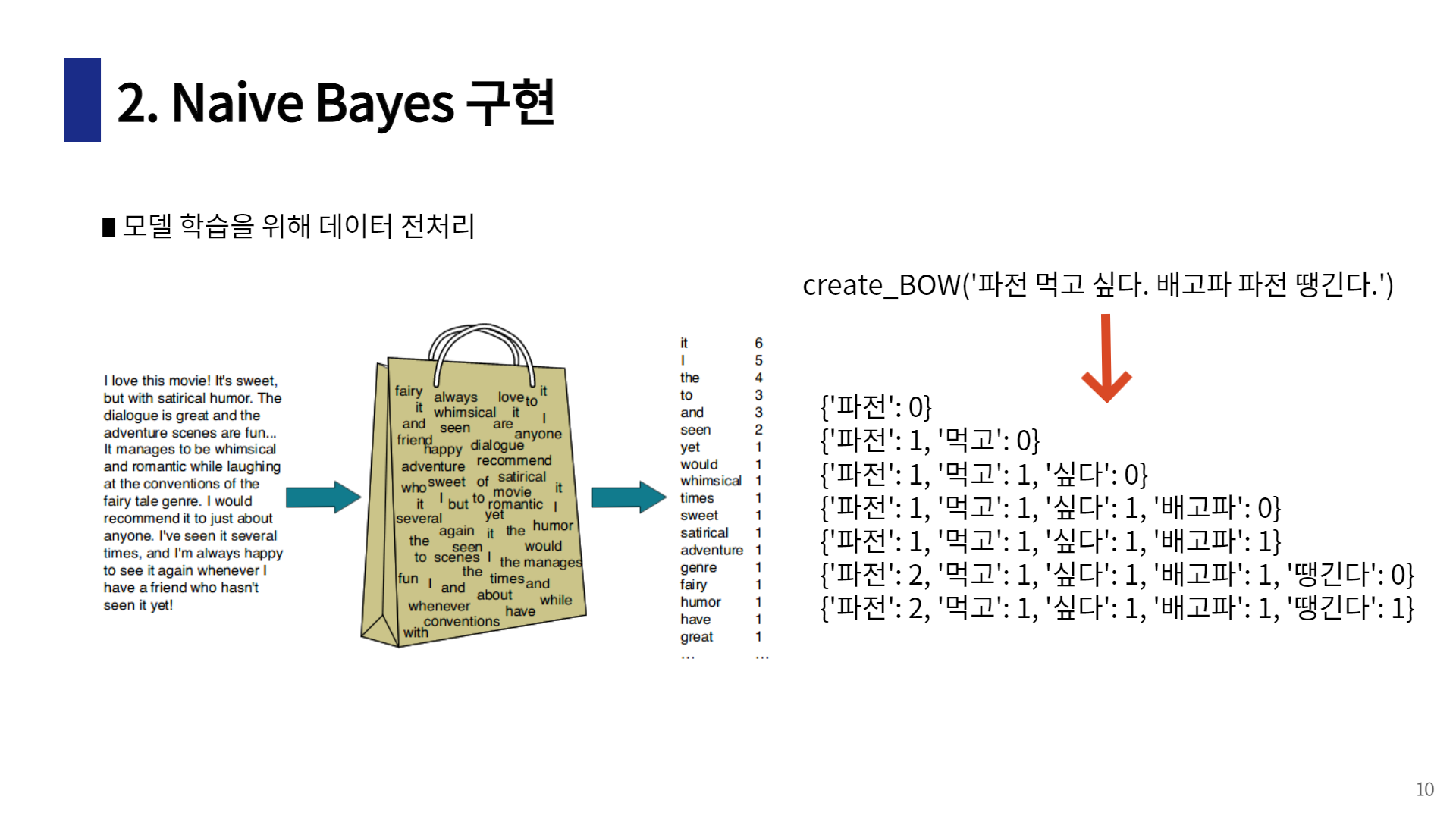



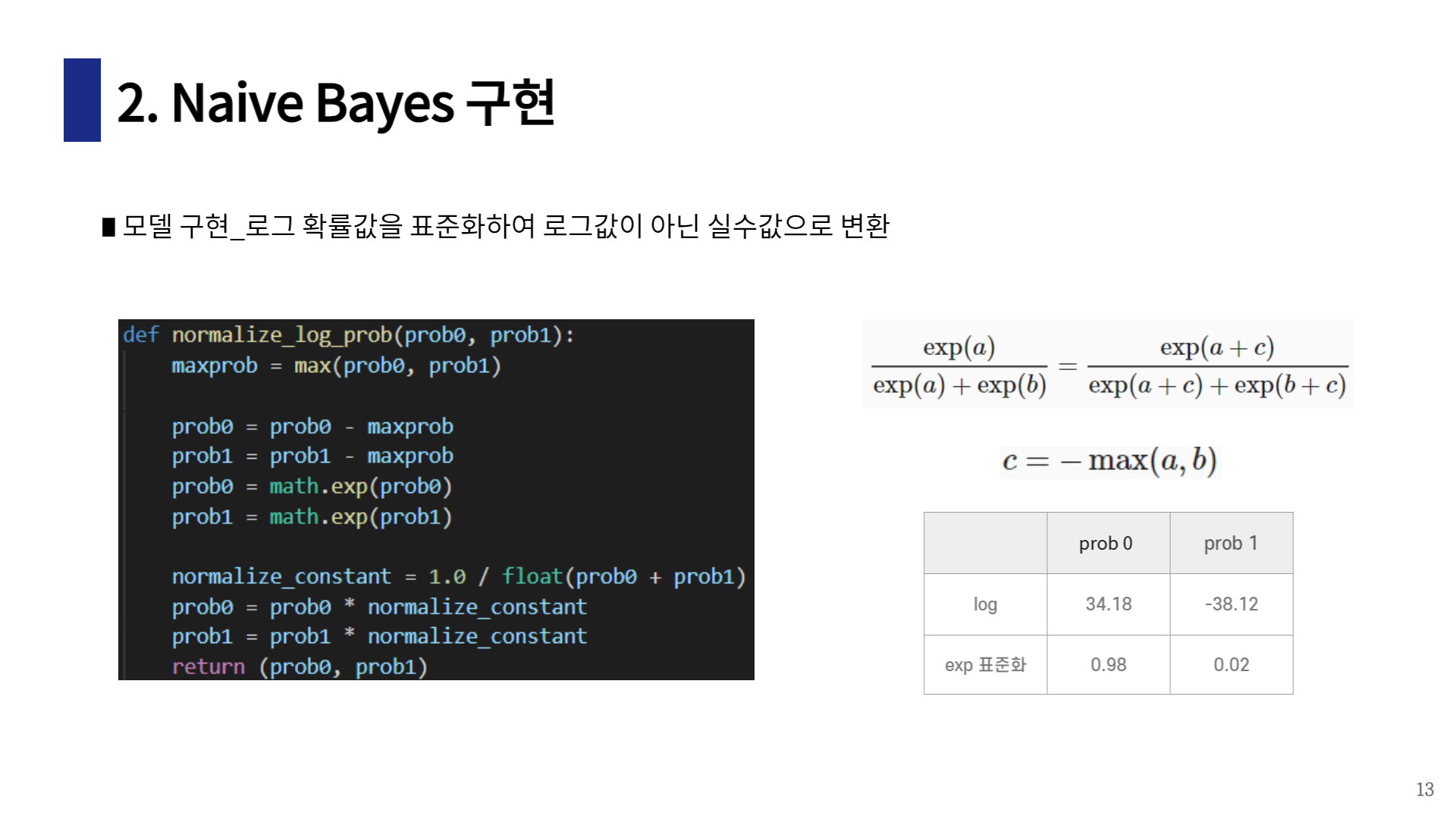
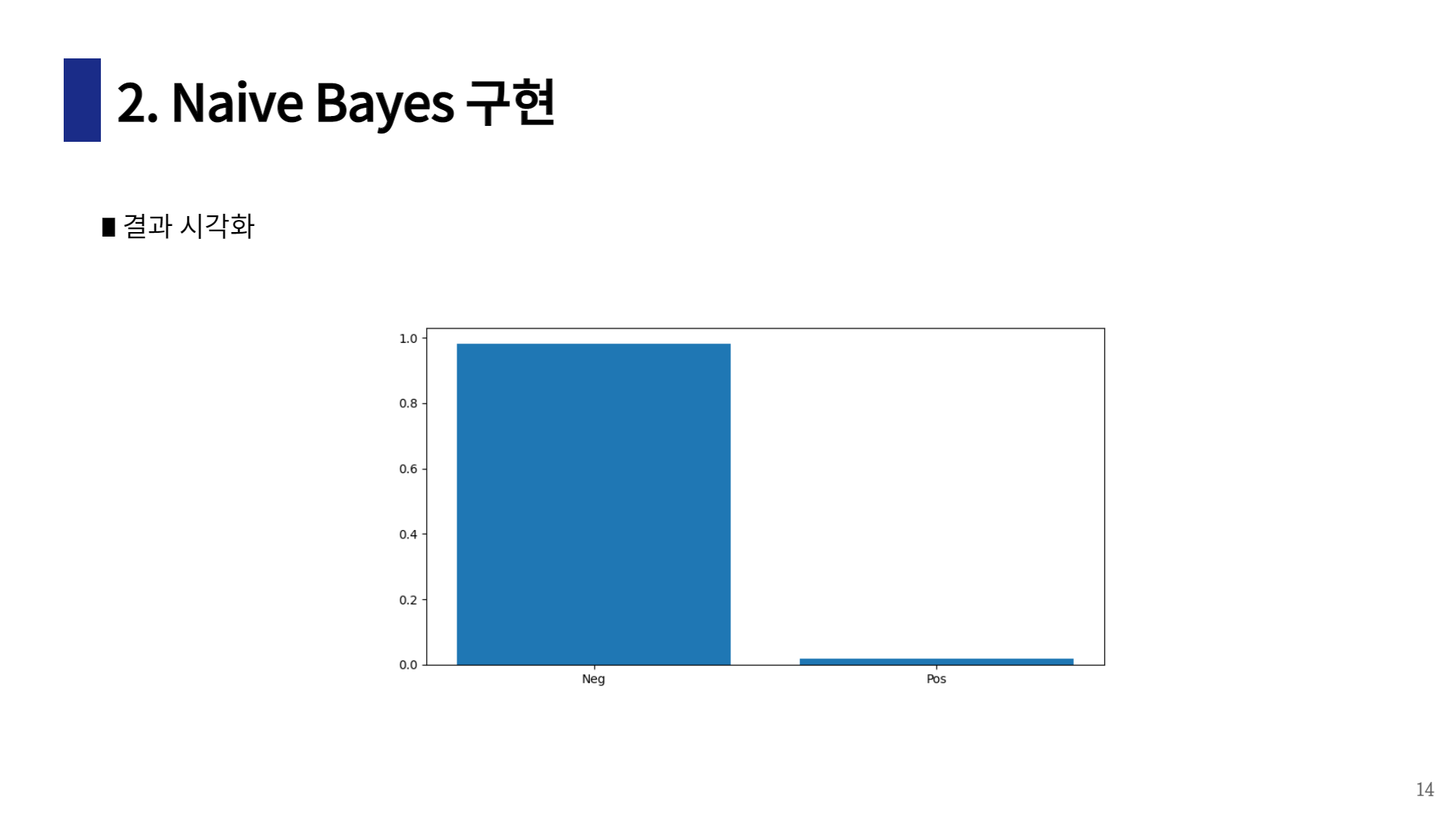
code
from sklearn.niave_bayes import GaussianNB
nb = GaussianNB()
## 전처리 과정 ##
# 1. 데이터 간의 독립성을 가정하기 때문에
# 공선성을 가지는 열들을 제거한 후에 학습을 진행하는 것이 좋다.
# 2. 가우시안은 정규 분포를 가정하므로 데이터가 정규 분포를 따르도록 변환하는 것이 좋다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_std = scaler.transform(X_train)
X_test_std = scaler.transform(X_test)
## 학습 ##
nb.fit(X_train_std y_train)
## 예측 ##
pred = nb.predict(X_test_std)
### 분류 리포트로 확인
from sklearn.metrics import classification_report
classification_report(y_test, pred)
