.png)
로지스틱 회귀 모델은 선형 회귀(Linear Regression)처럼 input의 w(가중치)를 계산하지만 바로 결과를 출력하는 것이 아니라 결과값의 logistic을 출력하기 때문에 분류 문제에 이용된다.
로지스틱 회귀 식을 벡터 표현식으로 나타내면 아래와 같다.
여기서 σ는 Sigmoid 함수이다.
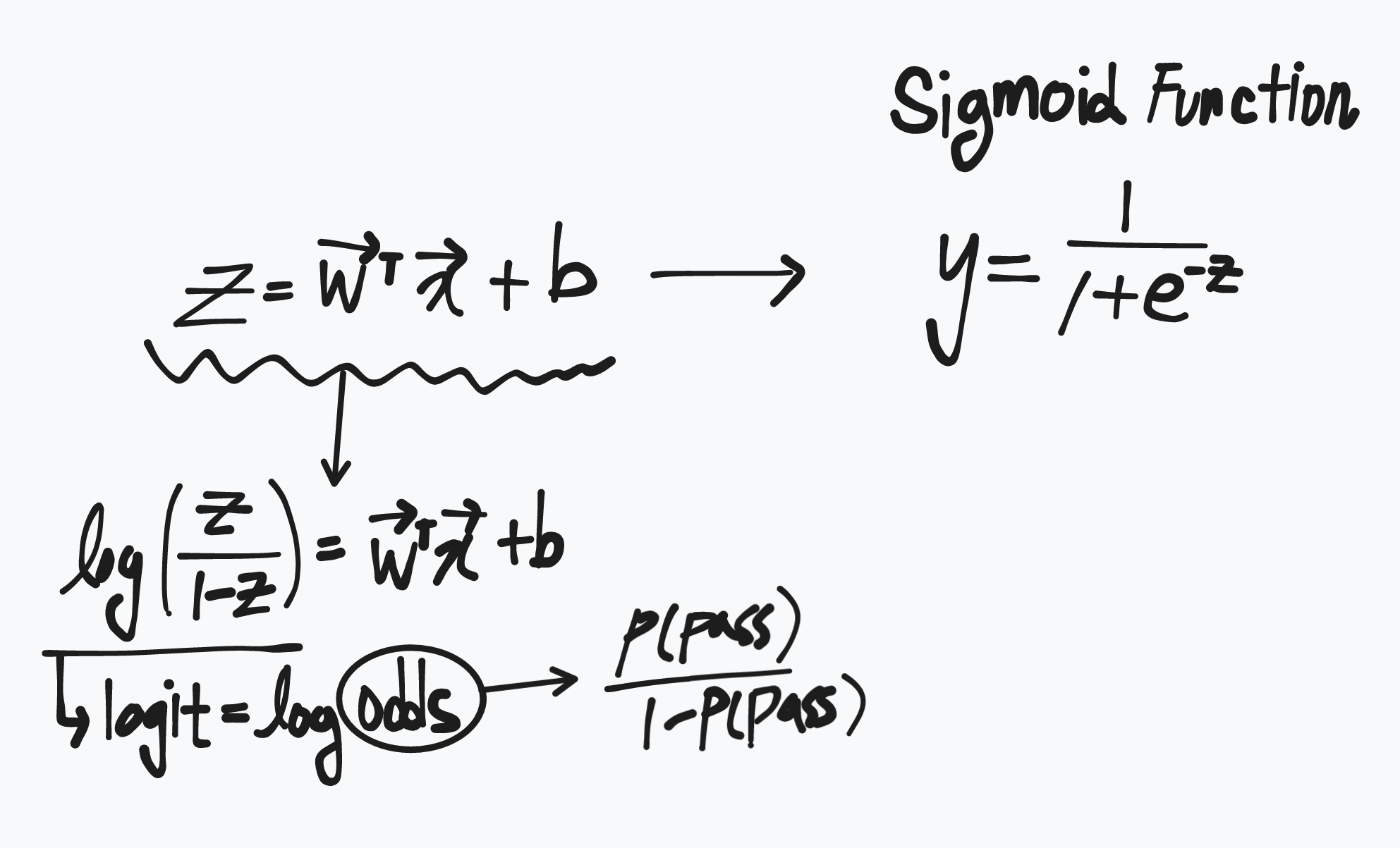
로지스틱 회귀모델의 종속변수 y가 0 또는 1을 갖기에, 단순 선형 함수 y=wx+b로는 풀기가 힘들다.(input이 커지면 output의 해석이 어렵기 때문이다).
확률 p의 범위는 [0,1],
Odds(p)의 범위는 [0,∞],
log(Odds(p))는 [−∞,∞]가 되어,
log(Odds(p))=wx+b과 같은 형태로는 선형분석이 가능하다.
즉, Sigmoid 함수에 넣기 전 선형 식은 logit 형태로 변형이 가능하다.
그리고 Sigmoid 함수는 logit 함수의 역함수이기때문에 input으로 logit이 들어간다면 output으로 Probability를 출력하게 된다.
.png)
출력 probability가 0.5보다 크면 1, 작으면 0으로 결과 예측을 한다.
코드
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression() # 인자에 penalty='l2'를 넣어 L2 제약식을 적용할 수 있다.
LR.fit(X_train, y_train)
# 로지스틱 회귀 모델 계수 및 절편 확인
print(LR.coef_)
print(LR.intercept_)
# 예측
pred = LR.predict(X_test)
print(pred)
>>> [0 1 0 1]
# 클래스 확률로 예측
pred_proba = LR.predict_proba(X_test)
print(pred_proba)
>>> [[0.97 0.03]
[0.24 0.76]
[0.94 0.06]
[0.44 0.56]]
# 정밀도 평가
from sklearn.metrics import precision_score
precision_score(y_test, pred)
>>> 0.9666
# confusion matrix 확인
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, pred)
>>> [[50 3]
[3 87]]
# 분류 리포트 확인
from sklearn.metrics import classification_report
classification_report(y_test, pred)import numpy as np
def inv_logit(p):
return np.exp(p) / (1+ np.exp(p))
# 칼럼 명, 계수 , 계수의 역 logit값
cols = X_train.columns
for col, val in sorted(zip(cols, lr.coef_[0]), key=lambda x: x[1], reverse=True):
print(f"{col:10}{val:10.3f} {inv_logit(val):10.3f}")Embarked_Q 0.040 0.510
Embarked_S -0.429 0.394
Age -0.480 0.382
Pclass -1.218 0.228
Sex_male -2.465 0.078
계수의 역 logit을 구하면 1(생존)에 대한 비율을 확인할 수 있다.
Embarked_Q 이면 생존 확률이 높고
Sex_male이면 생존 확률이 낮아짐을 알 수 있다.
