Title : IBOT : Image BERT Pre-Training with Online Tokenizer
Date : 22 Jan 2022
Keywords : Self-Supervised, Vision Transformer, BERT, Tokenizer, DINO
Abstract/Intro
본 논문은 BERT, BEIT, DINO 논문들에서 나오는 내용을 모두 알고 읽으시는게 이해가 쉬울 것 같습니다. 위 논문들의 링크입니다.
BERT | BEIT | DINO
BERT에서 사용되었던 MLM을 최근 Computer Vision에 적용하기 위한 연구들이 있다. DALL-E tokenizer를 사용해서 Image를 Token으로 만들었던 BEIT가 대표적이다. 본 논문은 BEiT의 Tokenizer를 사전에 학습해서 사용하는 Multi-stage training 방식에서 벗어나 Tokenizer를 target model과 함께 훈련시키는 online tokenizer 방식을 제시한다. Online Tokenizer를 학습하기 위해서 DINO에서 사용했던 Self-Distillation 방식을 채택했다.
Masked Language Model(이하 MLM)은 BERT에서 사용했던 사전학습 방식으로, 입력값의 일부에 마스킹을 적용한뒤 이를 최종 출력에서 예측한다. Computer Vision 분야에서도 ViT의 등장과 함께 MLM을 이미지 인식모델 사전학습에 사용하려고 했지만 MLM에서 필수인 Tokenizer의 부재로 사용에 어려움이 있었다. 최근 논문인 BEiT에서는 DALL-E pre-trained Tokenzier로 이미지를 토큰화해서 이를 해결했다.
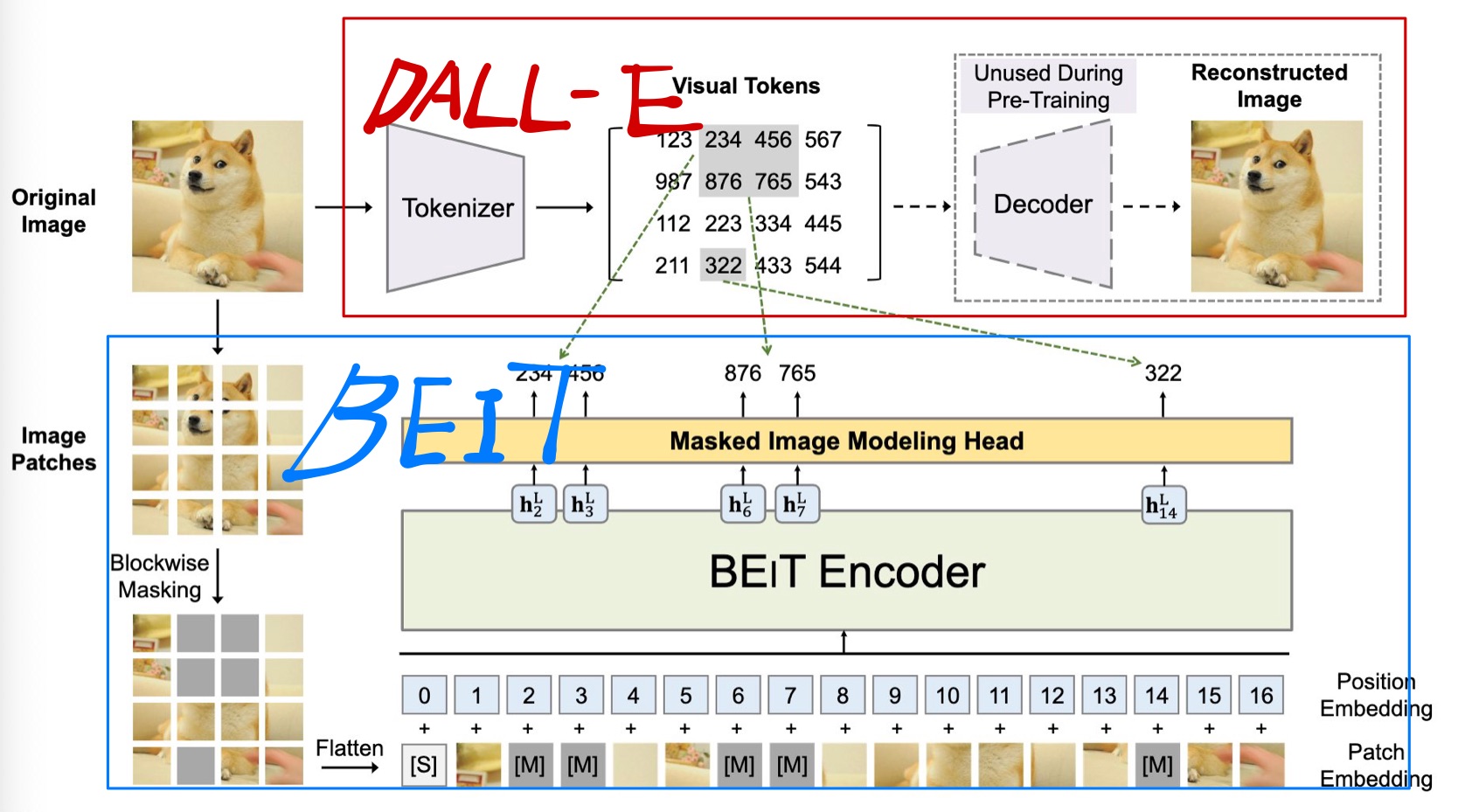
BEiT의 학습 순서는 다음과 같다.
1. 이미지를 사전에 학습된 DALL-E Tokenizer를 이용해서 토큰화
2. 이미지 패치의 일부에 마스킹을 적용
3. 모델이 마스킹된 패치의 token값을 예측 하도록 학습(MIM Head에서 예측)
4. Downstream task로 fine-tune
BEiT는 결국 DALL-E Tokenizer의 결과를 학습하는 것이기 때문에 DALL-E의 지식을 target 모델에 Distillation한다고 봐도 될것 같다.
IBOT에서 지적한 부분은 1번의 사전 학습된 토크나이저를 사용한 것이다. 토크나이저를 학습하기 위한 데이터가 추가로 필요하고, end to end 방식이 아닌 토크나이저 학습 - target 모델 학습 이라는 mulit-stage 방식으로 학습을 해야한다는 것이다.
본 논문에서 Tokenizer는 이미지의 semantic 정보를 잘 추출할 수 있어야하고, target 모델의 목표또한 이미지의 semantic 정보 추출에 있기 때문에 이 둘을 동시에 학습할 수 있다고 가정하고 IBOT 모델을 실험했다.
BEiT의 한계점이었던 사전에 학습된 Tokenizer를 사용했다는 부분을 DINO의 Self-Distillatio으로 해결했다. BEiT + DINO = IBOT
Preliminaries
Masked Image Modeling as Knowledge Distillation
BEiT에서는 DALL-E의 tokenizer를 사용해서 MIM을 구현했습니다. BEiT는 아래의 수식을 최소화합니다.
은 사전에 정의된 K(논문에선 8192) 차원의 확률 분포를 나타내며 는 마스킹 여부, 는 각각 원본 이미지, 마스킹된 이미지를 나타냅니다. 위 식을 살펴보면 사전 확률분포(DALL-E tokenizer) 와 모델의 출력인 가 서로 비슷해 지도록 합니다. DALL-E tokenizer는 사전 학습되어 있으며 모델의 학습 동안 파라미터가 바뀌지 않기 때문에 BEiT는 DALL-E tokenizer의 지식을 모델에 증류하는 것으로 볼 수 있습니다.
Self-Distillation
DINO 논문에서 제시된 자가 증류는 사전에 학습된 모델 가 아닌 모델의 전 iteration인 의 지식을 증류한다. Training Set 에서 랜덤하게 추출된 이미지 를 서로 다른 Augmentation을 적용해서 를 생성하고 각각 teacher, student 모델의 입력값으로 사용한다. 아래의 식으로 지식 증류가 일어난다.
[CLS]는 CLS토큰을 의미한다. Teacher, student 모델은 동일한 backbone을 사용한다. Student 모델은 위 식을 통해서 업데이트 되고 teacher 모델은 Student 모델의 파라미터를 이용해서 Exponential Moving Average로 업데이트 된다.
DINO 논문에서 Teacher에는 원본 이미지를 Global crop한 입력값을, student에는 local crop한 입력값을 사용한다.
Student는 이미지의 일부분만 보기 때문에 이를 마스킹된 이미지라고 해석할 수 있다고 생각한다. Student는 이미지의 일부만 보고 이미지 전체를 본 Teacher와 비슷한 CLS를 출력할 수 있게 학습되는 것이다.
Methodology
본 논문에서 제시하는 IBOT은 DALL-E Tokenzier와 같이 사전에 학습된 tokenizer를 사용하는 것이 아닌 self-distillation을 적용한 online tokenzier를 Target 모델과 함께 학습하는 MIM 모델을 제시합니다.
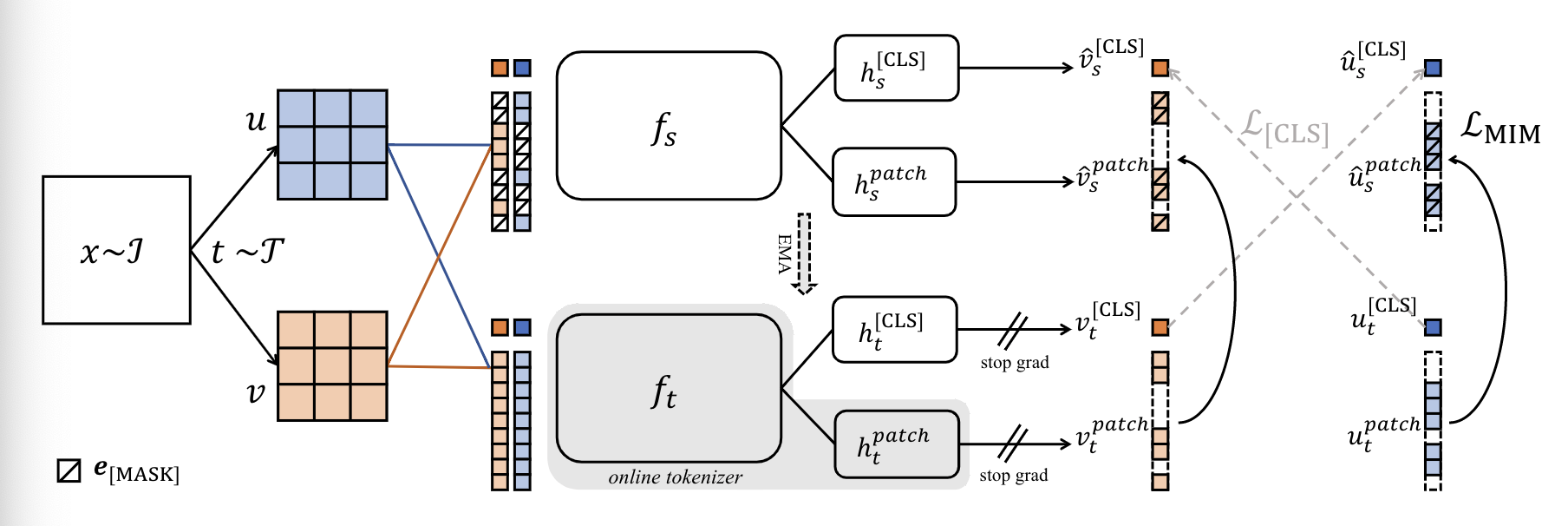
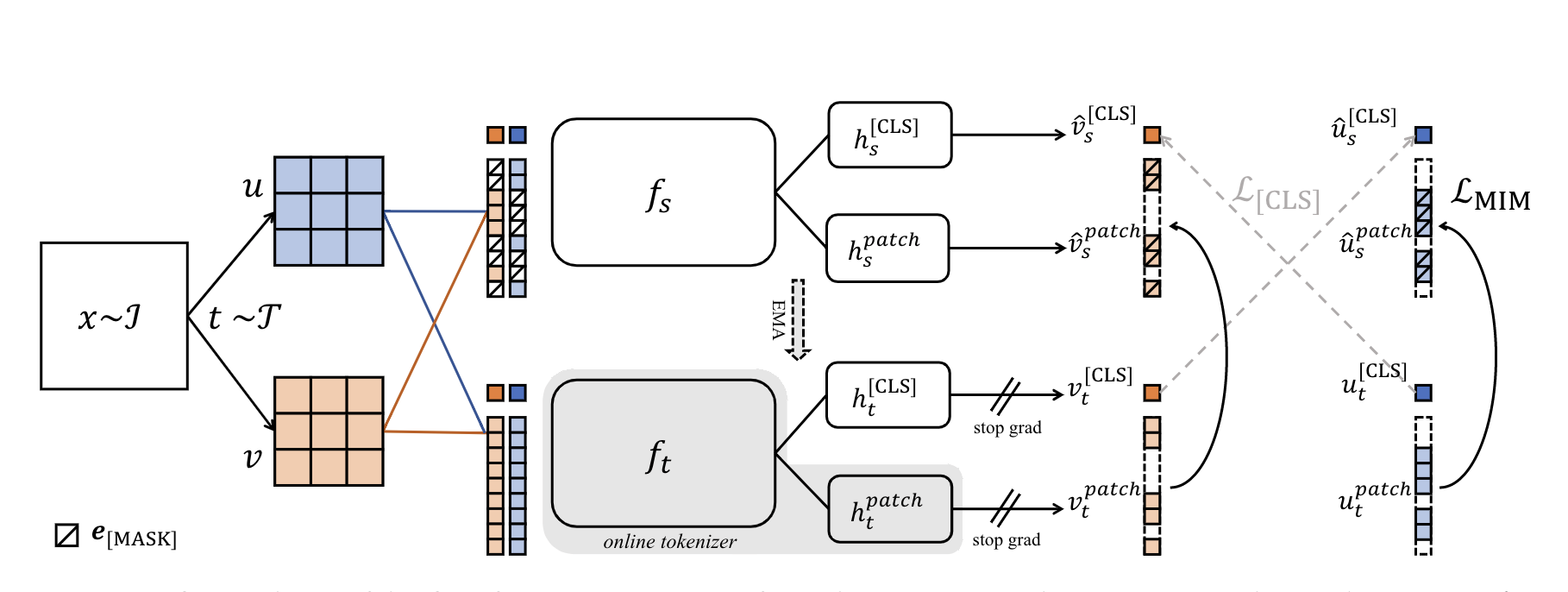
위 그림에서 볼 수 있듯이 DINO와 마찬가지로 같은 원본 이미지를 2개의 서로다른 Augmentation을 적용합니다(). 에 서로 다른 blockwise masking(BEiT 방법)을 적용한 를 student의 입력값으로, 를 teacher의 입력값으로 사용합니다.
Student와 Teacher는 각각 head를 통해서 CLS토큰과 Patch토큰을 예측하게 됩니다. Student의 경우 마스킹을 적용 되었기 때문에 마스킹된 부분의 Patch토큰을 예측하게 되고 Teacher는 마스킹 없이 예측합니다. BEiT에서 DALL-E Tokenizer가 했던 역할을 그대로 Teacher가 수행합니다. Teacher와 Student의 Patch 예측값을 비교해서 첫번째 로스인 이 나옵니다. 이는 아래와 같습니다.
IBOT에서는 tokenizer를 더 semantically-meaningful(본문 인용)하게 만들기 위해서 DINO에서처럼 CLS 토큰을 이용한 자가 증류를 합니다. 이를 수식으로 나타내면 아래와 같습니다.
위 식은 2개의 패치이미지 쌍을 사용했다는 점을 제외하면 DINO와 완전히 동일합니다.
CLS 토큰과 Patch 토큰 예측에는 같은 head를 사용하며, BEiT에서 토큰 임베딩 차원으로 사용한 8192를 그대로 사용했습니다.
DINO에서는 6만 정도의 큰 차원으로 CLS토큰을 임베딩 시켰습니다.
또한 BEiT에서는 One-hot 인코딩된 토큰을 사용했지만 본 논문에서는 softmax값을 그대로 사용했습니다. 이는 이미지 패치가 문장의 단어와는 다르게 매우 애매한 semantic meaning을 가지고 있기 때문이라고 설명합니다.
DINO에서도 temparature가 적용된 Softmax값을 사용했습니다.
추가적으로 실험에서 사용한 setting은 DINO의 그것과 거의 유사합니다. ViT, SwinTransformer를 기본 모델로 사용했으며, CLS와 패치 projection head는 3개의 MLP를 사용했으며, 모델이 자명한 답을 내지 않게 하기 위해서 L2 정규화를 MLP블락의 bottleneck에 적용했습니다.
정리
1. DINO와 마찬가지로 2개의 서로다른 Augmentation이 적용된 이미지를 준비한다. ->
2. 각 이미지에 blockwise 마스킹을 적용한다. ->
3. Teacher에는 를 Student에는 를 입력값으로 사용한다.
4. Student가 예측한 마스킹된 패치의 값과 Teacher가 예측한 패치의 값을 크로스 엔트로피를 적용해서 Teacher -> Student로 지식을증류한다.
5. 서로 다른 이미지의 CLS 토큰값을 이용해서 Semantic meaning을 증류한다.
6. CLS토큰과 패치 예측은 같은 head를 사용한다.
Experiment/Result
Result
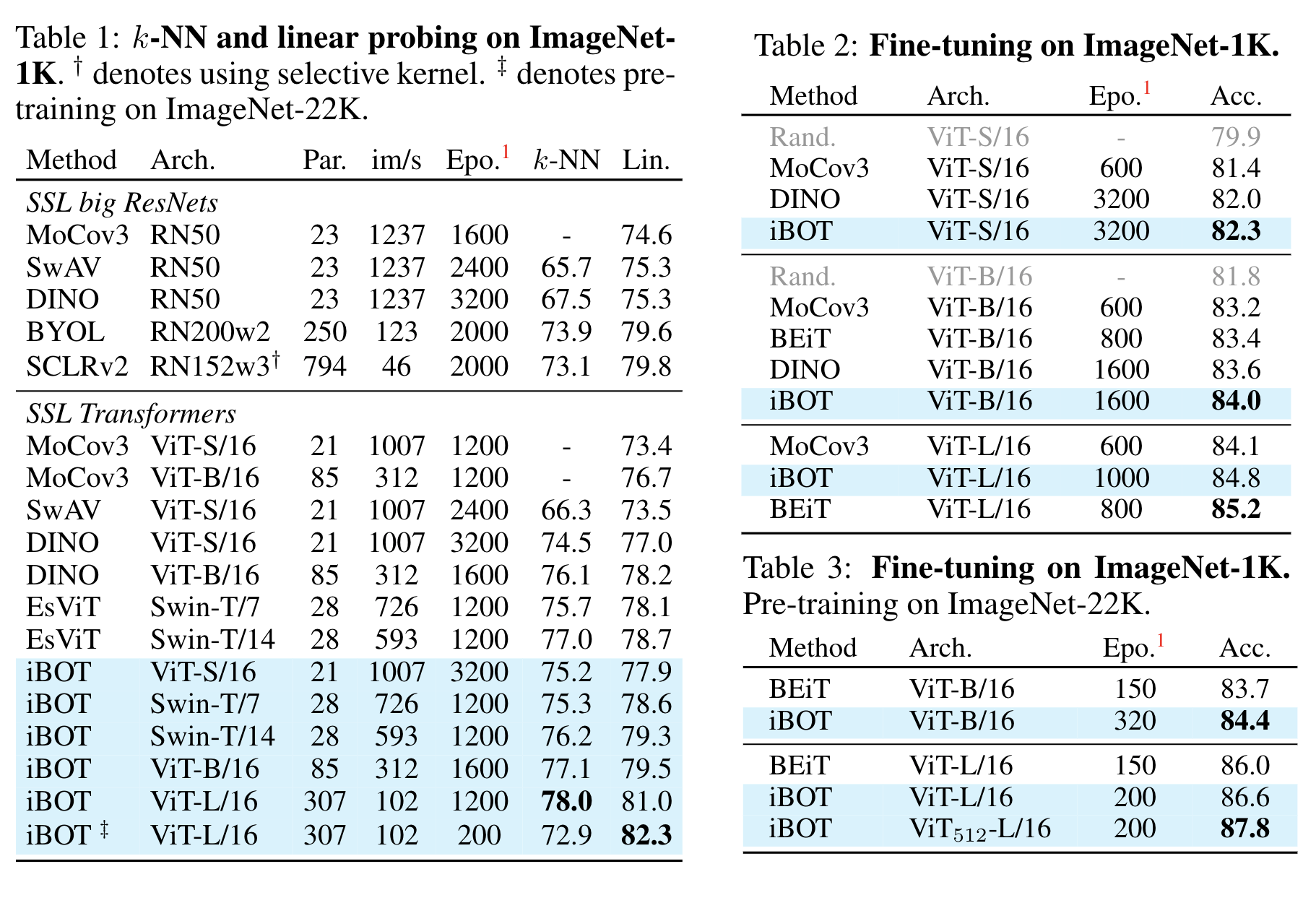
평가방식은 DINO에서 사용했던 방식인 KNN, Linear Probing, Fine-tuning 을 사용했습니다.
결과를 보면 알 수 있듯이 대부분의 경우 이전 SOTA였던 DINO, EsViT에 비해서 높은 성능을 내고 있습니다. 특히 ImageNet 1k 훈련을 시켰을 때 kNN성능이 뛰어난것을 확인할 수 있습니다.
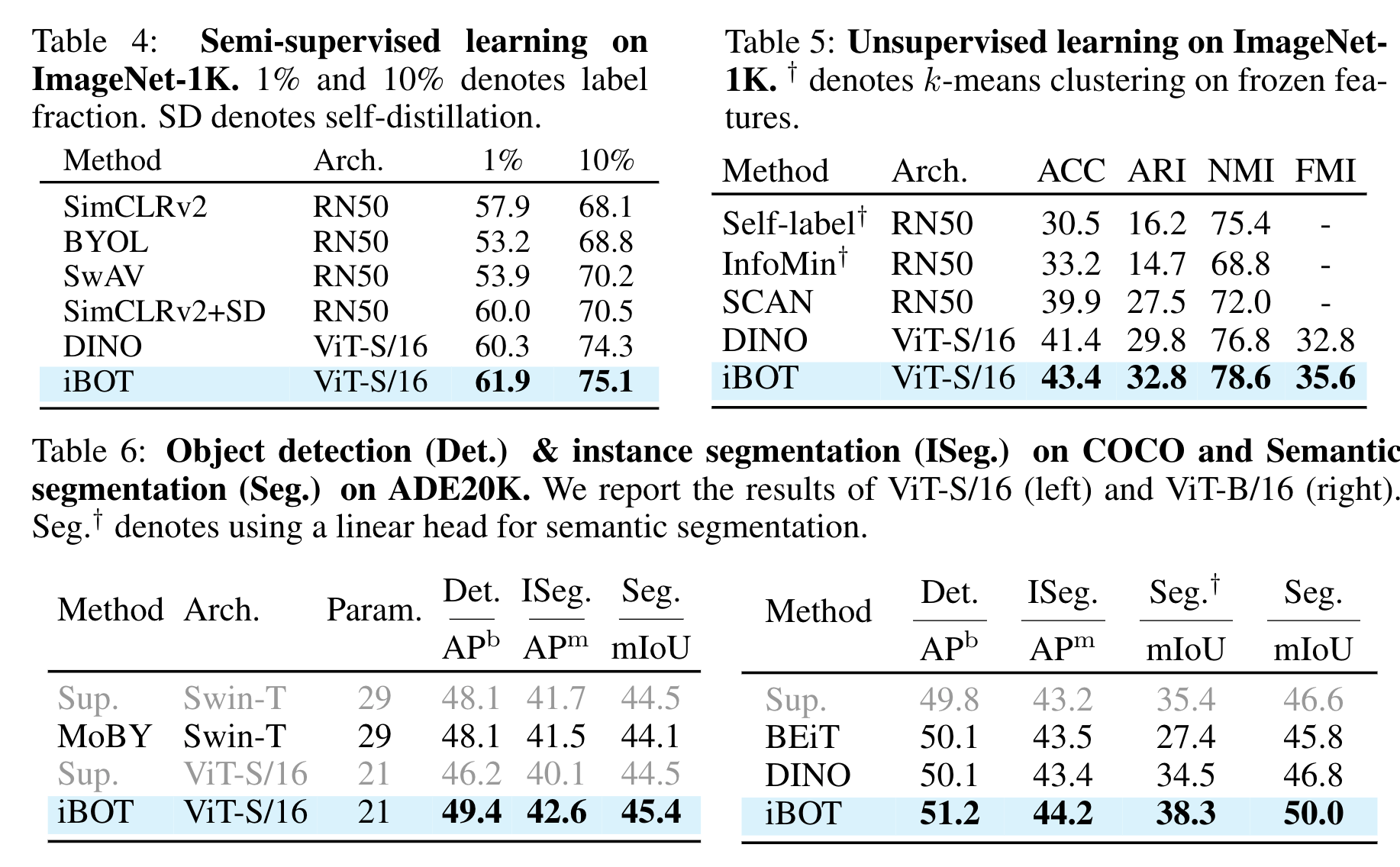
추가적으로 Semi-supervised learning, Unsupervised learning, Object detection, Semantic segmentation 등에서도 기존의 자가지도 학습방식 모델들보다 높은 성능을 보이고 있습니다.
Pattern layout

본 논문에서는 자가 증류를 통해서 MIM이 무엇을 학습하는지 밝히기 위해서 ImageNet 1k validation set에서 가장 높은 신뢰도(??)를 가진 패치들을 시각화 했습니다. 위 이미지에서 확인 할 수 있듯이 자동차의 헤드라이트, 동물의 귀, 사람의 머리처럼 특정 군집으로 묶을 수 있었습니다. 논문에서는 MIM을 통해서 high-level semantic meaning과 low-level detail을 모두 포착했다고 설명했습니다.
MIM & Recognition
본 논문에서는 MIM이 이미지 인식을 어떻게 향상시키는지 밝히고자 2가지 실험을 했습니다. 첫번째는 CLS 토큰을 이용한 linear classfication이고, 두번째는 k 개의 높은 self-attention을 가지는 패치들을 선택해서 평균내서 linear classification을 하는 것입니다.
첫번째 실험에서는 DINO와 IBOT의 성능이 77.9% v.s. 77.0%로 DINO가 소폭 앞섰습니다. 하지만 두번째 실험 즉, 패치 representation을 직접적으로 사용했을 경우에는 IBOT이 더 높은 성능이 나왔습니다. 아래 그림 참고
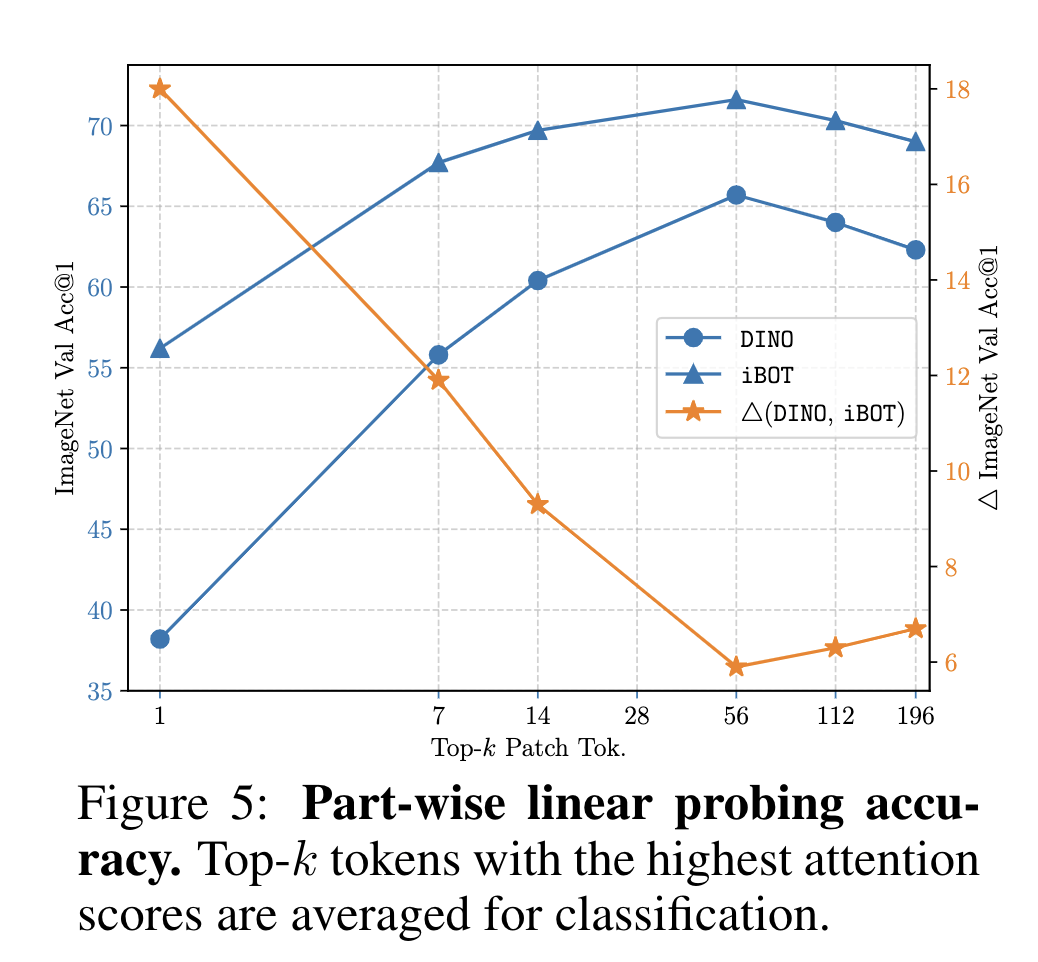
논문에서는 IBOT이 MIM을 통해서 각 패치들이 더 풍부한 Semantic information을 가지고 있기 때문에 가능하다고 설명했습니다.
Conclusion
본 논문에서 제시하는 IBOT은 이미지에서 BERT 방식의 학습을 하기위해서 필요했던 Image Tokenzier를 사전에 학습하지 않고 자가 증류를 이용해서 online으로 학습하는 방법을 제시했습니다. BEiT에서 부족하다고 평가받았던 pre-trained tokenizer 사용을 DINO의 자가 증류를 통해서 해결했다는 기여점이 있는 것 같습니다.

우와..