Title : BEIT : Pre-Training of Image Transformer
Date : 15 Jun 2021
Keywords : Autoencoder,Self-Supervsied, Vision Transformer, BERT, Tokenize
저는 NLP에 대한 지식이 거의 없기 때문에 본 논문에서 나오는 NLP에서 자주 사용하는 단어의 뜻을 잘 못 이해하고 있을 수 있습니다. 따끔한 지적해주시면 감사하겠습니다.
Abstract/Intro
본 논문은 NLP분야에서 가장 큰 영향력을 미쳤다고 평가받는 BERT의 훈련방식인 Masked language modeling을 이미지 모델에 적용했습니다. 기존의 이미지 모델들이 BERT의 훈련방식을 채택할 수 없었던 이유는 크게 두가지라고 밝힙니다.
1.NLP와 다르게 이미지는 사전에 정의된 사전이 존재하지 않아서 token화 시키기 어렵다
2.토큰을 쓰지 않고 픽셀 수준의 예측을 할 순 있지만 그렇게 되면 모델이 사전학습에서 short-range dependencies와 high-frequencey details만 학습할 수 있다.
본 논문에서 밝히진 않았지만 추가적으로 NLP와 Vision에서 주로 사용하는 기본 모델이 Transformer VS CNN 으로 달랐기 때문에 BERT와 같은 방식으로 학습하기 어려웠을 것으로 생각하고 있습니다.
본 논문에서는 OpenAI에서 발표한 논문에서 공개된 사전학습된 DALL-E tokenizer를 이용해서 이미지 패치들을 tokenizer 해서 위 두 문제들을 해결하고 BERT방식으로 모델을 훈련했습니다. 결과는 본 논문 이전까지 나왔던 대부분의 지도학습 및 비지도학습 기반 ViT 관련 논문에 비해서 성능이 좋았습니다.
BERT에서 영감을 받았다는 사실을 논문에서도 여러번 언급하고 이와 같은 학습 방식도 BERT의 Masked Language Modeling(MLM)의 이름을 모방하여 Masked Image Modeling(MIM)이라고 지었습니다.
위 설명에서도 알 수 있듯이 Tokenizer는 DALL-E에서 공개한것을 사용했고, 훈련방식은 BERT와 완전히 동일합니다. 전에 없던 새로운 방법론을 제시한건 아니지만 Masked Image를 사용해서 ViT를 사전훈련했을 때 높은 성능이 나온다는 것을 확인할 수 있다는 기여점이 있는 것 같습니다.
Method
Backbone/Image Patch
BEIT는 이미지를 ViT의 논문에서 제시했던 16x16패치로 이미지를 일정하게 나누는 방식을 사용했습니다. 개별 패치들은 flatten과 linear projection 과정을 거치고 Position embedding이 더해져서 최종 입력값이 됩니다. Backbone network도 ViT논문에서 제시했던 ViT모델을 변경없이 그대로 사용했습니다.
Visual Token
본 논문에서는 이미지 모델을 훈련하는데 BERT의 학습 방식인 Masked modeling을 적용했습니다. BERT는 문장의 단어들을 token화 하고 이중 일부를 masking해서 지웠습니다. Masking되지 않은 토큰과 masking된 토큰을 모델의 입력값으로 사용하고 masking된 토큰을 예측하면서 문장을 전체적으로 이해하는 학습방식 입니다.
BEIT에서 첫번째로 지적한 문제점이 여기서 발생합니다. NLP에서는 사전에 정의된 tokenizer를 이용해서 단어들을 토큰으로 만들 수 있지만 이미지의 경우 사전에 정의된 tokenizer가 없었기 때문에 이미지를 일정하게 토큰으로 만들 수 없었는데 OpenAI에서 발표한 DALL-E 논문에서 발표한 이미지 tokenizer를 사용하면서 이 문제를 해결했습니다.
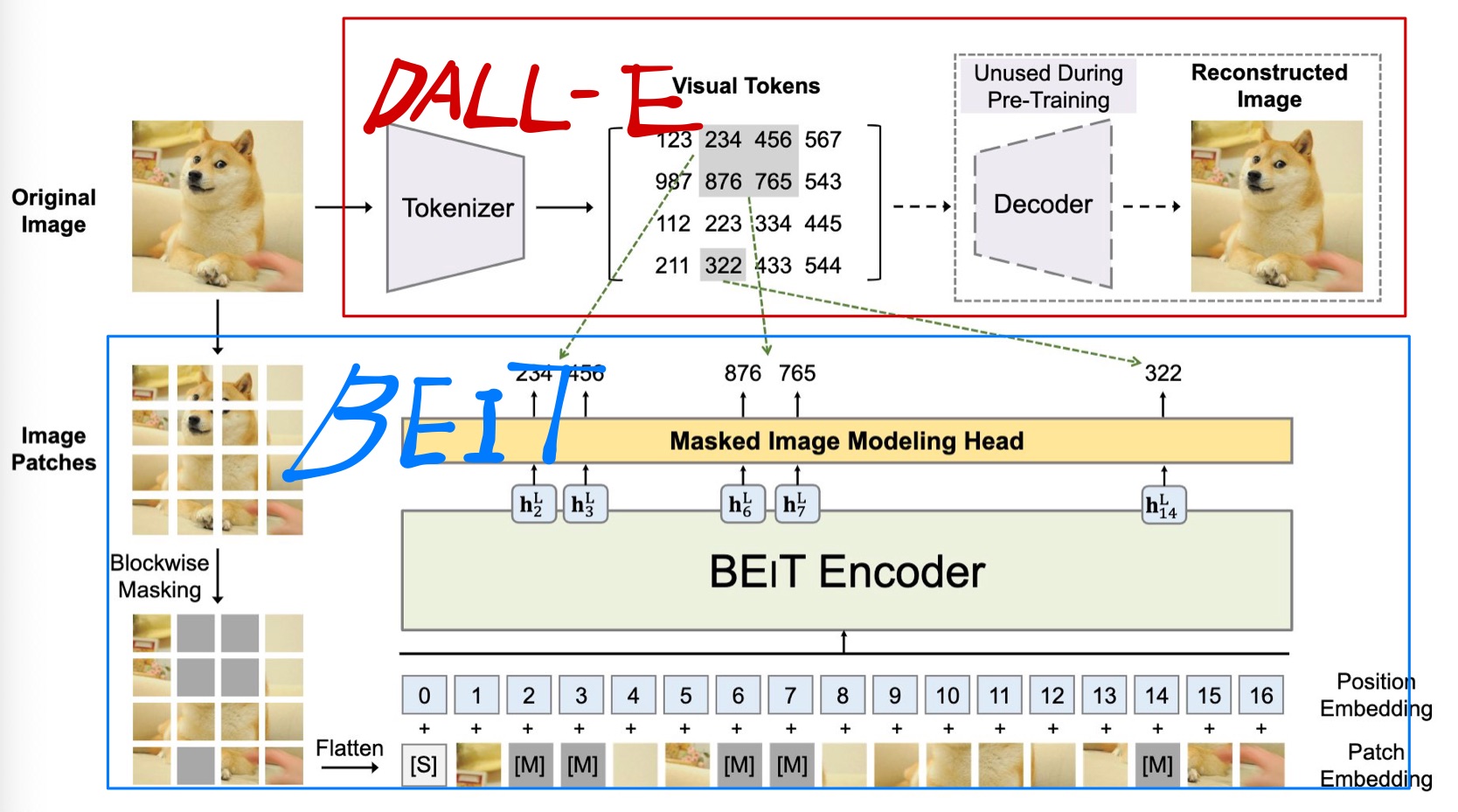
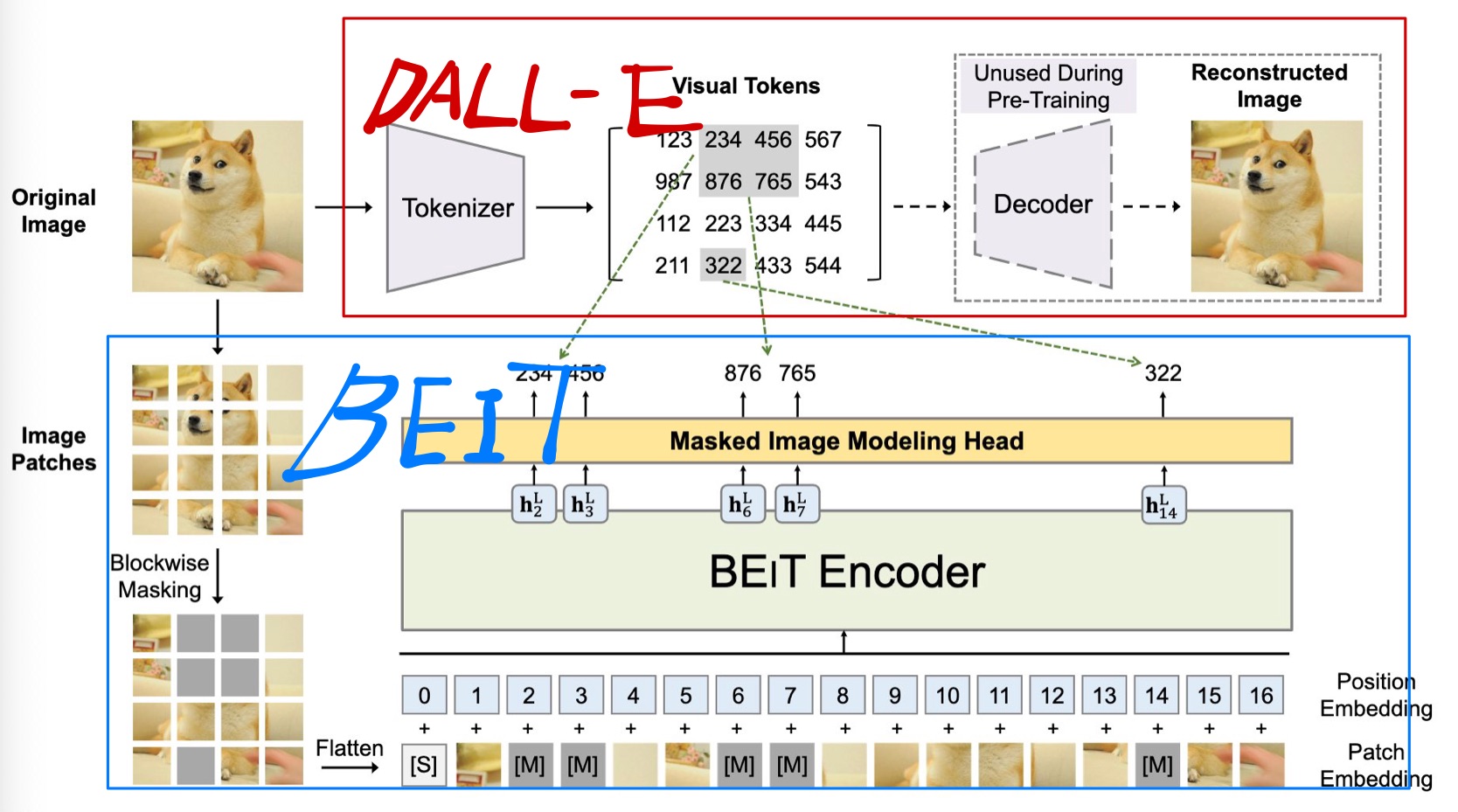
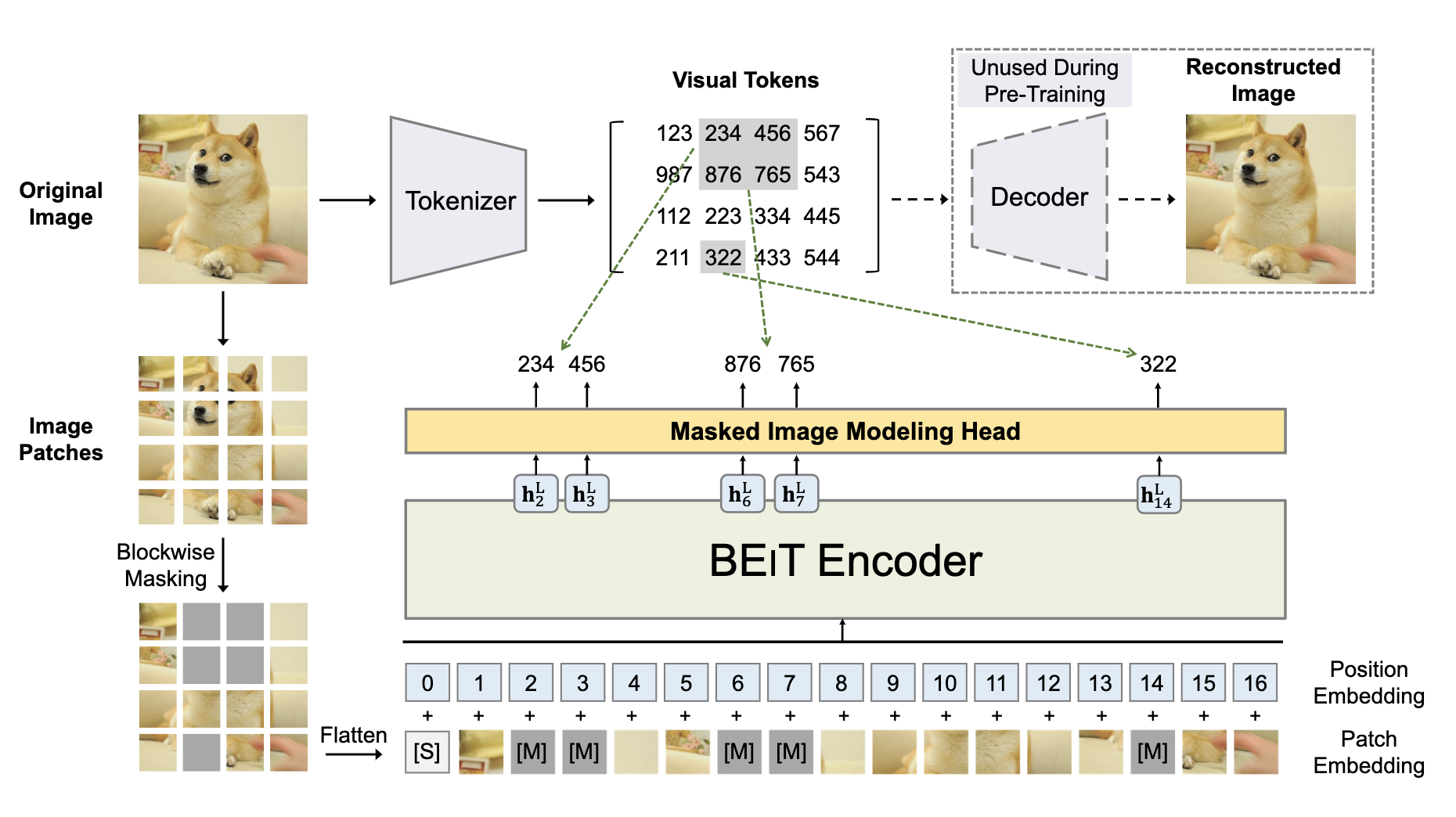
위 그림에서 빨간 박스안에 있는 부분이 DALL-E 에서 공개한 Tokenizer를 사용한 부분입니다. DALL-E의 Tokenizer를 이용해서 이미지를 discrete한 visual token으로 만들 수 있습니다.
DALL-E의 Tokenizer는 discrete Variational AutoEncoder 방식으로 학습되었는데 자세한 내용은 Paper에서 확인하실 수 있습니다.
Pre-Training
DALL-E Tokenizer를 이용해서 이미지를 discrete token들로 변환하고 image patch들 중에서 40%에 masking을 적용합니다. Masking된 패치들은 학습 가능한 임베딩으로 교체한뒤 masking되지 않은 패치와 함께 ViT의 입력값으로 사용됩니다.
ViT모델의 최종 히든 벡터들은 입력값의 encoded representation으로 취급하며, softmax classifier(MIM Head)를 통과해서 최종출력을 하게 됩니다.
masking되었던 패치들의 최종출력이 DALL-E를 통해서 미리 생성되었던 discrete token을 예측하도록 모델을 훈련합니다(log-likelihood사용).
위 내용만 놓고 보면 자료형태가 이미지인것을 제외하면 BERT와 거의 동일하다.
주목할만한 점은 masking할 패치들을 임의 선택한것이 아닌 blockwise하게 했다. 논문에서 밝힌 방법은 랜덤하게 block의 사이즈를 정하고 block의 위치를 정하는 과정을 masked patch가 전체의 40%가 될때까지 반복했다.
위 과정에서 이미지의 라벨을 전혀 사용하지 않았기 때문에 사전학습 과정은 온전히 자가지도학습 방법론이라고 주장한다.
Fine-Tuing
사전학습이 끝난 BEIT는 downstream task로 fine-tuning되어야 하는데 그중에서 Image classification Global Average Pooling을 이용해서 최종 출력층의 벡터를 모으고 linear classifier를 통과시키게 됩니다.
Experiment
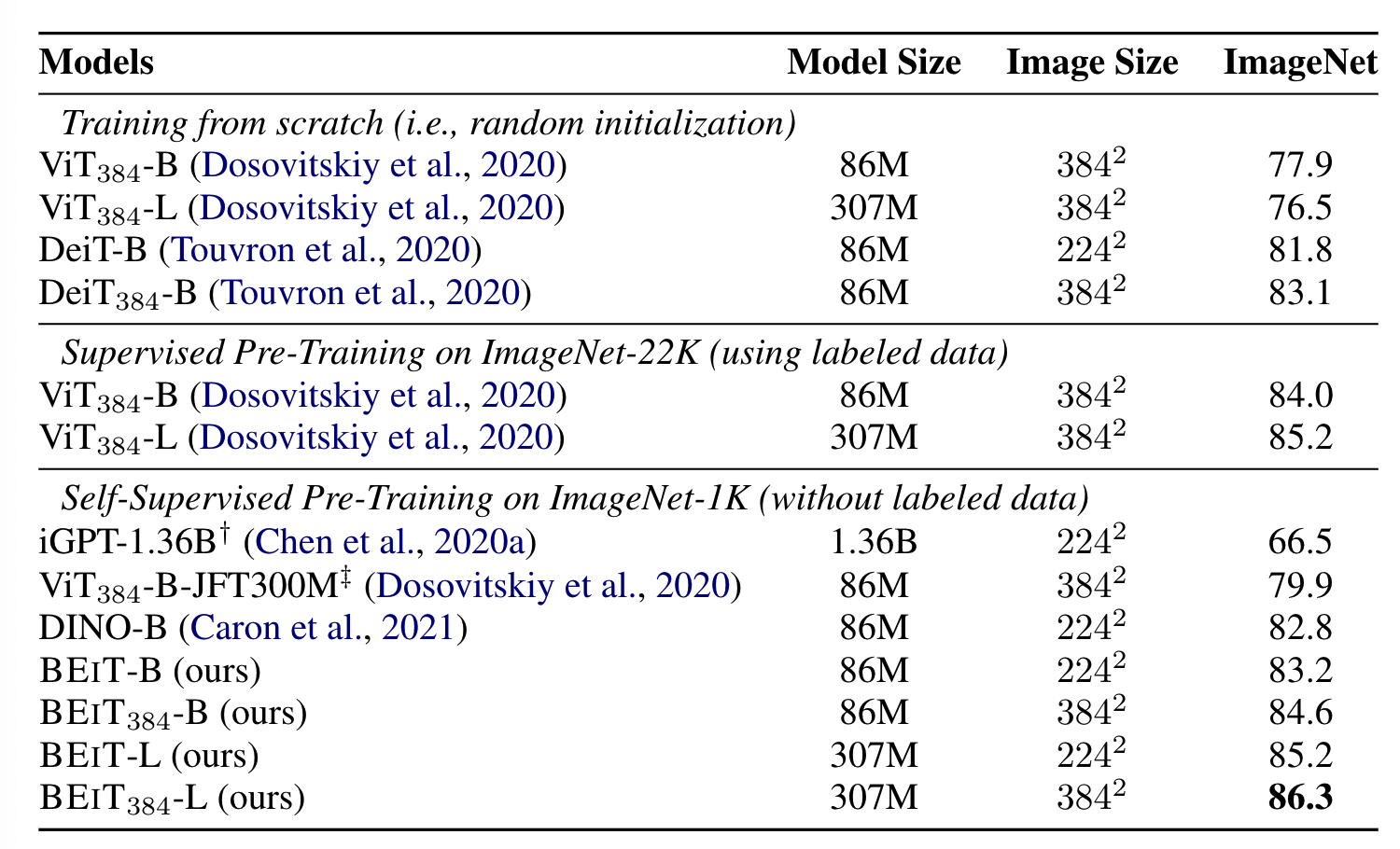
결과를 보면 똑같이 자가지도학습 방식을 채택했던 DINO에 비해서 더 좋은 결과가 나온것을 확인할 수 있습니다. 또한 JFT300M이라는 구글 내부의 거대한 데이터셋으로 지도학습시킨 모델보다도 ImageNet1k 만 사용한 BEIT가 높은 성능을 내주었습니다.
하지만 저는 BEIT도 사전 학습된 DALL-E를 사용했기 때문에 실제로는 ImageNet 1k 보다 많은 데이터를 사용했다고 보고 있습니다.
이외의 결과는 다른 많은 논문들과 마찬가지로 대부분의 downstream task에서 높은 성능이 나왔다고 주장합니다.

한가지 주목할만한 점은 BEIT도 DINO모델과 마찬가지로 지도 학습을 하지 않았음에도 attention map을 시각화하면 이미지에 존재하는 오브젝트가 활성화됩니다. ViT모델을 자가지도학습 방식으로 학습시키면 나타나는 하나의 특징인 것 같습니다.
결론/생각
본 논문은 DALL-E에서 공개한 이미지 tokenizer를 이용해서 BERT방식의 discrete token을 예측하는 masked image modeling을 제시했습니다.
사실 tokenizer는 DALL-E에서 공개했고, Backbone은 ViT를 그대로 사용했고, 학습방식은 BERT의 그것을 그대로 사용했습니다. 새로운 방법론을 제시했다고 보기는 어려울 것 같지만 ViT를 masking patch prediction 방식으로 학습하면 어떤 결과가 나오는지 보여준 논문이라고 생각합니다.
추가적으로 이후에 나온 Masked Autoencoders are scalable vision learner는 BEIT에서 좋지 않다고 주장한 pixel 수준의 재구성을 통해서 BEIT보다 높은 성능을 내주었습니다. 이 논문도 읽어보면 많은 도움이 될것 같습니다.
