
공부를 하다보니 배치 정규화에 대한 내용이 궁금하여 공부한 것을 기록해보았다.
배치 정규화, Batch Normalization
왜 사용하는 것 일까. 흔히 말해 학습시간을 줄이거나 모델이 Local optimum에 빠지지 않도록 또, overfitting에 빠지지않도록 하기위해서 라고 한다.
Internal Covariance shift
공부를 하며 단 한번도 빠지지 않고 나온 개념이었다. 뜻을 알아보겠다.
Convariance - 공변량
Convariance은 변수의 개념을 가지고 있다. 보통 종속변수와 독립변수을 흔하게 알고 있다. 하지만 여러 잡음이 섞여 독립변수와 종속변수의 관계를 설명하지 못하는 경우가 있다.
이때, 독립변수와 종속변수의 관계를 설명할 때 방해가 될 수 있는 요인을 공변량이라고 한다.
Covariance shift
이전 layer의 파라미터의 변화로 인해 현재 layer의 입력의 분포가 바뀌는 현상이라고 한다.
Internal Covariance shift
Covariance shift의 정의보다 조금더 확장되어서 입력 데이터가 model의 layer에 통과되면서 분산이 달라니는 것. 즉, 원래의 데이터에서 왜곡된다는 의미이다.
자 생각해보자 우리는 모델을 학습시켜서 입력값을 넣었을 때 원하는 결과값을 얻고 싶다. 하지만 input이 layer들을 통과될 수록 가중치들이 곱해지고 왜곡이 일어난다.
조금 다르게 말하면 training dataset을 학습시키면 분포가 test dataset과 달라져 우리가 원하는 결과와 멀어진다. 이것이 Overfitting이다.
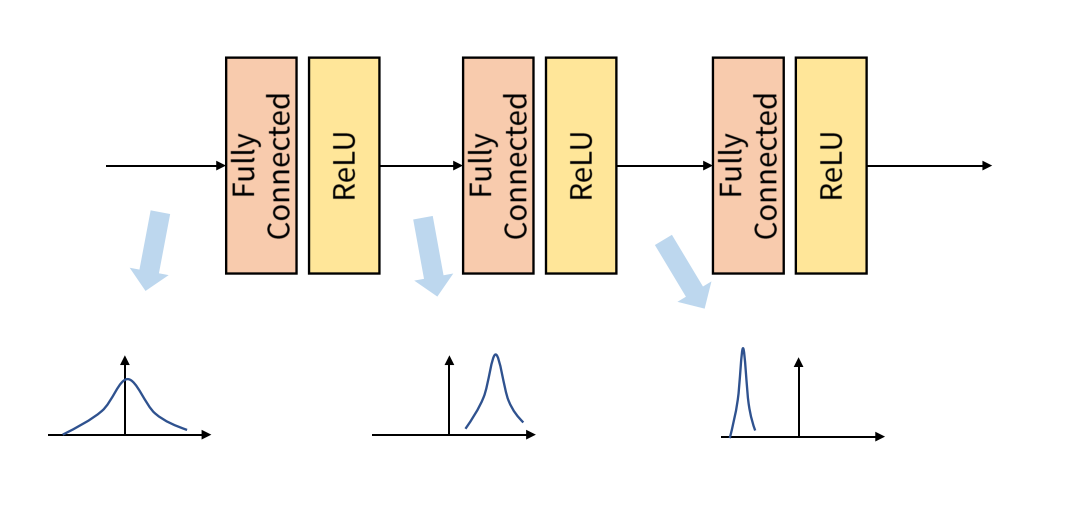
계층을 통과하고 나면 데이터 분포가 달라지고 있다.
Internal Covariance shift 해결방안
Internal Covariance shift의 해결방안은 Batch Normalization이다.
정말 쉽게 직관적으로 봤을 때 단순히 분포의 위치와 크기를 바꿔주면 해결이 된다고 생각할 수 있다. ( 이게 바로 Bath Normalization )
계산과정을 살펴 보겠다.
미니배치 평균 → 미니배치 분산 → 정규화 → 스케일 조정 및 이동
- mini-batch mean
- mini-batch variance
- normalize
평균은 0, 분산은 1
- scale and shift
마지막에 보이는 감마와 배타가 정규화를 통해 얻은 분산을 넓게/좁게 그리고 좌우로 이동시키는 역할을 한다.
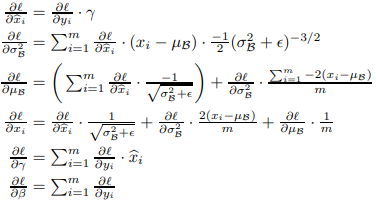
감마와 베타는 역전파 단계에서 업데이트된다. 위는 감마와 베타가 적용되는 수식이다.
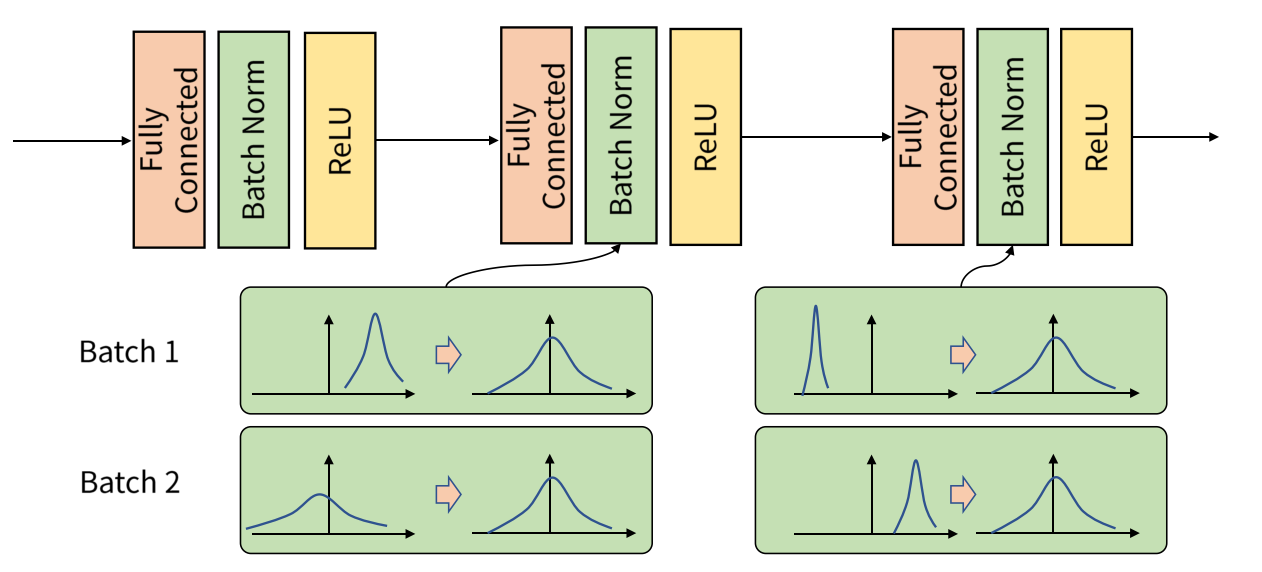
Batch Normalization 순서
Batch Normalization은 layer와 활성화 함수 사이에 들어가 동작을 수행하게 된다.
BatchNorm2d
BatchNorm2d 은 2차원 이미지를 학습할 때 배치 정규화과정에서 사용된다.
torch.nn.BatchNorm2d(*num_features*, *eps=1e-05*, *momentum=0.1*, *affine=True*, *track_running_stats=True*, *device=None*, *dtype=None*)num_features: 입력 데이터의 채널 수.
eps: 수치적 안정성을 위해 분모에 더해주는 값.
momentum: 매치마다 계산된 평균/분산을 누적할 때 사용하는 계수.
affine: True일 경우, 학습 가능한 와 를 사용
track_running_stats: True일 경우, 학습 중 계산한 평균/분산을 기록해두었다가 추론(Inference) 시에 사용.
BatchNorm2d — PyTorch 2.10 documentation
감사합니다.
Batch Normalization (velog.io)
[CNN] Batch Normalization(배치 정규화) (velog.io)
[Deep Learning] Batch Normalization (배치 정규화) (tistory.com)
