
Hyperparamerter
모델이 학습을 시작하기 전에 사용자가 설정해주는 “값”
Learning rate
학습률로, 모델이 학습을 할때 역전파(backward)를 통해 모델의 가중치를 얼마나 이동시킬지를 나타내는 값이다.
이때 학습률에 따라 나타날 수 있는 상황이있다.
- 학습률이 너무 클 경우 - Loss가 발산하거나 Local Minimum 주변에서 진동(Oscillation)하며 수렴하지 못한다.
- 학습률이 너무 작을 경우 - 수렴 속도가 매우 느리며, Saddle point나 Shallow Local Minimum에 갇힐 위험이 큽니다.
Oscillation(진동) - 학습률이 너무 클경우 극값으로 가지 못하고 반대편 사면으로 오버슈팅되는 현상
Saddle point - 이지만 극소/극대값이 아닌 지점 임계점
Batch Size
모델이 한번 학습할 때 사용되는 데이터 샘플 수를 나타낸다.
Batch size 결정
작은 배치 사이즈
-
장점
- 일반화 성능이 좋음
- 메모리 효율 굿
-
단점
- 학습속도가 느림
- gradient의 분산이 커서 불안할 수 있음
큰 배치 사이즈
-
장점
- 학습속도가 빠름
-
단점
- 과적합 위험
- 일반화 성능이 떨어질 수 있음
Epoch
전체 데이터셋이 신경망을 통과한 횟수
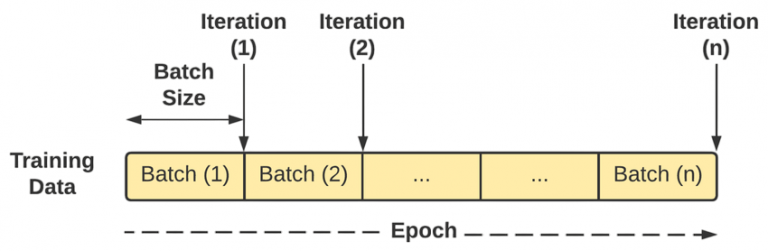
lteration은 1-epoch을 마치는데 필요한 미니배치 수를 의미한다. Step이라고 부르기도 한다.
Overfitting / Underfitting
Overfitting 과 Underfitting 발생 시 모델이 데이터를 정확하게 판단하지 못하는 결과를 가져온다. 발생하는 원인은 다르지만 모델에 성능에 영향을 끼친다.
Overfitting
모델이 데이터의 내재적 패턴(Signal)뿐만 아니라 샘플의 노이즈(Noise)까지 학습하여, 학습 데이터에만 특화된 결정 경계(Decision Boundary)를 형성하기 때문.
Underfitting
모델의 가중치 공간(Hypothesis Space)이 실제 데이터의 분포를 표현하기에 너무 작거나(Low Capacity), 학습이 충분히 이루어지지 않았을 때 발생한다.

💫