
Loss ? Cost ?
손실 값 혹은 cost 라고 불리는 이 값은 우리가 돌리고 있는 모델의 예측값과 실제 정답 사이의 차이를 값을 표현한 것이다.
당연하게 차이의 값이 작으면 작을수록 예측값이 실제 정답과 가까워진다고 표현할 수 있다. 그러기에 Loss 값을 적게하는게 AI 구조를 다루는 개발자의 역할이다.
위에는 MSE 손실 함수로 Loss 값을 구하는 방정식이다.구한 Loss 값을 가지고 가중치(weight)와 편향(bais)를 Loss 값이 최소한의 값이 되도록 조정해야한다.
주요 손실함수
- MSE(Mean Squared Error) - 예측값과 실제값의 차이를 제곱한 뒤에 평균값을 낸 값
- MAE(Mean Absolute Error) - 예측값과 실제값의 절대 차이 평균을 구한 값
손실함수도 상황과 목적에 맞게 사용해야 모델의 성능을 이끌어낼 수 있다. MSE와 MAE는 회귀에 유용하게 쓰이는 손실함 수 이다. MSE는 오차에 크게 반응하고 MAE는 이상치에 좋다.
Gradient Descent
구한 손실함수를 가지고 어떻게 가중치(weight) 와 편향(bais)을 조절할까?
가중치(weight)의 변할 때 Loss 값이 어떻게 변하는지를 구해 더 최적의 값을 찾아야한다.
가중치(weight) 변화에 대한 Loss 가 어떻게 변하는지 편미분을 통해 Gradient를 구할 수 있다. Loss 값을 줄이는 것이 목표이므로 경사가 완만한 방향으로 이동시켜야한다. 즉, 구한 Gradient의 반대 방향으로 이동시켜야한다.
이를 경사하강법이라고 한다.
Optimizer
경사하강법을 이용해 구한 기울기를 이용해 새로운 가중치를 구할 때 최적화 알고리즘이 사용된다.
이때, Learning Rate 학습률이라는 값이 사용된다. 학습률은 경사하강법을 통한 기울기값을 통해 얼마나 이동할지를 나타낸 값이다.
대표적인 Optimizer
- SGD(Stochastic Gradient Descent)
optimizer = optim.SGD(model.parameters(), lr=0.01) optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) - Adam(Adaptive Moment Estimation)
optimizer = optim.Adam(model.parameters(), lr=0.00
SGD는 기울기가 완만한 곳에서는 느리고, 진동하며 하강하는 경향이 있어서 최적점에 도달하기 어렵다. Adam은 방향(Momentum)과 보폭(Scale)를 스스로 조절하며 내려가 학습 초기에 매우 빠르고 안정적이지만 SGD보다 계산량이 많고 세부적인 조절이 필요한 경우에는 SGD 보다 성능이 떨어질 떄가 있다.
Local minimum
손실함수는 단순한 아치 함수형대가 아니라 여러개의 골짜기가 생긴다(미분이 0이 되는 구간, 극소값) 우리는 Loss 값을 작은 값을 만들기 위해 경사가 완만한 쪽으로 가야한다. 하지만 이동한 곳이 가장 완만한 곳이 아니라면 제대로된 경사하강법을 했다고 말할 수 없다. 이러한 문제를 Local Minimum 문제라고 부른다.
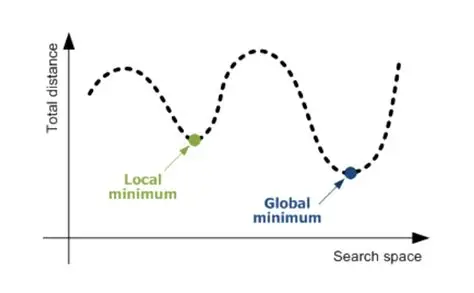
- Local Minimum: 부분적으로 최저점인 곳. 여기서 기울기가 완만해져 학습이 멈출 수 있다.
- Global Minimum: 전체 구간에서 진짜 최저점.
- Saddle Point (안장점): 한 방향에서는 극소값이지만 다른 방향에극대값인 지점. 고차원 신경망에서는 Local Minimum보다 이 안장점에 갇히는 경우가 더 많다.
