예전부터 좀 궁금했었던게 하나 있었는데 "유튜브 자막은 어떻게 달았을까?" 라는 궁금증이 있었습니다.
이거와 관련되어서 궁금증을 해결해준게 바로 이번 AI 음성 인식 서비스 였습니다.
유료 결제를 해야하는 부분이 있어서 그전까지만 했었습니다.

음성 인식 서비스
음성 인식 -> 텍스트 변환 : Speach-To-Text(STT)라고 불립니다.
아래 같은 과정으로 크게 진행되는데요
- 목소리가 마이크를 통해 디지털 신호로 변환
- 디지털 신호가 음성 인식 알고리즘을 거침
- 변환된 텍스트 기반으로 명령 수행
활용사례
대표적인 활용 사례는 아래가 있습니다.
- 스마트폰 가상 비서 서비스 - 빅스비, 시리
- 자동차 네비게이션 서비스 - 카카오 내비, 티맵
- 음성 메모 서비스
알아야하는 기술 키워드
자동 음성 인식 - 컴퓨터가 사용자의 말을 자동으로 인식하고 이해하는 시스템
- 음성신호 수집
- 신호 전처리 - 노이즈 제거 등
- 음향 모델링 : 음성을 작은 단위로 나눠서 발음 인식
- 언어 모델링 : 음향 모델링 결과를 바탕으로 문맥에 맞는 텍스트로 변환
- 텍스트 출력
스팩트로그램 - 시간에 따른 소리 주파수를 2차원 이미지로 표현한 그래프
- 복잡한 시간 - 주파수 특성을 분석해줌
SRT 포맷 - 비디오 파일에 대한 자막을 저장하는데 사용되는 텍스트 기반 파일 포맷
- 번호 : 각 자막 블록에는 순차적인 번호가 할당됨
- 시간 : 자막 시작과 끝 시간을 나타냄 -> 로 구분
- 자막 텍스트 : 시간코드 다음에는 자막 텍스트가 위치

만들 서비스 구체화
1단계 : 사용자가 원하는 유튜브 영상 링크를 입력하게 해주는 유튜브 링크 입력 UI 필요
2단계 : 유튜브 링크를 기반으로 영상 정보 및 음성정보를 출력하는 "유튜브 정보 추출기" 구현
3~4단계 : 음성 정보를 음성 인식 모델 추론기에 입력 -> 텍스트로 변환 -> 후처리로 자막파일로 생성 -> UI로 보기 및 다운로드 가능
5단계 : 이제 영상과 자막 합쳐서 새로운 영상 생성
모델 선정 - opneAI의 whisper
음성 인식모델이 갖추어야할 기본 능력
발화감지 - 음성 정보에 사람의 말 포함 감지
발화 시간 감지 - 어느 시점에 사람의 말이 등장했는지 감지
언어 감지 - 어떤 언어인지 감지OpneAI의 whisper모델 사용 예정
680,000시간 분량의 다국어 음성 데이터를 학습함
모델 구조
사실 글로는 어려워서 글 아래있는 그림으로 보면 편합니다;;
트랜스포머로 구현된 인코더-디코더 구조
- 30초 단위로 분할된 음성정보를 입력받음
- 소리정보를 시각화한 그래프인 스펙트로그램으로 표현됨 - 특성한 주파수 패턴을 보고 이런 정보를 학습에 활용
- 1D 컨볼루션 레이어는 음성정보로부터 1차원 특징을 추출 -> 인코더를 위한 전처리
- 사인파 위치 인코딩은 음성 정보 특징에 시계열 정보를 추가 -> 인코더가 시계열 정보 인식하게
- 인코더 블록이 음성정보 특징을 추출, 트랜스포머로 구성
- 디코더 블록은 인코더로부터 획득한 특징들을 기반으로 어떤 단어와 문장이 발화되었는지 감지
- 데이터 속 말을 텍스트로 변환, 트랜스포머 구조
- 디코더 블록에 음성정보로부터 발화내용 예측 위한 토큰 구조를 입력 ->
- 토큰 입력에도 학습된 위치 인코딩을 통해 시계열 정보를 추가
- 디코더는 입력토큰을 기반으로 다음 토큰 예측
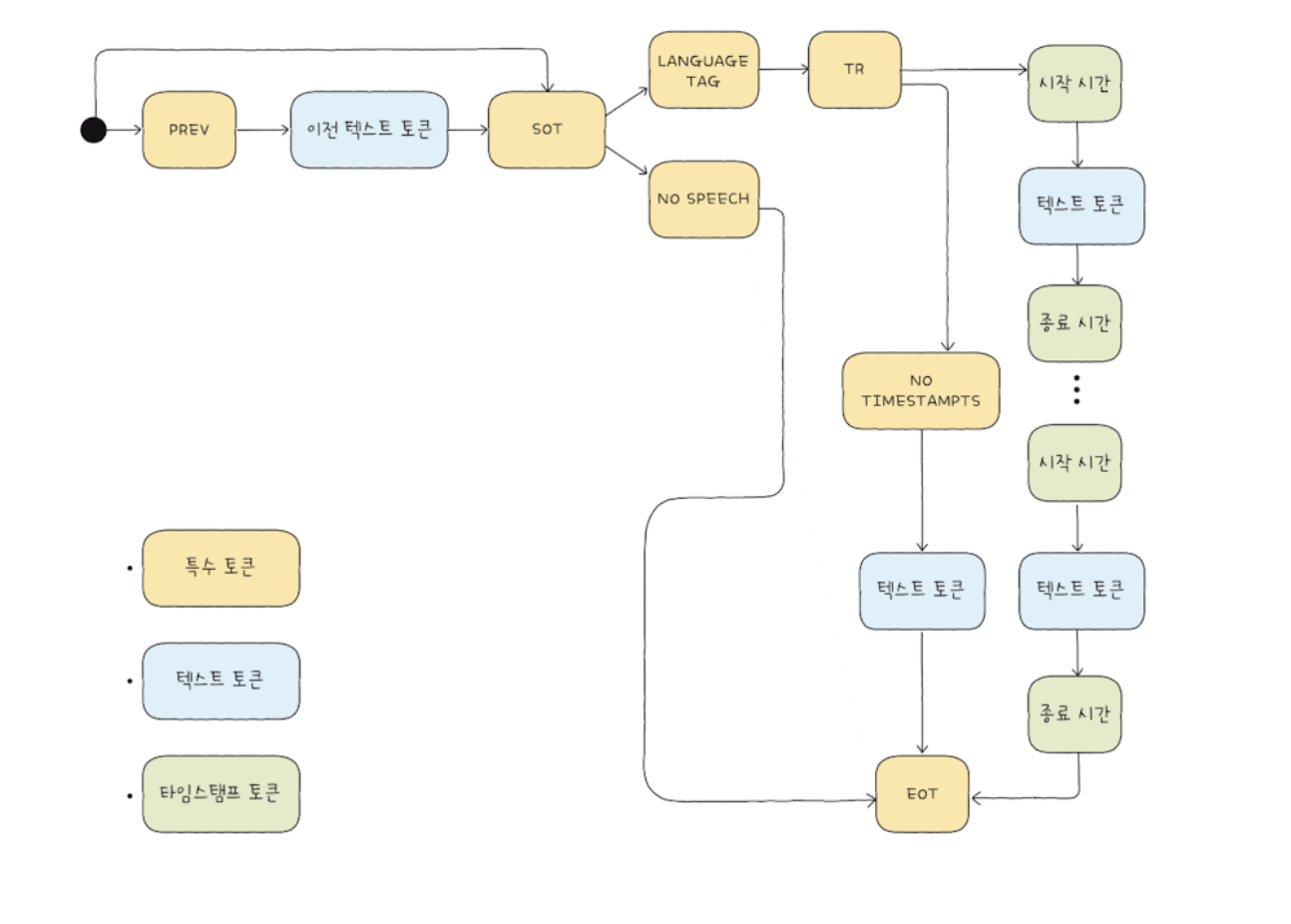
토큰 구조
PREV : 이전 텍스트 정보임을 표시하는 토큰
SOT : 음성 텍스트 변환 작업의 시작을 표시하는 토큰
No SPEECH : 음성 속 발화 없으면 발생하는 토큰
LANGUAGE TAG : 음성의 언어 나타내는 토큰 EN, KO
TRANSCRIBE : 음성-텍스트 변환 작업을 표시
NO TIMESTAMPTS : 발화 시간 감지를 하지 않도록 설정하는 경우 이를 표시하는 토큰
EOT : 음성-텍스트 변환 작업의 마지막을 표시하는 토큰
flask + react로 직접 음성 번역 만들었지만 실패한 이유
colab
from IPython.display import Audio # 오디오 컨텐츠를 불러오기 위해 사용함
from openai import OpenAI # OpenAI의 모델을 가져오기 가능
import whisper
model = whisper.load_model("large")
audio_path = "examples/example.wav"
Audio(audio_path)
result = model.transcribe(audio_path)
result["text"]" 그는 괜찮은 척하려고 애쓰는 것 같았다." 라는 결과가 나옵니다
그래서 이걸 보고 react에서 음성을 보내면 flask에서 텍스트로 변환 해서 응답 반환하는 사이트를 만들었는데 실패했습니다.
실패의 2가지 이유
-
환경의 차이
IPython.display.Audio는 코랩의 노트북 환경에서 음성을 직접 재생할 수 있는 기능을 제공하지만 로컬 서버에서는 웹 브라우저에서 음성을 처리하는 방식과 관련하여 웹 애플리케이션의 HTTP 요청과 응답을 다루어야 합니다
-
CORS 문제
이건 flask에 cors해결하는 방식을 적었는데도 계속 떠서 결국 해결하지 못했습니다.. 내부ip끼리 제대로 연동이 안되는 문제가 있어서 해결을 해야할거 같습니다.
피드백
저번과 마찬가지로 꽤나 간단하게 AI모델을 가져와서 실제 구현을 볼 수 있었습니다.
각 AI 서비스들이 어떻게 돌아가고 내가 만들 포트폴리오에 적합하게 넣기 위해 노력...해보겠습니다