사실 처음 이번 챕터를 보고는 "뭐야 객체 인식이네 이번에도 박스하나 만들겠네" 라고 생각했었습니다.
객체인식보다 더 섬세한(?) 기술이 있다는 것을 이번에 모델을 사용해보며 알았고 이건 정말 사용할 수 있겠다 싶었습니다

이미지 세그멘테이션
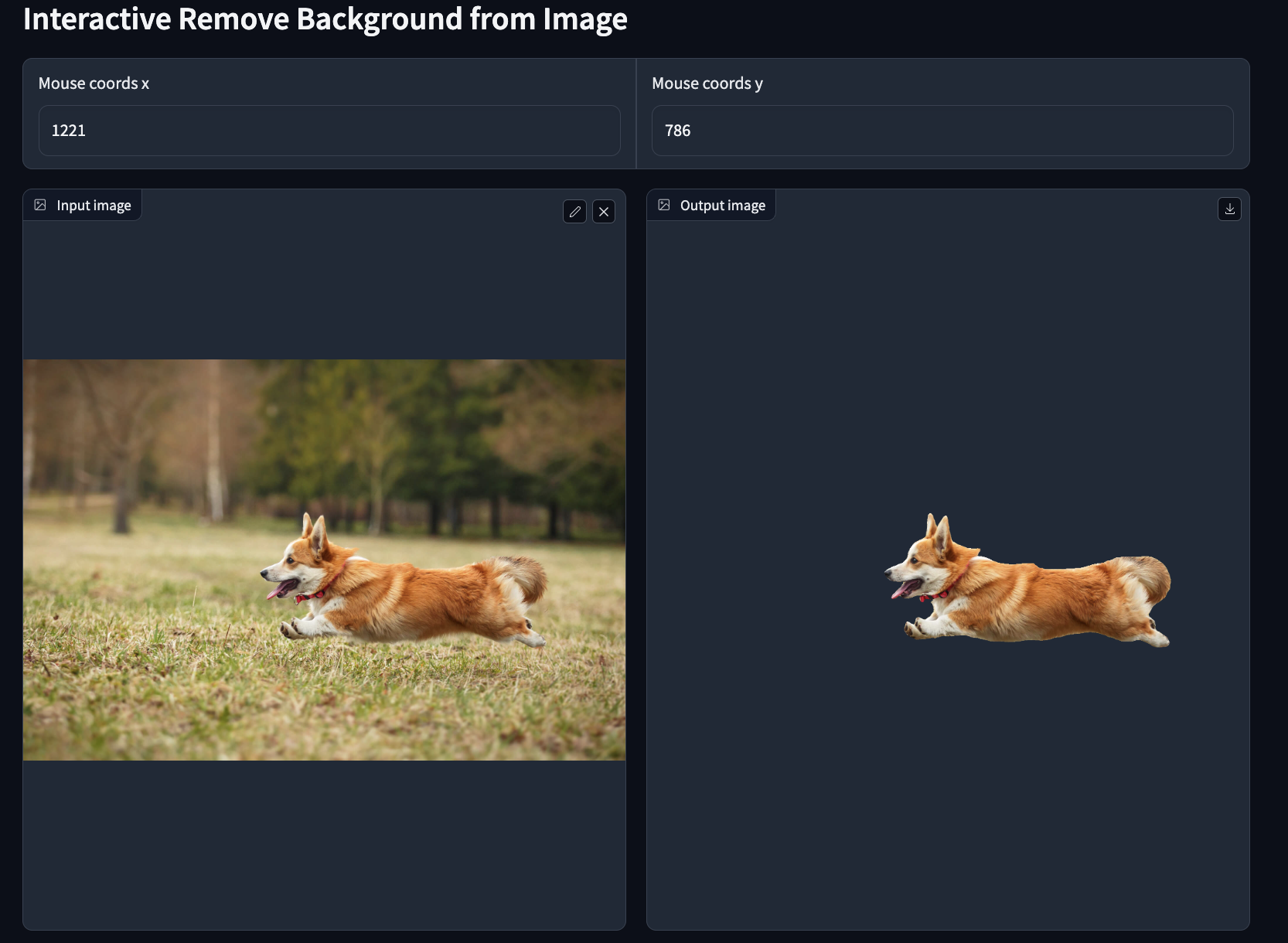
쉽게 말하면 내가 선택한 이미지를 제외하고는 배경을 다 날리는 것입니다.
컴퓨터가 디지털이미지나 영상에서 데이터를 추출하고 해석할 수 있도록 하는 컴퓨터 비전 기술
객체인식 vs 이미지 세그멘테이션
사실 둘다 객체를 인식하는 공통점이 있지만 약간의 차이점이 있습니다
객체인식 기술 -> 객체의 위치와 크기를 바운딩 박스로 표현
이미지 세그멘테이션 -> 더 상세히 픽셀단위로 파악해서 해당 이미지 부분만 분리
실제 적용 가능한 분야
- 의료 이미지 분석 서비스 -> 세포나 종양등의 특정 영역을 정확하게 분리하고 특성 분석
- 자율주행 서비스 -> 도로 위의 표지판, 보행자를 인식해서 적절한 조치
- 영상분석 서비스 -> CCTV 영상의 사람들에 대한 정보 데이터화
...
알아야하는 키워드
그렇다면 OCR처럼 미리 알아야하는 단어들을 알아봅시다!!
클래스 -> 분류 문제에서 대상이 되는 여러 카테고리
개와 고양이를 분리한다면 개, 고양이가 클래스
세그멘테이션 마스크 -> 결과물, 원본이미지 크기이며 어떤 클래스인지 파악
인간분리 한다면 인간은1, 아니면0으로 픽셀 분리!
바운딩 박스 -> 객체 주위를 사각형으로 둘러싸는 것
모델 선정 - SAM(Segment Anything Model)
2023년 4월에 메타에서 만든 SAM이라는 모델을 사용했습니다
1100만개의 이미지와 10억개의 마스크 데이터 셋을 학습시켜서 꽤 많이 정확합니다...!!!
SAM의 구성
크게 3가지로 구성 되어 있습니다 -> 이미지 인코더, 프롬프트 인코더, 마스크 디코더
이미지 인코더
이미지 입력값을 받으면 저차원의 임베딩(CNN)을 합니다, 입력 이미지를 '수치화'하여 모델이 이해할 수 있는 형태로 변환하는 역할입니다.
프롬프트 인코더
세그멘테이션 프롬프트 정보(유저가 마우스로 클릭 위치)를 입력값으로 받으면 해당 정보를 임베딩으로 변환합니다
마스크 디코더
위에 2개의 정보를 입력하면 세그멘테이션 마스크를 출력함, 이를 통해 객체의 경계를 정확히 구분한 마스크를 생성합니다.
결과
코드 금지
코드의 경우 이 책의 저자의 코드를 그대로 제 블로그에 올리는건 코드 날치기 같아서 최근 공부하는 Django로 변환시켜서 한번 올리겠습니다!