방학동안 공부중인 딥러닝 & GCP에 대해 이제부터 꾸준히 작성하며 복습해보려고 합니다
주에 3개 이상 작성을 목표로!
Pandas를 이용해 - 교통사고 분석 표 만들기
Pandas의 DataFrame을 이용하면 우리가 자주 접하는 엑셀 처럼 테이블 형태의 데이터 표를 만들 수 있습니다.
- 기본 데이터 -> 년도, 총 사고건수, 총 사망자 수, 역주행 사고 수, 역주행 사망자 수
year = ['2019', '2020', '2021']
tAccident = [4223, 4039, 4370]
tDead = [206, 223, 191]
rAccident = [28, 33, 27]
rDead = [5,3,2]pandas를 이용하기 위해 import 해주면 됩니다
추가로 칼럼을 정해주고 리스트를 넣어주면 표의 세로줄이 완성!!
import pandas as pd
df = pd.DataFrame()
df["년도"] = year
df["총 사고건수"] = tAccident
df["총 사망자수"] = tDead
df["역주행 사고건수"] = rAccident
df["역주행 사망자수"] = rDead
df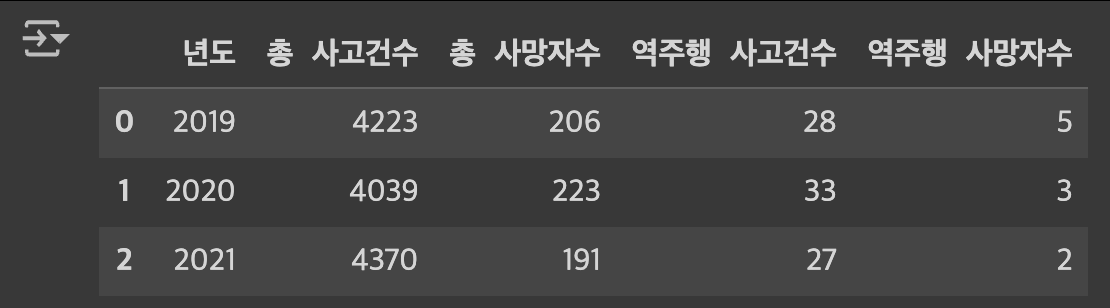
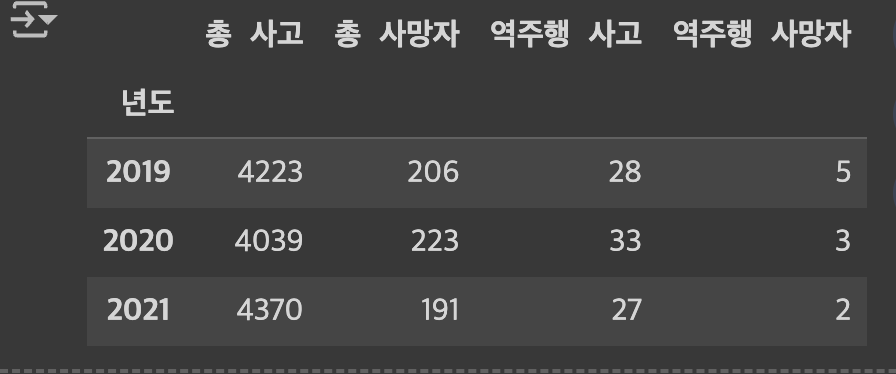
df.info() - 현재 테이블의 속성을 볼 수 있습니다
df.columns - 현재 테이블의 칼럼 값들을 볼 수 있고 이름을 다시 지정도 가능!
df.set_index("년도", inplace=True) - 기본 인덱스를 "년도" 칼럼으로 변환!
matPlot 사용 - 국세청에서 조사한 지역별 체납액 통계자료
판다스와 함께 자주 사용되는 막대 그래프 등을 만들어 주는 라이브러리입니다.
-> 이것도 판다스처럼 import먼저!
import matplotlib.pyplot as plt-> 그래프에서 한글을 사용하려면 한글 폰트를 지정해줘야한다!
%config inlineBackend.figure_format='retina'
!apt -qq -y install fonts-nanum
import matplotlib as mpl
import matplotlib.font_manager as fm
fe = fm.FontEntry(
fname=r'/usr/share/fonts/truetype/nanum/NanumGothic.ttf', # ttf 파일이 저장되어 있는 경로
name='NanumGothic') # 이 폰트의 원하는 이름 설정
fm.fontManager.ttflist.insert(0, fe) # Matplotlib에 폰트 추가
plt.rcParams.update({'font.size': 18, 'font.family': 'NanumGothic'}) # 폰트 설정국세청 체납액을 이용한 선 그래프 만들기
일단 국세청 사이트에서 필요한 자료를 가져와서 리스트로 변형했습니다.
area = ['서울','인천','경기','강원','대전','충북','충남','세종','광주','전북','전남','대구','경북','부산','울산','경남','제주']
amt = [627656,197952,859968,74890,70479,82257,122028,15760,63069,82779,93364,102952,117383,160554,53879,160893,40286]
cnt = [50758,12757,61944,3717,3731,4585,7730,928,4207,4357,5243,6061,6652,9296,3186,8778,2781]-> 아래 코드를 이용해서 그래프를 그려보았습니다
plt.plot()함수를 이용할때 'co--'를 작성하는데
맨 앞 영어가 컬러
그다음 영어가 (o-동그라미, x-x표시, v-역방향세모) 이거를 표현합니다
마지막 -는 그냥 선, --은 점선으로 나타냅니다
plt.figure(figsize=(10,6)) # 그래프 그릴 도화지 사이즈
plt.plot(amt,area, 'co--', label='체납액') # 체납액이 선으로 나타남, 지역이 x축에 표시!
plt.title('지역별 체납액', fontsize=15)
plt.xlabel('지역', fontsize=10)
plt.ylabel('체납액', fontsize=10)
plt.xtricks(rotation=90) # x축에 글씨들 90도 반시계로 돌리기!
plt.grid()
plt.axhline(y=200000, color='r', ls='--', lw=1)
for i in range(len(amt)):
plt.text(i - 0.5, amt[i] + 20000, amt[i], fontsize=10)
# x축 위치, y축 위치, 글자, 폰트 사이즈 지정
plt.show()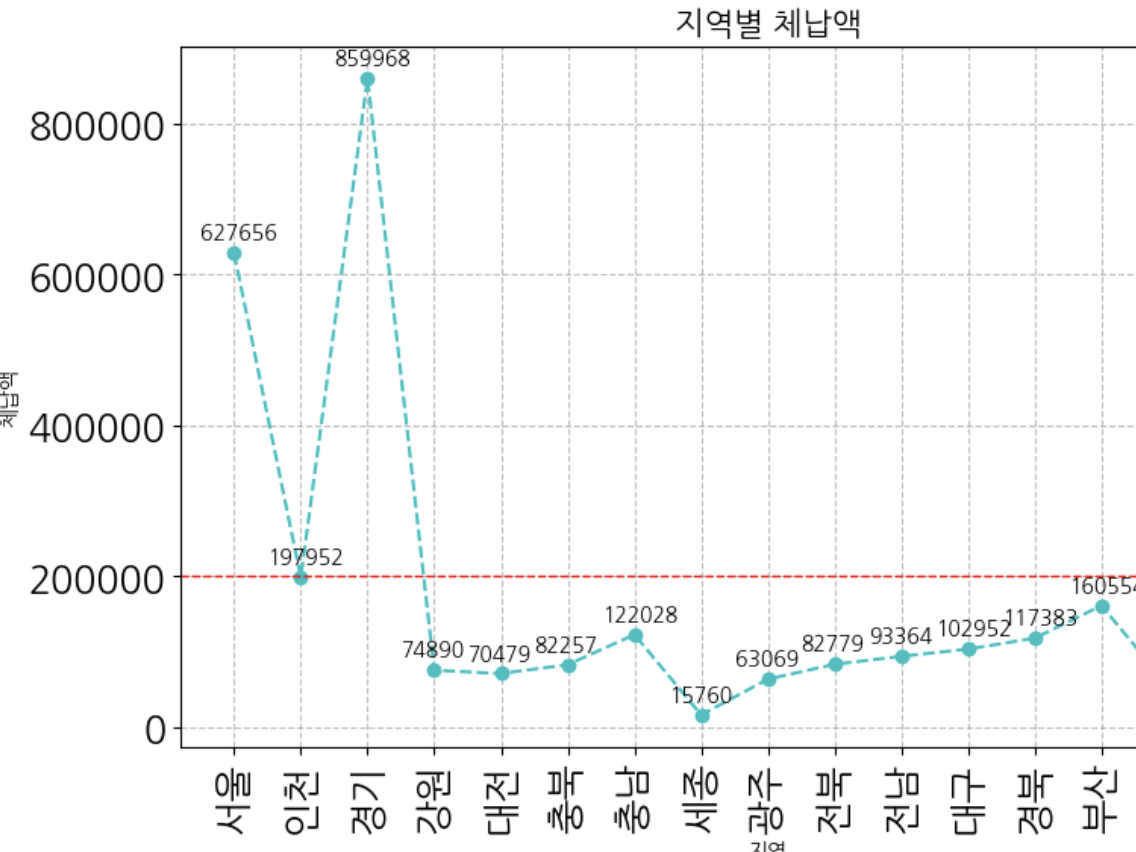
MNIST - 흑백 손글씨 숫자 이미지 분석
1. 문제 정의
흑백 글자가 들어왔을때 무엇인지 알려주는 AI 모델!
정확도 90% 이상인 AI 모델을 만들어보자
2. 데이터 수집
데이터는 keras 내부에 있는 mnist를 가져와 사용했습니다
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()3.데이터 이해 (EDA)
일단 데이터 형태 및 타입 확인하기
print(f'데이터 확인')
print(f'x_train_shape : {x_train.shape}')
print(f'y_train_shape : {y_train.shape}')
print(f'x_test_shape : {x_test.shape}')
print(f'y_test_shape : {y_test.shape}')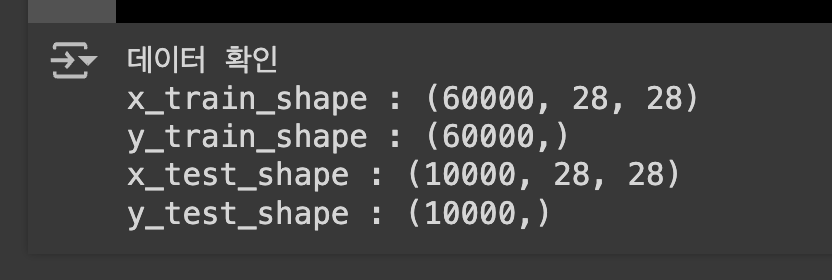
데이터는 현재 2차원 흑백 이미지 (원래 이미지는 3차원인데 흑백은 채널이 1이라 2차원으로 표현!)
그리고 데이터 타입은 현재 numpy.ndarray 입니다
3-1. 데이터 전처리
DNN 방식을 사용할 예정이므로 입력값이 1차원 정수나 실수여야 합니다!!
x_train = x_train.reshape(60000,28*28)
x_train = x_train.astype('float64') / 255
x_test= x_test.reshape(10000,28*28)
x_test = x_test.astype('float64') / 255추가로 원-핫 인코딩 방식을 이용해서 정답을 0,1로 표현했습니다
from keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)4. 학습 알고리즘(신경망) 선택
DNN을 사용하며, 다중 클래스이기 때문에 softmax를 사용할 예정입니다
그리고 입력에 대한 출력이 일정하기 때문에 Sequential을 사용합니다
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (28*28,)))
model.add(Dense(10, activation='softmax'))
model.summary()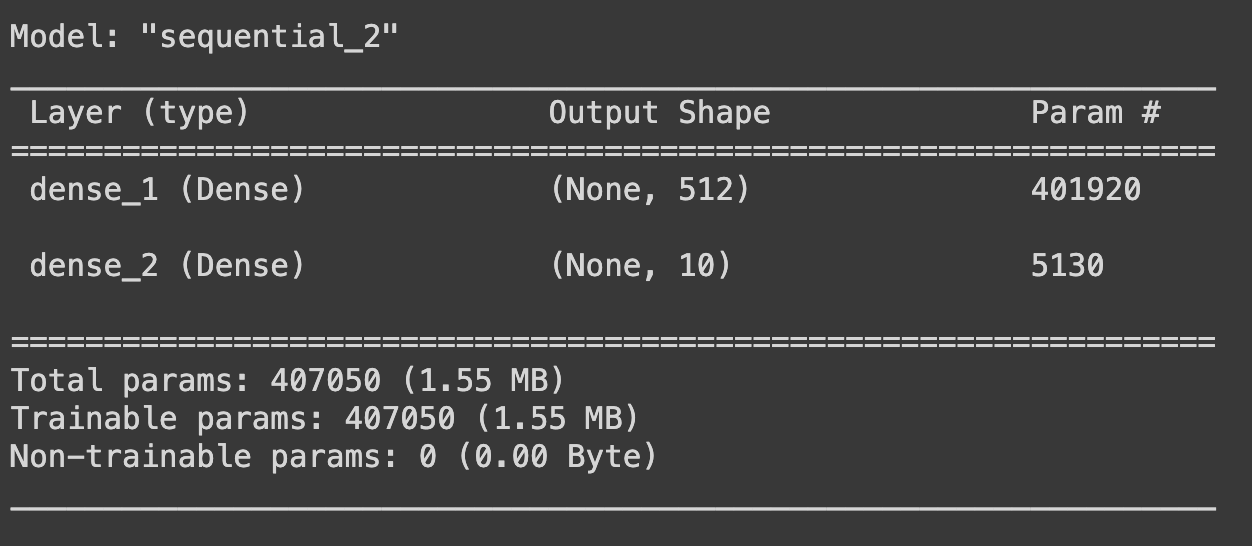
5. 학습(훈련, 모델링)
model.compile(loss='categorical_crossentropy", optimizer='adam', metrics='[accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)6. 평가
loss, accuracy = model.evaluate(x_test, y_test)
print(f'loss : {loss}')
print(f'accuracy : {accuracy}')
x_pred = model.predict(x_test)
for i in range(10):
print(f'예측값 : {np.argmax(x_pred[i])} 실제값 : {np.argmax(y_test[i])} {np.argmax(y_test[i]) == np.argmax(x_pred[i])}')