케라스로 딥러닝하기 라는 책에 있는 타이타닉을 연습한 과정과 결과, 그리고 느낀점을 적어보았습니다.
현재 딥러닝을 배우고 있는 입장에서 코드를 최대한 안보고 공부한대로 해보았습니다
문제 이해
이 문제는 딥러닝이나 머신러닝을 공부한다면 무조건 마주치는 문제라고 봐도 될 정도로 베이직한 문제입니다
쉽게 말하면 배에 탄 사람들의 정보를 토대로 이 사람이 생존할지에 대해 예측하는 문제입니다
데이터 전처리 및 이해
Titanic 데이터 가져오기
데이터는 googleapis내부의 tf-datasets에서 가져왔습니다
627개의 행과 10개의 열로 구성되었습니다
import pandas as pd
URL = "https://storage.googleapis.com/tf-datasets/titanic/train.csv"
df = pd.read_csv(URL)
print(df.shape) # (627,10)
df.head()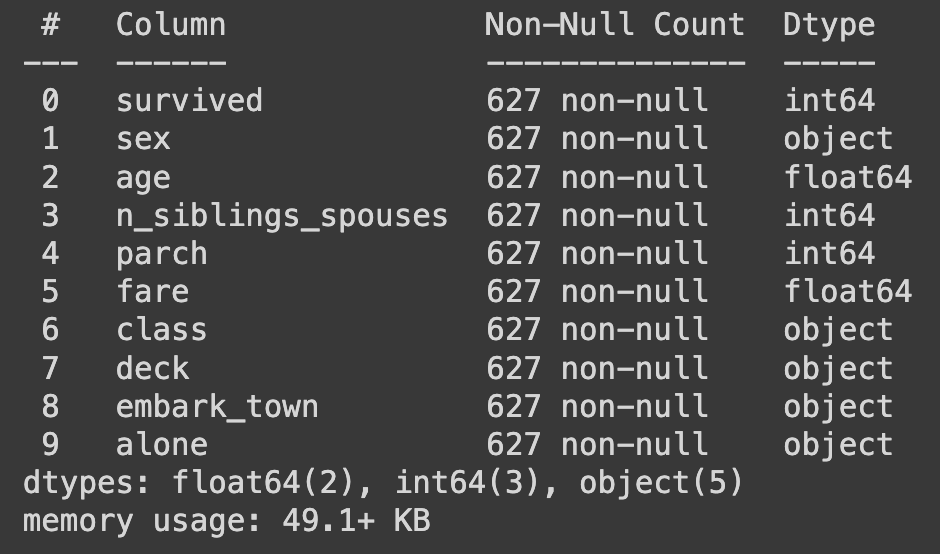
데이터 이해
데이터의 형태와 라벨, 그리고 각 데이터 타입이 무엇인지 알아야합니다
df.info()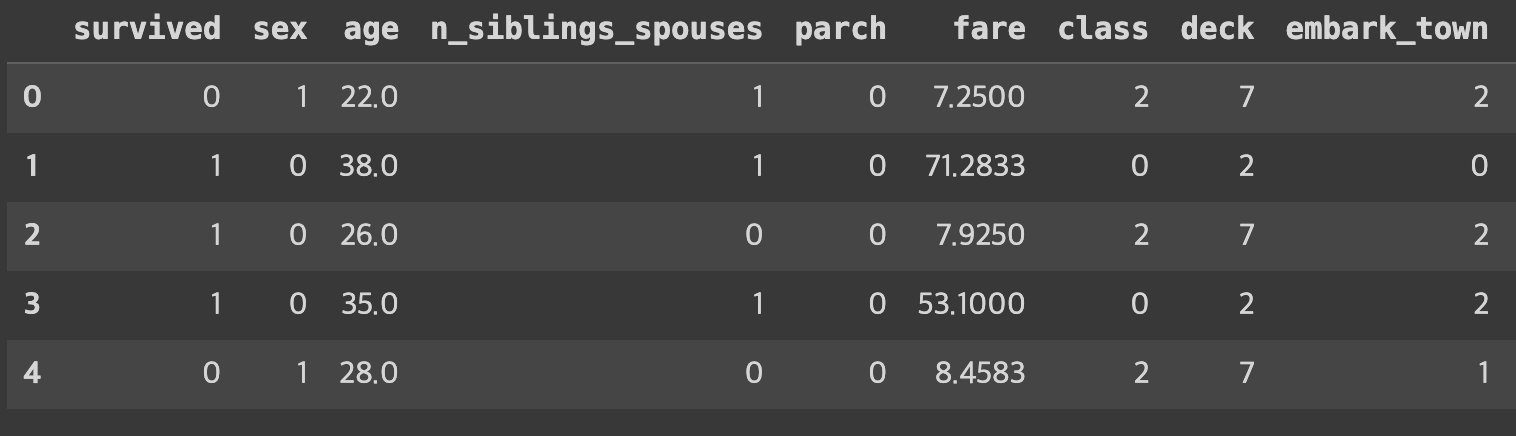
데이터 전처리
신경망에 입력 값으로 넣으려면 규칙이 2가지가 있습니다
- 결측값은 없어야한다 (null, NaN)
- 문자가 아닌 정수로 들어가야한다 (인코딩 해주기)
isnull() 함수를 사용해서 결측치가 있는지 확인했습니다.
다행히(?) 이 데이터는 전처리가 어느정도 되어있어서 결측치는 없었습니다.
df.isnull().any()문자형 -> 숫자형으로 인코딩하기
df.info()로 정보를 보게 되면 object 타입인 sex, class, deck, embark_town, alone 이 있습니다
이 데이터들을 각 문자들을 고유한 숫자로 변환해 주는 LabelEncoder를 이용해서
입력층에 넣을 수 있게 전처리 했습니다
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le = df[['sex', 'class', 'deck', 'embark_down', 'alone']].apply(le.fit_trainsform)
df['sex'] = le['sex']
df['class'] = le['class']
df['deck'] = le['deck']
df['alone'] = le['alone']
df['embark_town'] = le['embark_town']
df.head()
데이터 분류 -> (입력 인자가 2개일때)
이 문제는 라벨이 데이터 내부에 있기 때문에 분리해줘야합니다
이때 입력 인자의 구성에 의해 정확도가 달라지는지 알아보기 위해 입력을 2개, 전부 사용하기로 나눠서 모델링을 해봅니다
df_y = df.pop('survived')
df_x = df.loc[:,['age', 'fare']].copy()모델링을 하기 위한 데이터 셋 분리
훈련 / 검증 / 테스트로 나눠서 일반화에 적합하게 데이터를 분리합니다
검증은 나중에 훈련에서 분리하게 됩니다
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, test_size=0.2, random_state=42)
print(f'train dataset : ${x_train.shape} /// ${y_train.shape}')
print(f'test dataset : ${x_test.shape} /// ${y_test.shape}')x_train dataset : (501,2)
x_test dataset : (126,2)
y_train dataset : (501)
y_test dataset : (126)
모델링
model = Sequential()
model.add(Input(shape=(2,))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
컴파일, 훈련, 평가
이제 모델을 만들었으므로 컴파일하고 실제 데이터를 넣어 훈련을 해봅니다
그리고 평가를 해서 결과를 확인합니다
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=5, batch_size=1, validation_split=0.2)loss, accuracy = model.evaluate(x_test, y_test)
print(f'loss : ${loss})
print(f'accuracy : ${accuracy})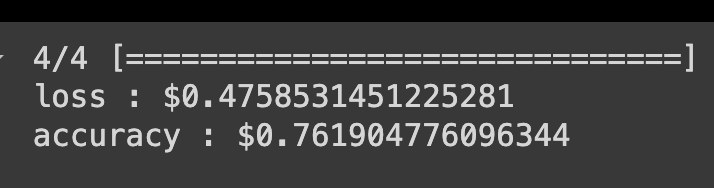
데이터 분류 -> (입력 인자가 9개일때)
이제는 가지고 있는 피처를 전부 사용해서 모델링을 해봅니다
df_x = df.copy()
df_y = df_y.copy()
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, test_size=0.2, random_state=42)
model = Sequential()
model.add(Input=shape(9,))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
callback_EarlyStopping = EarlyStopping(monitor='val_loss', patience=5, verbose= 0)
history = model.fit(x_train, y_train, epochs=5, batch_size=1, validation_split=0.2, callbacks=callback_EarlyStopping)
loss, accuracy = model.evaluate(x_test, y_test)
print(f'loss : ${loss}')
print(f'accuracy : ${accuracy}')결과
2개를 사용한 것보다 9개의 피처를 전부 사용하여 만든 모델이
정확도가 더 정확하고 오차가 더 적어서 상세하게 데이터를 넣는게 훨씬 향상 시킨다는 것을 증명했습니다
피드백
데이터 분석을 하는 것에 대해 더 집중하고
각 데이터에는 어떻게 모델을 만들면 좋은지 공부해봐야 할거 같습니다