드디어 네이버 pre-course에 있는 내용을 1회독 했다
이제 시작이니까 지금부터는 내용들 다시 들어보고 + 블로그 상세히 찾아보면서
기본을 탄탄하게 만들자!!
오늘 배운내용인 LSTM을 이해하기 위해 Sequence(data의 특징)와 RNN(모델)을
이해해보자!

Sequence
말그대로 순서가 있는 data를 시퀀스라고 한다
ex) 음성,영상, 문장 등 순서와 함게 흘러가는 데이터를 뜻한다
이 연속적인 데이터를 다루는 프로그램들(모델) -> RNN, GRU, LSTM
기존의 data들과 차이점
기존의 모든 inputs들이 독립적이라 가정했다
하지만 이전의 정보가 의미가 있는 순서적 정보에는 달라짐!!
순차적으로 과거정보를 반영할 수 있는 모델이 필요!
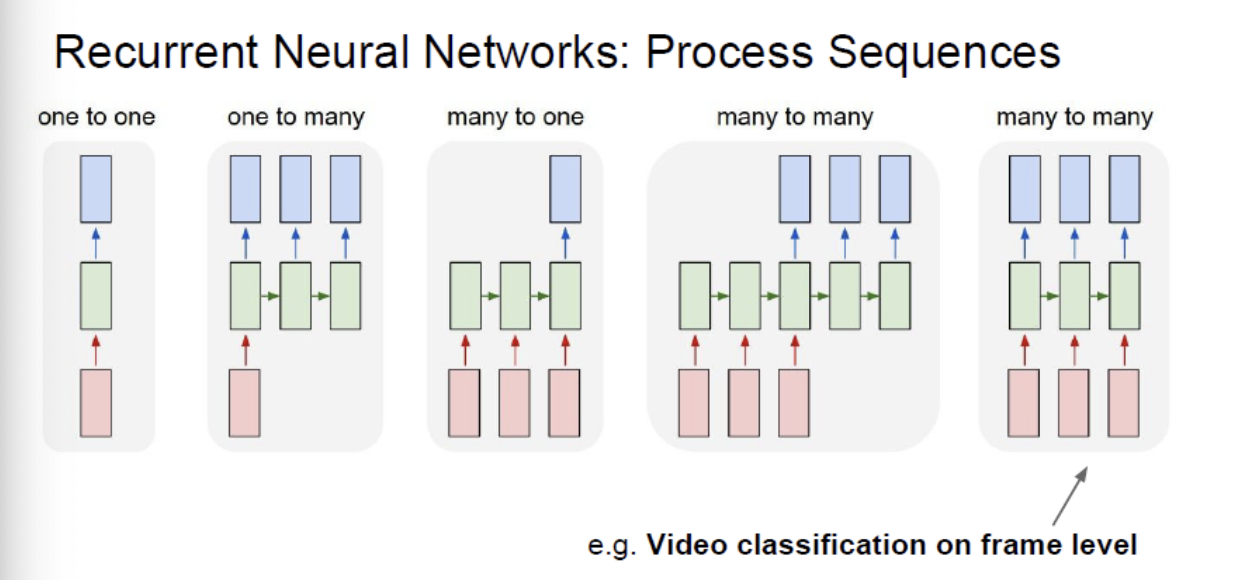
sequence model의 종류
- one to many
- image Captioning: image -> sequence of words
이미지 데이터에서 설명글을 출력할 수 있다
- many to one (주로 알아야하는 파트)
- sequence of words -> sentiment
텍스트에서 감정이 긍정적이냐 부정적이야 분류 등
- many to many (encoder -> decoder)
- sequence of words -> sequence of words
영어문장을 한국어로 번역하기
- many to many
- Name entity recognition(개체명 인식)
TEXT에서 언급된 사람,회사등의 개체를 인식하여 출력
RNN
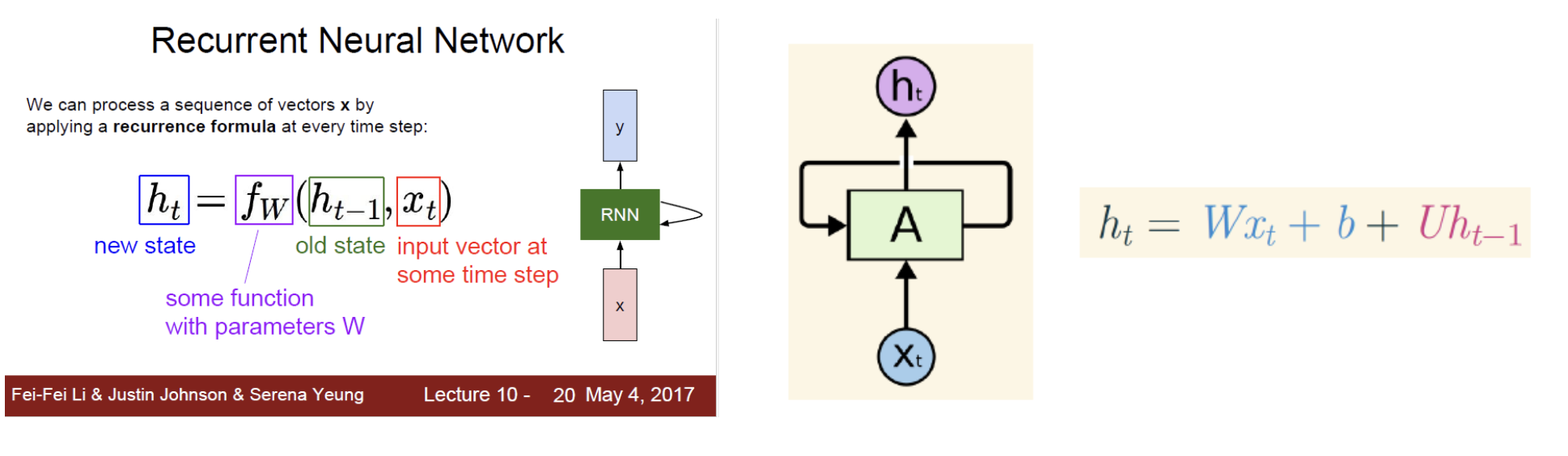
RNN의 과정
-
input
우선 시퀀스 데이터 즉 정보는 백터로 표현되어 model에 input된다!
(가령 TEXT인 경우는 벡터로 표현하기 위해 Word embedding이라는 작업을 한다) -
state
input인 백터(가공된 정보)는 순서(timestep)에 따라 순환 신경망의 상태에 저장됩니다
이 상태는 함수로 변형될수있다
즉 함수(f)는 파라미터W(가중치)와 이전상태(old state), input로 구성되어 있습니다 -
update
그리고 W가 튜닝되면서 계속 발전해나감 -
output
그리하여 매 timestep마다 새로운 인풋이 들어오면서 다른 반응 결과를 출력!
이를 통해 다른 timestep에서 다른 예측을 하는것이 가능!
RNN의 특이사항
매 timestep마다 동일한 function과 동일한 parameters(개수) 사용되어야한다!
input,output size에 영향을 받지않고 무관하게 적용가능하게 되어짐
RNN의 단점
개념 이해
RNN은 출력과 먼 위치에 있는 정보를 기억할 수 없다!!
즉 RNN은 최근의 정보일수록 더 예측에 반영할 수 있게 설계되어있다
Short-term-Dependencies라는 뜻
예를 들어 ) "I grew up in France, I speak fluent French"
이 French라는 부분을 예측하기 위해서는 훨씬 이전단어로부터 context파악해야함
이를 위해서는 Long-term-dependencies가 필요하다!
RNN의 수식적 이해
RNN은 입력정보와 그 입력정보를 사용하려는 출력지점 거리가 멀 경우 역전파 할 시 기울기가 점차 줄어지든가 커져서 학습능력이 저하됩니다.
(역전파시 기울기가 전 층 기울기와 계속 곱하는 연산으로 구해지기 떄문. 즉 출력층의 기울기가 만약 0.9면 입력층 쪽은 0.9 0.9 0.9 ... 이런 연산이 적용이 됨. )
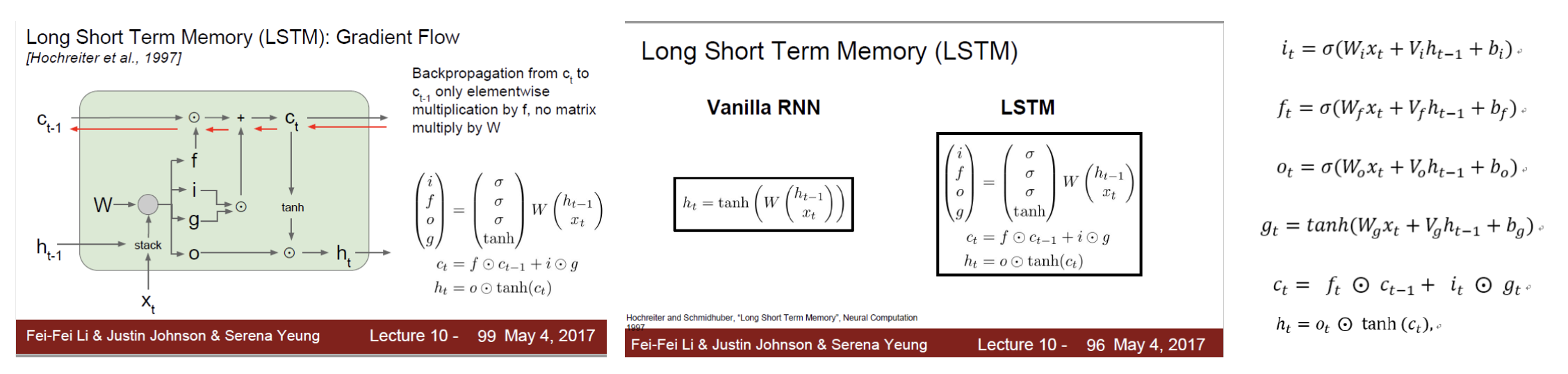
LSTM
오래전 혹은 최근의 단어들을 기억할 수 있는 아키텍쳐가 LSTM이다
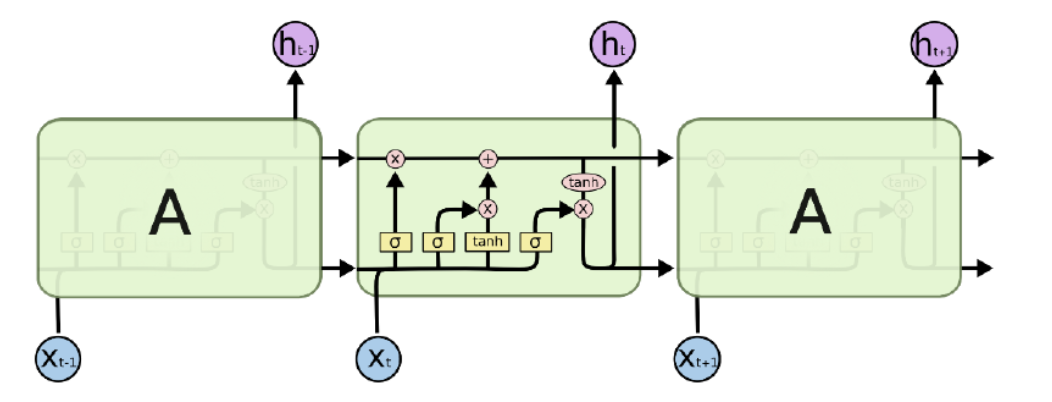
구성하는 부분 역할
1. Cell state역할
정보를 기억(저장)하는 역할이다
- 3개의 gate의 역할
정보가 추가되고 제거되는것을 조정하는 역할
Cell state + 3개 gate의 역할
기억도 잊을 것은 잊고, 저장할 것은 저장하도록 한다.
왜냐하면 Cell은 용량이 있다.
중요한 정보만 기억하는 것이 효율적이다.
LSTM 과정
input: RNN과 동일하다
우선 데이터 즉 정보는 벡터로 표현되어 model에 input된다
state: RNN과 이게 다름!!
cell state가 추가되었다
즉 LSTM의 state는 hidden state와 cell state 총 2개임
input인 벡터가 순서에 따라 이전상태와 함께 현재 상태(hidden state)에
저장되기 앞서 기억상태가(cell state)가 참전하는 처리과정을 겪는다!
이 처리과정헤서는 3개의 gate(i,f,o)가 cell state의 참전(활성화)여부를 결정합니다
update와 output 모두 RNN과 동일합니다
LSTM의 핵심: cell state함수 -> hidden state
각각의 부분을 설명하기 위해 저렇게 사진을 캡쳐해서 가져왔다...
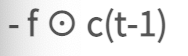
기존의 정보를 얼마나 잊어버릴 것인가?
f(forget gate)는 과거 정보를 잊기위한 게이트
h(t-1)와 x(t)를 받아서 시그모이드를 취해준 값이 forget gate가 내보내는 값입니다
출력범위가 0에서 1사이이기 때문에 값이 0에 가까우면 이전 이전사앹는 거의 잊는것이고 1이라면 이전상태의 정보를 많이 기억!

새로운 정보를 얼마나 기억할 것인가?
h(t-1)와 X(t)를 받아서 시그모이드를 취해준 값과 같은 입력의 tanh를 취해준값을
inner product연산해서 input gate를 통해 내보내줌
i값의 범위: 0~1
g값의 범위: -1~1
i의 의미는 현재 cell state를 얼마나 포함시켜줄거냐
g의 의미는 새로운 정보를 의미 -1~1사이의 정보를 추출, RNN에서 정보 추출과 같다
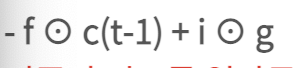
기존의 정보를 얼만큼 잊고, 새로운 정보로 얼만큼 대체 할 것인가?
생존해있는 old cell state(c(t-1))에 얼마만큼 i ⊙ g를 더해주겠냐!!!