저번에 팀으로 딥러닝 미니 프로젝트를 진행하면서 데이터분석이 얼마나 중요한지
맞아가면서 배웠기에 강의를 보고 이해한 내용들을 정리해보려고 합니다

이건 어제 playground의 AI를 이용해서 만든 공룡입니다^^
이번 정리에서 사용하는 테이블입니다.
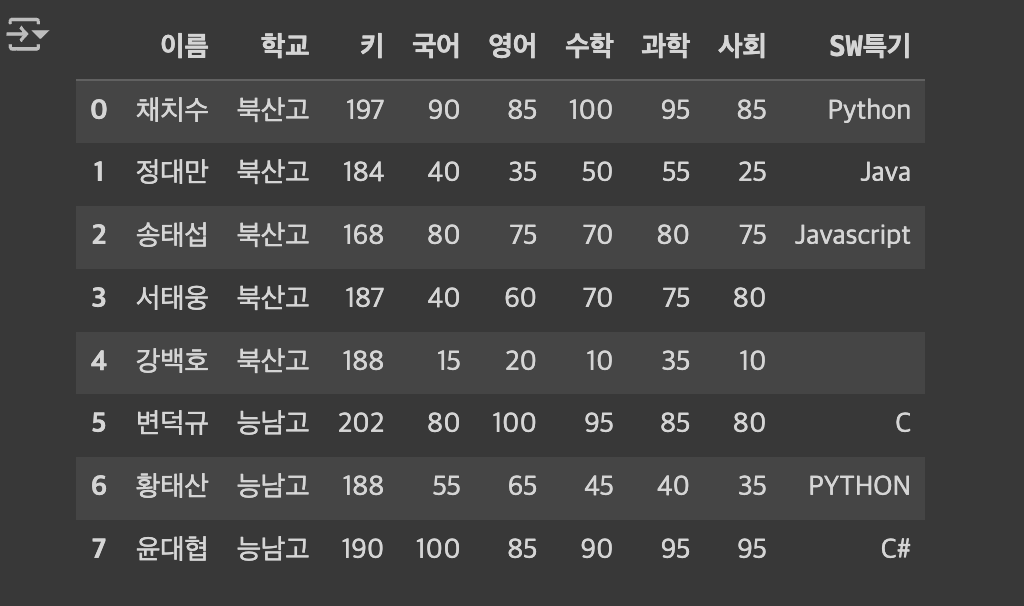
직접 데이터 선택
데이터분석을 하다보면 테이블에서 우리가 원하는 데이터만을 추출해야할때가 있습니다
이때 인덱스의 이름이나 숫자로 원하는 데이터를 가져올 수도 있는데요
쉽게 원하는 데이터를 가져올 수 있는 loc와 iloc(integer + loc 인듯?) 방법이 있습니다
loc
loc는 인덱스명 + 칼럼명을 사용해서 내가 원하는 데이터를 추출하는 방식입니다.
df.loc[1] # 이러면 인덱스 1번인 데이터가 추출됩니다
df.loc[1,'국어'] # index 1번의 국어 점수가 추출됩니다
df.loc[[1,2], ['영어', '수학']] # index 1,2번의 영어와 수학 점수가 나옵니다
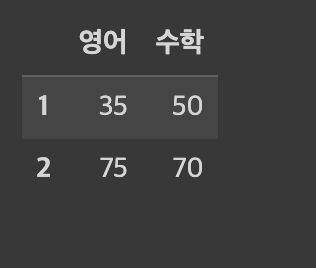
iloc
iloc는 우리가 정확한 칼럼 명을 모르거나 적기 너무 길때 사용하면 편한 방식입니다
위와 가져오는 방식은 같지만 데이터를 부를때 위치를 불러서 가져옵니다
df.iloc[0] #0번째 위치의 인덱스내용 가져옴, 채치수 정보
df.iloc[0,1] # 0번째 인덱스의 1번째 칼럼을 가져옴 -> 채치수의 학교정보
df.iloc[0:5, 3:8] # 0~4인덱스의 3:7번째 칼럼 내용을 가져옵니다!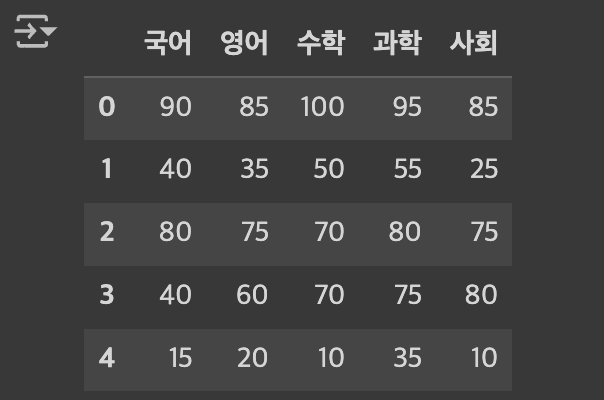
조건에 맞는 데이터 가져오기
키가 185이상인 학생들의 정보만 가져오고 싶거나, 학교가 북산고인 학생들만 알고 싶다면
위의 loc에 조건을 적용해보면 됩니다
df.loc[df['키'] >= 185, '이름'] # 키가 185이상인 학생들의 이름을 가져옵니다원하는 조건이 2개 이상이거나 and,or을 사용이 필요해도 loc를 사용하면 됩니다
df.loc[ (df['키']>=185) & (df['학교'] == '북산고') ]
df.loc[ (df['키']>=200) | (df['키'] < 165), ['이름', '키'] ]결측치
결측치는 NaN, 즉 없는 값을 의미합니다.
이런 데이터는 학습을 하는데도 방해를 해서 삭제나 평균값으로 채우기, 최빈값으로 채우기 등으로 대체합니다
NaN값을 원하는 데이터로 대체하기
df.fillna('없음', inplace=True) # NaN값이 없음으로 대체됩니다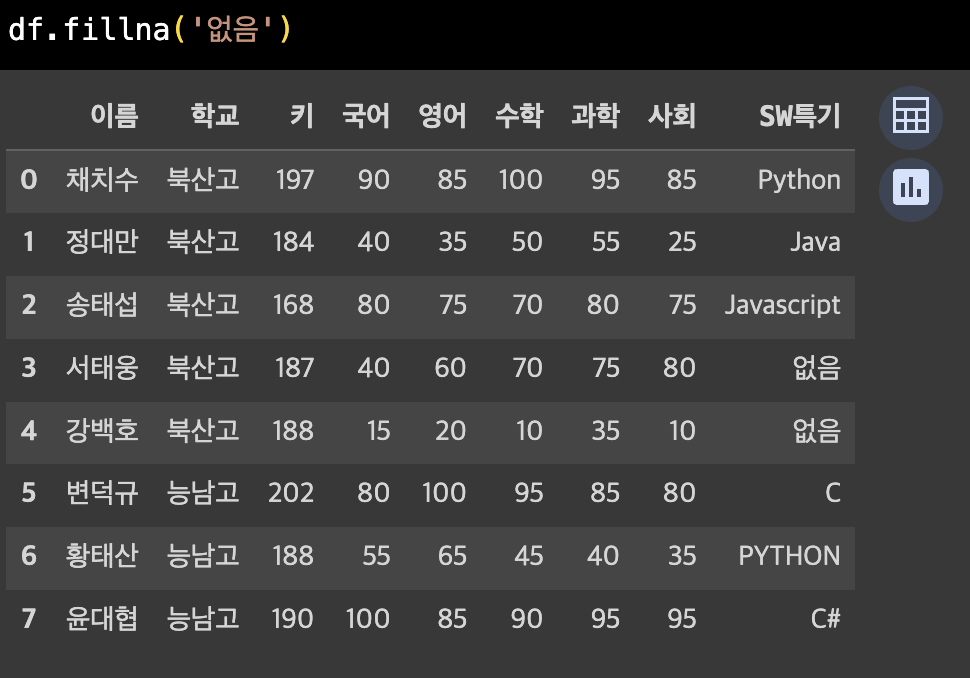
NaN값을 제거하기
df.dropna()
df.dropna(axis='columns', how='all') # 해당 칼럼이 전부 NaN이면 그 칼럼을 삭제!
df.dropna(axis='index', how='any') # 해당 인덱스에 NaN이 있으면 그 index삭제!
SW로 문제를 해결하려는 열정만 있는 대학생