견종분류, 타이타닉, 손글씨, 상추분석 등 몇개의 AI 모델을 만들어보면서
하나의 의문이 생겼었는데요.
AI Model을 실제 프로젝트에서 활용해서 만들어보고 싶다...!!!
이제는 AI 개발에 돈을 투자하는 흐름에서 AI를 이용해 서비스를 만드는게 트렌드라 하여 흐름에 타보기로 했습니다
AI & 머신러닝 & 딥러닝
항상 헷갈리는 3대장 ai, 머신러닝 그리고 딥러닝을 다시 한번 복습겸 적었습니다.
AI
인간처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술입니다.
지금까지의 컴퓨터는 우리가 정해진 입력과 과정(함수)을 적으면 => 결과를 출력해줍니다.
하지만 이제는 이 컴퓨터가 스스로 학습하고 새로운 입력에 대한 결과를 내줍니다.
머신러닝
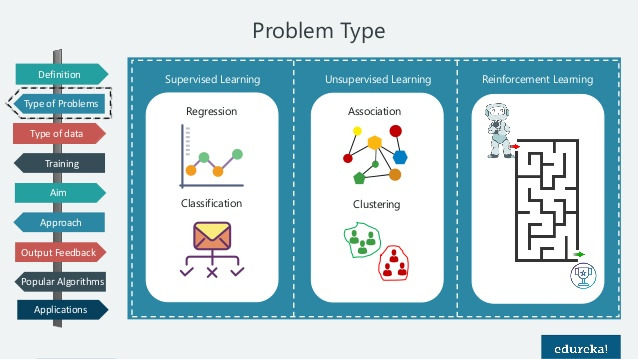
데이터를 학습시켜서 데이터 내 패턴을 찾아내서 새로운 데이터를 예측하거나 분류하는 ai의 한 분야
- 지도 학습
- 입력과 정답을 알려줌
- 분류 이진분류 다중분류 - 스펨메일 구분
- 회귀 - 데이터들의 feature를 기준으로 패턴이나 트렌드 경향을 예측, 집값 예측- 비지도 학습
- 정답이 없는 데이터를 학습시킴 - 비슷한 특징끼리 군집화
- 라벨링 없는 데이터의 패턴이나 형태를찾아야하는것 -> 과일 사진이 있고 바나나끼리 사과끼리 군집화- 강화 학습
- 행동에 대한 보상으로 학습을 시키는 개념 - 게임의 규칙이 없는채로 높은 점수를 찾아가게 행동함
딥러닝
머신러닝의 한 하위 분야로, 복잡한 문제를 해결하기 위해 대규모 신경망을 사용하는 방법.
- 인공신경망의 층을 연속적으로 쌓아올려 데이터를 학습합니다.
- 다층 구조 (Deep Neural Networks): 여러 층의 뉴런으로 구성된 신경망을 사용하여 복잡한 데이터 표현을 학습.
- 비선형성 학습: 단순한 머신러닝 모델보다 더 복잡한 비선형 관계를 학습 가능.
손글씨 이미지 처리란
그러면 이제 손글씨 이미지처리가 뭔지 찾아보고 어떠한 모델을 사용했는지 적어보겠습니다.
아래 보이는 글씨를 -> I Love You로 텍스트로 변환해주는것을 의미합니다.
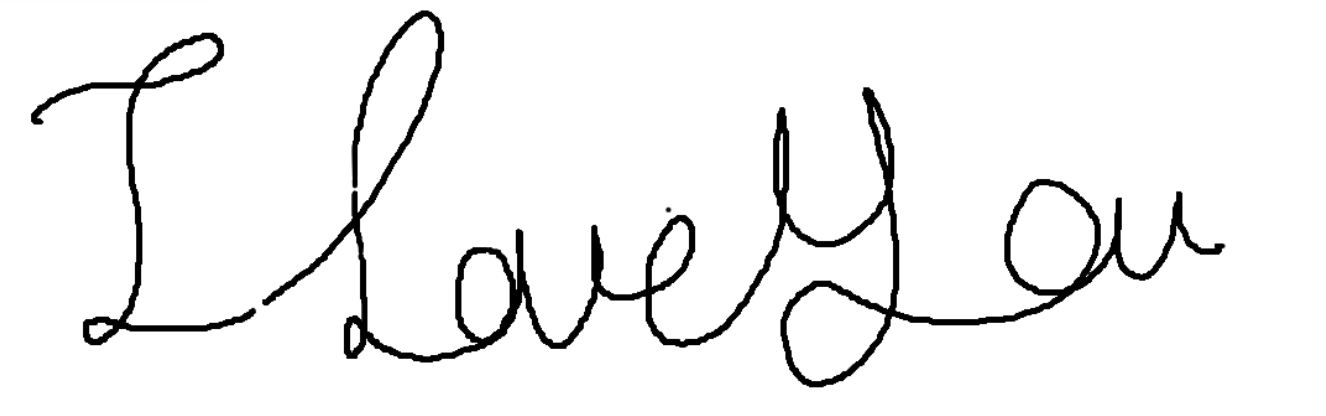
이미지를 변환해보자 -> OCR 사용
- 이미지속에 들어있는 문자를 컴퓨터가 인식할 수 있는 디지털 숫자로 변환해주는 기술입니다.
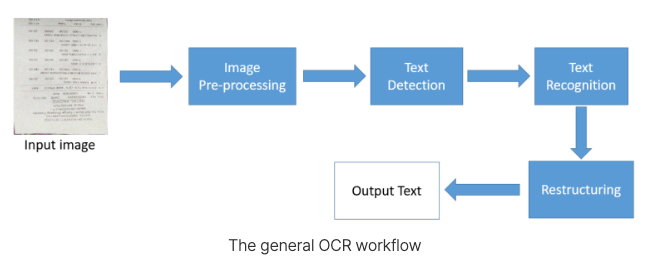
OCR의 변환 과정
- 이미지 입력: 텍스트가 포함된 이미지를 입력.
- 이미지 전처리: 텍스트를 더 쉽게 인식할 수 있도록 이미지 품질 개선.
- 텍스트 탐지: 이미지에서 텍스트가 포함된 영역을 식별.
- 문자 분할: 텍스트 블록을 개별 문자로 나눔.
- 문자 인식: 각 문자를 디지털 텍스트로 변환.
- 결과 출력: 변환된 텍스트를 저장하거나 출력.
선정한 모델
만든 모델보다 성능이 뛰어나고 더 빠르게 응답을 전달해주는 MS의 TrOCR을 사용했습니다.
Transformer 아키텍처를 기반으로 합니다.
Transformer는 2017년 논문 딥러닝 모델 아키텍처로, 주로 자연어 처리(NLP)와 컴퓨터 비전(CV) 작업에서 사용됩니다.
이 모델은 Self-Attention 메커니즘을 기반으로 하며, 순차적인 계산이 필요 없어서 병렬 처리가 가능하다는 장점이 있습니다.
입력 데이터를 Encoder에서 고차원 표현으로 변환하고, Decoder를 통해 원하는 출력으로 변환하는 구조를 가지고 있습니다.
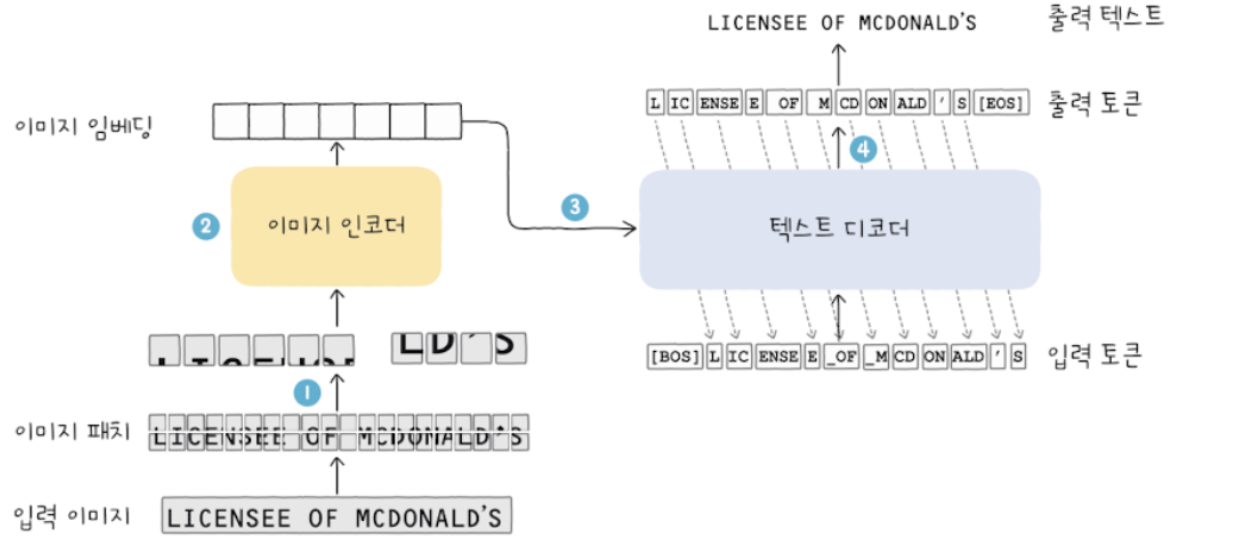
- 손글씨 이미지 입력 -> 작은 부분으로 나눈 조각들인 이미지 패치를 입력값으로 받음
- 인코더는 이미지 패치를 저차원 벡터 정보로 변환 -> 임베딩 정보
- 이게 이제 텍스트 디코더 입력값으로 들어감
- 이미지 임베딩 정보를 기반으로 토큰을 순차적으로 출력
손글씨 Backend 사용법 및 코드 분석
현재 백엔드부분은 GCP의 VM 인스턴스로 만들어서 배포해놓은 상태입니다.
추가로 현재는 돈이 나가지 않게 매번 정지하고 키는 방식으로 서버를 운영중입니다
계속 꺼놓으면 기본이 48원이 나간다는 새로운 사실을 알았습니다..!!1
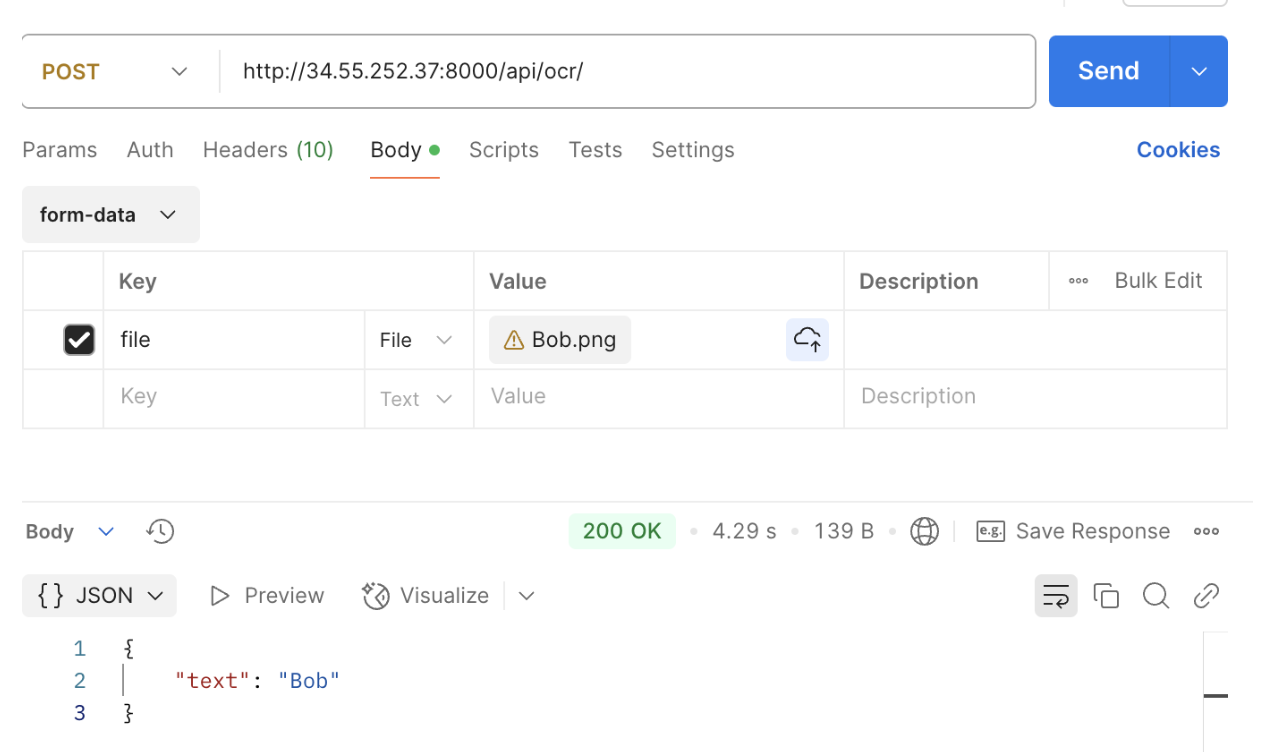
Postman으로 api test
기본적으로 image의 key에 file을 작성하고 이미지 파일을 업로드 합니다.
이때 Content-Type이 multipart/form-data 여야합니다.
현재 다양한 이미지들 Test결과
텍스트 없는 이미지 -> 걸러짐 (400에러)
텍스트 있는 이미지 -> 안걸러짐 뭔가 나옴...(이걸 막는게 쉽지않다;;)
손글씨 -> 진짜 잘나옴(너무 잘나와서 감동...)
EasyOCR로 텍스트 없는 이미지의 오류를 검출하자!
텍스트가 이미지에 있는지 감지할 수 있는 OCR라이브러리입니다.
역할
이미지를 Numpy 배열로 변환 후 텍스트 존재하는지 판단
코드의 플로우
이미지 업로드:
- 클라이언트가 이미지를 업로드하면, UploadFile 객체로 받습니다.
- 텍스트 존재 여부 확인:
- EasyOCR을 사용하여 이미지에 텍스트가 포함되어 있는지 확인.
- 텍스트가 없다면 오류 응답 반환.
- 손글씨 텍스트 추출:
- TrOCR 모델을 사용하여 손글씨를 분석하고 텍스트를 추출.
- 추출된 텍스트를 JSON으로 반환
import os
from PIL import Image
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from fastapi import FastAPI, UploadFile
from fastapi.responses import JSONResponse
from fastapi.middleware.cors import CORSMiddleware
import cv2
import numpy as np
import easyocr # EasyOCR 라이브러리
# FastAPI 앱 생성
app = FastAPI()
# CORS 설정
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# TrOCR 모델 초기화
class TrOCRInferencer:
def __init__(self):
print("[INFO] Initialize TrOCR Inferencer.")
# 손글씨 모델
self.handwritten_processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
self.handwritten_model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
# EasyOCR 리더 초기화
self.ocr_reader = easyocr.Reader(['en'], gpu=False) # 'en'은 영어만 지원 (다른 언어 추가 가능)
def inference_handwritten(self, image: Image) -> str:
pixel_values = self.handwritten_processor(images=image, return_tensors="pt").pixel_values
generated_ids = self.handwritten_model.generate(pixel_values)
generated_text = self.handwritten_processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
return generated_text
def contains_text(self, image: Image) -> bool:
"""EasyOCR을 사용하여 텍스트 감지"""
# 이미지를 NumPy 배열로 변환
image_np = np.array(image)
results = self.ocr_reader.readtext(image_np)
# 텍스트가 감지되었는지 확인
if len(results) > 0:
return True
return False
## 인퍼런서 초기화
inferencer = TrOCRInferencer()
@app.post("/api/ocr/")
async def image_to_text(file: UploadFile):
try:
image = Image.open(file.file).convert("RGB")
# 이미지에 텍스트가 포함되어 있는지 확인
if not inferencer.contains_text(image):
return JSONResponse({"error": "이미지에 텍스트가 없습니다."}, status_code=400)
# 손글씨 분석
text = inferencer.inference_handwritten(image)
return JSONResponse({"text": text}) # JSON 응답 반환
except Exception as e:
return JSONResponse({"error": str(e)}, status_code=500)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)피드백
이번에 만들면서 VM에 배포한 방식은 최적의 방식은 아니었겠다는 생각이 들었습니다.
현재는 GPU가 아닌 CPU를 사용하고 있어서 GPU 사용보다는 확실히 30초 이상 차이가 납니다
vm을 GPU로 만들면 숨 쉴때마다 커피값이...
그렇기에 현재 내가 할 수 있는 선에서 최대한 노력을 해보고
그거에 대해 완벽한 이해를 하고 만들었다를 강조해야겠습니다!!
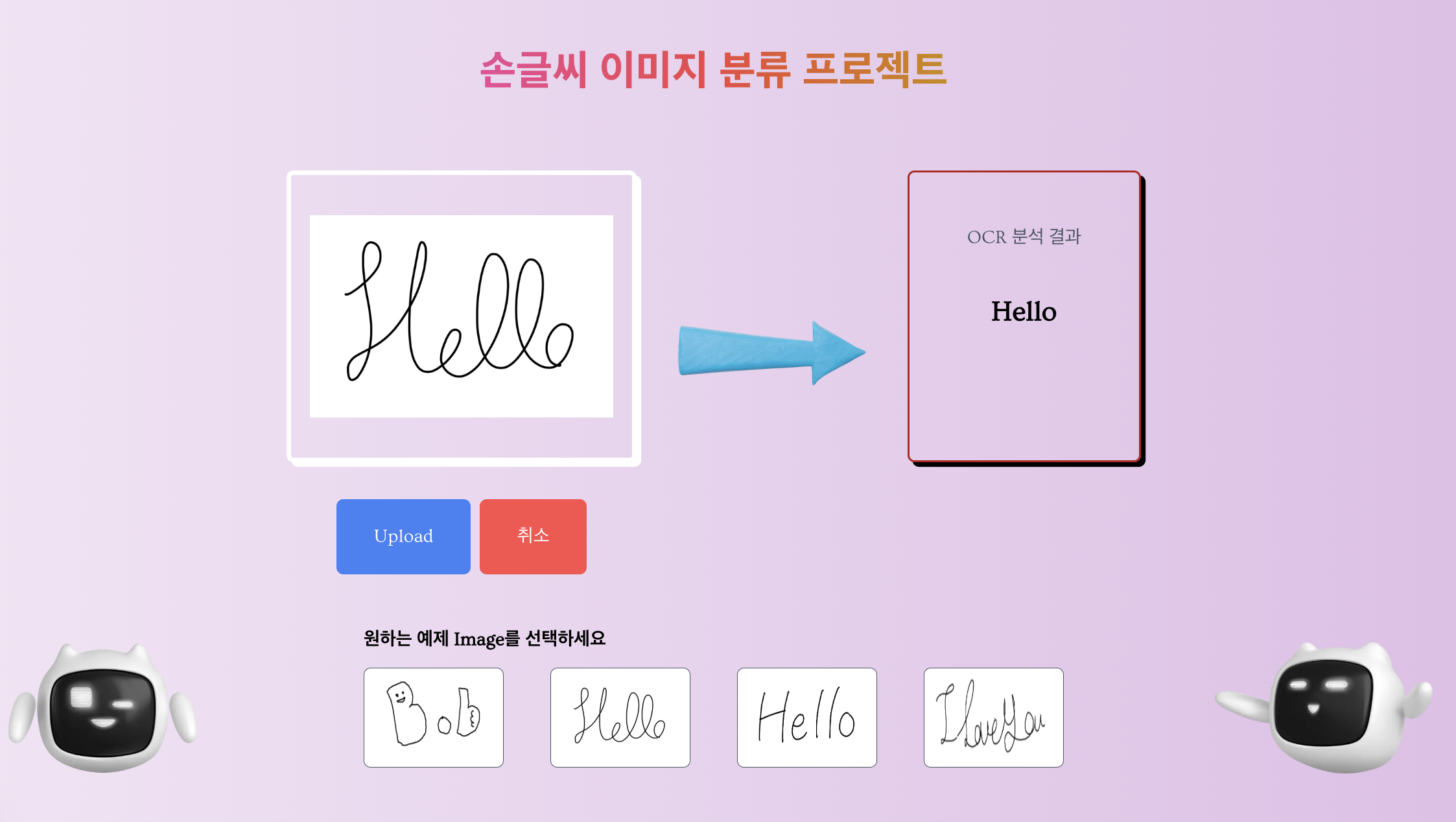
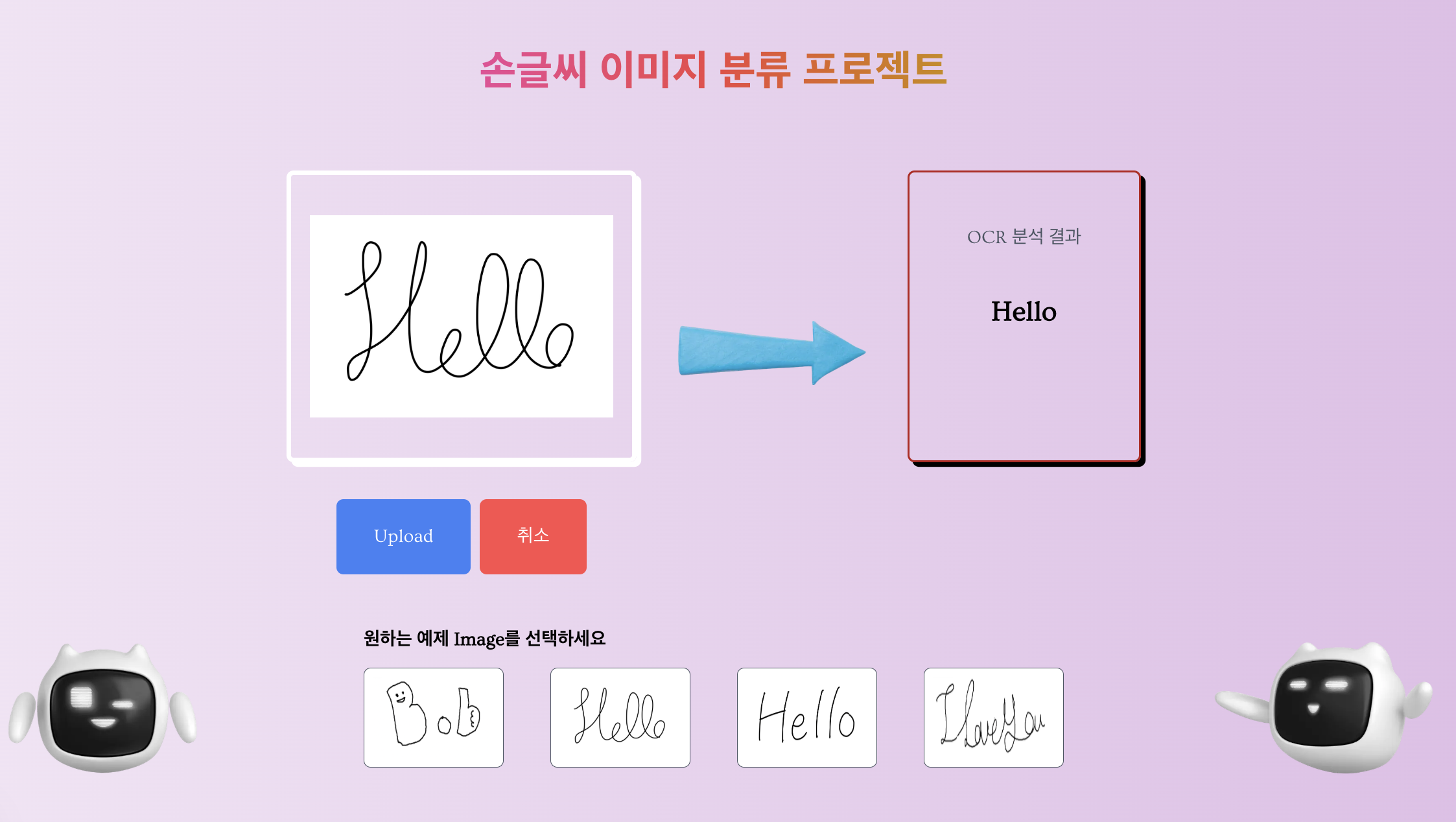
미리 UI를 스포하면(?) 이러한 구조로 작성을 했습니다
저 로봇이 motion으로 통통 튀는게 킬포인트!!