2013년 9월 유럽 신용카드 사용자들이 사기 거래를 당했는지 알려주는 예측 모델을 만들었습니다.
캐글에서 코랩에 데이터 가져오는 법!
이건 저번 블로그 적을때도 적었지만 자주 잊어먹어서 한번 더 작성했습니다.
!pip install kaggle # kaggle 설치
from google.colab import files # kaggle.json 가져오기
files.upload()
ls -1ha kaggle.json # kaggle.json 제대로 가져왔는지 확인
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/ # kaggle.json 위치 옮기기
# Permission Warning 방지
!chmod 600 ~/.kaggle/kaggle.json # 권한 설정
# 캐글에서 원하는 데이터를 가져오기 및 압축 풀기
!kaggle competitions download -c big-data-analytics-certification-kr-2024-2
!unzip /content/big-data-analytics-certification-kr-2024-2.zip문제 정의
이 문제는 2013년 유럽의 해당 카드 사용자들이 카드 사기거래를 당했는지 예측하는 AI 모델을 구성하는 문제입니다.
사기의 경우 1, 아니면 0으로 출력해서 submission을 캐글에 제출하면 됩니다.
데이터 이해 및 분석(EDA)
사실 빅데이터 기사 실기 문제여서 데이터가 좀 작고 아담(?)할 줄 알았는데 생각보다 꽤나 양이 많았다;;
import numpy as np
import pandas as pd
train = pd.read_csv("/content/train.csv")
test = pd.read_csv("/content/test.csv")
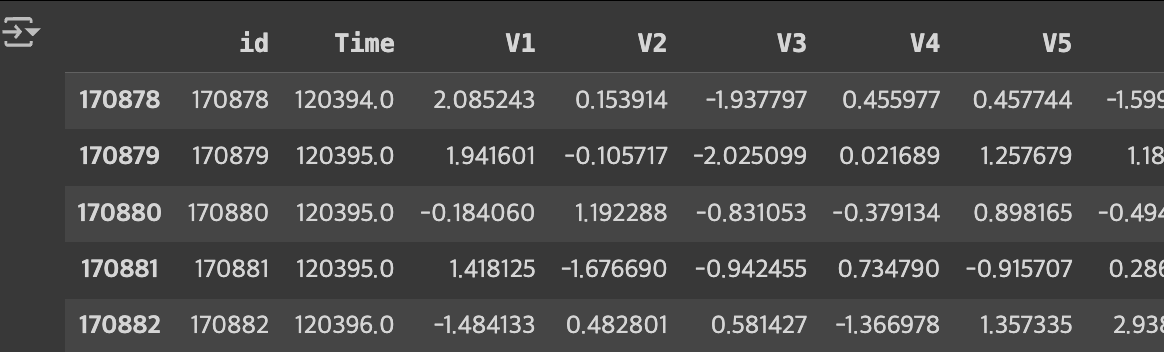
train.tail()약 17만개 정도의 훈련 데이터가 존재합니다
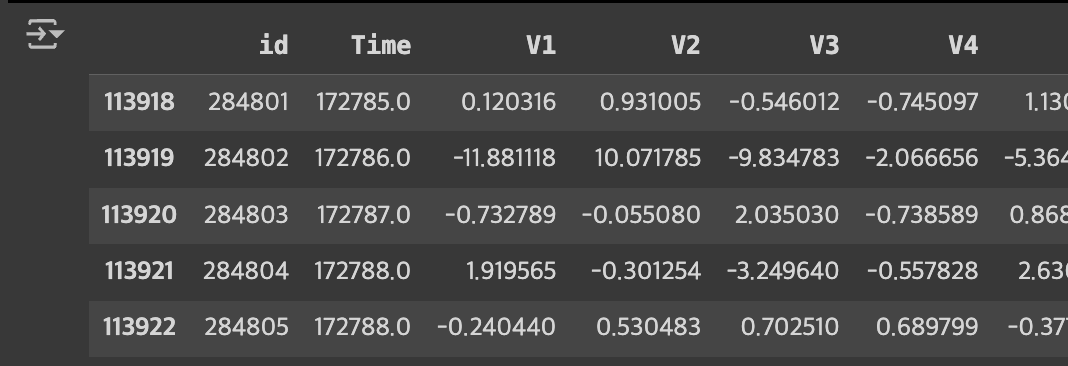
테스트 데이터는 약 11만개 정도 존재합니다.
칼럼이 나타내는 의미 및 분석 - 속성들
- Class가 1이면 사기, 0이면 아님
- Amount는 거래 금액
- V1...V28은 PCA를 거친 주성분
- Time은 거래 경과시간(초)
- train shape : (170883, 32)
- test shape : (113923, 31)
이 문제에서 label은 Class 속성을 의미합니다.
print(train['Class'].value_counts())- Class
0 => 170523
1 => 360
데이터 전처리
전처리에서는 대표적으로 결측지와 이상치를 확인해야합니다.
결측치 존재 여부 확인 => 일단 결측치는 존재하지 않습니다
print(train.isnull().sum())
print(test.isnull().sum())
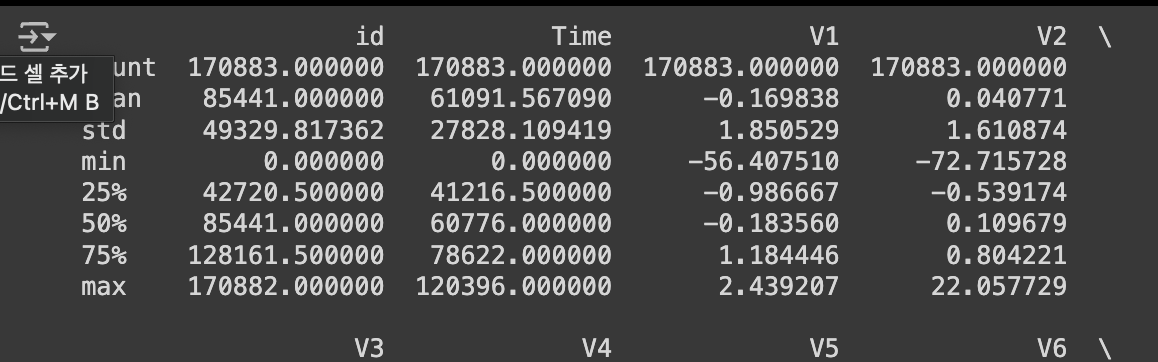
이상치 및 현재 분포도 확인
print(train.describe())
print(test.describe())min과 max의 차이가 각 속성마다 크게 나서 줄여주는 scaling을 해주어야 한다는 것을 알 수 있습니다.
label분리 및 스케일 조정
일단 먼저 label을 분리했고, id는 필요 없기 때문에 제거했습니다.
나중에 submission에서 test내 id가 필요하기 때문에 이건 따로 저장해두었습니다.
target = train.pop('Class')
test_id = test.pop('id')
train = train.drop('id', axis=1)이제 RobustScaler를 사용해서 각 속성에 대한 스케일링을 중앙값과 사분위수 범위에 맞게 조절했습니다.
StandardScaler가 아닌 RobustScaler를 사용한 이유
StandardScaler의 경우 평균 0, 표준편차 1로 스케일링하기 때문에 이상치에 영향을 받습니다.
하지만 Robust는 위 말처럼 중앙값과 4분위수를 이용하기 때문에 이상치가 있을때 효과적입니다!
고로 RobustScaler는 이상치가 많을때 가져다 사용하자!
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
columns = train.columns
for c in columns:
train[c] = scaler.fit_transform(train[[c]])
test[c] = scaler.transform(test[[c]])이제 시각화를 해서 실제로 스케일링이 제대로 되었는지 확인해보면 됩니다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(8,6))
sns.boxplot(x=train['V2'])
plt.title('Box Plot')
plt.show()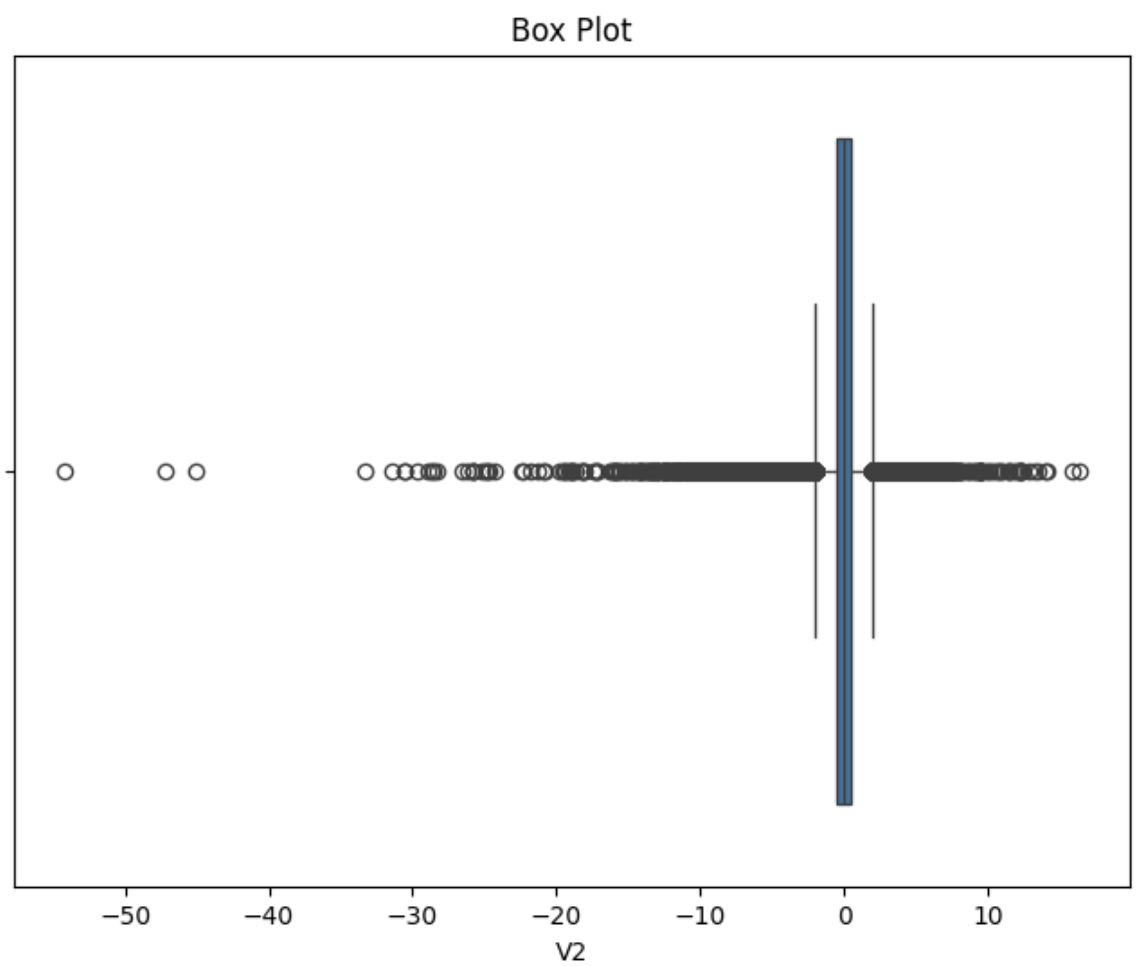
데이터 분리
from sklearn.model_selection import train_test_split
x_tr, x_val, y_tr, y_val = train_test_split(train, target, test_size=0.2, random_state=42)
print(x_tr.shape, y_tr.shape, x_val.shape, y_val.shape)(136706, 30) (136706,) (34177, 30) (34177,)
모델링 및 평가
모델링의 경우 분류 모델에 효과적인 RandomForestClassifier를 활용했습니다.
RandomForestClassifier가 분류에 왜 좋은지
- 단일 모델이 아닌 여러 모델을 만들어서 결정트리를 만들게 됩니다 -> 각 트리의 예측결과를 결합해 최종 결과를 도출합니다.
- 과적합 방지 -> 여러 트리의 예측을 결합하기 때문에 학습데이터에만 맞춰지는걸 방지할 수 있습니다.
- 이상치와 노이즈에 강함 -> 역시나 여러 트리가 협력하기 때문에 이상치에 덜 영향을 받습니다.
- 각 특정의 중요도를 측정해서 특성을 식별하고 선택 할 수 있습니다.
ex) 스팸 이메일분류, 고객이탈 예측, 이미지 분류, 의료 진단 등에서 활발하게 사용됩니다
from sklearn.ensemble import RandomForestClassifier
model1 = RandomForestClassifier()
model1.fit(x_tr, y_tr)
# 각 샘플이 각 클래스에 속할 확률을 제공함, 1에 속할 즉 사기거래 당했는지 확률을 구한다
pred = model1.predict(x_val)[:,1]
from sklearn.metrics import roc_auc_score
roc_auc_score(y_val, pred)
매우 높은 예측 결과가 나왔습니다!

피드백
이번 문제의 경우 캐글의 코드를 보고 작성한거라 결과가 높았습니다.
꼭 딥러닝만 고집하지말고 머신러닝으로 해결할 수 있는 문제는 머신러닝으로 해결하자!