이번 방학때 Google cloud & AI 수업을 듣고 AI를 이용한 서비스들을
여러개 실제로 만들고 포트폴리오겸 수익을 내보고 싶어서
쓸모있는 AI 서비스 만들기 책을 구매했다.
앞으로는 AI를 활용해 넓은 시야로 주어진 문제를 해결할 줄 아는 인재를 뽑는다는 말에 꽂혀서!!

손글씨 인식
일단 손글씨 인식을 하기 위해서는 알아야하는 단어가 몇가지 있습니다.
대표적으로 OCR, 인코더, 디코더가 있습니다
OCR이란?
이미지 속에 들어있는 문자를 컴퓨터가 인식할 수 있는 디지털 문자로 변환해주는 기술!
하지만 이건 많은 변수가 존재하는데요
ex) 폰트종류, 이미지 왜곡, 글자 크기, 명암 등에 따라 오류나 정확도에 문제가 생깁니다
우리 일상 속에 OCR 기술은 뭐가 있을까?
1. 신용카드 인식 서비스 -> 신용카드를 찍으면 자동으로 기입된다
2. 영수증 인식 서비스 -> 영수증을 찍으면 내부 숫자들과 글자를 인식합니다.
인코더와 디코더
인코더 - 이미지 표현을 압축할 수 있는 모델로 구성
중요한 특징 추출,고차원이미지 데이터 => 저차원 벡터표현으로 압축디코더 - 문자를 생성할 수 있는 모델
인코더의 저차원 벡터로 문자를 생성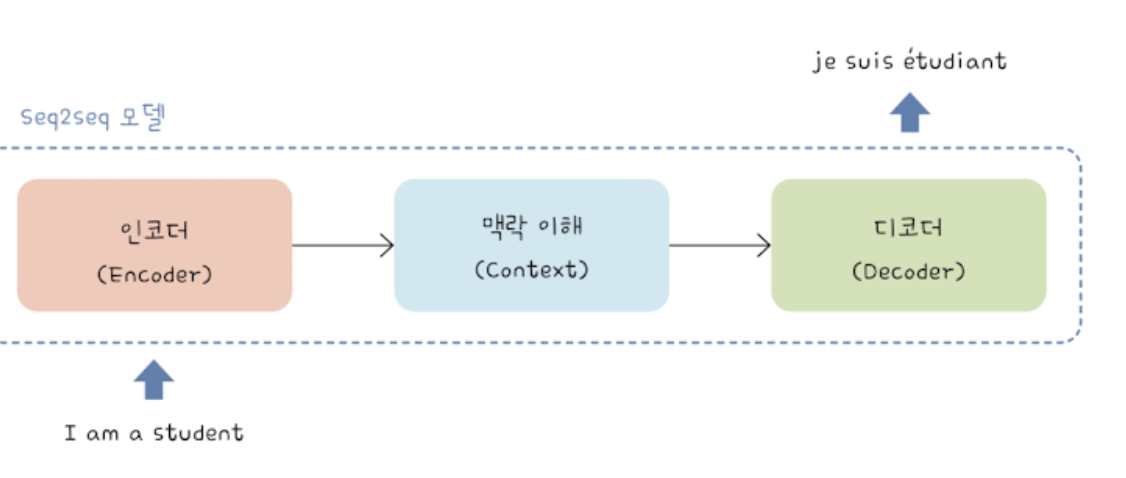
모델 선정 - 허깅페이스의 TrOCR
MS에서 공개한 트랜스포머 기반의 OCR 작업을 수행하는 인코더-디코더 모델
생각보다 정확도 떨어짐;; 글자가 클수록 인식을 잘했습니다...
파이썬코드 - 코랩에서 실행
import os
import gradio as gr
import numpy as np
from PIL import Image
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
# Implement inferencer
class TrOCRInferencer:
def __init__(self):
print("[INFO] Initialize TrOCR Inferencer.")
self.processor = TrOCRProcessor.from_pretrained(
"microsoft/trocr-base-handwritten"
)
self.model = VisionEncoderDecoderModel.from_pretrained(
"microsoft/trocr-base-handwritten"
)
def inference(self, image: Image) -> str:
"""Inference using model.
It is performed as a procedure of preprocessing - inference - postprocessing.
"""
# preprocess
pixel_values = self.processor(images=image, return_tensors="pt").pixel_values
# inference
generated_ids = self.model.generate(pixel_values)
# postprocess
generated_text = self.processor.batch_decode(
generated_ids, skip_special_tokens=True
)[0]
return generated_text
inferencer = TrOCRInferencer()
# Implement event function
def image_to_text(image: np.ndarray) -> str:
image = Image.fromarray(image).convert("RGB")
text = inferencer.inference(image)
return text
# Implement app
with gr.Blocks() as app:
gr.Markdown("# Handwritten Image OCR")
with gr.Tab("Image upload"):
image = gr.Image(label="Handwritten image file")
output = gr.Textbox(label="Output Box")
convert_btn = gr.Button("Convert")
convert_btn.click(
fn=image_to_text, inputs=image, outputs=output
)
gr.Markdown("## Image Examples")
gr.Examples(
examples=[
os.path.join(os.getcwd(), "examples/Hello.png"),
os.path.join(os.getcwd(), "examples/Hello_cursive.png"),
os.path.join(os.getcwd(), "examples/Red.png"),
os.path.join(os.getcwd(), "examples/sentence.png"),
os.path.join(os.getcwd(), "examples/i_love_you.png"),
os.path.join(os.getcwd(), "examples/merrychristmas.png"),
os.path.join(os.getcwd(), "examples/Rock.png"),
os.path.join(os.getcwd(), "examples/Bob.png"),
],
inputs=image,
outputs=output,
fn=image_to_text,
)
with gr.Tab("Drawing"):
sketchpad = gr.Sketchpad(
label="Handwritten Sketchpad",
shape=(600, 192),
brush_radius=2,
invert_colors=False,
)
output = gr.Textbox(label="Output Box")
convert_btn = gr.Button("Convert")
convert_btn.click(
fn=image_to_text, inputs=sketchpad, outputs=output
)
# App 실행
app.launch(inline=False, share=True)결과
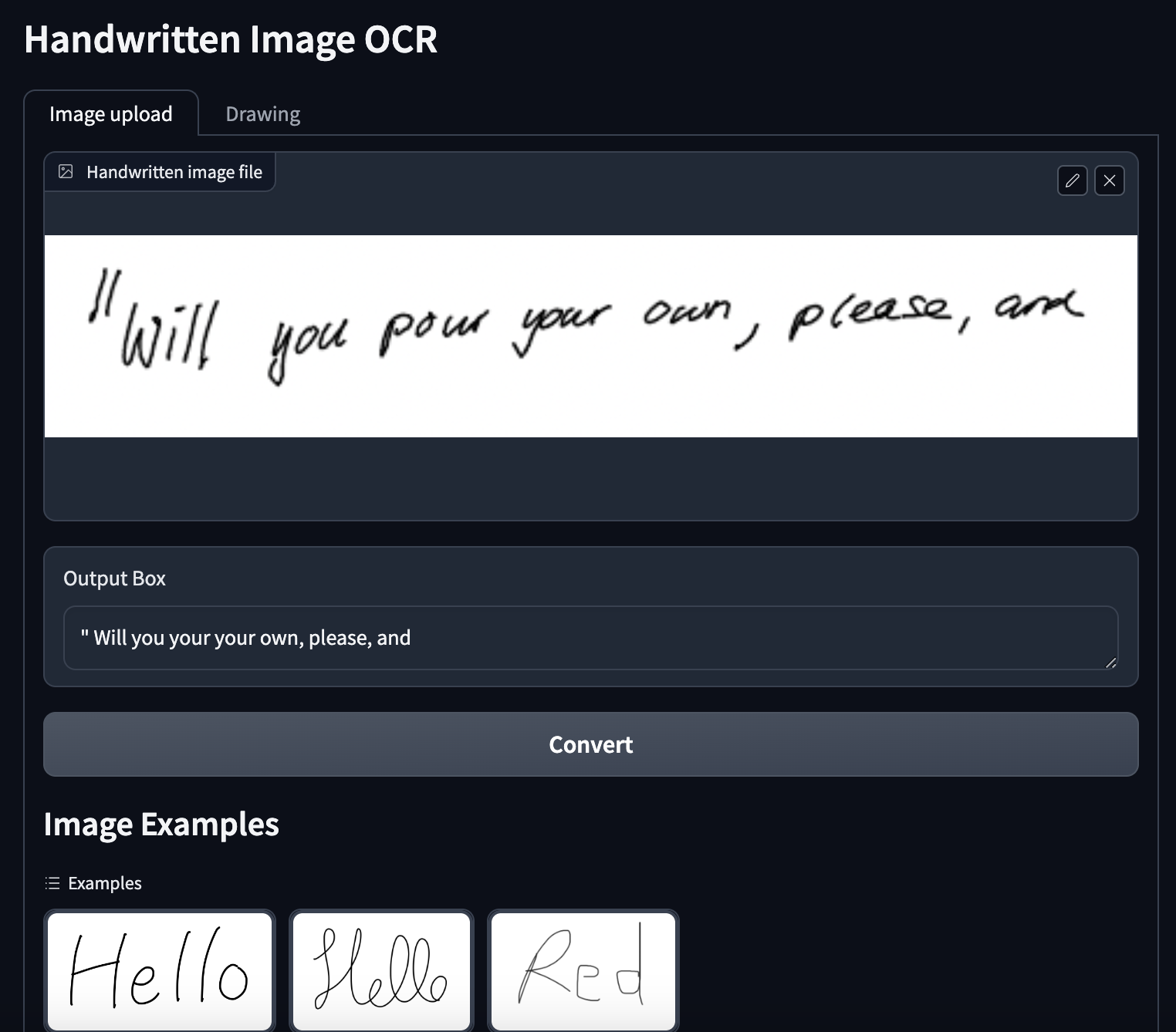
글자가 크면 인식을 잘한다 -> 이미지건 실제 작성하는 글씨 상관없이
피드백
이걸 어떻게 사용할 수 있을까?
고민했는데 나중에 웹 사이트를 만들면 실제로 한 페이지에 번역이 가능하게 만들 생각이다!!
- 유저가 UI에 직접 모르는 단어 작성
- OCR 인식
- Google Translate API를 이용한 번역
- 웹에 번역한 글자 알려주기 및 음성 나오게!
SW로 문제를 해결하려는 열정만 있는 대학생