
오픈소스를 활용한 데이터 파이프라인 구축
오픈소스로 전환하는 이유
Azure와 같은 클라우드 플랫폼은 편리하고 강력한 관리형 서비스 제공
- 단점: 종속성, 비용 부담, 커스터마이징 한계
오픈소스로 전환시
- 장점: 유연성 및 확장성, 비용 효율성, 활발한 커뮤니티, 투명성(소스코드 공개)
Azure 서비스를 대체할 오픈소스 목록

Apache Kafka
- 높은 처리량
- 분산 아키텍처
- 영속성
- 생산자-소비자 모델
Apache Flink
- 스트림 처리(마이크로배치 + 리얼 스트림)
- 상태 저장 처리
- 이벤트 시간 처리
- 높은 수준의 API(SQL구문과 유사)
마이크로 배치는 배치와 리얼 타임 처리의 중간 단계로, 짧은 주기 동안 데이터를 그룹화하여 처리하는 방식을 의미
Elasticsearch
- 매우 빠른 검색 및 분석
- JSON기반의 유연한 문서 저장
- 강력한 전문 검색 기능
- 확장성(클러스터링)
데이터 파이프라인
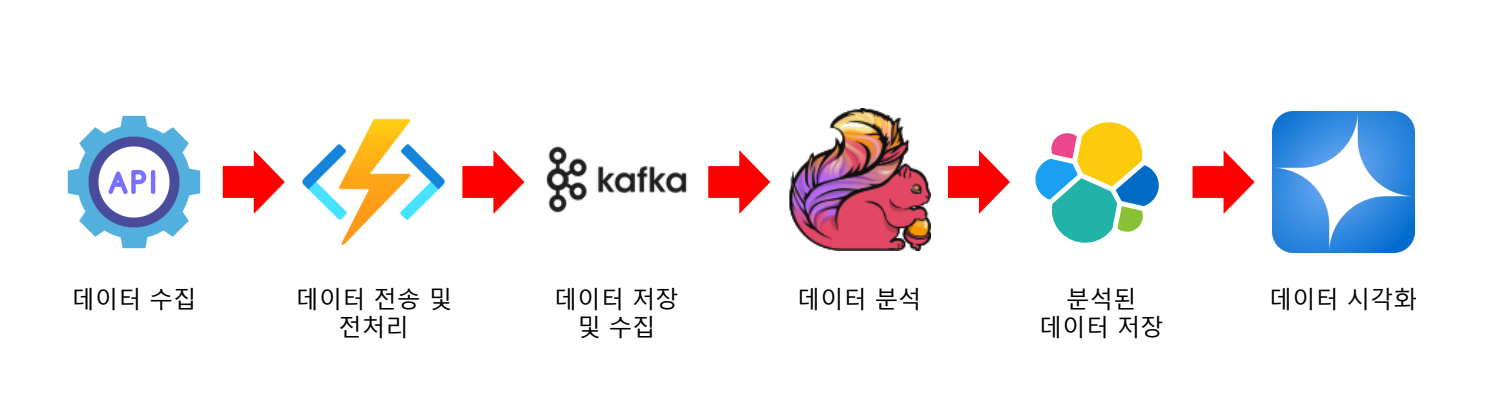
실습을 위한 개발 환경 구축
WSL, Docker, Docker Compose를 활용한 개발 환경
Kafka, Flink, Elasticsearch와 같은 분산 시스템은 각기 다른 의존성과 설정을 가지고 있어 직접 설치하고 연동하기가 까다로움
-> 컨테이너 사용
WSL(Windows Subsystem for Linux)
Windows사용자들이 Linux 환경을 직접 설치할 수 있게 해주는 도구
... 나는 mac환경이므로 이건 설치하지 않아도 될듯
Docker/Docker Desktop
패키징 기술 제공. 어떤 환경에서든 동일한 실행 보장
Docker Compose
컨테이너(Kafka, Flink, Elasticsearch)로 구성된 복잡한 애플리케이션을 정의하고 실행
Docker와 Kubernetes의 차이: kubernetes는 컨테이너화된 기술을 오케스트레이션할 수 있는 도구(=Docker Compose). Docker는 컨테이너화 하는 도구
예시) Kafka, Flink, Elasticsearch 총 3개의 이미지들끼리 데이터 통신을 시킬때, 이를 관리할 수 있게 함
(Window라면) WSL 설치 + Ubuntu 설치
- PowerShell을 관리자 권한으로 실행
wsl --install명령어 실행- microsoft store에서 ubuntu 검색 후 설치
Docker 설치
아래 부분은 따라하지 말자 그냥 도커를 다시 설치하고 재부팅이나 하자~~ 트러블슈팅 기록용으로만 남겨둔다
mac에 설치하니 악성 코드에 의해서 차단됐다고 작동이 안돼서 오류를 구글에 검색하여 해결하였다. (흔한 오류일듯하여...)
sudo launchctl bootout system/com.docker.vmnetd 2>/dev/null || true
sudo launchctl bootout system/com.docker.socket 2>/dev/null || true
sudo rm /Library/PrivilegedHelperTools/com.docker.vmnetd || true
sudo rm /Library/PrivilegedHelperTools/com.docker.socket || true
ps aux | grep -i docker | awk '{print $2}' | sudo xargs kill -9 2>/dev/null터미널에 입력하고 재실행하면 해결된다. 나같은경우에는 com.docker.vmnetd파일은 없어서 그 부분은 삭제하지 않았다.
의미도 모르고 사용하면 문제가 발생할까봐 의미도 찾아봤다.
launchctl로 Docker 시스템 서비스 중지
2>/dev/null: 에러 메시지 숨김 (stderr 버림)
|| true: 명령이 실패해도 에러로 종료하지 않도록 처리
sudo rm~ 부분:Docker가 설치한 root 권한 helper 파일을 직접 삭제
ps aux: 현재 실행 중인 모든 프로세스 출력
grep -i docker: docker 포함된 프로세스 필터링
awk '{print $2}': PID(프로세스 ID)만 추출
sudo xargs kill -9: 해당 PID들을 SIGKILL로 강제 종료
-9:정상 종료 요청이 아니라 그냥 즉시 강제 종료
Docker Compose 실행하기
docker을 사용할 프로젝트 폴더로 이동 후
docker compose up -d 명령어 실행
여기서 command not found 떠서 다시 설정을 해줘야했다(환경변수)
vi ~/.zshrc
그리고 하단에 추가한다
alias docker="/Applications/Docker.app/Contents/Resources/bin/docker"esc 후 :wq로 저장하고, 실행해서 적용해준다
source ~/.zshrc
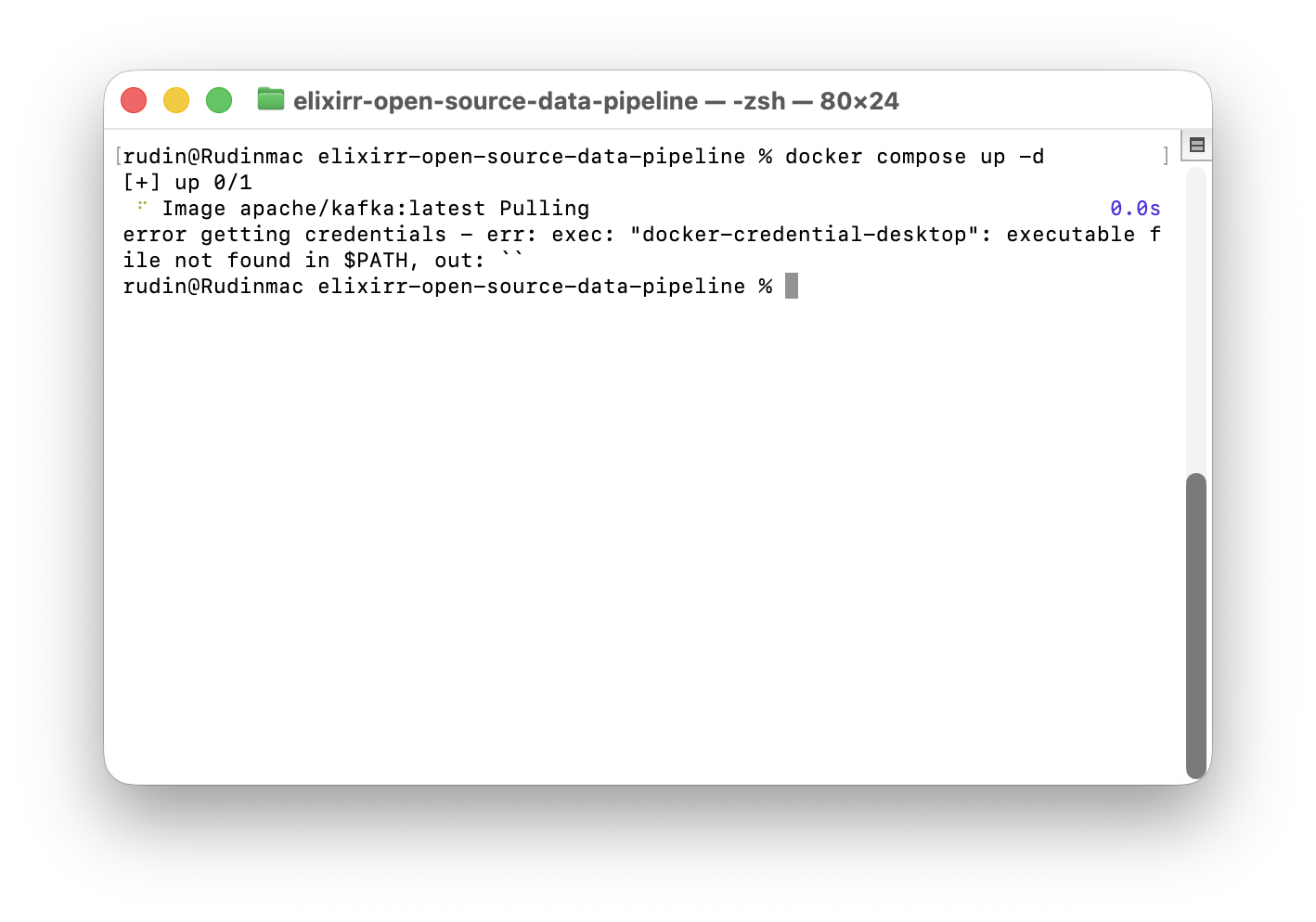
에러가 발생했다
error getting credentials
아까 helper를 삭제해서 그런듯했다.
그냥 도커를 재설치해주니 문제없이 동작했다. (뻘짓 무엇...)
Elastic Search와 Flink 초기화 명령 실행
./init-es.sh
docker exec -it flink-jobmanager ./bin/sql-client.sh -f /opt/flink/sql-scripts/job.sql이미 실행 중인 Flink JobManager 컨테이너 안에서 SQL 스크립트(job.sql)를 실행해서 스트림 처리 Job을 등록하는 명령어(즉, Flink Job을 제출하는 작업임.)
컨테이너를 만들때마다 수작업으로 스크립트를 작성해야 하지만, init-es, job.sql과 같이 미리 스크립트를 준비해두면 번거로움을 줄일 수 있다.
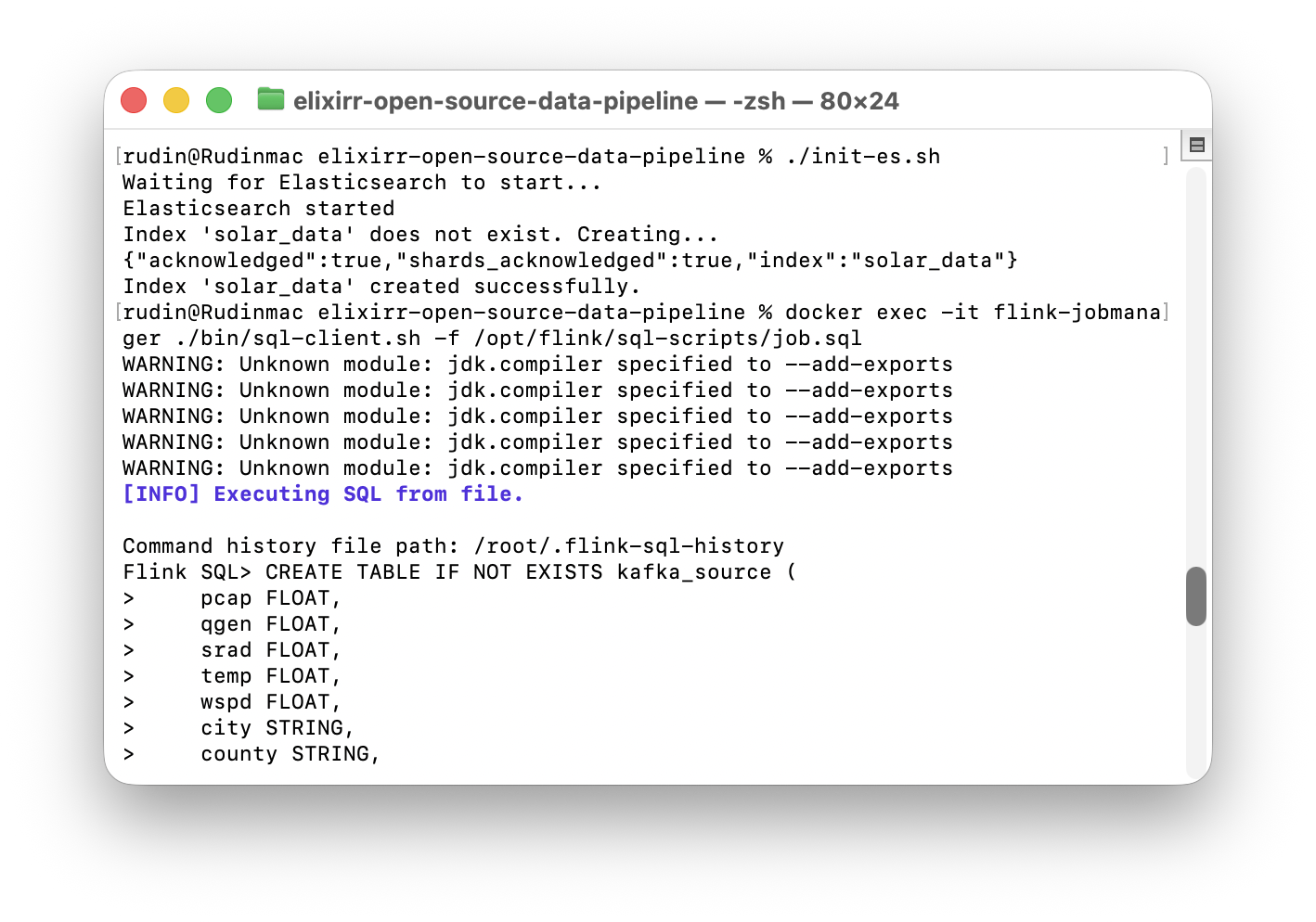
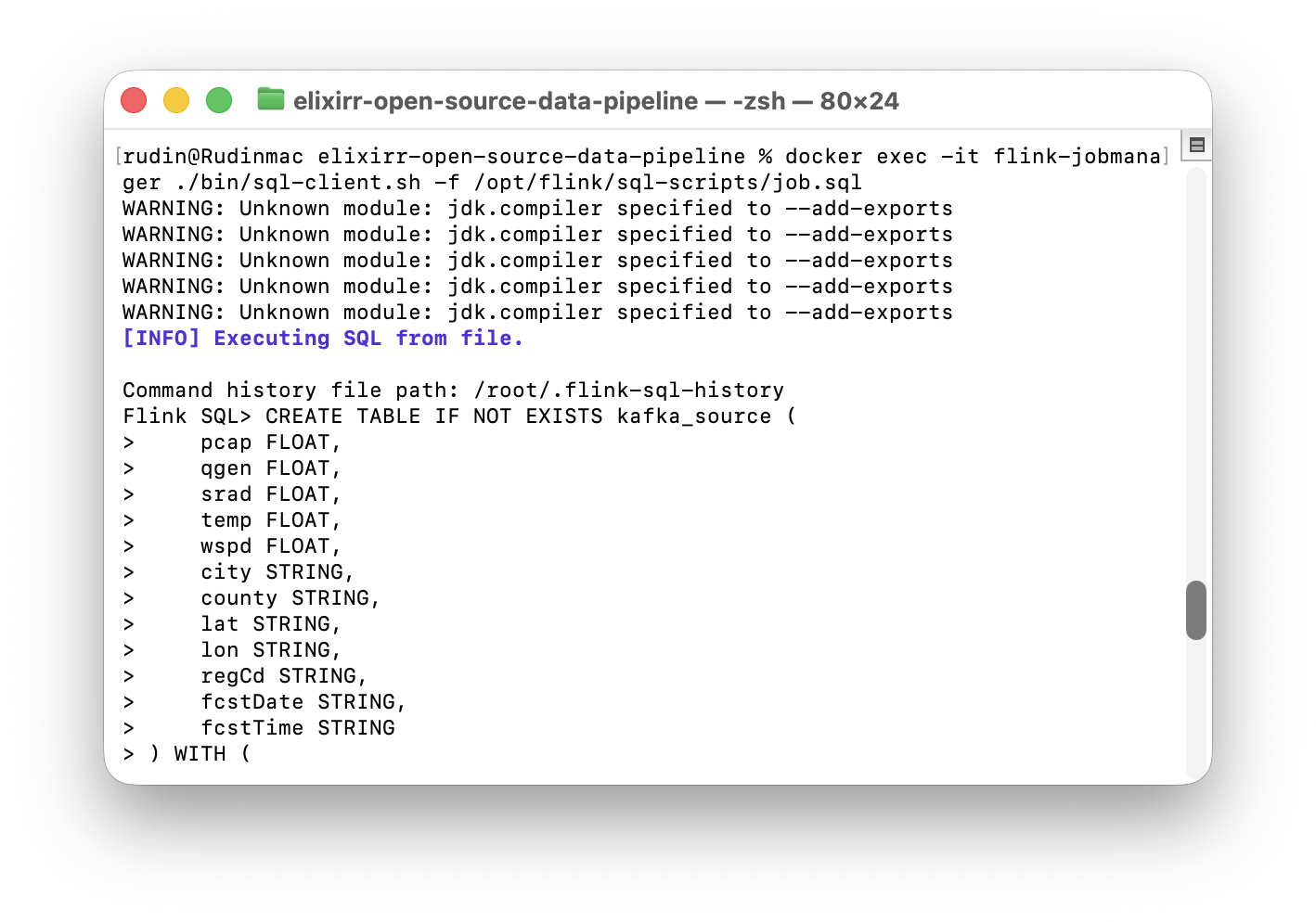
warning: unknown module~ 부분이 걸려서 찾아보았다.
jdk.compiler모듈은 JDK에만 존재하고 JRE에는 없다.
Flink가 현재 JRE 기반 이미지로 실행중이기 때문에 jdk.compiler이 없다고 하는 것.
Flink SQL Client는 javac 내부 API를 사용하지 않기 때문에 대부분이ㅡ Flink SQL 실행에는 영향 없으므로 현재는 무시해도 된다.
태양광 발전량 예측 데이터 챗복 구축
프로젝트 파일 준비 및 환경변수 설정
실습 파일을 항상 하던대로 동일하게 git으로 받아 준비하였고, local.json.settings 를 추가해서 작성했다.
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "python",
"KafkaBrokerList": "localhost:29092",
"KafkaSendTopic": "test-topic",
"kafkaReceiveTopic": "flink-result-topic",
"ES_HOST": "http://localhost:9200"
}
}Azure OpenAI 키 및 엔드포인트 설정
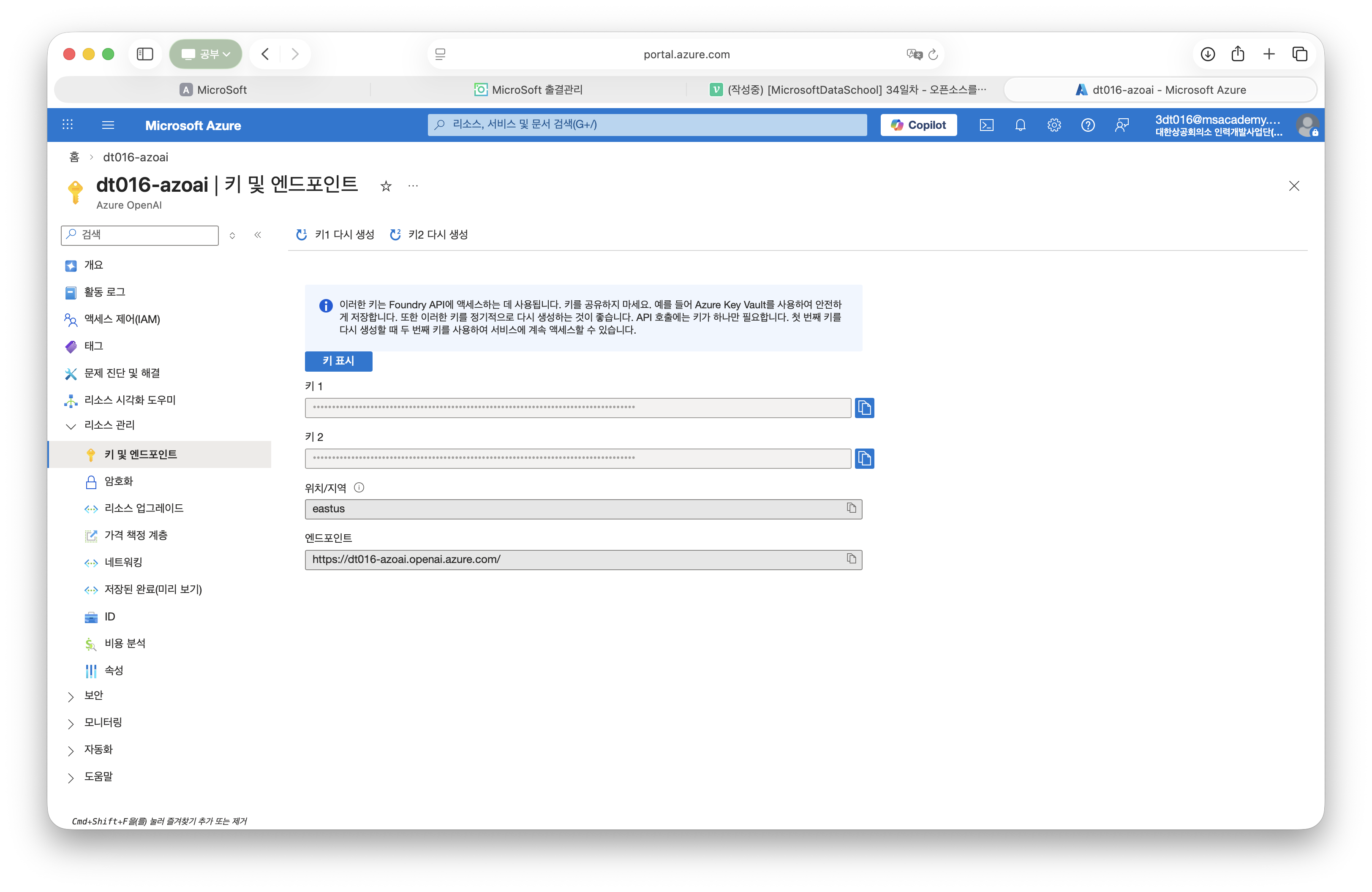
local.settings.json에 키1 엔드포인트 값을 입력한다.
"OPENAI_ENDPOINT": <엔드포인트 정보>,
"OPENAI_KEY": <키1 정보>
"OPENAI_API_VERSION": "2025-01-01-preview",Azure OpenAI 모델 배포 이름 설정
AI Foundry -> 배포 탭으로 들어가 gpt와 text-embedding의 이름을 복사하여 local.settings.json 에 입력한다.
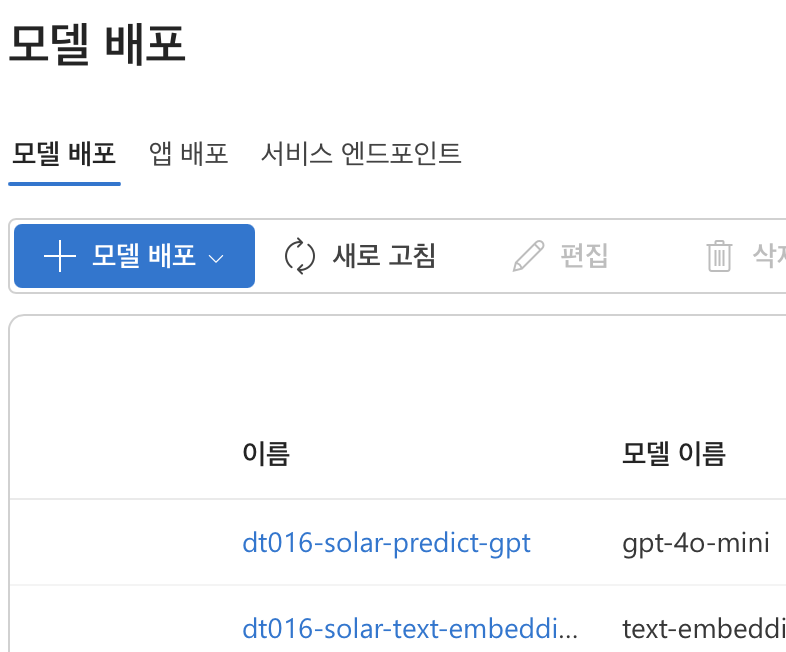
"OPENAI_GPT_MODEL": <GPT 이름>,
"OPENAI_EMBEDDINGS_DEPLOYMENT": <Text-Embedding 이름>Azure Function 실행하기
가상환경 생성
python -m venv .venv
Azurite Start
F1키 입력 후 Azurite Start
mac으로 환경을 옮기며 azurite설치를 까먹어서 vscode extension에서 설치해주었다.
함수 실행
F5
azure function core tools가 없어 설치하는데, mac을 26.2로 업데이트 한 탓인지 cts 버전이 안맞는다고 설치가 안되었다.
자체적으로도 cts 업데이트가 안먹혀서 그냥 apple developer쪽에서 26.2 cst를 수동설치 해주었고, 이후 azure core tools도 정상적으로 설치되었다.
Kafka에 데이터 전송 API 사용하기
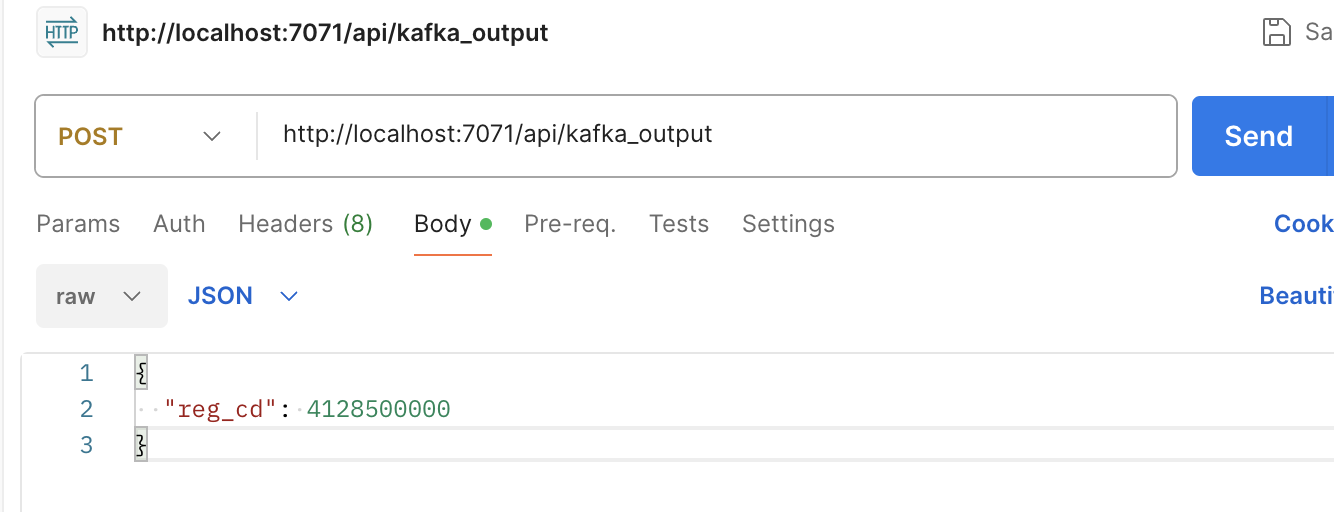
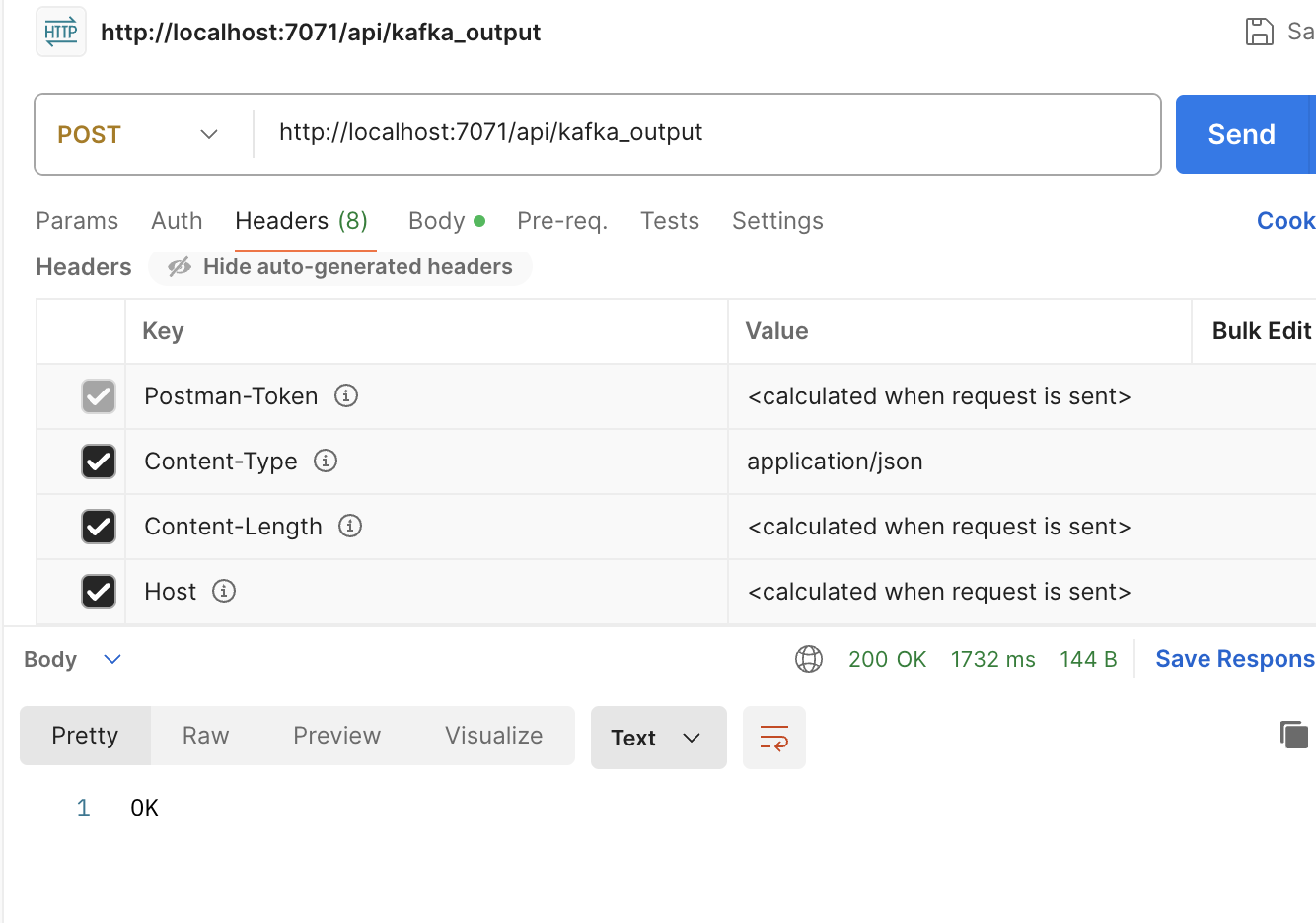
curl -X POST -d "{\"reg_cd\": 4128500000 }" http://localhost:7071/api/kafka_output
나는 postman을 이용했다
1. Postman 실행
2. New → HTTP Request
3. Method를 POST로 변경
4. URL 입력 http://localhost:7071/api/kafka_output
5. Body탭 클릭
6. raw 선택
7. 드롭다운에서 JSON 선택
{
"reg_cd": 4128500000
}
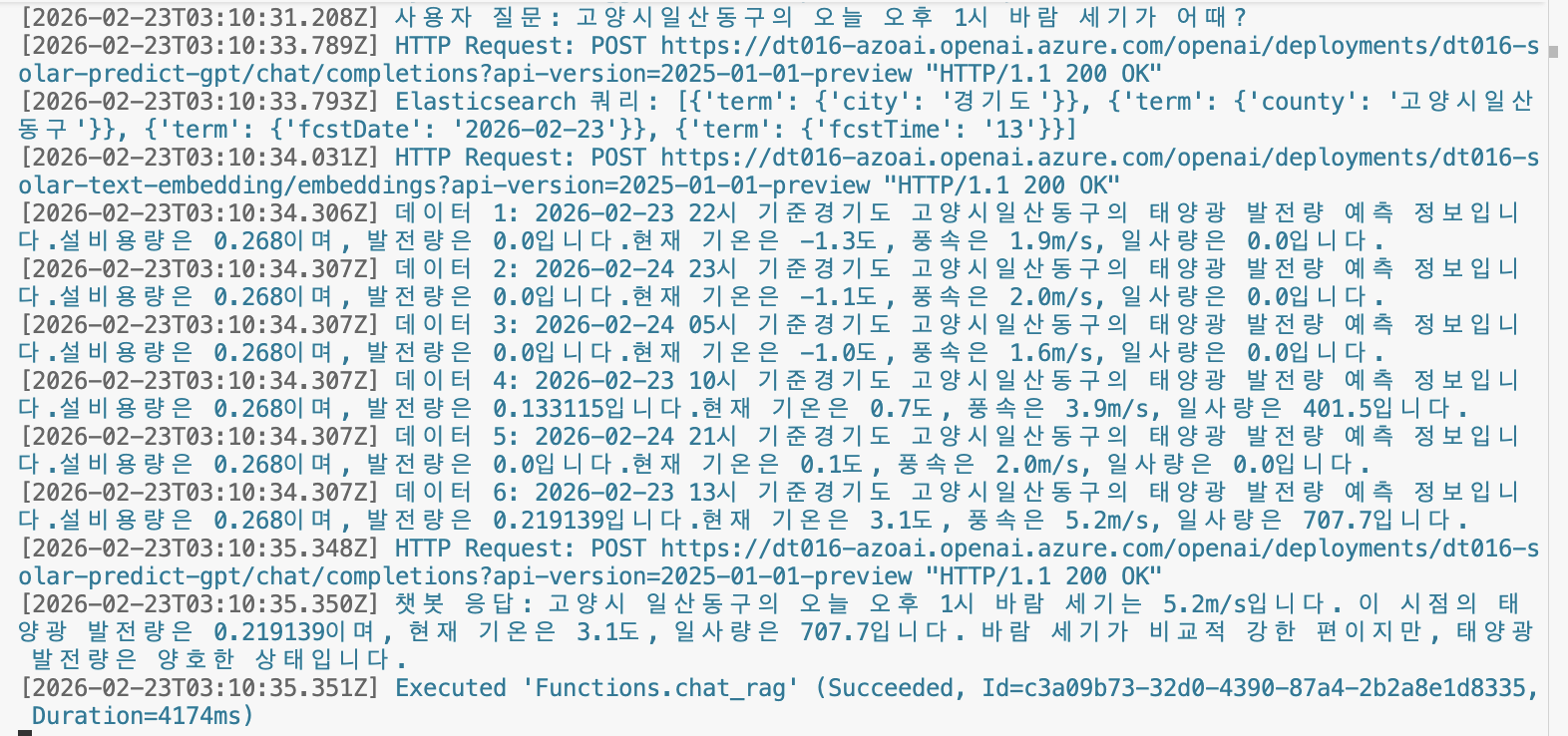
RAG 챗봇 API 사용하기
curl -X POST -d "{\"question\": \"고양시일산동구의 오늘 오후 1시 바람 세기가 어때?\" }" http://localhost:7071/api/chat_rag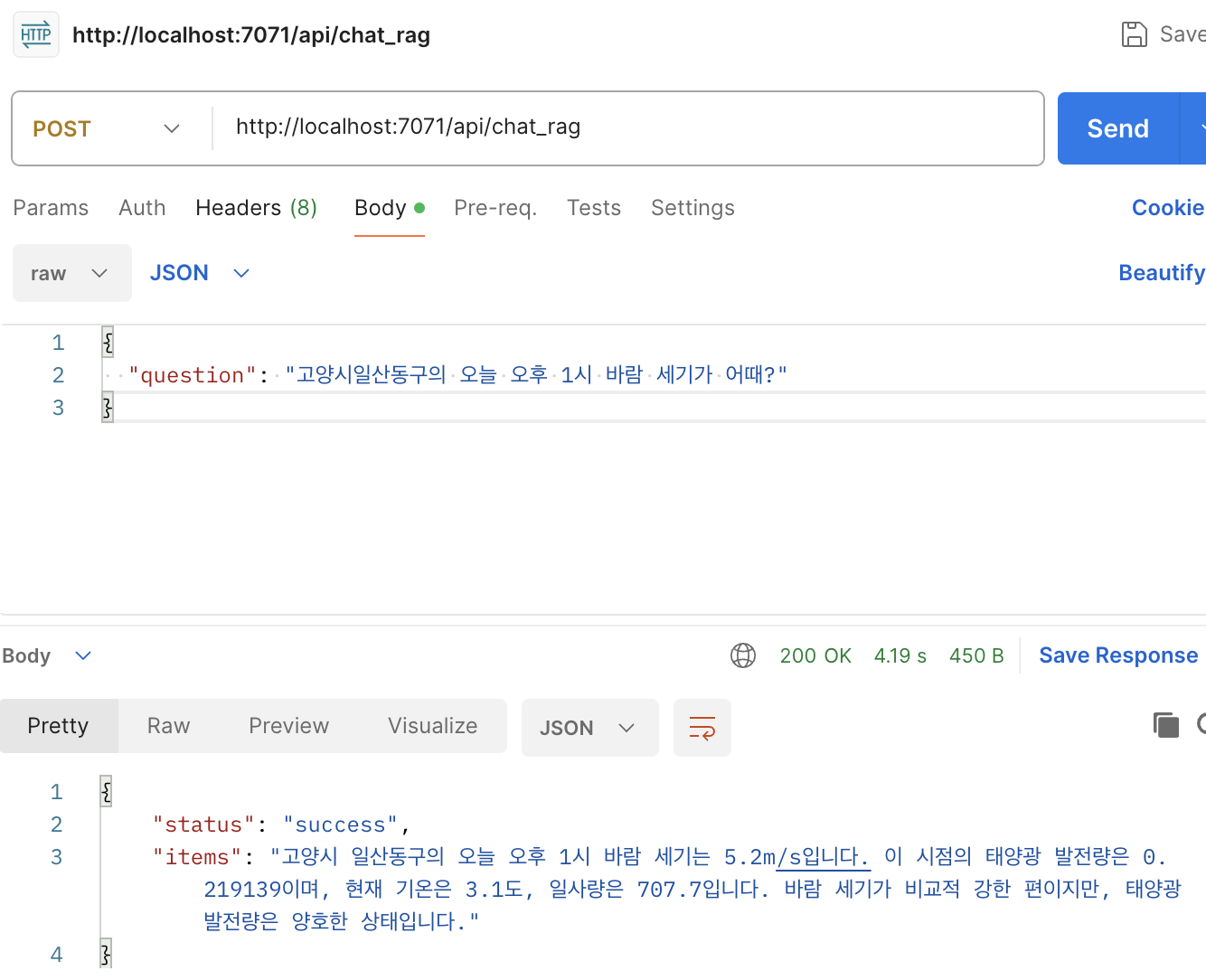
Docker Compose 종료하기
해당하는 프로젝트 디렉토리에서
docker compose down
정리
Azure Functions(로컬)에서 Kafka로 데이터를 직접 전송 + Azure OpenAI와 연계하여 검색 증강 생성(RAG) 애플리케이션으로 확장
- Docker Compose로 오픈소스 파이프라인 실행
- 로컬 Azure Function을 통해 Kafka로 데이터 전송
- Python으로 Elasticsearch의 데이터를 조회하여 RAG 애플리케이션 구현
agentic coding
예전 agent workflow
출장 계획 보고서 작성 앱을 가정하자.
비용산출 agent, 장소검색 agent, 회의록 작성 agent가 있다고 하면 이를 오케스트레이션하는 agent도 사용한다.
모두 동일한 고성능 LLM을 쓰게되면 비용이 발생한다.
최근 트렌드
오케스트레이션이나 Task가 작은 일을 할때는 작은 LLM을 쓴다(ex: mini, nano 등 저비용)
장소검색 등 주요 MVP 기능에는 비싼 모델 사용
GroqCloud
인공지능(AI) 스타트업 Groq(그록)이 개발한 독자적인 LPU(Language Processing Unit, 언어 처리 장치) 인프라를 통해, 초고속 AI 추론(Inference) 서비스를 제공하는 클라우드 기반 플랫폼
제일중요한것 무료다
api key
잘 복붙해두자
llm test
groq cloud의 playground에서 샘플 코드를 가져와 실행해보자.
1. 가상환경 생성
python -m venv .venv
source .venv/bin/activate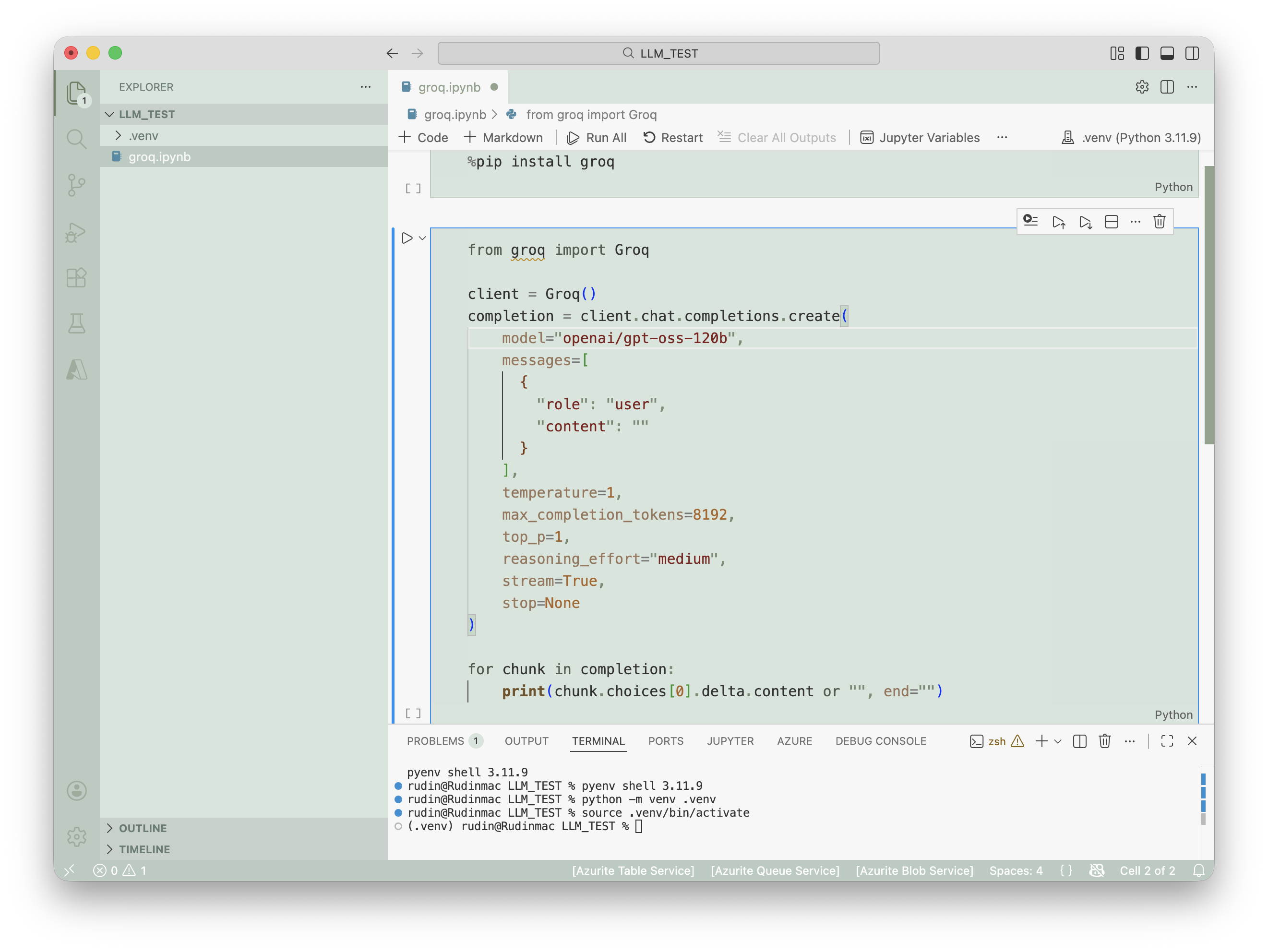
-
환경변수 설정
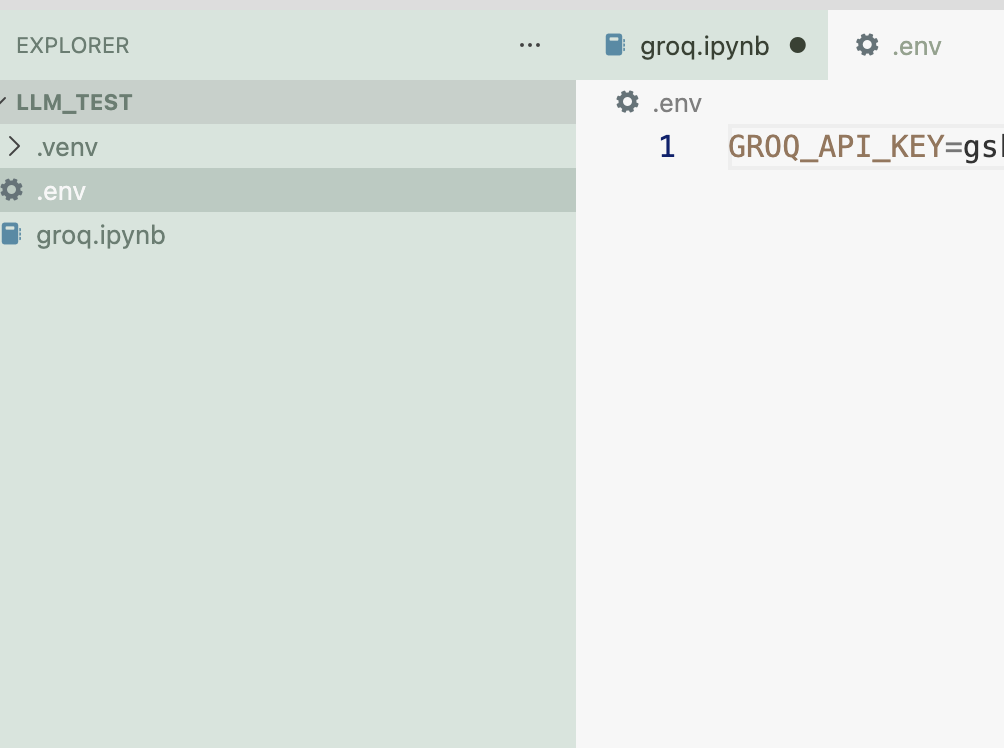
-
실행
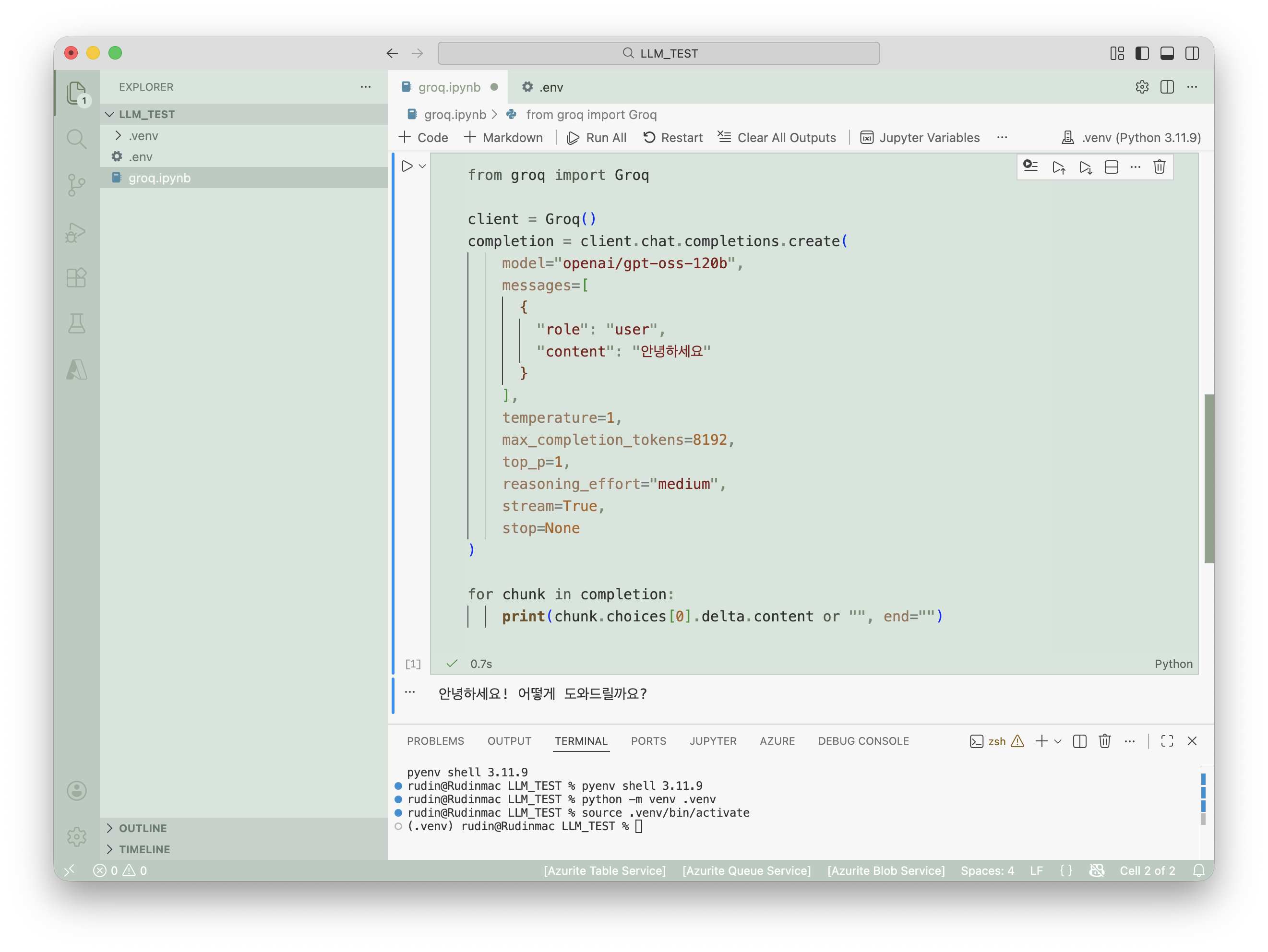
참고로 한국어 토큰은 2배 더 소요돼서, 싸게 하고싶으면 영어로 프롬프트를 작성했다 한다.
Gemini 무료 API 활용
APIkey 생성
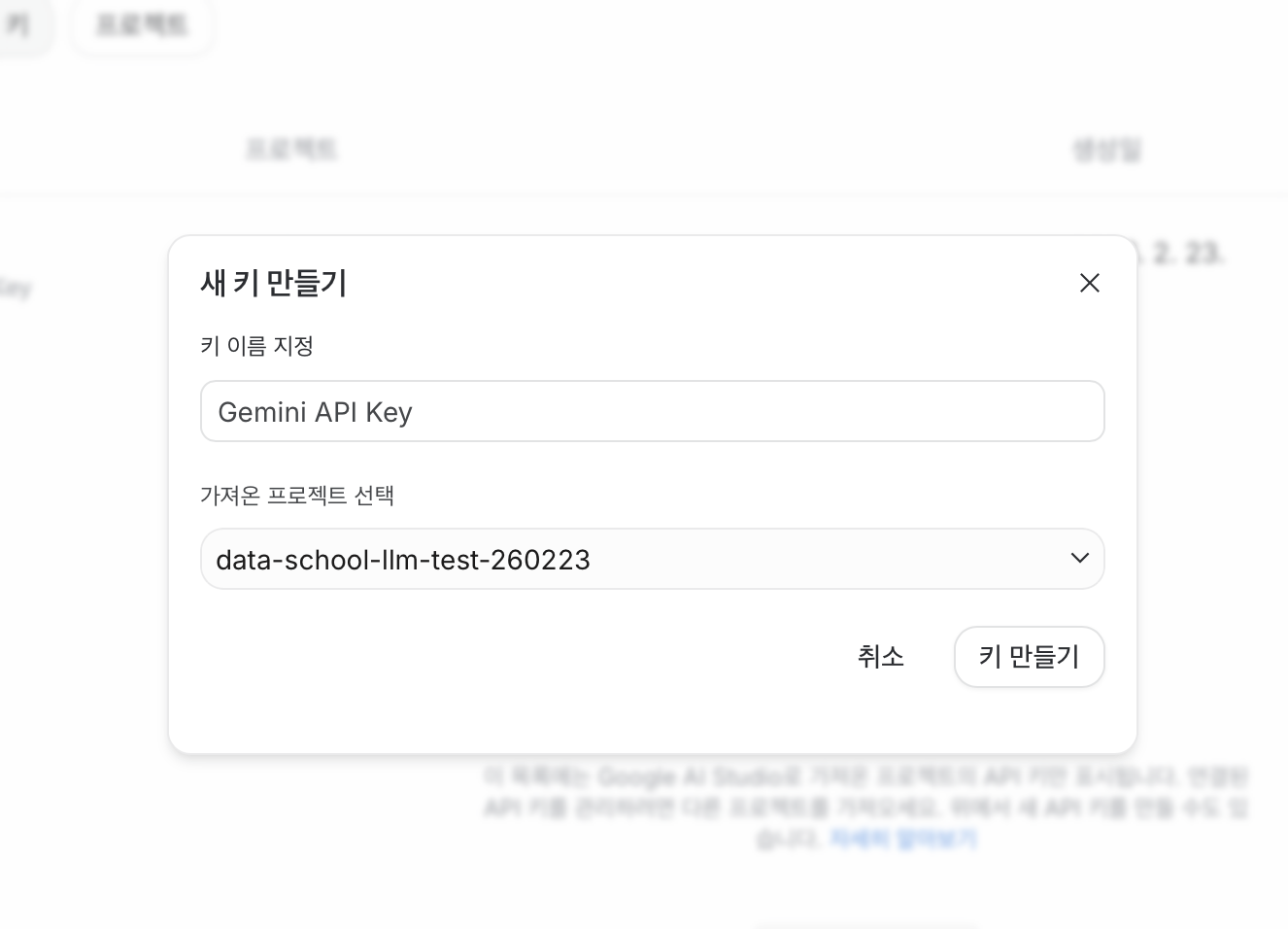
Playground get code
%pip install google-genai
# To run this code you need to install the following dependencies:
# pip install google-genai
import os
from google import genai
from google.genai import types
def generate():
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemini-3-flash-preview"
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text="""오늘 미세먼지 어때"""),
],
),
]
tools = [
types.Tool(googleSearch=types.GoogleSearch(
)),
]
generate_content_config = types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="LOW",
),
tools=tools,
)
for chunk in client.models.generate_content_stream(
model=model,
contents=contents,
config=generate_content_config,
):
print(chunk.text, end="")
if __name__ == "__main__":
generate()
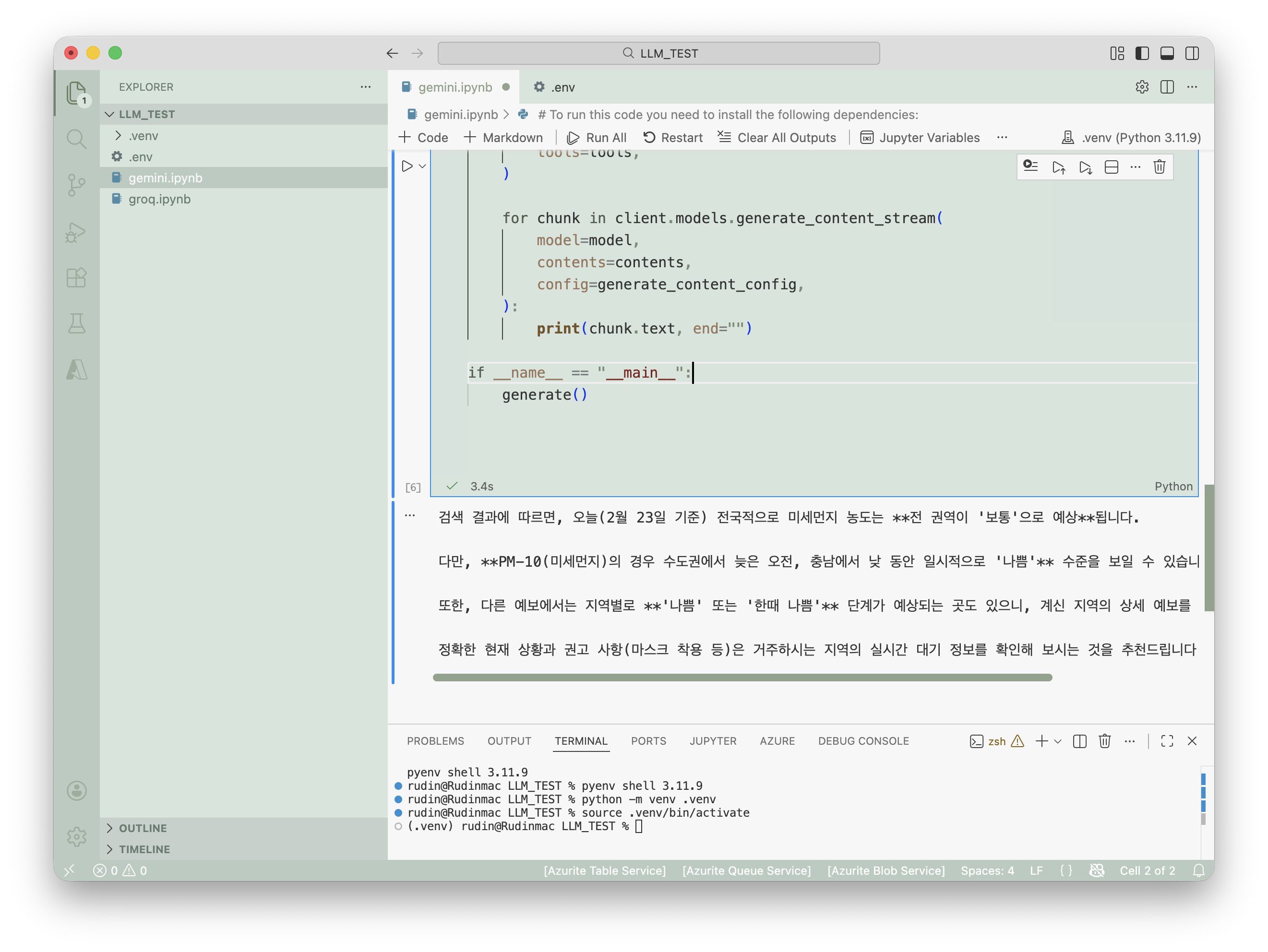
quota 초과 오류가 떠서 모델을 바꿔주었다.
...
def generate():
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemini-flash-lite-latest"
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text="""오늘 미세먼지 어때"""),
],
),
]
tools = [
types.Tool(googleSearch=types.GoogleSearch(
)),
]
generate_content_config = types.GenerateContentConfig(
# thinking_config=types.ThinkingConfig(
# thinking_level="LOW",
# ),
tools=tools,
)
...
멀티에이전트 구조
이전에는 if문으로 분기하여 LLM의 응답 결과를 기준으로 가동해야하는 LLM을 판단하는 방식으로 멀티에이전트를 구성했다고 한다.
https://learn.deeplearning.ai/courses/agentic-ai/lesson/pu5xbv/welcome!
AutoGen
멀티에이전트를 할 수 있게 도와주는 프레임워크
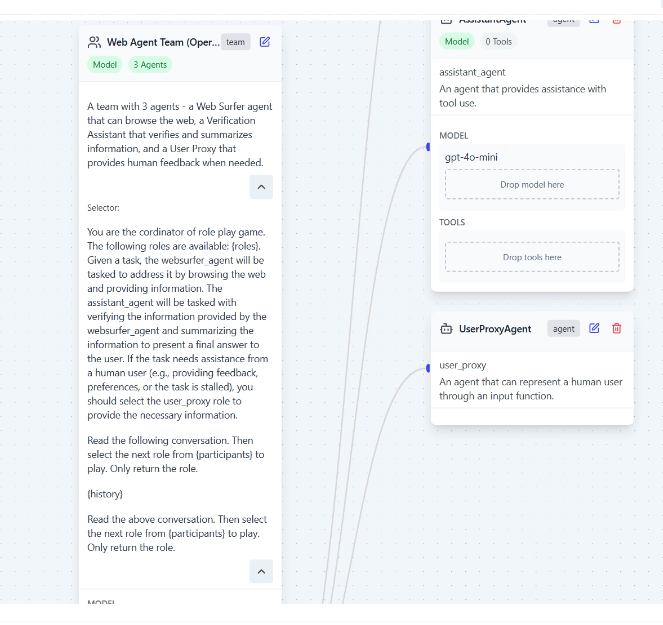
오케스트레이션을 담당하는 Agent는 입력을 받아 어떤 에이전트를 실행해야하는지 반환하게 된다.(변수형식으로 반환해라 등 지정 -> 샘플에서는 "Only return the role")
Langchain Langgraph
실무에서 많이 쓰는 멀티에이전트 프레임워크
Adversarial Attack
머신러닝(특히 딥러닝) 모델을 의도적으로 속이기 위해 입력 데이터를 아주 미세하게 조작하는 공격 기법
