Fabric 시작하기
Databricks와 같은 서비스를 포함하는 더 큰 서비스
실습 준비
평가판 활성화
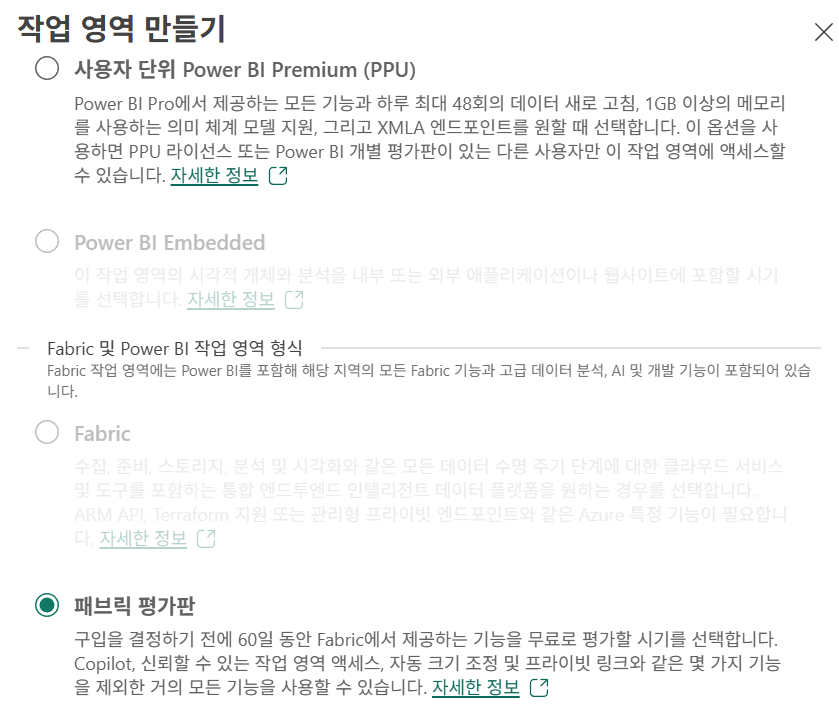
작업 영역 생성
패브릭 평가판을 선택한다.
OneLake 기반의 데이터 수집, 정제 파이프라인과 웨어하우스 분석 기초
Fabric의 필요성
- 도구의 파편화에서 비용 추적이 어려우며, 관리 복잡도가 증가함
- 데이터 사일로 현상 발생(팀 간 데이터 공유 어려움)
- 각 플랫폼별 학습곡선 존재
→ 통합 솔루션의 등장 필요
Azure Service Fabric
마이크로서비스와 컨테이너를 패키징, 배포, 관리하는 분산 시스템 플랫폼
Fabric에 속한 서비스
| Experience | 담당자 | 핵심기능 |
|---|---|---|
| Data Factory | 데이터 엔지니어 | 데이터 수집, Mirroring (Zero-ETL), Shortcuts(연결) |
| Data Engineering | 데이터 엔지니어 | Spark 기반 변환, Lakehouse 구조, Medallion Architecture |
| Data Science | 데이터 과학자 | ML 모델 개발, MLflow 통합 |
| Data Warehousing | 데이터 분석가 | T-SQL 분석, DirectLake(실시간), 엔터프라이즈 DW |
| Real-Time Intelligence | 실시간 분석가 | KQL 스트림 분석, Data Activator (알림) |
| Power BI | BI 개발자 | 시각화 & 대시보드 |
OneLake의 계층 구조
Tenant → Domain → Workspace → ItemLakehouse vs Warehouse
Fabric 은 둘 다 지원
| 구분 | Data Warehouse | Lakehouse |
|---|---|---|
| 데이터 형태 | 정형 데이터만 (정제된 형식) | 모든 형식 (정형 + 반정형 + 비정형) |
| 스키마 | 엄격함 (Schema-on-Write, Star Schema) | 유연함 (Schema-on-Read) |
| 데이터 흐름 | Lakehouse → 변환 → 저장 | 수집 → 저장 (원본 그대로) |
| 계층 구조 | Gold (최종, 분석용) | Bronze(원본) → Silver(정제) → Gold |
| 주요 사용자 | 비즈니스 분석가 (BI 팀) | 데이터 엔지니어 |
| 처리 방식 | ETL 중심 | ELT 및 스트리밍 포함 |
| 활용 영역 | BI, 리포트 중심 | BI + 데이터 사이언스 + ML + 실시간 분석 |
Microsoft Fabric 의사 결정 가이드
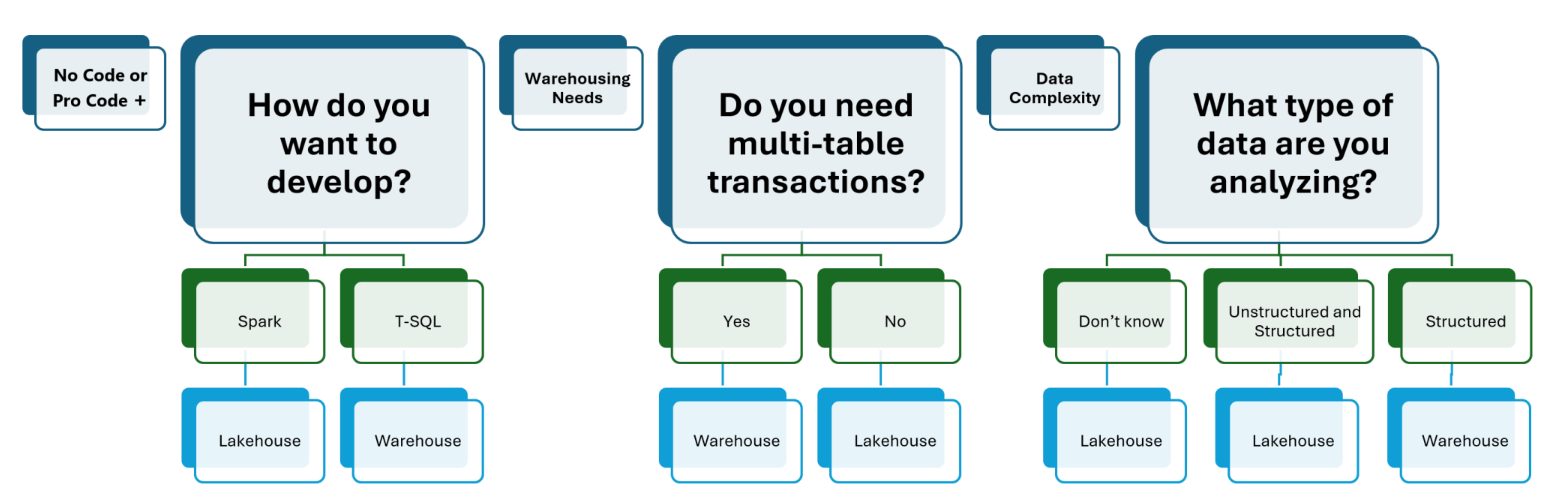
데이터 이동을 위한 전략적 선택 가이드
Fabric에서는 가능한 Shortcut이나 Mirroring을 쓰고, 어쩔 수 없을 때만 Copy하도록 권장
| 비교 항목 | 1. Mirroring | 2. Copy Data Pipeline | 3. Shortcut |
|---|---|---|---|
| 별명 | 거울 (실시간) | 트럭 (배치) | 지름길 (연결) |
| 데이터 이동 | 자동 복제 (Zero-ETL) | 물리적 복사 | 이동 없음 |
| 복잡도 | 매우 쉬움 | 중간 (설정 필요) | 매우 쉬움 |
| 비용 | 무료 (컴퓨팅만) | 유료 (처리량 비례) | 무료 |
| 대상 | Azure SQL, Snowflake | On-prem DB, File | S3, ADLS Gen2 |
Shortcut의 동작방식
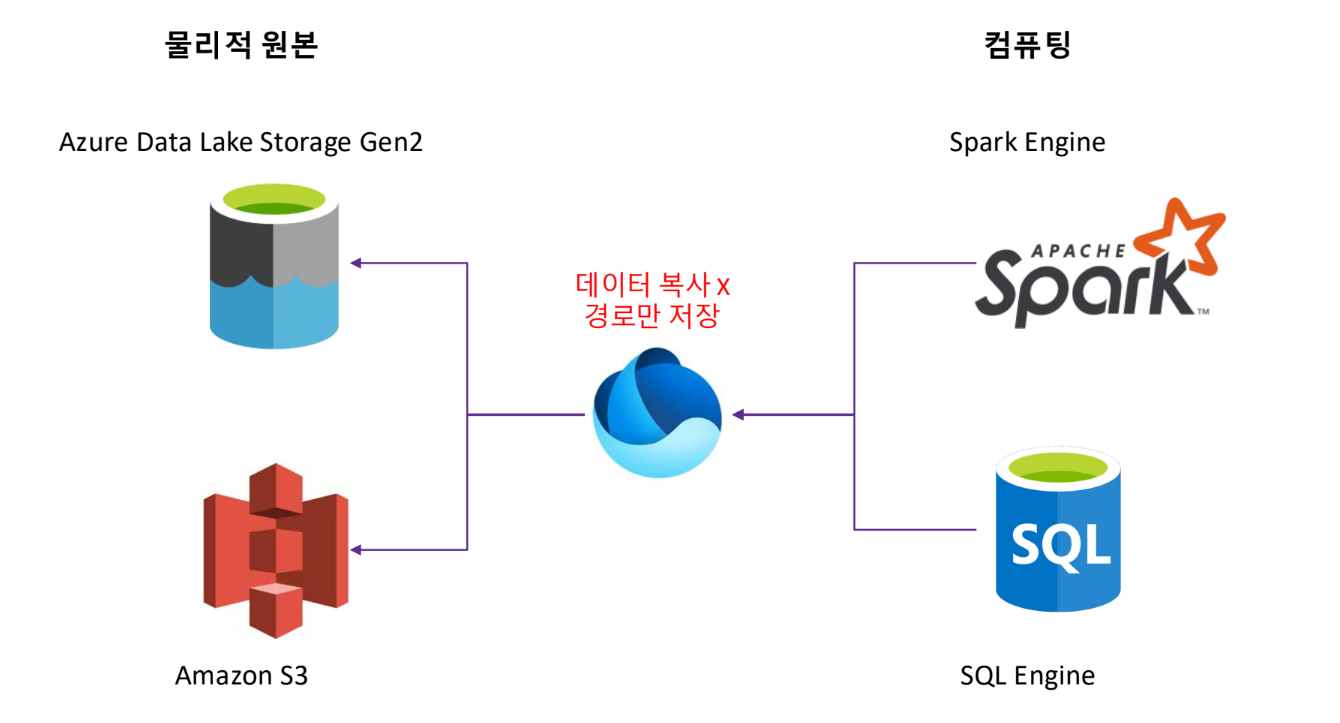
Spark나 SQL은 OneLake를 바라보지만 실제 I/O는 원본 스토리지에서 직접 발생
Egress비용(Cloud 간 이동)은 발생할 수 있지만 Fabric 내부 저장 비용은 0원
실습
Lakehouse 생성 및 파일 업로드
https://microsoftlearning.github.io/mslearn-fabric/Instructions/Labs/01-lakehouse.html
- Fabric의 저장소인 OneLake와 Lakehouse를 직접 만들어보기
생성
좌상단 +새항목 버튼 클릭
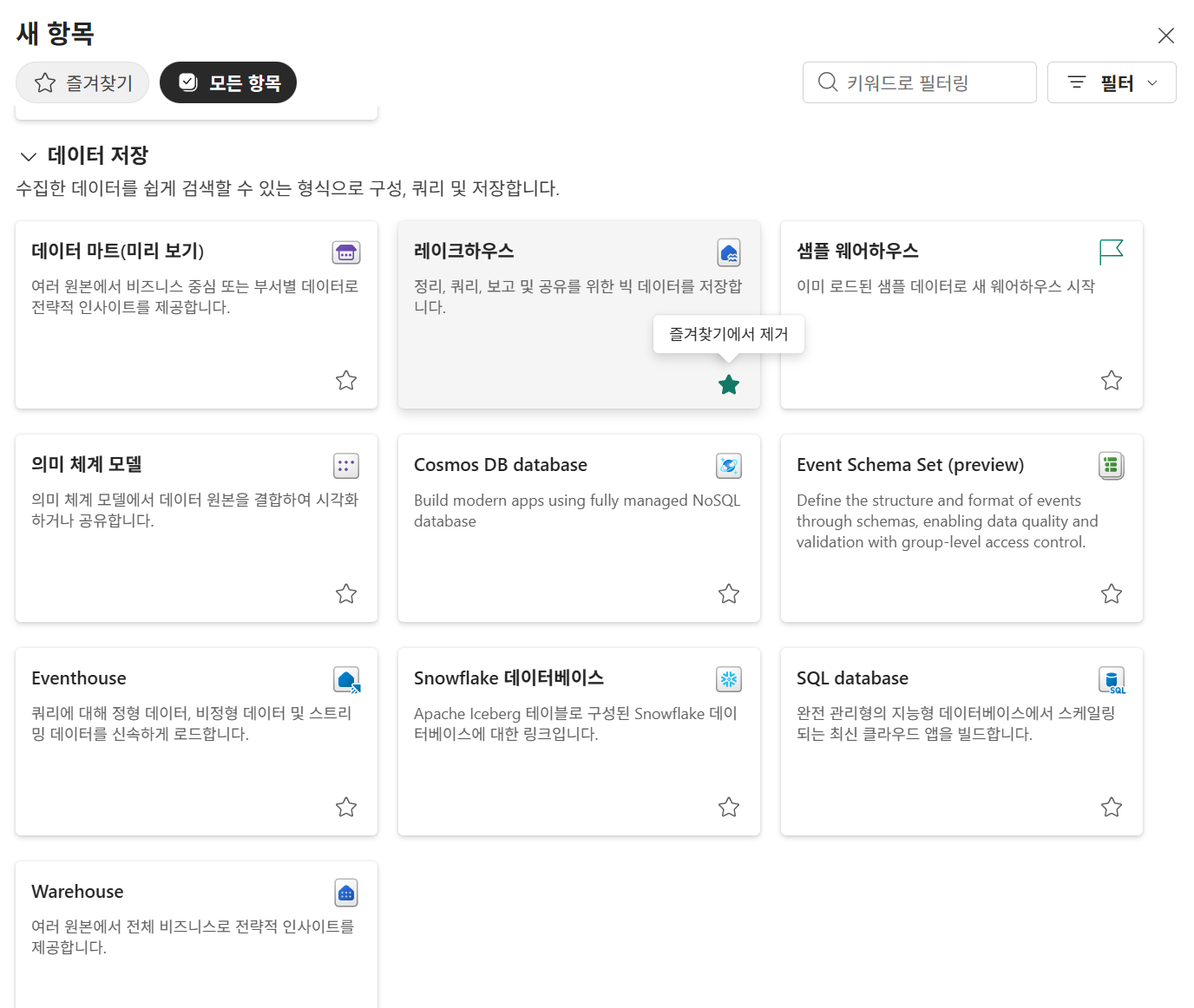
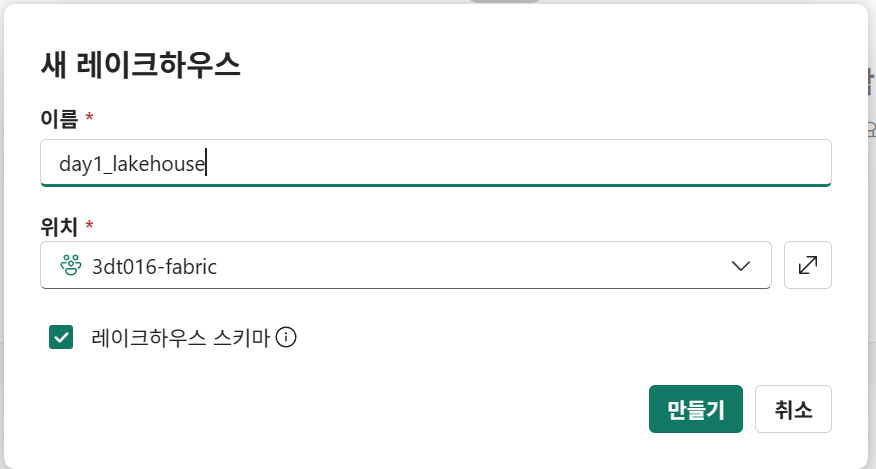
- 레이크하우스 스키마: 스키마 별로 저장 가능. X시 기본 데이터테이블에 저장
파일 업로드
데이터 가져오기 - 파일 업로드
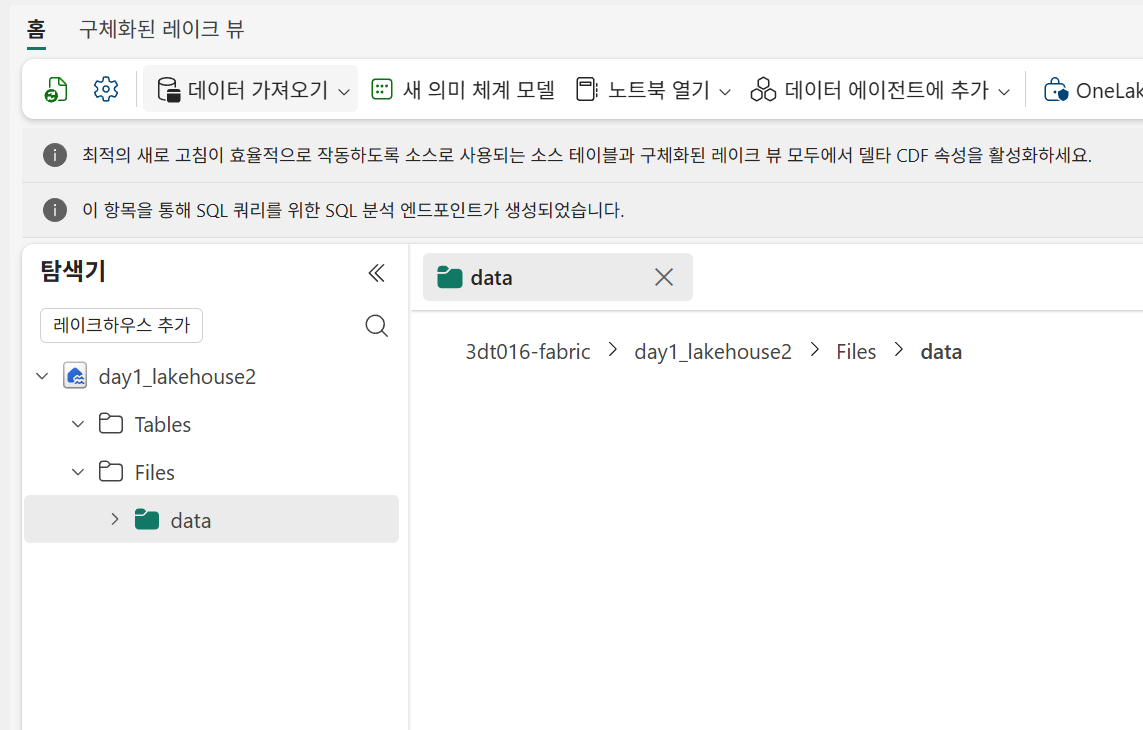

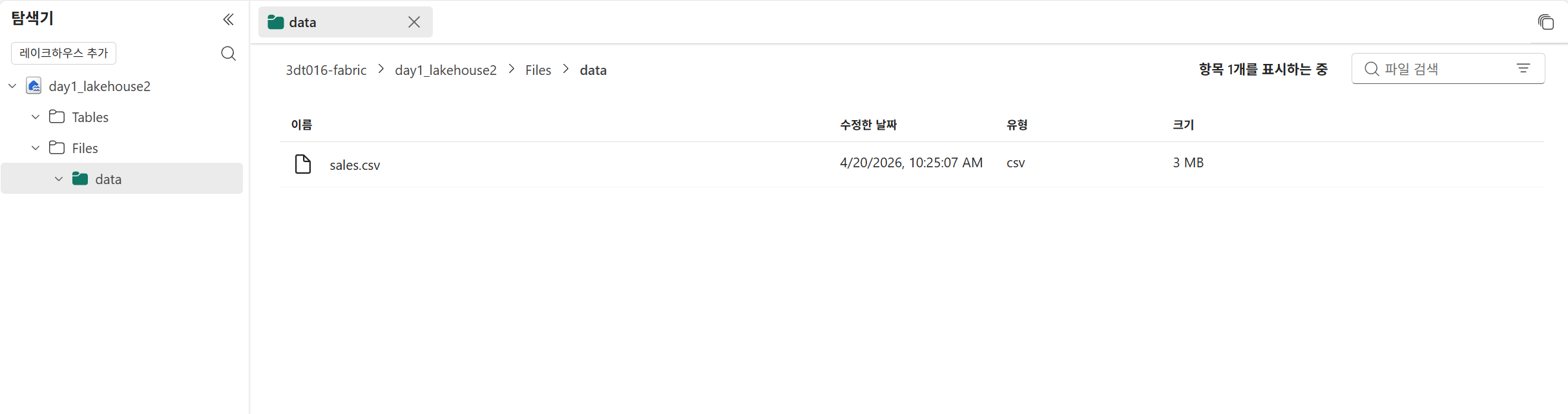
테이블에 로드
새 테이블 만들기를 시도했으나, 과정의 이전 기수들의 리소스 해제가 안되어있어 Too many Requests 오류가 발생했다.

삭제해주신 후 정상 진행이 되었다.
무료 평가판에서는 테넌트 내의 50명이 정원인 듯 했다.
쿼리 전송
SQL 분석 엔드포인트로 이동
새 SQL 쿼리 선택
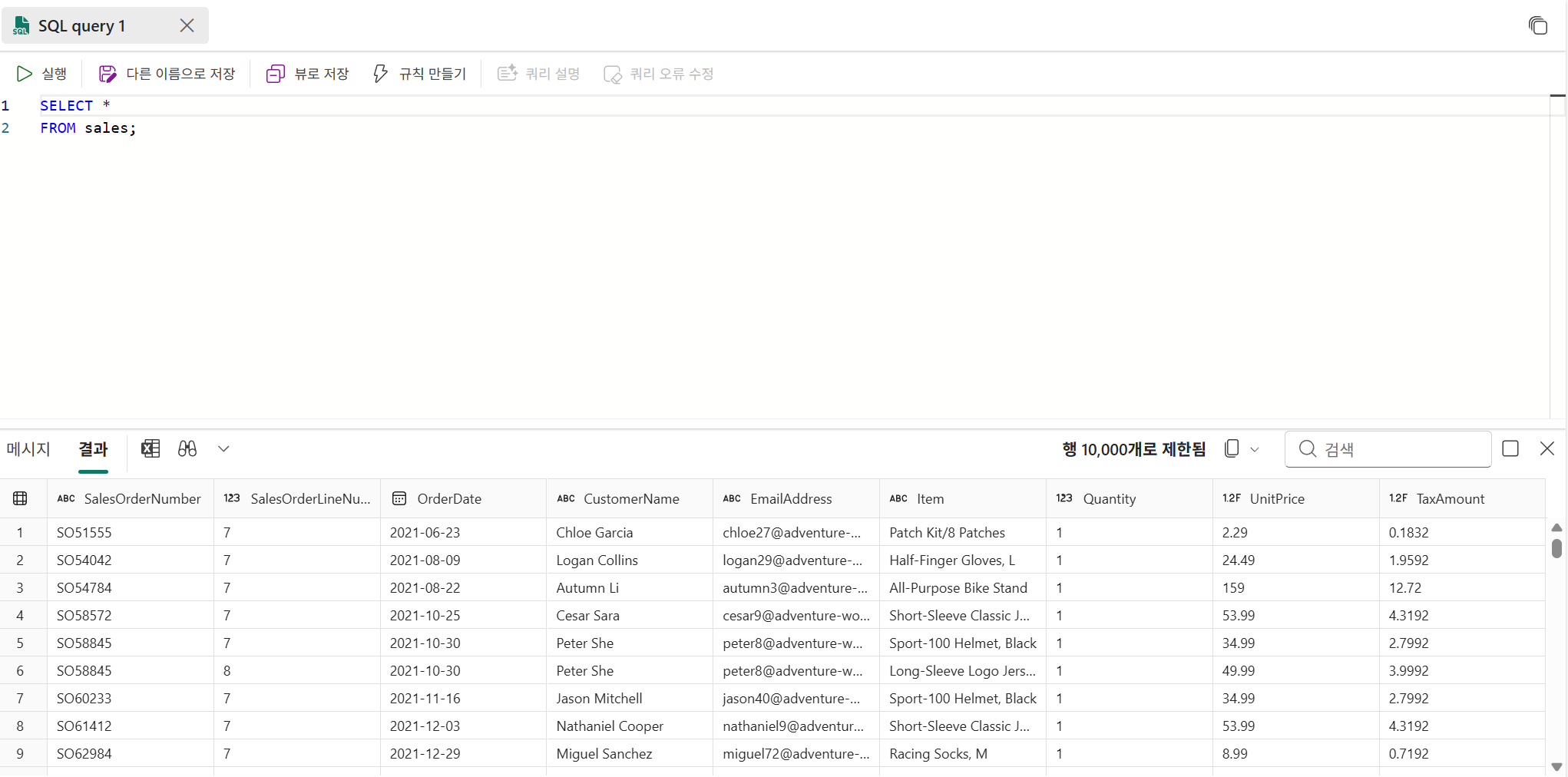
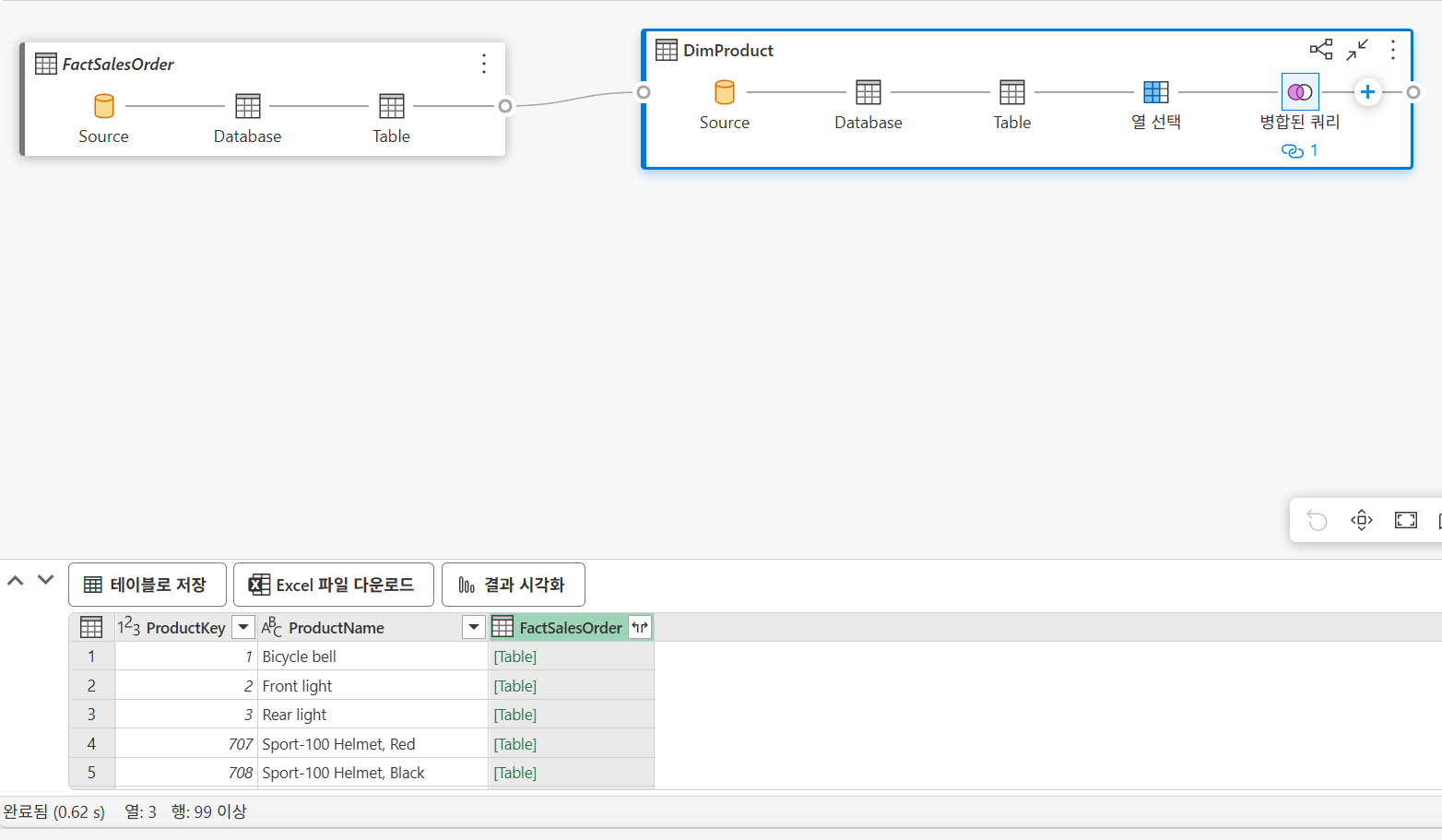
Visual Query
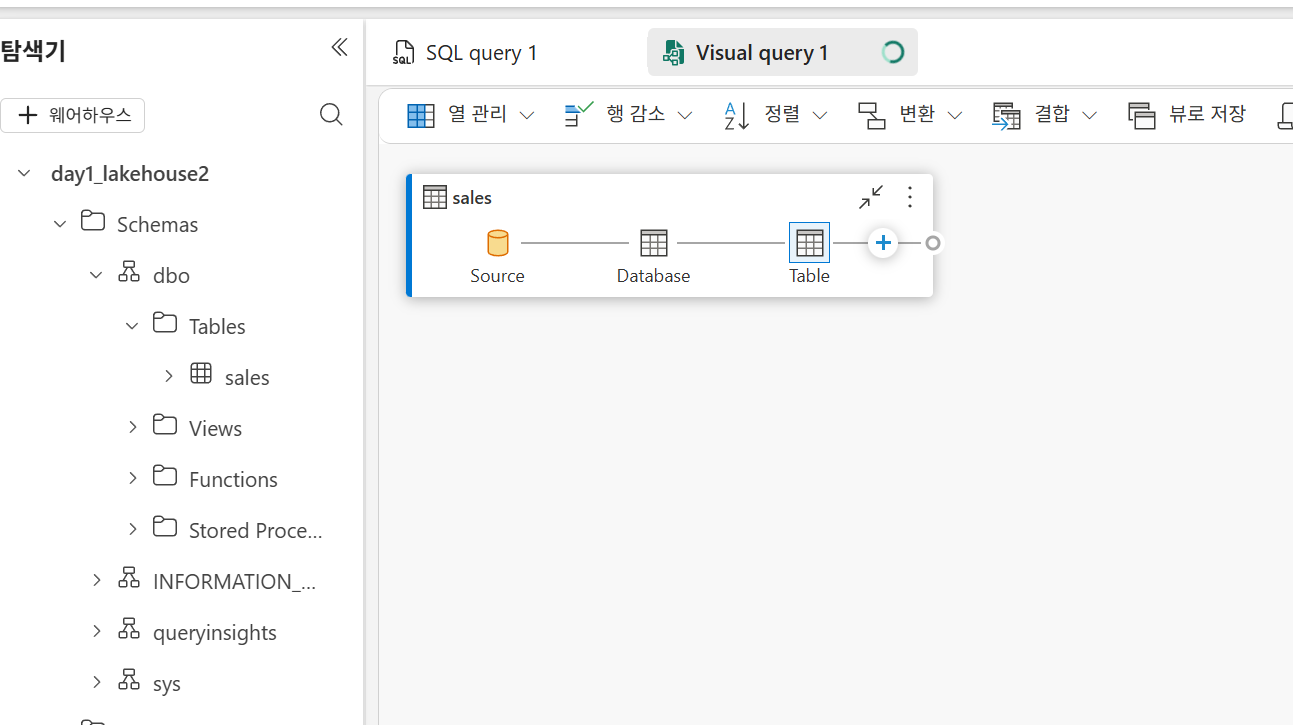
테이블을 드래그 앤 드랍해서 시작
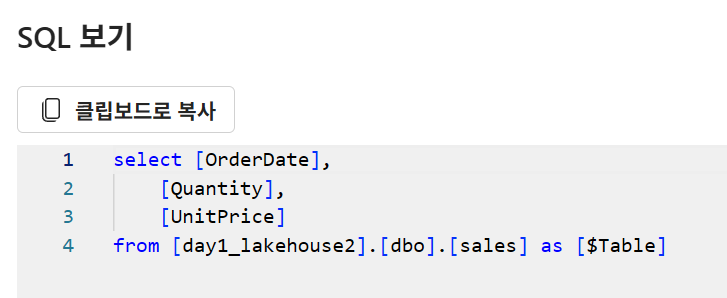
SQL 보기 선택으로 SQL 코드 확인 가능
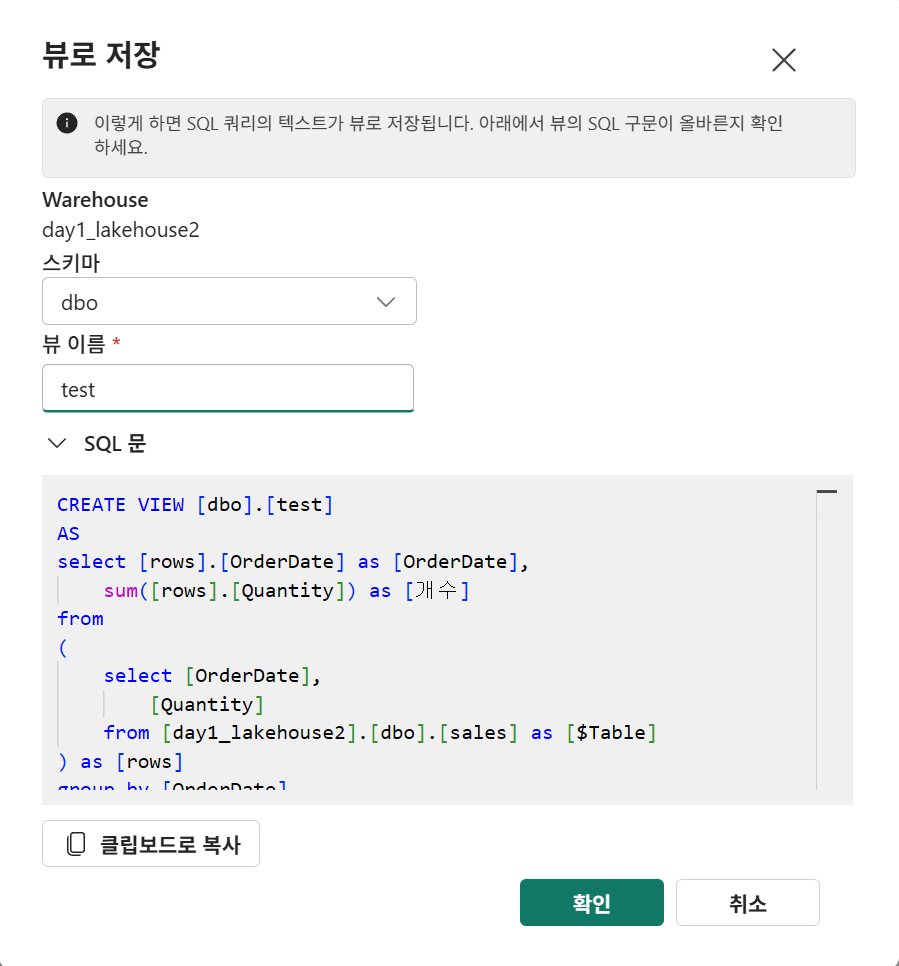
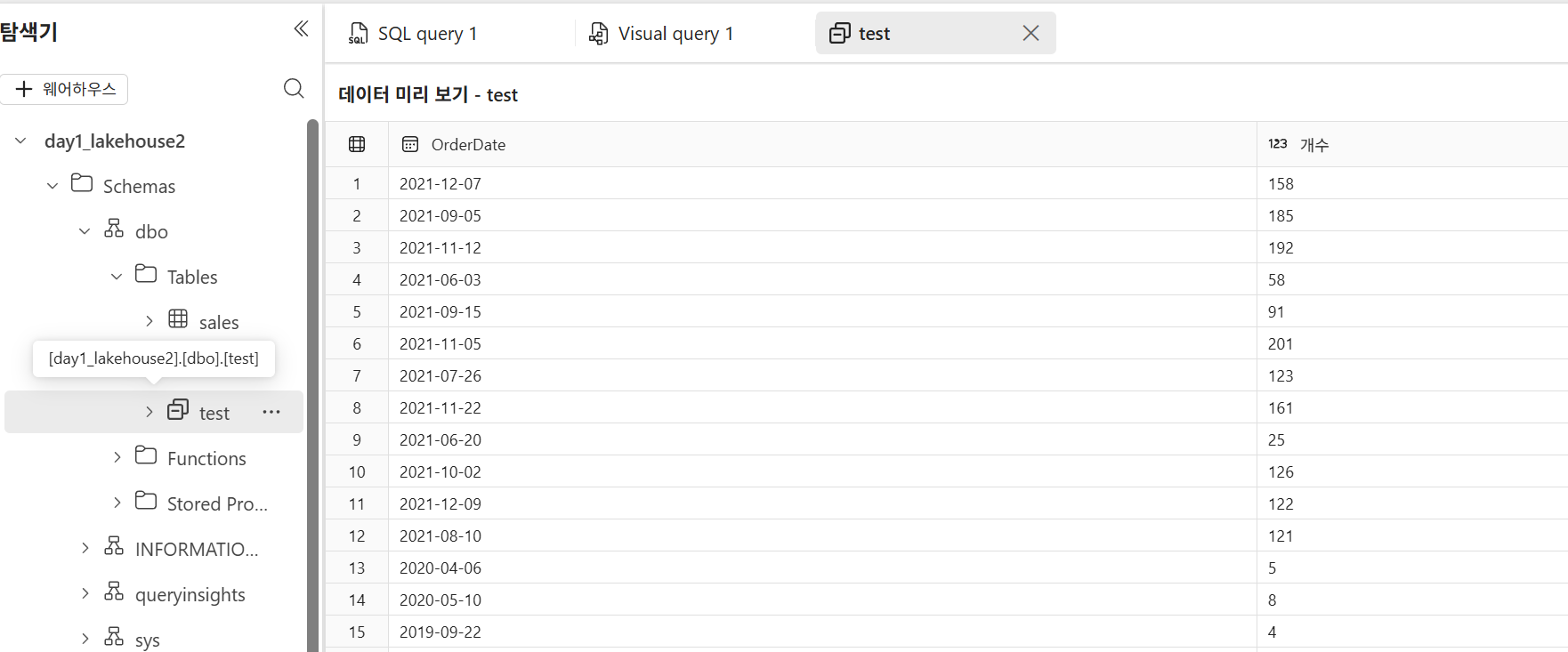
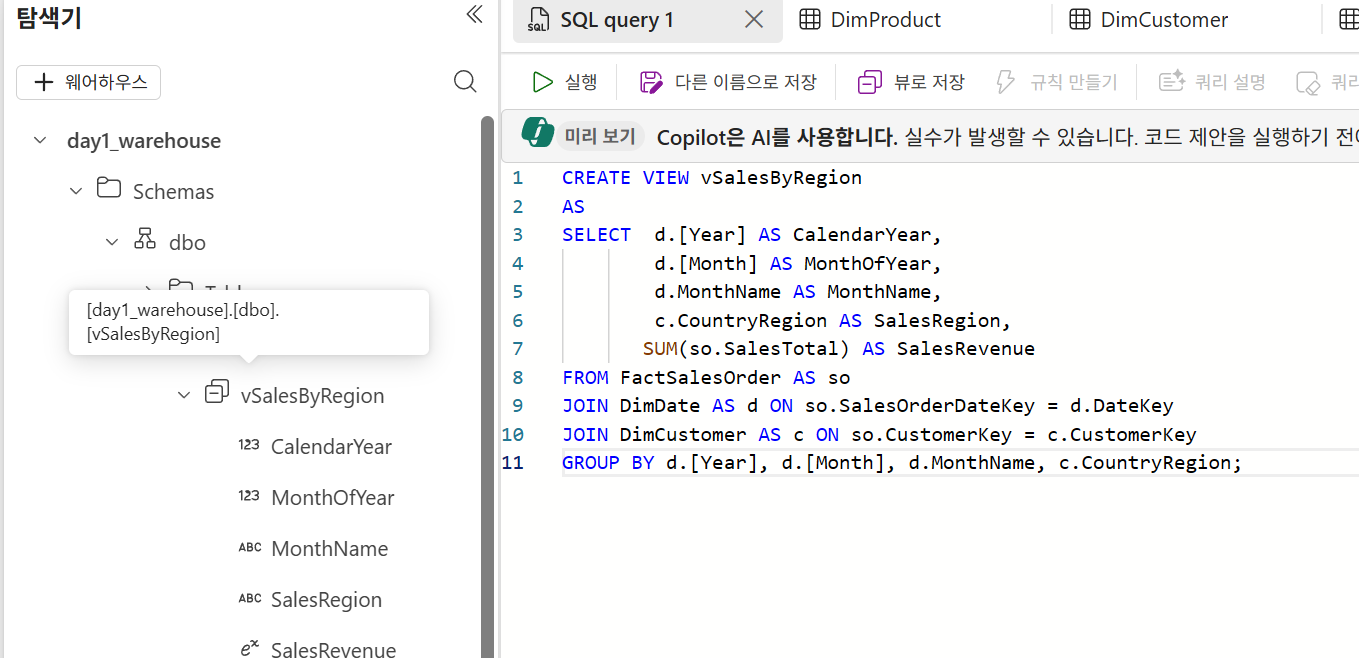
뷰로 저장도 가능
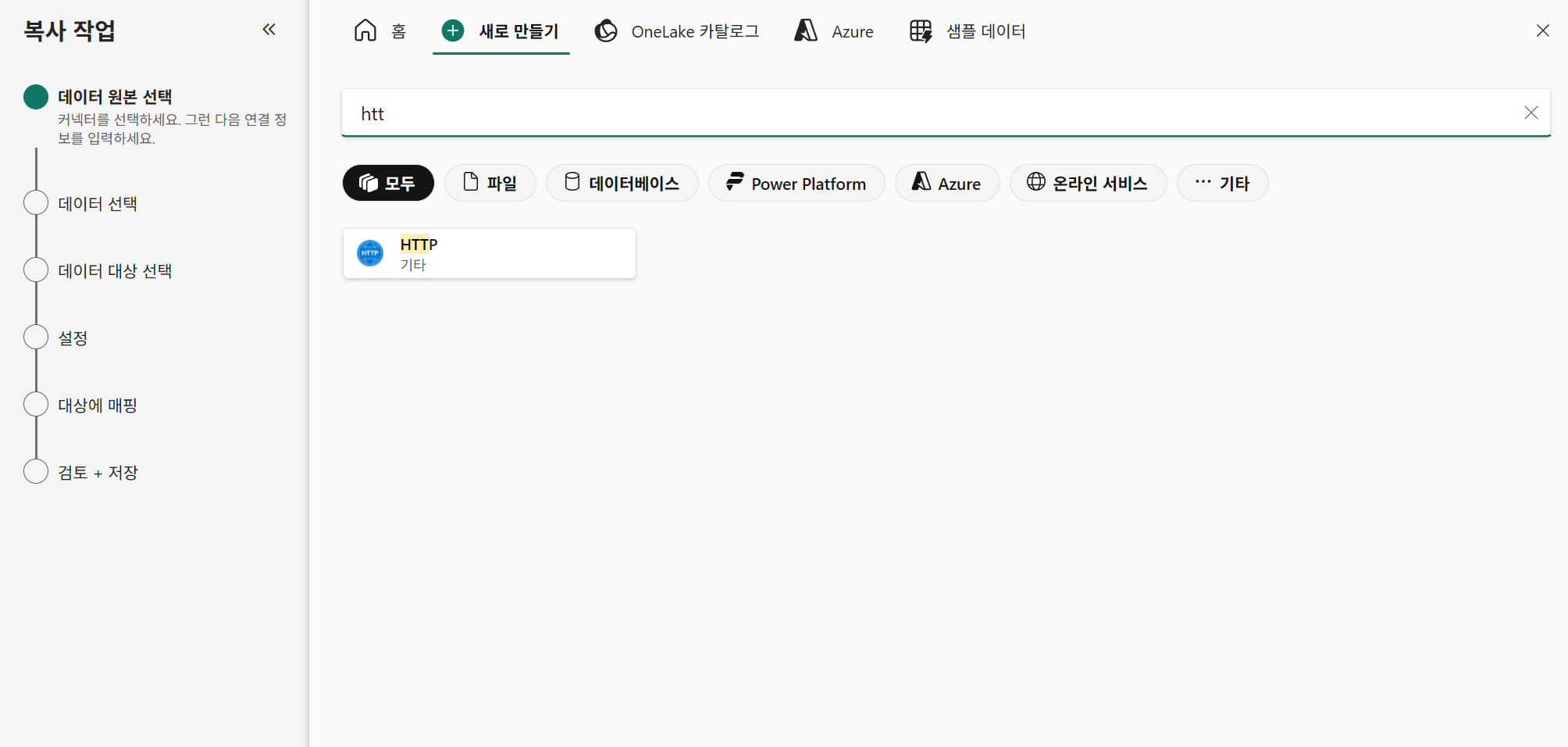
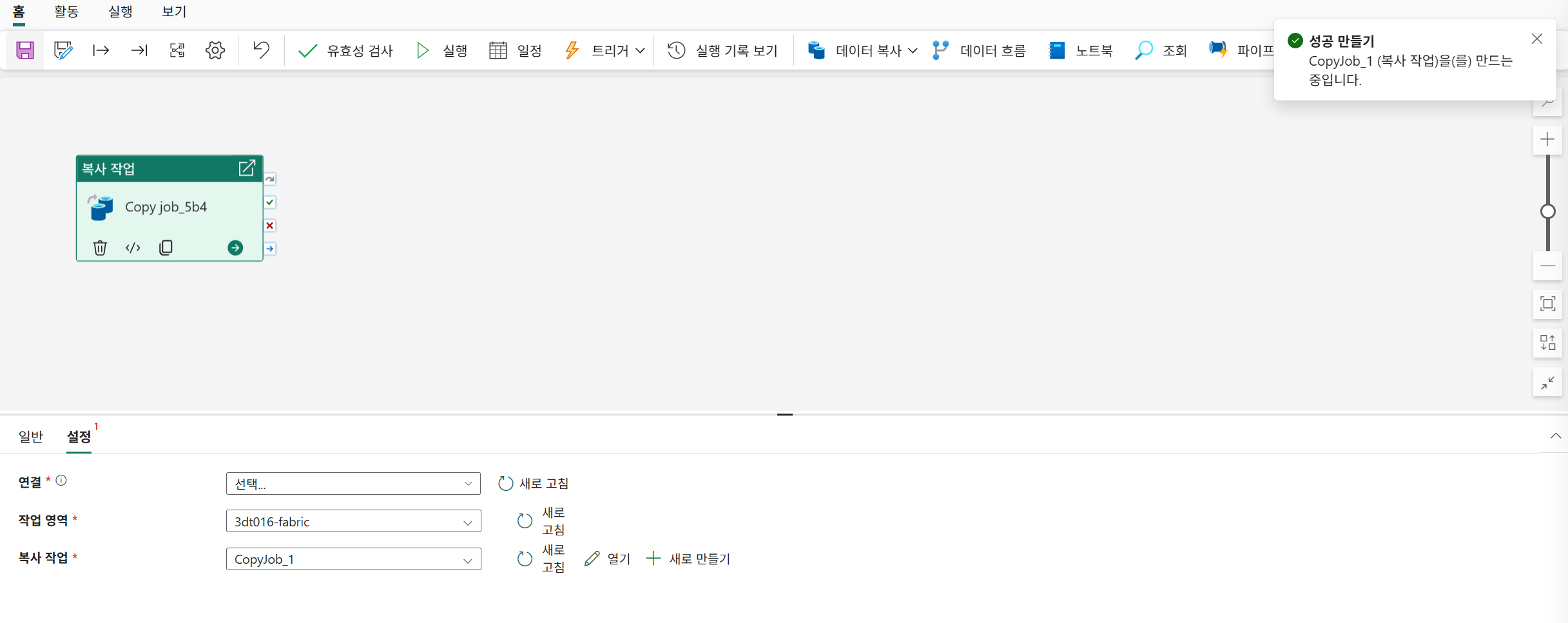
파이프라인으로 데이터 가져오기(HTTP)
https://microsoftlearning.github.io/mslearn-fabric/Instructions/Labs/04-ingest-pipeline.html
파이프라인 생성
작업영역-좌상단 새항목-파이프라인 선택
데이터 복사 도우미 선택

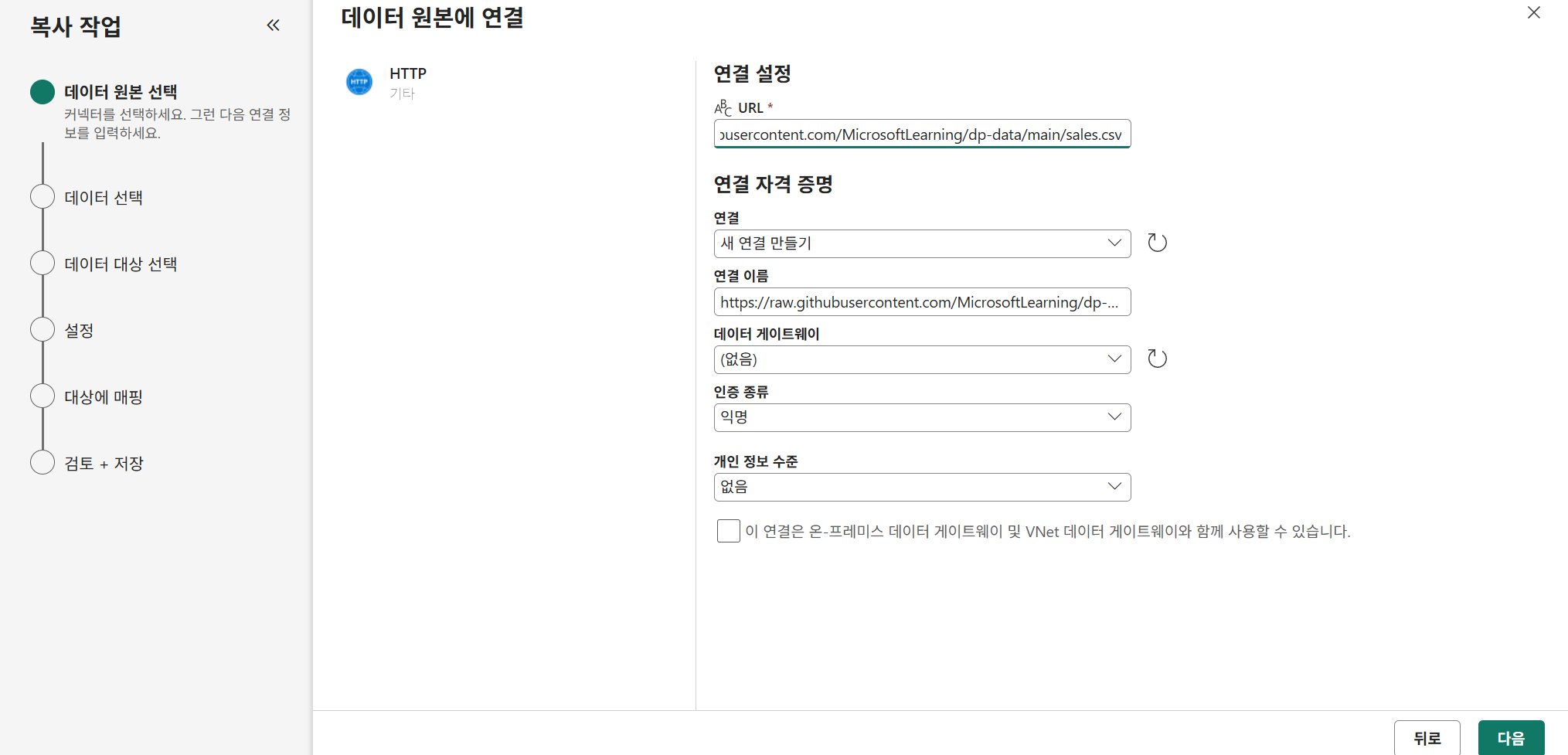
기존 레이크하우스 선택
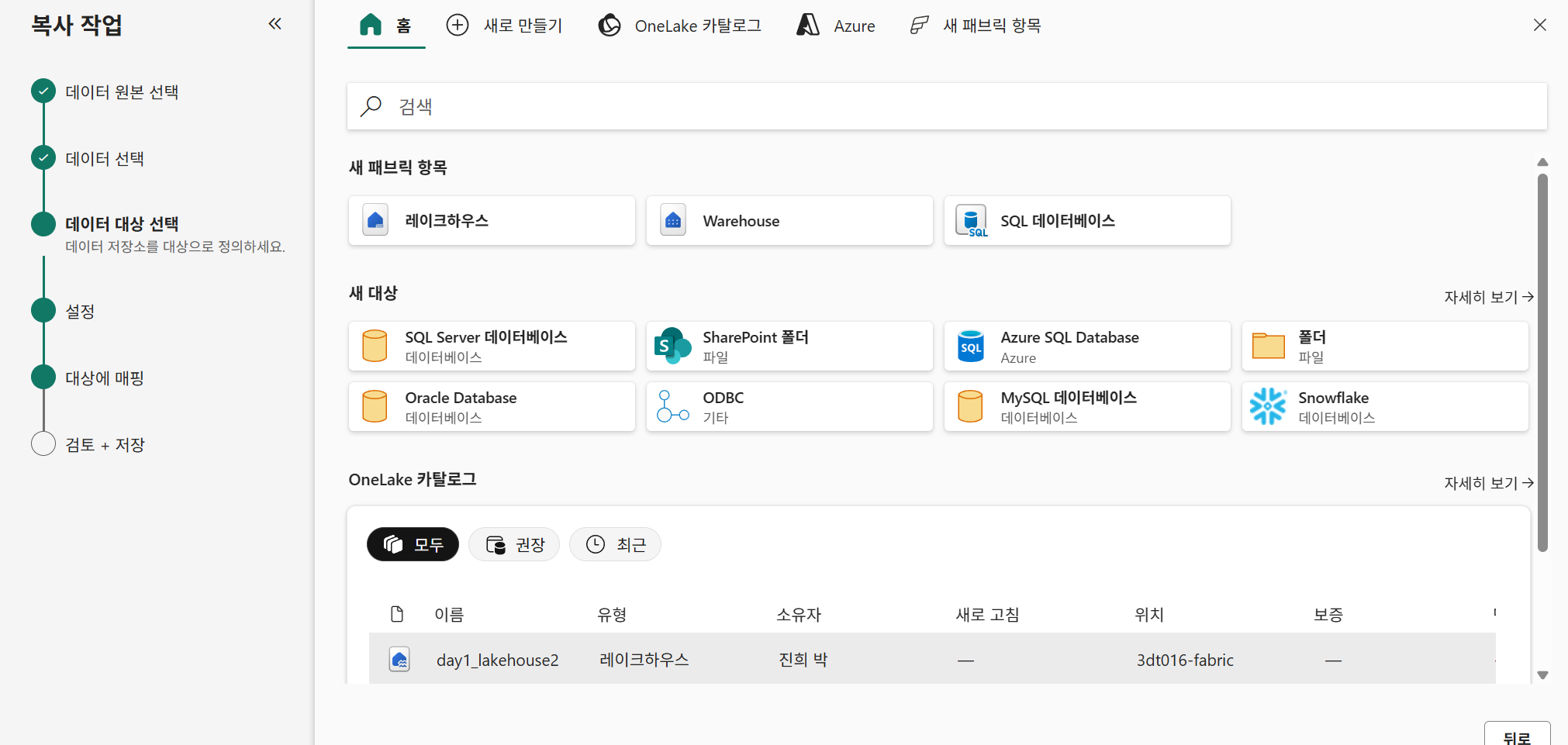
연결에 파이프라인을 추가해야하는데, 안 뜨는 현상이 발생했다.
그래서 일단 작업영역으로 나와 직접 1회 파이프라인을 실행했다.
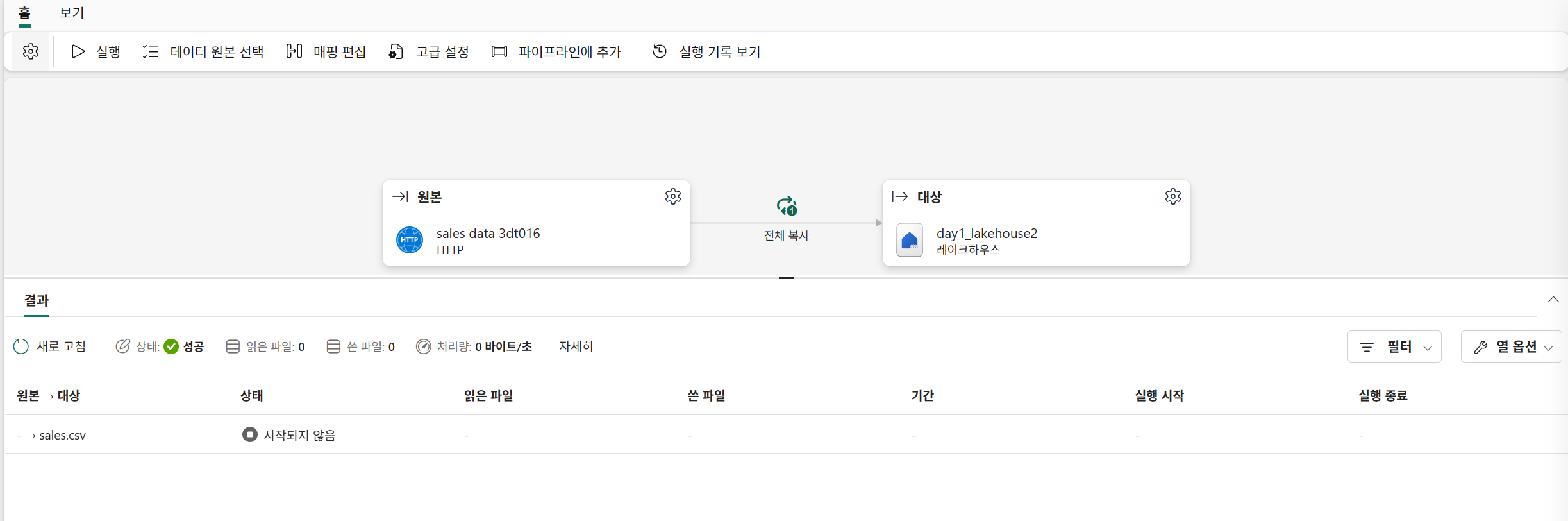
이렇게 하면 복사작업 권한이 생긴다..고했으나 생기지 않았다.
우상단 점 3개 - 설정 - 연결 및 게이트웨이 관리
안뜬다면 자격증명을 새로 만들어야 한다.
좌상단 신규 후 클라우드 선택
추가하면 이제 표시된다.
노트북 생성
여기서도 표준 세션을 할당할 때 403 에러가 발생했다. 다른 분이 세션을 끊어주셔야만 쓸 수 있었다. 문제가 많다.

또한 세션을 받더라도, Storage Blob Data Contributor 권한이 없어 에러가 발생했다.
작업 영역 설정에서
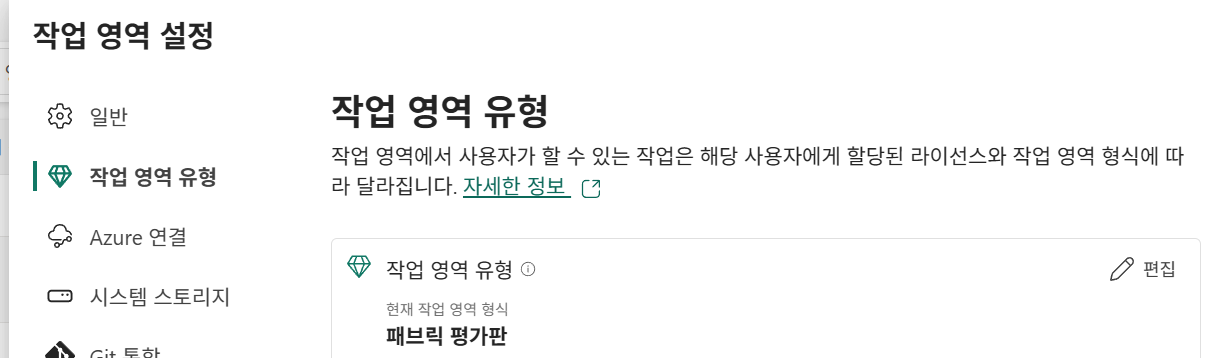
작업 영역 유형 설정이 가능하다.
여기서 원격 컴퓨팅 리소스를 설정할 수 있다.
일단은 강의에선 5개의 컴퓨팅 리소스로 사람들을 분할하여 해결하고자 했다.
그럼에도 400 에러가 발생했다.
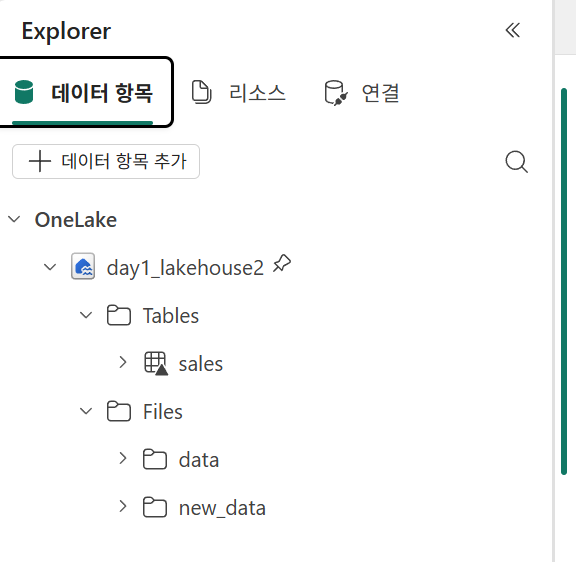
알고보니 내가 데이터 항목을 추가하지 않아서였다.
이후에도 강사님께서 추가 컴퓨팅 리소스를 마련해주심에도 세션이 시작되지 않아 노트북을 아예 새로 생성했더니 세션 설정이 되었다.
미묘하게 처리 확인이 힘든 에러가 많은듯하다.
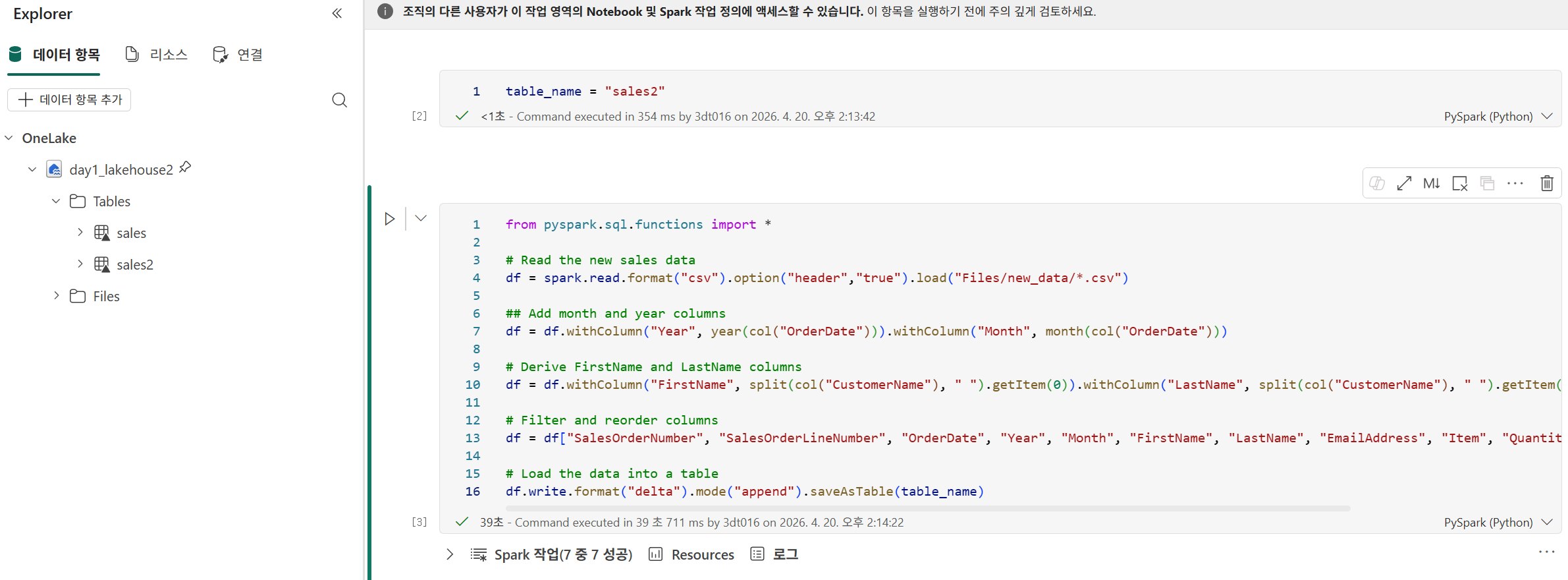
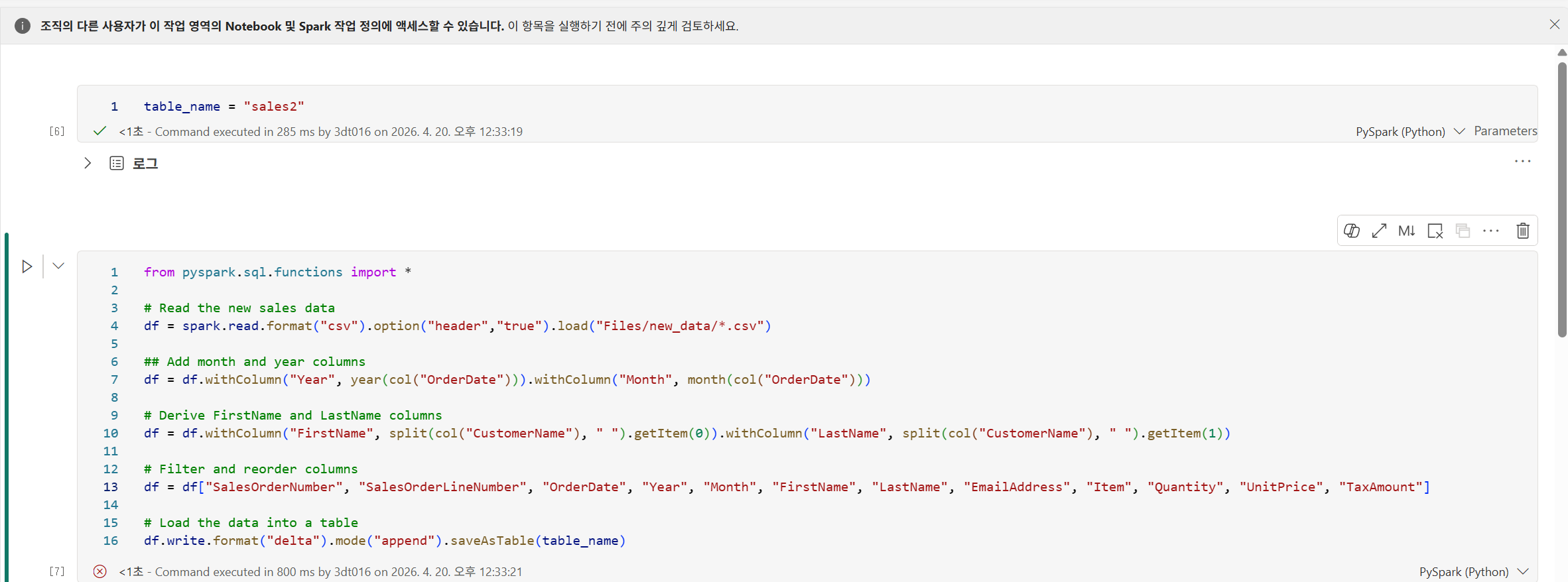
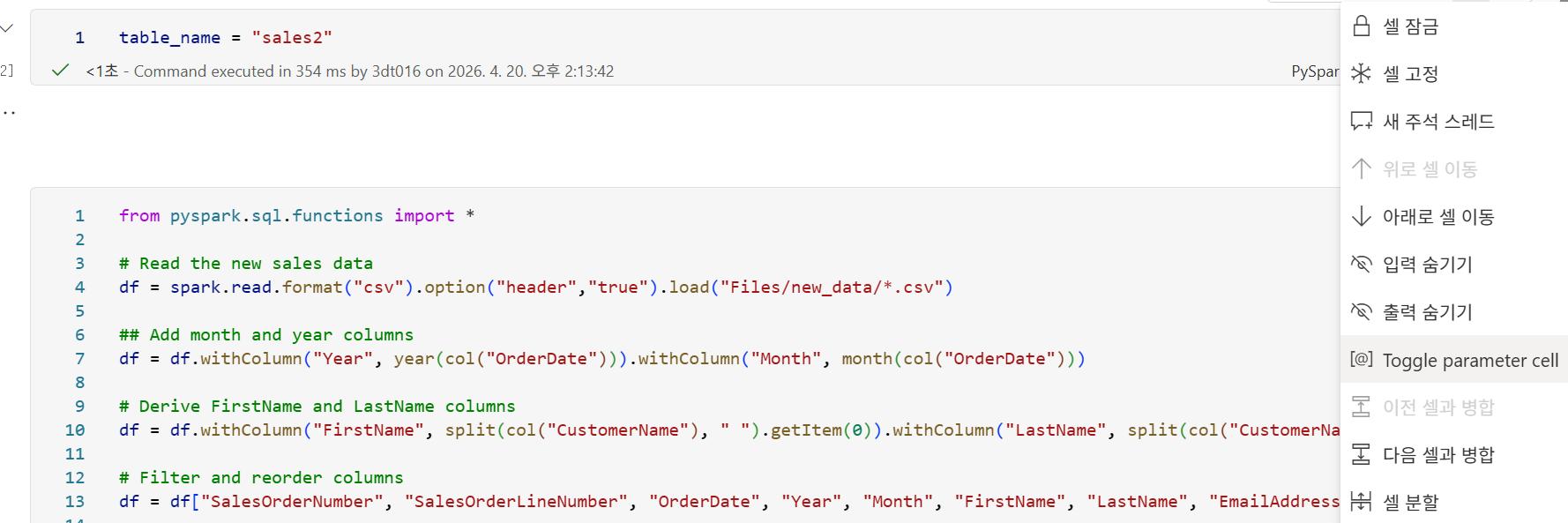
참고로 변수처럼 테이블 이름을 바꿀 수 있게 하기 위해서는 toggle parameter cell 을 선택해줘야 한다.
파이프라인에 노트북 추가
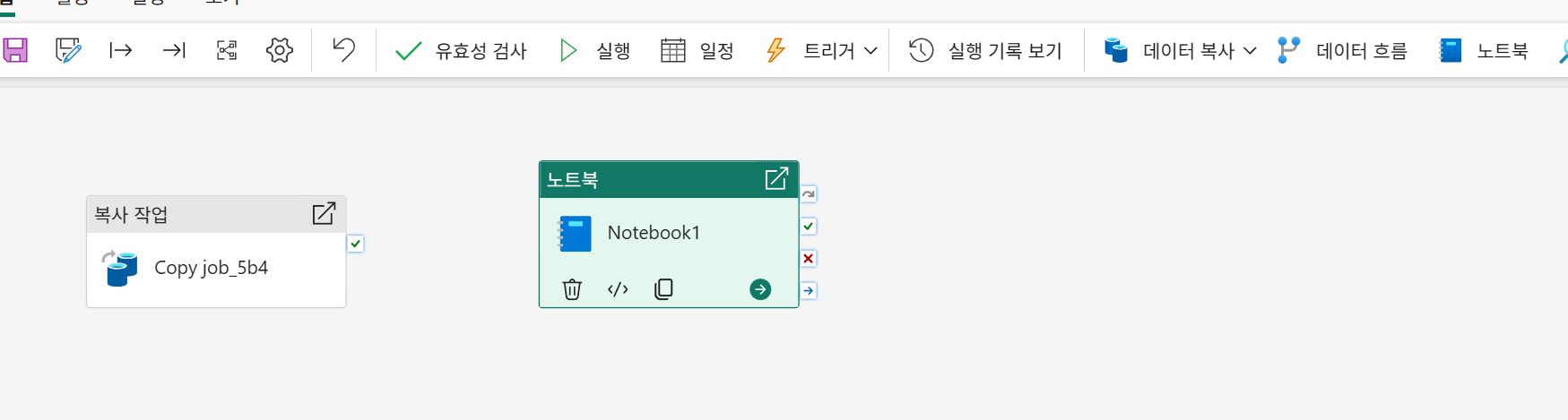
우상단 노트북 선택으로 추가
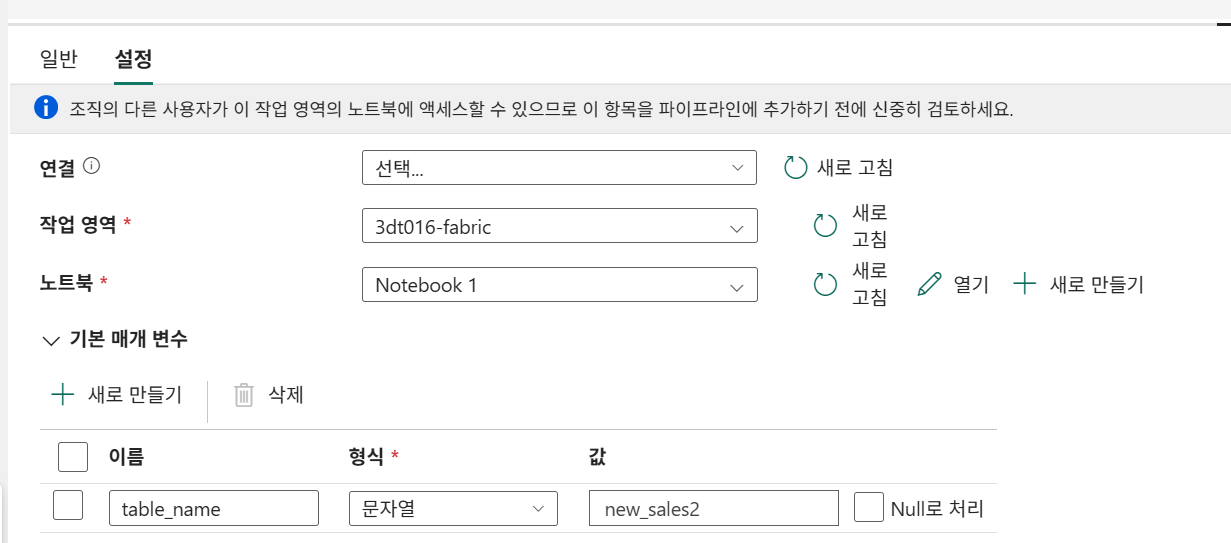
이후 기본 매개변수 추가
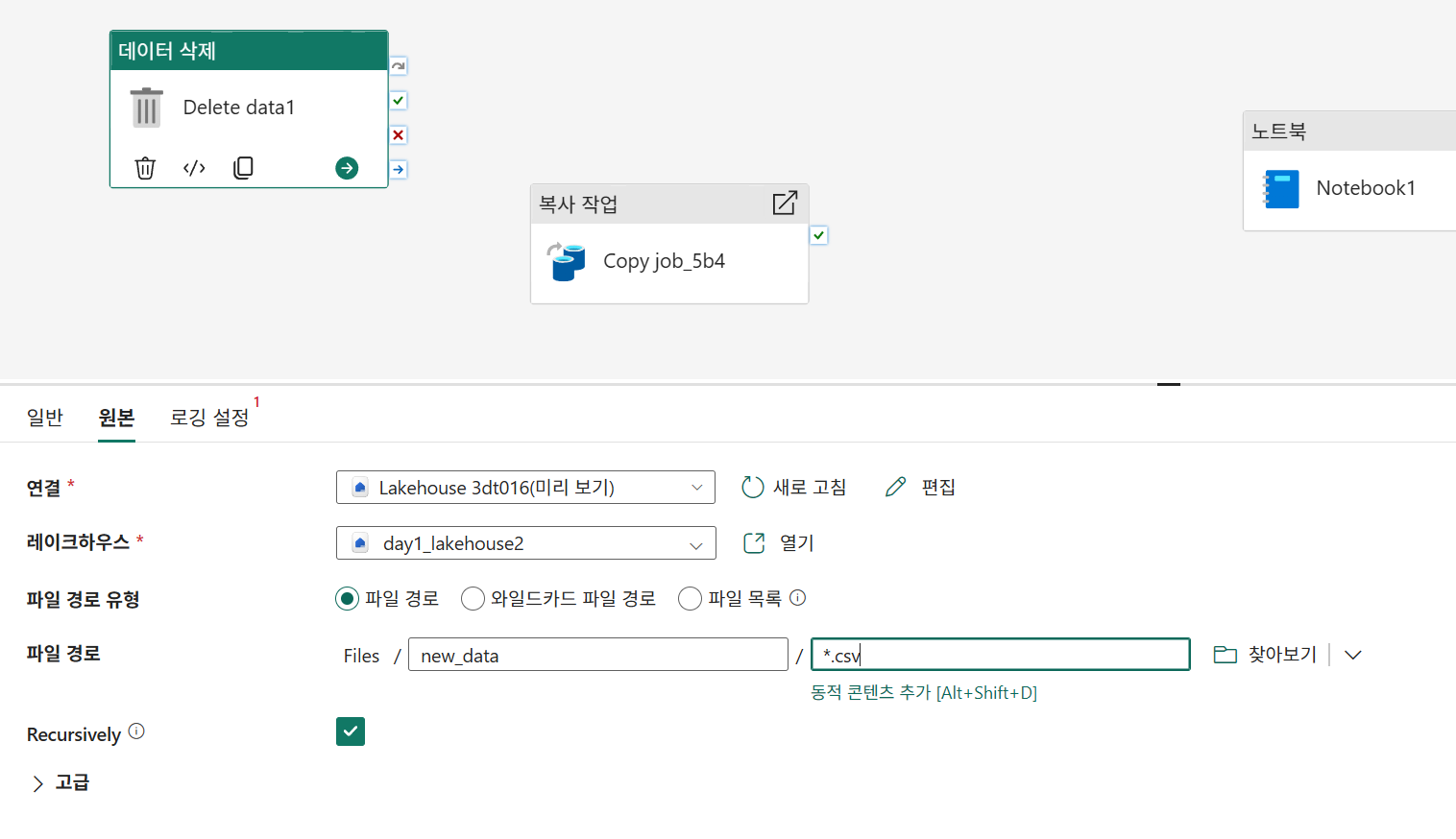
데이터 삭제를 추가하여 기존에 만들어둔 csv를 삭제한다.
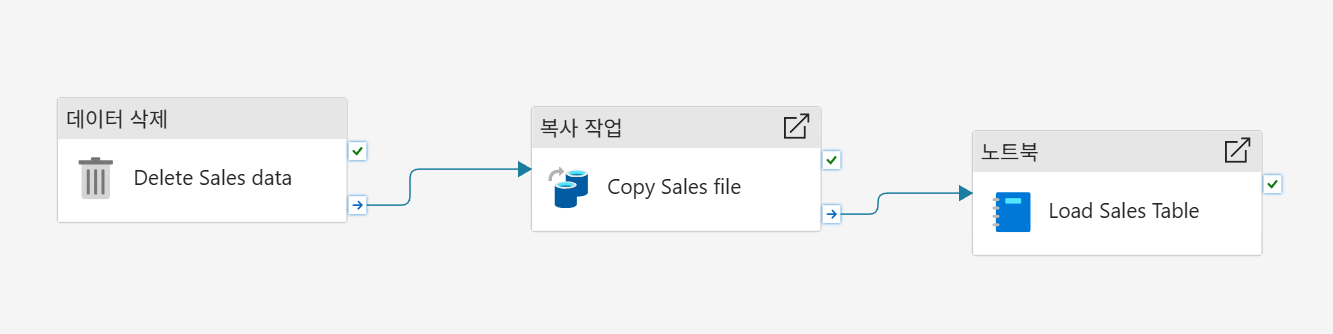
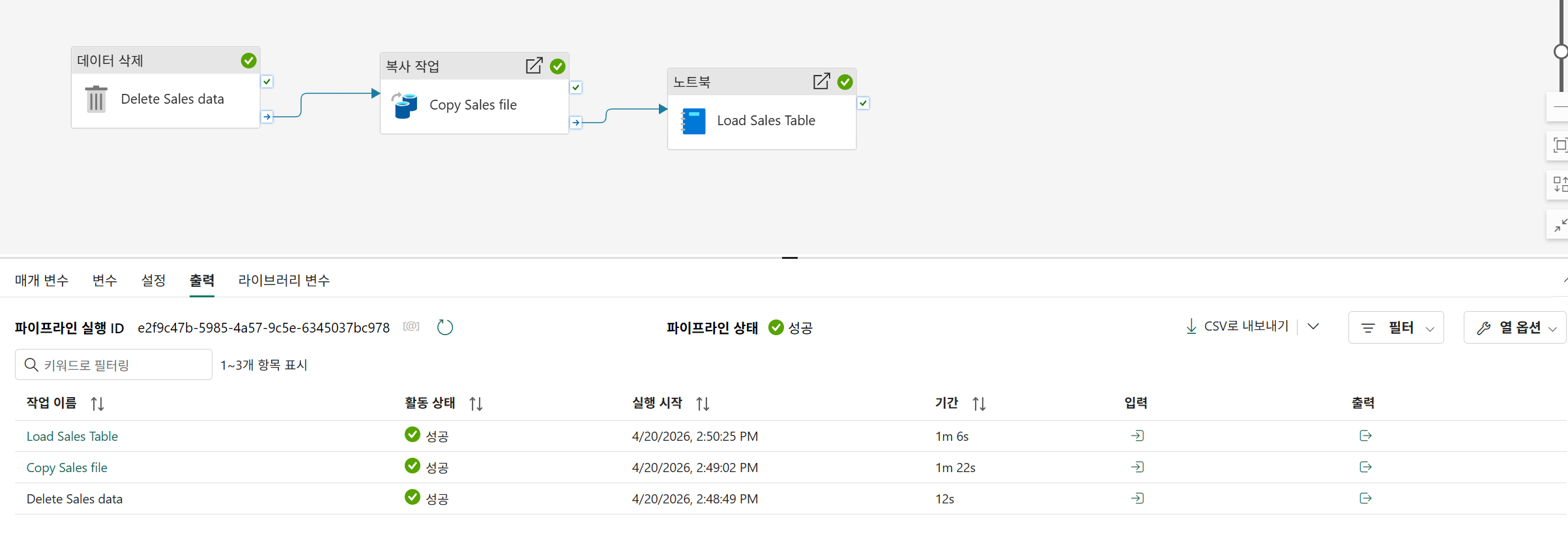
기존의 sales2가 아닌, newsales2로 테이블이 생성됨을 확인 가능하다

데이터 웨어하우스에서 데이터 분석
https://microsoftlearning.github.io/mslearn-fabric/Instructions/Labs/06-data-warehouse.html

이후 https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/create-dw.txt 의 쿼리로 데이터 생성
- DimCustomer
- DimDate
- DimProduct
- FactSalesOrder
쿼리
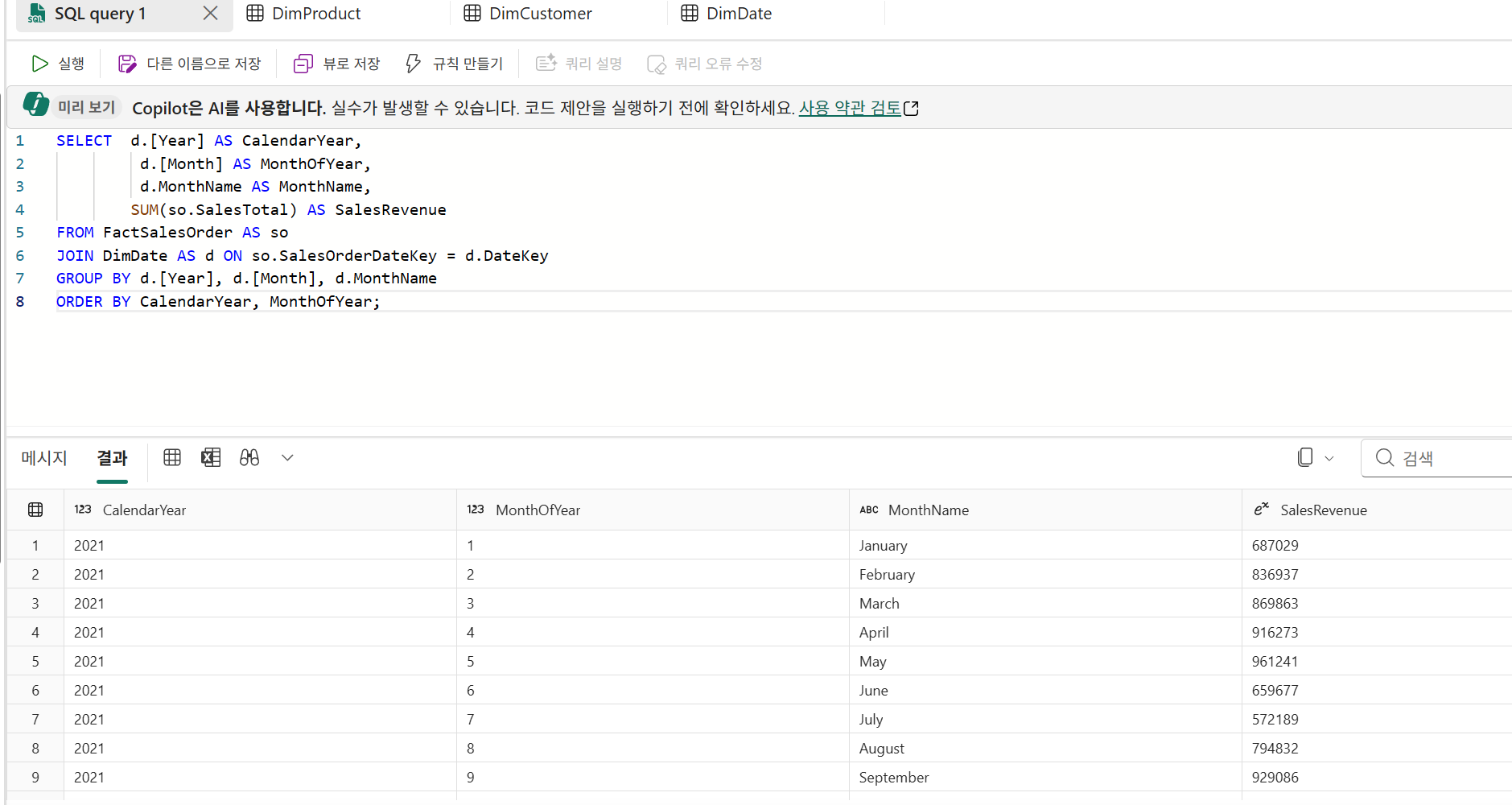
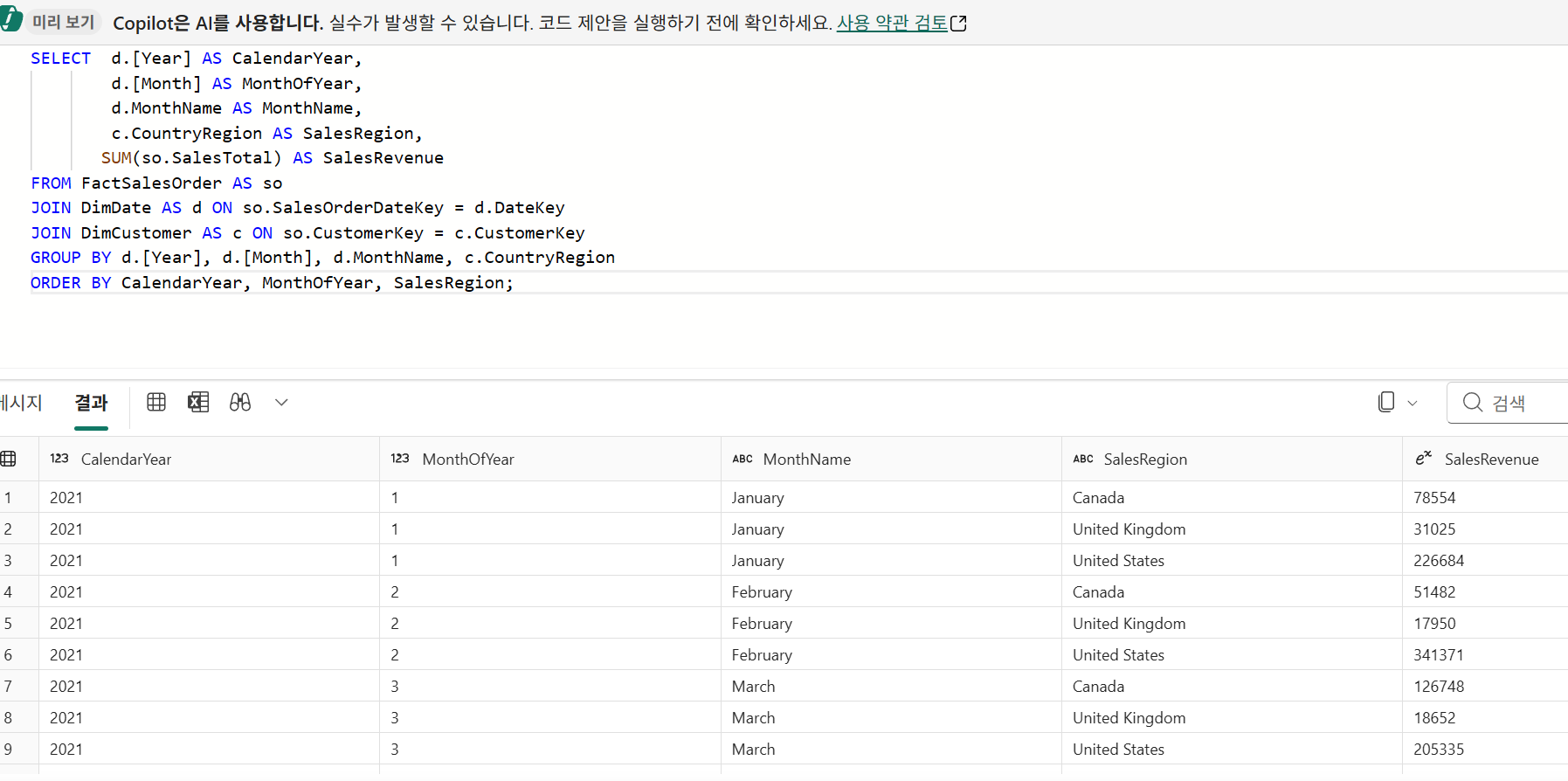
뷰 생성
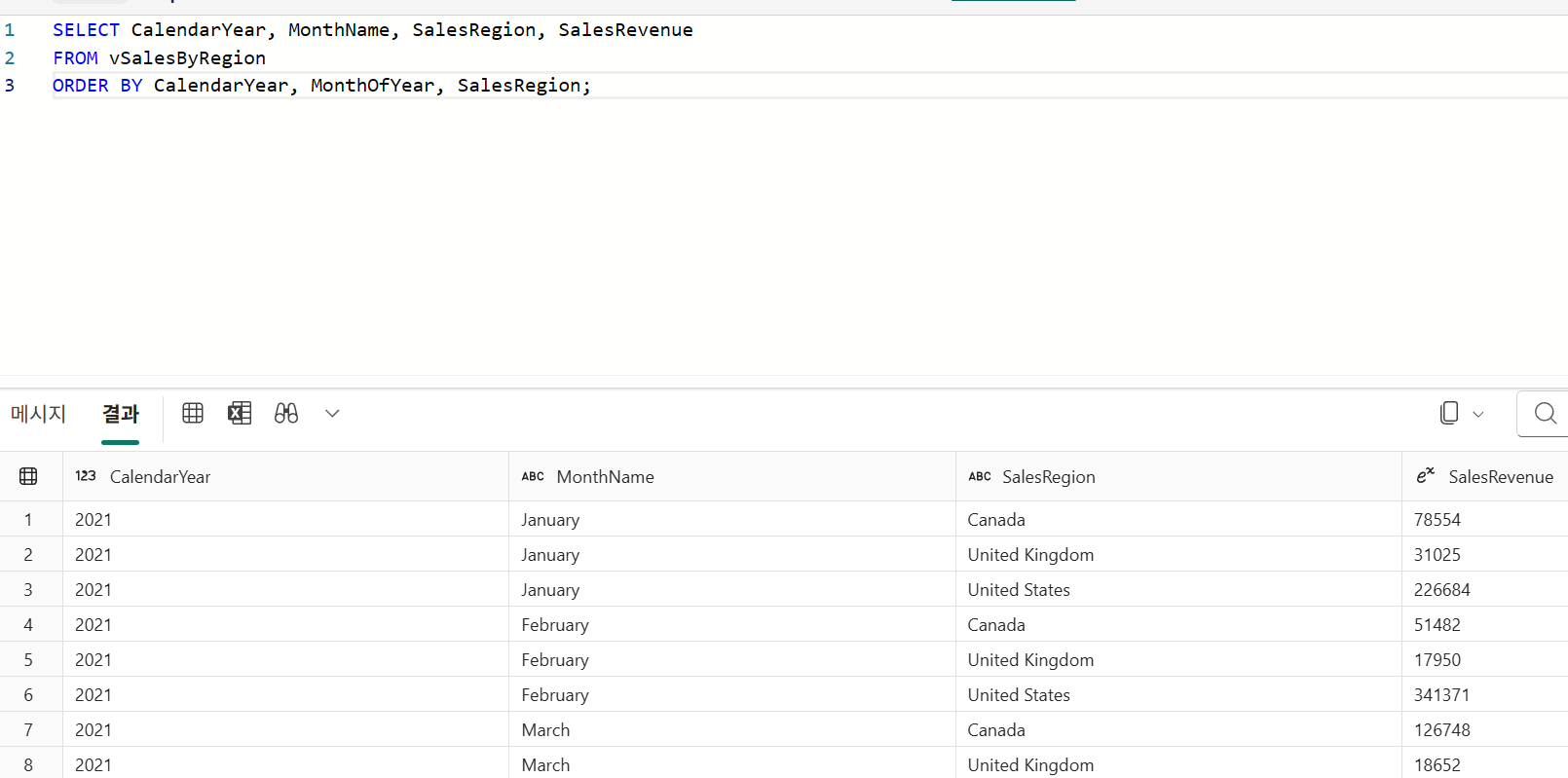
Visual Query
Fabric에서 Apache Spark를 사용하여 데이터 분석
https://microsoftlearning.github.io/mslearn-fabric/Instructions/Labs/02-analyze-spark.html
데이터 읽어오기
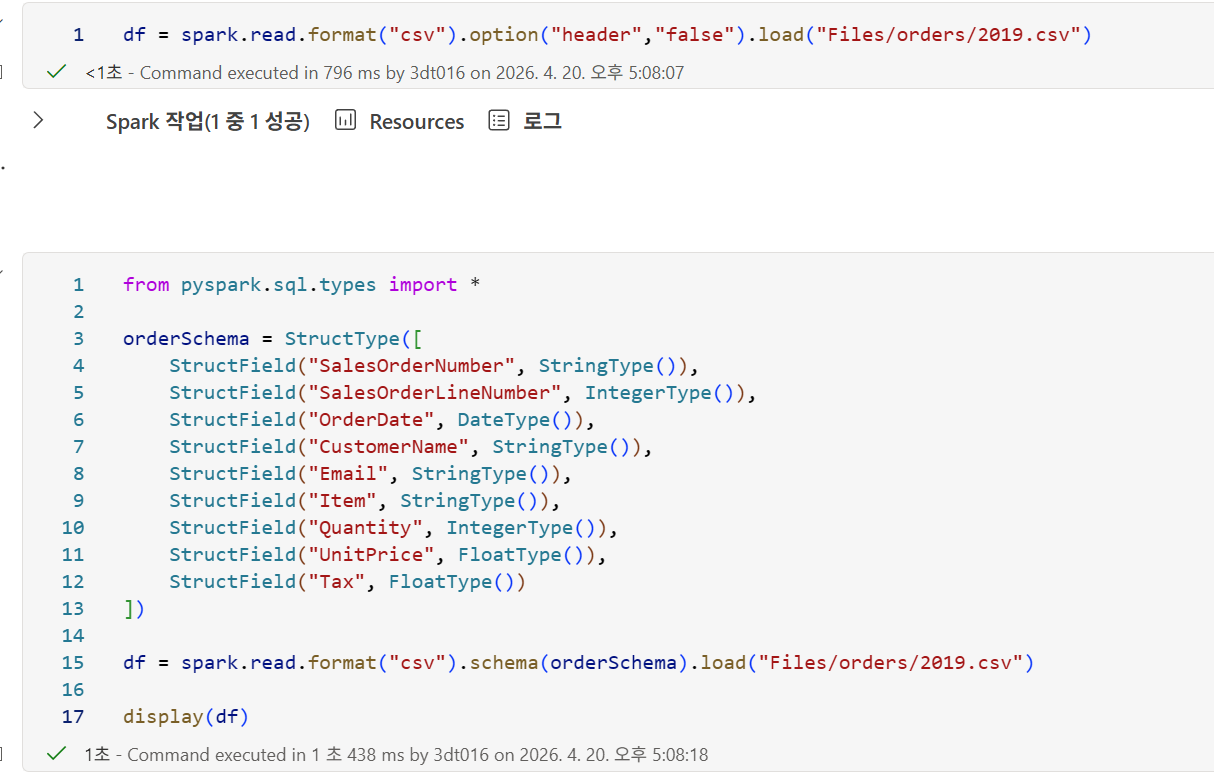
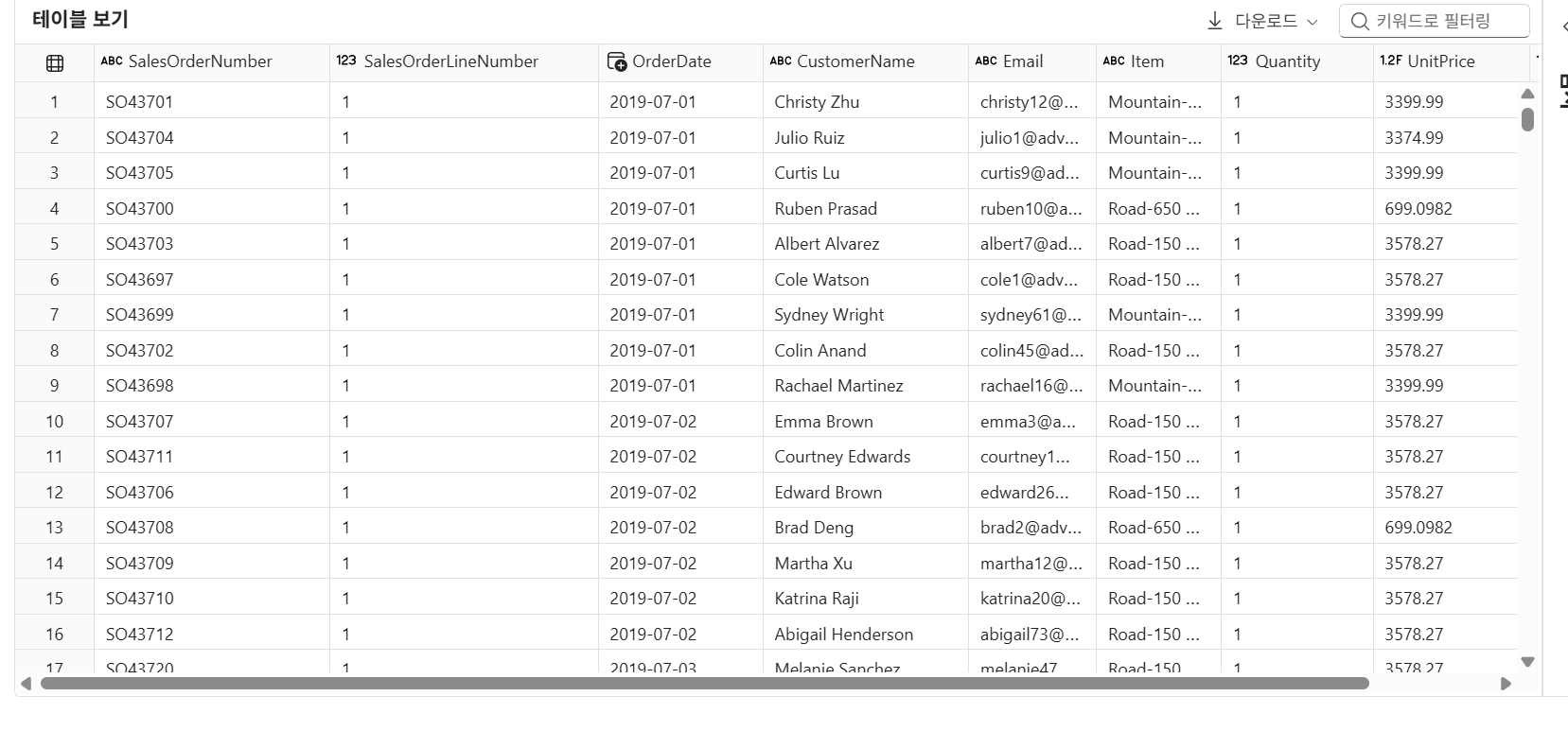
와일드카드를 이용하여 전체 데이터를 가져올 수 있다.
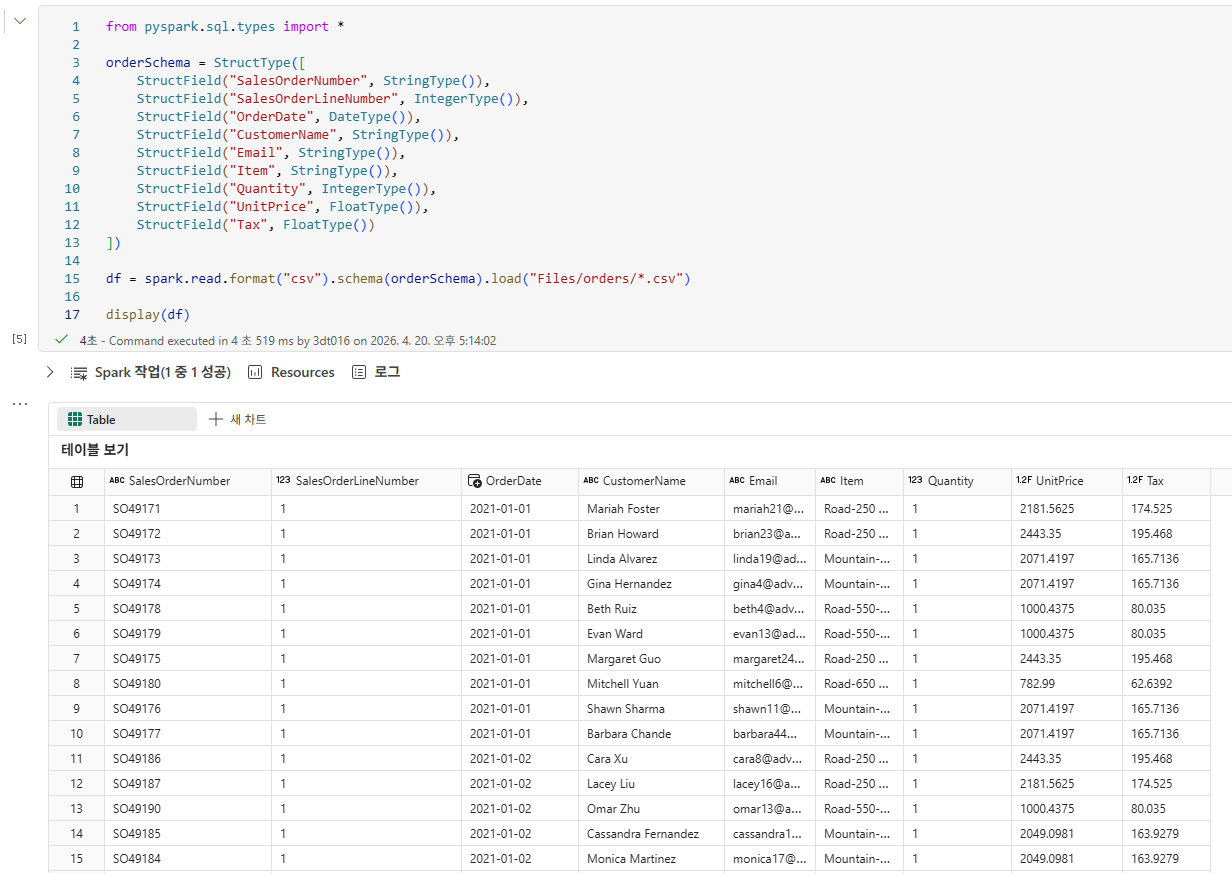
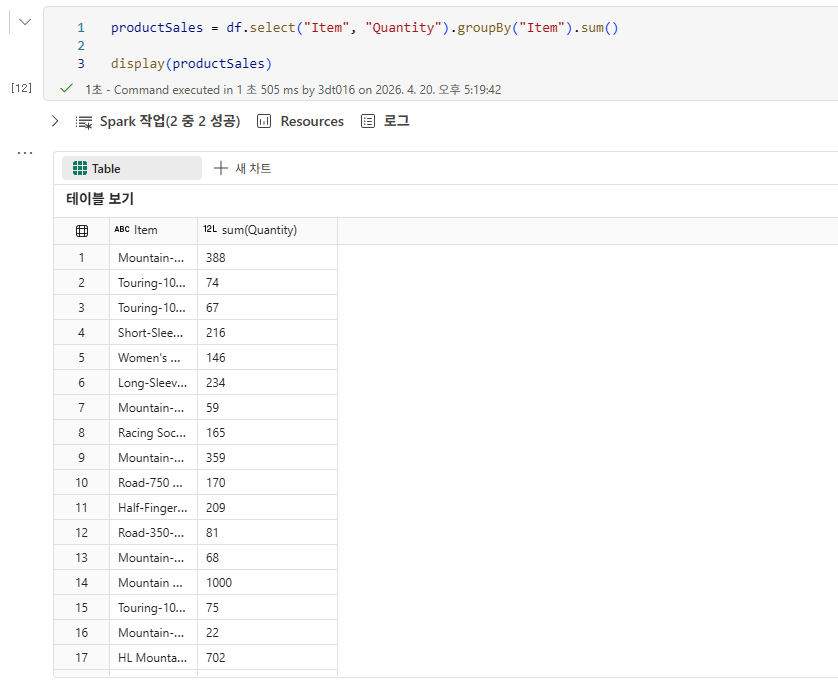
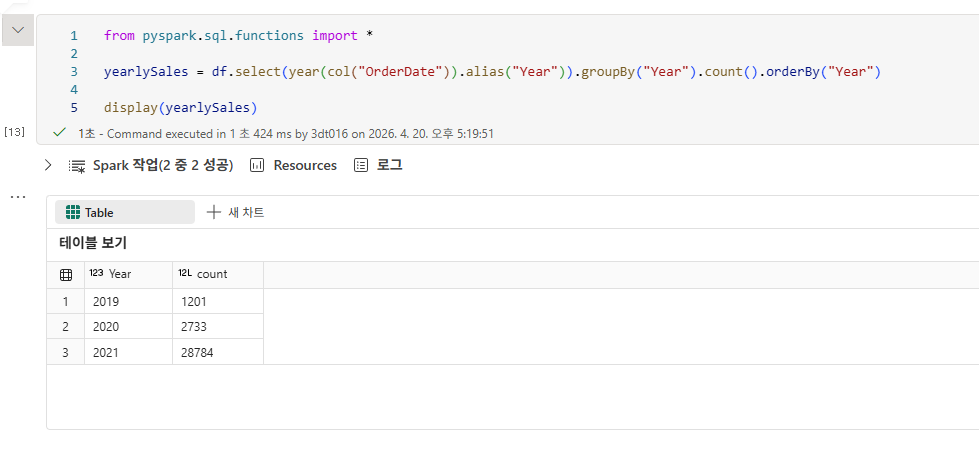
DataFrame에서 데이터 탐색
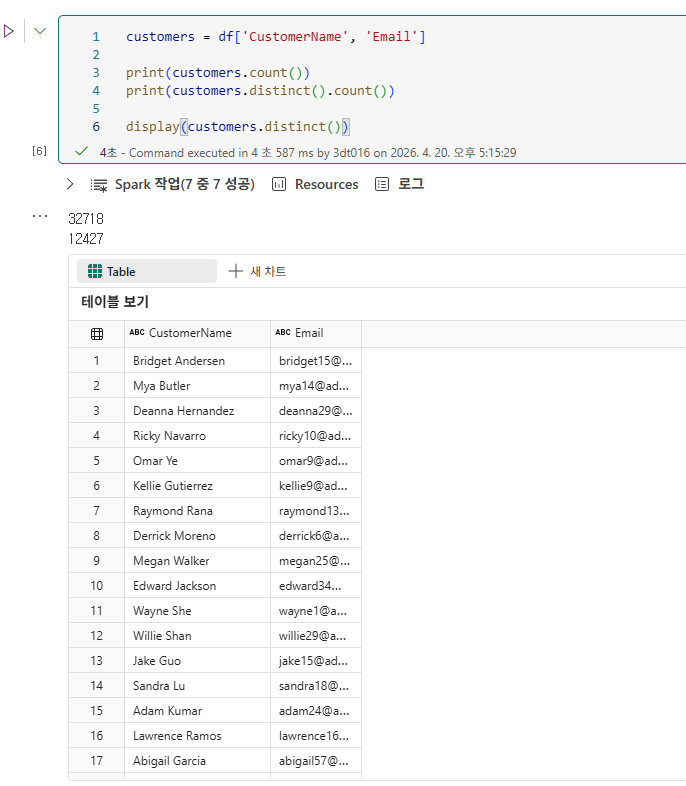
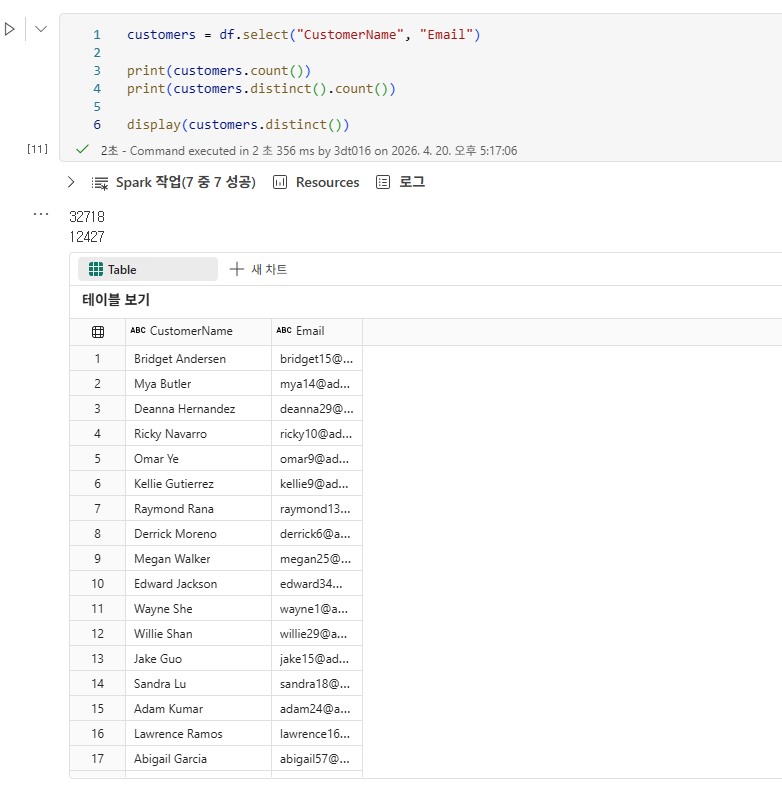
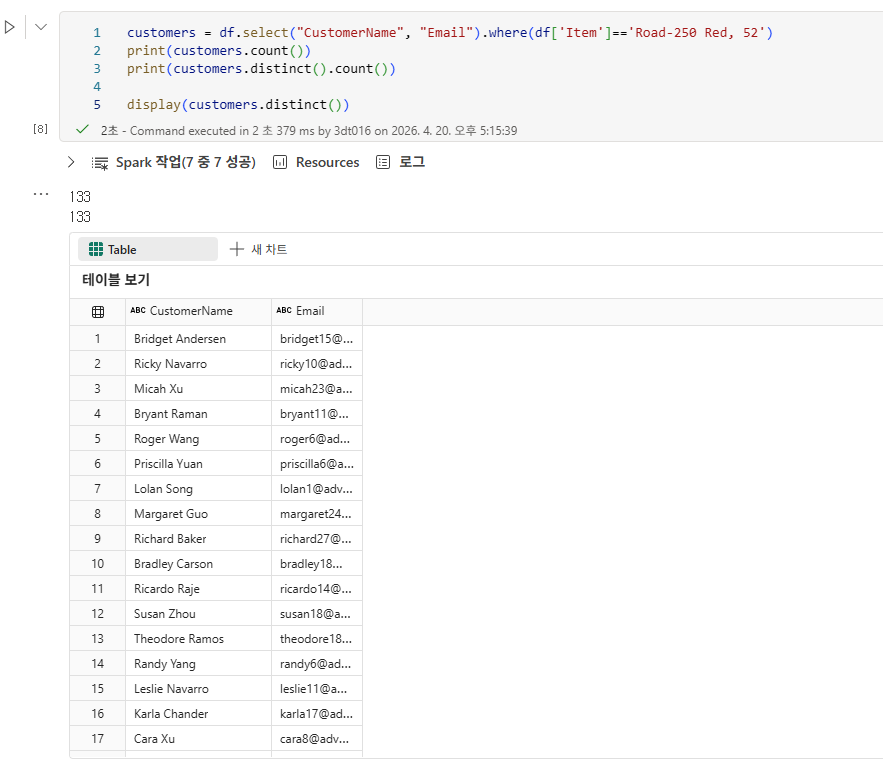
DataFrame에서 데이터 집계 및 그룹화