[MicrosoftDataSchool] 81일차 - SQL Server VM → Azure SQL Database 마이그레이션, 데이터베이스 조각화
Microsoft Data School 3기

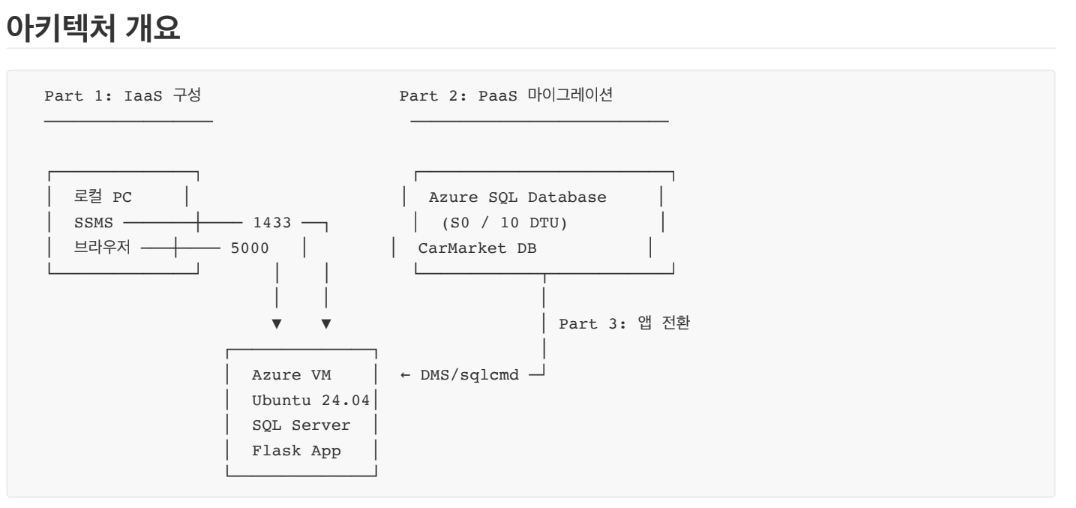
CarMarket 중고차 MVP — IaaS에서 PaaS로
아키텍처 개요
#!/usr/bin/env bash
# ============================================================
# 01-setup-vm-sqlserver.sh
# Azure VM 생성 → SQL Server 2025 설치 → 외부 SSMS 접근 → 시딩
#
# 로컬 PC (Mac/Linux/WSL) 에서 실행
#
# 사용법:
# bash 01-setup-vm-sqlserver.sh
#
# 환경변수 사전 설정 가능:
# export RG=rg-carmarket-lab LOC=koreacentral SA_PASSWORD='YourP@ssw0rd!'
# bash 01-setup-vm-sqlserver.sh
# ============================================================
set -euo pipefail
# =============================================================
# 기본값
# =============================================================
RG="${RG:-rg-carmarket-lab}"
LOC="${LOC:-koreacentral}"
VM="${VM:-vm-carmarket-$(date +%m%d)}"
VM_SIZE="${VM_SIZE:-Standard_B2s}"
USER_NAME="${USER_NAME:-azureuser}"
SSH_KEY="${SSH_KEY:-$HOME/.ssh/id_rsa.pub}"
SA_PASSWORD="${SA_PASSWORD:-}"
REPO_URL="https://github.com/jhjwlee/sqlvm_usedcar.git"
# 색상
G='\033[0;32m'; Y='\033[0;33m'; R='\033[0;31m'; B='\033[0;34m'; NC='\033[0m'
banner() { echo ""; echo -e "${B}═══════════════════════════════════════════════════${NC}"; echo -e "${B} $1${NC}"; echo -e "${B}═══════════════════════════════════════════════════${NC}"; }
step() { echo ""; echo -e "${G}▶ [$1/$TOTAL_STEPS]${NC} $2"; }
ok() { echo -e "${G} ✓${NC} $1"; }
warn() { echo -e "${Y} ⚠${NC} $1"; }
fail() { echo -e "${R} ✗${NC} $1"; }
abort() { echo -e "${R}❌ $1${NC}"; exit 1; }
TOTAL_STEPS=8
LOG_FILE="/tmp/carmarket-setup-$(date +%Y%m%d-%H%M%S).log"
exec > >(tee -a "$LOG_FILE") 2>&1
banner "CarMarket Lab — VM + SQL Server + SSMS 접근 자동 설정"
echo " 리소스 그룹: $RG"
echo " 위치: $LOC"
echo " VM 이름: $VM"
echo " VM 크기: $VM_SIZE"
echo " 로그 파일: $LOG_FILE"
# =============================================================
# Step 1: 사전 점검
# =============================================================
step 1 "사전 점검 (Azure CLI · SSH 키 · 로그인)"
command -v az >/dev/null 2>&1 || abort "Azure CLI 미설치. https://aka.ms/azcli"
ok "Azure CLI: $(az version --query '\"azure-cli\"' -o tsv 2>/dev/null || echo 'unknown')"
if ! az account show >/dev/null 2>&1; then
warn "Azure 로그인 필요"
az login
fi
ok "구독: $(az account show --query name -o tsv)"
if [ ! -f "$SSH_KEY" ]; then
warn "SSH 키 없음 → 자동 생성"
ssh-keygen -t rsa -b 4096 -N "" -f "${SSH_KEY%.pub}" -q
fi
ok "SSH 키: $SSH_KEY"
# =============================================================
# Step 2: SA 비밀번호 입력
# =============================================================
step 2 "SA 비밀번호 설정"
if [ -z "$SA_PASSWORD" ]; then
echo " SQL Server SA 비밀번호를 입력하세요."
echo " 요구사항: 8자+ / 대·소문자·숫자·특수문자 중 3종 이상"
echo " 예) CarMarket@2026"
while true; do
read -s -p " SA Password: " SA_PASSWORD; echo ""
read -s -p " Confirm: " SA_CONFIRM; echo ""
if [ "$SA_PASSWORD" = "$SA_CONFIRM" ] && [ ${#SA_PASSWORD} -ge 8 ]; then
break
fi
echo -e "${R} 비밀번호 불일치 또는 8자 미만. 재입력.${NC}"
done
fi
ok "SA 비밀번호 설정 완료 (${#SA_PASSWORD}자)"
# 비용 안내
echo ""
echo " 예상 비용: VM(B2s) ≈ \$0.5/일"
echo " 예상 시간: 약 10~15분"
read -p " 진행? (y/N): " ok_proceed
[[ "$ok_proceed" =~ ^[Yy]$ ]] || abort "취소됨"
# =============================================================
# Step 3: Resource Group + VM 생성
# =============================================================
step 3 "Azure 리소스 생성 (RG + VM)"
if az group show -n "$RG" >/dev/null 2>&1; then
ok "RG '$RG' 이미 존재 (재사용)"
else
az group create -n "$RG" -l "$LOC" --output none
ok "RG '$RG' 생성"
fi
if az vm show -g "$RG" -n "$VM" >/dev/null 2>&1; then
warn "VM '$VM' 이미 존재 → 재사용"
else
echo " → VM 생성 중 (3~5분)..."
az vm create \
--resource-group "$RG" \
--name "$VM" \
--image Ubuntu2404 \
--size "$VM_SIZE" \
--admin-username "$USER_NAME" \
--ssh-key-values "$SSH_KEY" \
--public-ip-sku Standard \
--storage-sku Premium_LRS \
--os-disk-size-gb 32 \
--output none
ok "VM '$VM' 생성 완료"
fi
PUBIP=$(az vm show -d -g "$RG" -n "$VM" --query publicIps -o tsv)
ok "Public IP: $PUBIP"
# =============================================================
# Step 4: NSG 포트 오픈 (22, 1433, 5000)
# =============================================================
step 4 "NSG 포트 오픈 — SSH(22) + SQL(1433) + Flask(5000)"
# NSG 이름 자동 탐색
NSG_NAME=$(az network nsg list -g "$RG" --query "[0].name" -o tsv 2>/dev/null || echo "${VM}NSG")
open_port() {
local PORT=$1 PRIORITY=$2 NAME=$3
if az network nsg rule show -g "$RG" --nsg-name "$NSG_NAME" -n "$NAME" >/dev/null 2>&1; then
ok "$NAME ($PORT) 이미 존재"
else
az vm open-port -g "$RG" -n "$VM" --port "$PORT" --priority "$PRIORITY" --output none 2>/dev/null || true
ok "$NAME ($PORT) 오픈"
fi
}
open_port 1433 1010 "allow_sql_1433"
open_port 5000 1020 "allow_flask_5000"
ok "NSG 규칙 적용 완료"
# =============================================================
# Step 5: SSH 대기 + 접속
# =============================================================
step 5 "SSH 연결 대기"
echo " → SSH 준비 대기 (최대 90초)..."
for i in $(seq 1 45); do
if ssh -o StrictHostKeyChecking=no -o ConnectTimeout=3 -o BatchMode=yes \
"$USER_NAME@$PUBIP" "echo ready" >/dev/null 2>&1; then
ok "SSH 연결 가능"
break
fi
sleep 2
[ $i -eq 45 ] && abort "SSH 연결 90초 타임아웃"
done
# =============================================================
# Step 6: VM 내부 — SQL Server 설치 (0.0.0.0 바인딩)
# =============================================================
step 6 "VM 내부: SQL Server 2025 설치 + 0.0.0.0 바인딩"
ssh -o StrictHostKeyChecking=accept-new "$USER_NAME@$PUBIP" bash -s "$SA_PASSWORD" << 'REMOTE_SCRIPT'
#!/usr/bin/env bash
set -euo pipefail
SA_PASSWORD="$1"
G='\033[0;32m'; NC='\033[0m'
ok() { echo -e "${G} ✓${NC} $1"; }
echo "=== [VM] 패키지 업데이트 ==="
sudo apt update -qq
sudo apt install -y -qq curl wget gnupg2 software-properties-common \
apt-transport-https ca-certificates lsb-release git unzip jq > /dev/null
ok "기본 패키지"
# Swap (RAM < 6GB)
RAM_GB=$(free -g | awk 'NR==2{print $2}')
if [ "$RAM_GB" -lt 6 ] && ! swapon --show | grep -q swapfile; then
sudo fallocate -l 2G /swapfile && sudo chmod 600 /swapfile
sudo mkswap /swapfile -q && sudo swapon /swapfile
grep -q "/swapfile" /etc/fstab || echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab > /dev/null
ok "swap 2GB 활성화"
fi
echo "=== [VM] Microsoft GPG 키 + 저장소 ==="
sudo rm -f /etc/apt/sources.list.d/mssql-server-2022.list /etc/apt/sources.list.d/mssql-server-preview.list
if [ ! -f /usr/share/keyrings/microsoft-prod.gpg ]; then
curl -fsSL https://packages.microsoft.com/keys/microsoft.asc | \
sudo gpg --dearmor -o /usr/share/keyrings/microsoft-prod.gpg
fi
curl -fsSL https://packages.microsoft.com/config/ubuntu/24.04/mssql-server-2025.list | \
sudo tee /etc/apt/sources.list.d/mssql-server-2025.list > /dev/null
curl -fsSL https://packages.microsoft.com/config/ubuntu/24.04/prod.list | \
sudo tee /etc/apt/sources.list.d/mssql-release.list > /dev/null
sudo apt update -qq
ok "저장소 등록"
echo "=== [VM] SQL Server 설치 ==="
if ! dpkg -l | grep -q "^ii.*mssql-server "; then
sudo apt install -y -qq mssql-server > /dev/null
ok "mssql-server 패키지 설치"
else
ok "mssql-server 이미 설치됨"
fi
if ! sudo systemctl is-active --quiet mssql-server; then
sudo MSSQL_PID=Developer ACCEPT_EULA=Y MSSQL_SA_PASSWORD="$SA_PASSWORD" \
/opt/mssql/bin/mssql-conf -n setup > /dev/null
ok "SQL Server setup (Developer Edition)"
fi
# ★ 핵심: 0.0.0.0 바인딩 (외부 SSMS 접근 허용)
sudo /opt/mssql/bin/mssql-conf set network.ipaddress 0.0.0.0 > /dev/null
sudo systemctl restart mssql-server
echo "=== [VM] SQL Server 시작 대기 ==="
for i in $(seq 1 30); do
if sudo ss -tlnp 2>/dev/null | grep -q ":1433"; then
ok "0.0.0.0:1433 listen 확인"
break
fi
sleep 2
[ $i -eq 30 ] && { echo "❌ 60초 내 시작 안됨"; exit 1; }
done
echo "=== [VM] mssql-tools18 + ODBC ==="
sudo ACCEPT_EULA=Y apt install -y -qq mssql-tools18 unixodbc-dev msodbcsql18 > /dev/null
grep -q "mssql-tools18/bin" "$HOME/.bashrc" || \
echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> "$HOME/.bashrc"
export PATH="$PATH:/opt/mssql-tools18/bin"
ok "mssql-tools18 + ODBC Driver 18"
# 연결 검증
if /opt/mssql-tools18/bin/sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -Q "SELECT 1" -h -1 -W 2>/dev/null | grep -q "^1$"; then
ok "sqlcmd 로컬 연결 성공"
else
echo "❌ sqlcmd 연결 실패"; exit 1
fi
echo "=== [VM] 완료 ==="
REMOTE_SCRIPT
ok "SQL Server 2025 설치 + 0.0.0.0 바인딩 완료"
# =============================================================
# Step 7: DB 스키마 + 시드 데이터
# =============================================================
step 7 "DB 스키마 + 시드 데이터 적용"
ssh "$USER_NAME@$PUBIP" bash -s "$SA_PASSWORD" "$REPO_URL" << 'SEED_SCRIPT'
#!/usr/bin/env bash
set -euo pipefail
SA_PASSWORD="$1"
REPO_URL="$2"
INSTALL_DIR="$HOME/sqlvm_usedcar"
export PATH="$PATH:/opt/mssql-tools18/bin"
G='\033[0;32m'; NC='\033[0m'
ok() { echo -e "${G} ✓${NC} $1"; }
# Repo clone
if [ -d "$INSTALL_DIR/.git" ]; then
cd "$INSTALL_DIR" && git pull --rebase --quiet
else
[ -d "$INSTALL_DIR" ] && mv "$INSTALL_DIR" "${INSTALL_DIR}.bak.$(date +%s)"
git clone -q "$REPO_URL" "$INSTALL_DIR"
cd "$INSTALL_DIR"
fi
ok "Repo clone: $(git rev-parse --short HEAD)"
# Schema
sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -i sql/schema.sql > /dev/null
ok "schema.sql 적용 (Users, Cars, Inquiries + 3 indexes)"
# Seed
sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -i sql/seed.sql > /dev/null
# 검증
SEED_COUNT=$(sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -d CarMarket \
-Q "SELECT COUNT(*) FROM Cars" -h -1 -W 2>/dev/null | head -1 | tr -d ' \r')
if [ "$SEED_COUNT" = "5" ]; then
ok "seed.sql 적용 (Users 5건, Cars 5건)"
else
echo "⚠ Cars 행 수: $SEED_COUNT (예상 5)"
fi
SEED_SCRIPT
ok "CarMarket DB 시딩 완료"
# =============================================================
# Step 8: Flask 앱 + systemd + 검증
# =============================================================
step 8 "Flask 앱 배포 + 헬스체크"
ssh "$USER_NAME@$PUBIP" bash -s "$SA_PASSWORD" << 'APP_SCRIPT'
#!/usr/bin/env bash
set -euo pipefail
SA_PASSWORD="$1"
INSTALL_DIR="$HOME/sqlvm_usedcar"
G='\033[0;32m'; NC='\033[0m'
ok() { echo -e "${G} ✓${NC} $1"; }
sudo apt install -y -qq python3 python3-pip python3-venv python3-dev > /dev/null
cd "$INSTALL_DIR/app"
[ ! -f venv/bin/activate ] && python3 -m venv venv
source venv/bin/activate
pip install --quiet --upgrade pip
pip install --quiet -r requirements.txt
deactivate
cat > .env <<EOF
SA_PASSWORD=$SA_PASSWORD
DB_SERVER=localhost
DB_NAME=CarMarket
FLASK_PORT=5000
EOF
chmod 600 .env
ok ".env 생성"
cd "$INSTALL_DIR"
sudo cp systemd/carmarket.service /etc/systemd/system/carmarket.service
sudo sed -i "s|/home/azureuser|$HOME|g" /etc/systemd/system/carmarket.service
sudo sed -i "s|User=azureuser|User=$(whoami)|" /etc/systemd/system/carmarket.service
sudo systemctl daemon-reload
sudo systemctl enable carmarket --quiet
sudo systemctl restart carmarket
sleep 3
if sudo systemctl is-active --quiet carmarket; then
ok "carmarket.service 실행 중"
else
echo "❌ Flask 서비스 실행 실패"
sudo journalctl -u carmarket -n 20 --no-pager
exit 1
fi
HEALTH=$(curl -s --max-time 5 http://localhost:5000/health || echo '{}')
if echo "$HEALTH" | grep -q '"status":"ok"'; then
ok "Health OK: $HEALTH"
fi
APP_SCRIPT
ok "Flask 앱 배포 완료"
# =============================================================
# 외부 검증
# =============================================================
echo ""
sleep 3
echo " → 외부 헬스체크..."
if curl -fsS --max-time 10 "http://$PUBIP:5000/health" 2>/dev/null | grep -q '"status":"ok"'; then
ok "외부 Flask 접근 확인: http://$PUBIP:5000/"
else
warn "Flask 외부 접근 실패 — NSG/서비스 확인 필요"
fi
# =============================================================
# 완료 안내
# =============================================================
banner "설치 완료!"
# 환경변수 파일 저장
cat > "$HOME/.carmarket-env" <<EOF
export RG=$RG
export LOC=$LOC
export VM=$VM
export PUBIP=$PUBIP
export USER_NAME=$USER_NAME
export SA_PASSWORD='$SA_PASSWORD'
EOF
chmod 600 "$HOME/.carmarket-env"
cat <<EOF
┌─────────────────────────────────────────────────────────────┐
│ SQL Server 2025 (Developer) — 외부 SSMS 접근 가능 │
├─────────────────────────────────────────────────────────────┤
│ │
│ SSMS 연결 정보: │
│ 서버: $PUBIP,1433 │
│ 인증: SQL Server 인증 │
│ 로그인: sa │
│ 암호: (설정한 SA_PASSWORD) │
│ ★ 연결 속성 → "서버 인증서 신뢰" 체크 │
│ │
│ 웹 앱: http://$PUBIP:5000/ │
│ SSH: ssh $USER_NAME@$PUBIP │
│ │
│ 비용 차단: az vm deallocate -g $RG -n $VM │
│ 완전 삭제: az group delete -n $RG --yes --no-wait │
│ │
│ 환경변수: source ~/.carmarket-env │
└─────────────────────────────────────────────────────────────┘
EOF
- Azure CLI 로그인 확인 + SSH 키 검증
- Resource Group + Ubuntu 24.04 VM (B2s) 생성
- NSG에서 22(SSH) + 1433(SQL) + 5000(Flask) 포트 오픈
- SQL Server 2025 Developer Edition 설치
- 0.0.0.0 바인딩 (외부 SSMS 접근 허용)
- CarMarket DB 스키마 생성 + 시드 데이터 5건
- Flask 앱 배포 + systemd 서비스 등록
SSMS 연결

또는 VSCode에서 SQL Server(mssql) extension을 통해 접속 가능
데이터 확인
USE CarMarket;
GO
-- 테이블 목록 확인
SELECT TABLE_NAME, TABLE_TYPE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE';
-- 차량 매물 확인
SELECT c.Brand, c.Model, c.Year,
FORMAT(c.Price, 'N0') AS Price,
FORMAT(c.Mileage, 'N0') AS Mileage,
u.Name AS Seller
FROM Cars c
JOIN Users u ON c.SellerId = u.UserId
ORDER BY c.Price DESC;
-- 인덱스 확인
SELECT i.name AS IndexName,
t.name AS TableName,
COL_NAME(ic.object_id, ic.column_id) AS ColumnName
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.index_columns ic ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE i.name LIKE 'IX_%';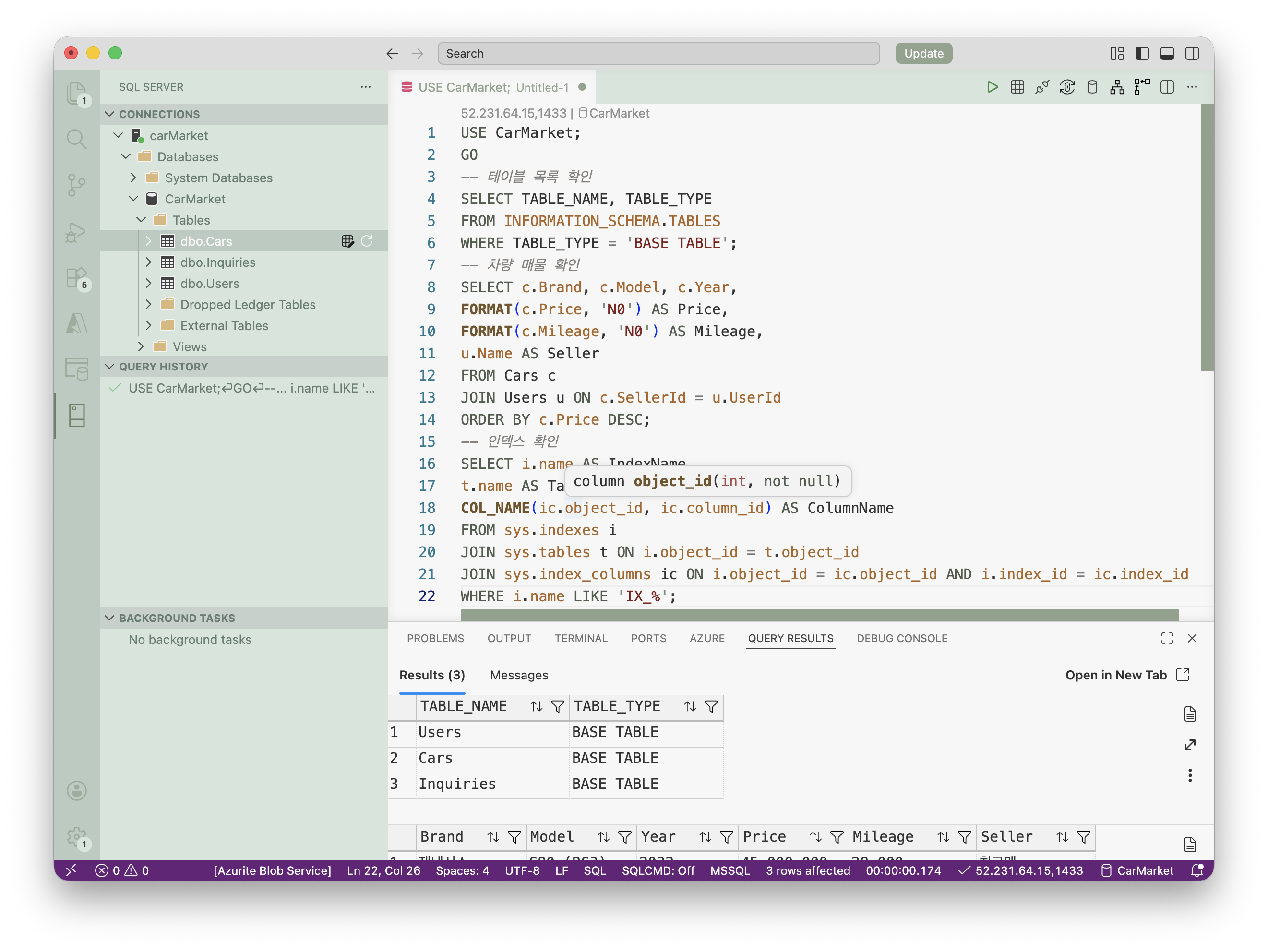
이 실습에서는 학습 편의를 위해 1433을 외부에 직접 오픈합니다. 프로덕션 환경에서는 절대 하지 마세요. 실무에서는 다음 방법을 사용합니다:
- SSH 터널:
ssh -L 1433:localhost:1433 azureuser@<PUBIP>후 SSMS에서 localhost 접속 - VPN Gateway 또는 Azure Bastion
- Private Endpoint
Azure SQL Database 마이그레이션
#!/usr/bin/env bash
# ============================================================
# 02-migrate-to-azure-sql.sh
# VM SQL Server → Azure SQL Database 마이그레이션 (Azure DMS)
#
# 사전 조건:
# - 01-setup-vm-sqlserver.sh 완료
# - source ~/.carmarket-env (환경변수 로드)
#
# 사용법:
# source ~/.carmarket-env
# bash 02-migrate-to-azure-sql.sh
# ============================================================
set -euo pipefail
# =============================================================
# 환경변수 확인 + 기본값
# =============================================================
RG="${RG:-rg-carmarket-lab}"
LOC="${LOC:-koreacentral}"
VM="${VM:-}"
PUBIP="${PUBIP:-}"
USER_NAME="${USER_NAME:-azureuser}"
SA_PASSWORD="${SA_PASSWORD:-}"
# Azure SQL 관련 변수
SQL_SERVER_NAME="${SQL_SERVER_NAME:-sql-carmarket-$(date +%m%d)-$RANDOM}"
SQL_DB_NAME="${SQL_DB_NAME:-CarMarket}"
SQL_ADMIN="${SQL_ADMIN:-sqladmin}"
SQL_ADMIN_PASSWORD="${SQL_ADMIN_PASSWORD:-}"
DMS_NAME="${DMS_NAME:-dms-carmarket-$(date +%m%d)}"
# 색상
G='\033[0;32m'; Y='\033[0;33m'; R='\033[0;31m'; B='\033[0;34m'; NC='\033[0m'
banner() { echo ""; echo -e "${B}═══════════════════════════════════════════════════${NC}"; echo -e "${B} $1${NC}"; echo -e "${B}═══════════════════════════════════════════════════${NC}"; }
step() { echo ""; echo -e "${G}▶ [$1/$TOTAL_STEPS]${NC} $2"; }
ok() { echo -e "${G} ✓${NC} $1"; }
warn() { echo -e "${Y} ⚠${NC} $1"; }
abort() { echo -e "${R}❌ $1${NC}"; exit 1; }
TOTAL_STEPS=7
LOG_FILE="/tmp/carmarket-migrate-$(date +%Y%m%d-%H%M%S).log"
exec > >(tee -a "$LOG_FILE") 2>&1
banner "CarMarket Lab — VM → Azure SQL Database 마이그레이션"
# =============================================================
# Step 1: 사전 점검
# =============================================================
step 1 "사전 점검"
command -v az >/dev/null 2>&1 || abort "Azure CLI 미설치"
az account show >/dev/null 2>&1 || { warn "로그인 필요"; az login; }
ok "Azure CLI 로그인 확인"
# PUBIP가 비어있으면 VM에서 가져오기
if [ -z "$PUBIP" ] && [ -n "$VM" ]; then
PUBIP=$(az vm show -d -g "$RG" -n "$VM" --query publicIps -o tsv 2>/dev/null || echo "")
fi
[ -z "$PUBIP" ] && abort "PUBIP를 확인할 수 없습니다. source ~/.carmarket-env 후 재시도"
ok "소스 VM: $PUBIP"
# SA 비밀번호 확인
if [ -z "$SA_PASSWORD" ]; then
read -s -p " 소스 VM SA 비밀번호: " SA_PASSWORD; echo ""
fi
ok "소스 SA 비밀번호 확인"
# Azure SQL 관리자 비밀번호
if [ -z "$SQL_ADMIN_PASSWORD" ]; then
echo " Azure SQL Database 관리자 비밀번호를 입력하세요."
echo " (소스와 같은 비밀번호 사용 가능)"
while true; do
read -s -p " SQL Admin Password: " SQL_ADMIN_PASSWORD; echo ""
read -s -p " Confirm: " CONFIRM; echo ""
[ "$SQL_ADMIN_PASSWORD" = "$CONFIRM" ] && [ ${#SQL_ADMIN_PASSWORD} -ge 8 ] && break
echo -e "${R} 불일치 또는 8자 미만${NC}"
done
fi
ok "Azure SQL 관리자 비밀번호 설정"
echo ""
echo " Azure SQL Server: $SQL_SERVER_NAME.database.windows.net"
echo " Database: $SQL_DB_NAME"
echo " Admin: $SQL_ADMIN"
echo " 예상 비용: DTU 기반 S0 ≈ \$0.49/일"
read -p " 진행? (y/N): " ok_proceed
[[ "$ok_proceed" =~ ^[Yy]$ ]] || abort "취소됨"
# =============================================================
# Step 2: Azure SQL Server + Database 생성
# =============================================================
step 2 "Azure SQL Server + Database 생성"
# SQL Server (논리 서버)
if az sql server show -g "$RG" -n "$SQL_SERVER_NAME" >/dev/null 2>&1; then
ok "SQL Server '$SQL_SERVER_NAME' 이미 존재"
else
echo " → 논리 서버 생성 중..."
az sql server create \
--resource-group "$RG" \
--name "$SQL_SERVER_NAME" \
--location "$LOC" \
--admin-user "$SQL_ADMIN" \
--admin-password "$SQL_ADMIN_PASSWORD" \
--output none
ok "SQL Server '$SQL_SERVER_NAME' 생성"
fi
# 방화벽: VM Public IP 허용
echo " → 방화벽 규칙 추가..."
az sql server firewall-rule create \
--resource-group "$RG" \
--server "$SQL_SERVER_NAME" \
--name "AllowSourceVM" \
--start-ip-address "$PUBIP" \
--end-ip-address "$PUBIP" \
--output none 2>/dev/null || true
# 방화벽: 내 로컬 IP 허용
MY_IP=$(curl -s https://api.ipify.org 2>/dev/null || echo "")
if [ -n "$MY_IP" ]; then
az sql server firewall-rule create \
--resource-group "$RG" \
--server "$SQL_SERVER_NAME" \
--name "AllowMyIP" \
--start-ip-address "$MY_IP" \
--end-ip-address "$MY_IP" \
--output none 2>/dev/null || true
ok "방화벽: VM($PUBIP) + 로컬($MY_IP) 허용"
else
ok "방화벽: VM($PUBIP) 허용"
fi
# Azure 서비스 접근 허용
az sql server firewall-rule create \
--resource-group "$RG" \
--server "$SQL_SERVER_NAME" \
--name "AllowAzureServices" \
--start-ip-address 0.0.0.0 \
--end-ip-address 0.0.0.0 \
--output none 2>/dev/null || true
ok "Azure 서비스 접근 허용"
# Database 생성 (S0 = 10 DTU, 실습에 충분)
if az sql db show -g "$RG" -s "$SQL_SERVER_NAME" -n "$SQL_DB_NAME" >/dev/null 2>&1; then
ok "Database '$SQL_DB_NAME' 이미 존재"
else
echo " → Database 생성 중 (1~2분)..."
az sql db create \
--resource-group "$RG" \
--server "$SQL_SERVER_NAME" \
--name "$SQL_DB_NAME" \
--service-objective S0 \
--output none
ok "Database '$SQL_DB_NAME' 생성 (S0 / 10 DTU)"
fi
SQL_FQDN="${SQL_SERVER_NAME}.database.windows.net"
ok "Azure SQL: $SQL_FQDN / $SQL_DB_NAME"
# =============================================================
# Step 3: 소스 VM에서 bacpac 내보내기 준비
# =============================================================
step 3 "소스 DB에서 스키마·데이터 SQL 스크립트 생성"
# DMS 대신 sqlcmd를 통한 직접 마이그레이션 (소규모 DB에 적합)
# 대규모에서는 DMS를 사용하지만, 이 실습은 교육용이므로 두 방식 모두 제공
echo " → VM에서 스키마 + 데이터 추출..."
ssh "$USER_NAME@$PUBIP" bash -s "$SA_PASSWORD" << 'EXPORT_SCRIPT'
#!/usr/bin/env bash
set -euo pipefail
SA_PASSWORD="$1"
export PATH="$PATH:/opt/mssql-tools18/bin"
EXPORT_DIR="$HOME/migration_export"
mkdir -p "$EXPORT_DIR"
G='\033[0;32m'; NC='\033[0m'
ok() { echo -e "${G} ✓${NC} $1"; }
# Azure SQL 호환 스키마 생성 (IDENTITY 유지, Azure SQL 미지원 구문 제거)
cat > "$EXPORT_DIR/schema-azure.sql" << 'AZSCHEMA'
-- Azure SQL Database용 스키마 (CarMarket)
-- Azure SQL은 CREATE DATABASE를 별도로 실행하므로 DB 생성 구문 제외
-- 기존 테이블 정리 (멱등성)
IF OBJECT_ID('Inquiries', 'U') IS NOT NULL DROP TABLE Inquiries;
IF OBJECT_ID('Cars', 'U') IS NOT NULL DROP TABLE Cars;
IF OBJECT_ID('Users', 'U') IS NOT NULL DROP TABLE Users;
GO
CREATE TABLE Users (
UserId INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(100) NOT NULL,
Email NVARCHAR(200) NOT NULL UNIQUE,
Phone NVARCHAR(20),
UserType NVARCHAR(10) NOT NULL DEFAULT 'both'
CHECK (UserType IN ('seller', 'buyer', 'both')),
CreatedAt DATETIME2 DEFAULT SYSUTCDATETIME()
);
GO
CREATE TABLE Cars (
CarId INT IDENTITY(1,1) PRIMARY KEY,
SellerId INT NOT NULL FOREIGN KEY REFERENCES Users(UserId),
Brand NVARCHAR(50) NOT NULL,
Model NVARCHAR(100) NOT NULL,
Year INT NOT NULL,
Price DECIMAL(12, 0) NOT NULL,
Mileage INT NOT NULL,
FuelType NVARCHAR(20),
Description NVARCHAR(MAX),
Status NVARCHAR(20) NOT NULL DEFAULT 'available'
CHECK (Status IN ('available', 'reserved', 'sold')),
CreatedAt DATETIME2 DEFAULT SYSUTCDATETIME()
);
GO
CREATE TABLE Inquiries (
InquiryId INT IDENTITY(1,1) PRIMARY KEY,
CarId INT NOT NULL FOREIGN KEY REFERENCES Cars(CarId),
BuyerId INT NOT NULL FOREIGN KEY REFERENCES Users(UserId),
Message NVARCHAR(1000) NOT NULL,
CreatedAt DATETIME2 DEFAULT SYSUTCDATETIME()
);
GO
CREATE INDEX IX_Cars_Brand ON Cars(Brand);
CREATE INDEX IX_Cars_Status ON Cars(Status);
CREATE INDEX IX_Cars_CreatedAt ON Cars(CreatedAt DESC);
GO
AZSCHEMA
ok "Azure SQL 호환 스키마 생성"
# 데이터 추출 (INSERT 문으로)
sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -d CarMarket -h -1 -W -Q "
SET NOCOUNT ON;
-- Users
SELECT 'SET IDENTITY_INSERT Users ON;'
UNION ALL
SELECT 'INSERT INTO Users (UserId, Name, Email, Phone, UserType) VALUES ('
+ CAST(UserId AS NVARCHAR) + ', N''' + REPLACE(Name, '''', '''''') + ''', '''
+ Email + ''', ''' + ISNULL(Phone, '') + ''', ''' + UserType + ''');'
FROM Users
UNION ALL
SELECT 'SET IDENTITY_INSERT Users OFF;'
UNION ALL
SELECT ''
UNION ALL
-- Cars
SELECT 'SET IDENTITY_INSERT Cars ON;'
UNION ALL
SELECT 'INSERT INTO Cars (CarId, SellerId, Brand, Model, Year, Price, Mileage, FuelType, Description, Status) VALUES ('
+ CAST(CarId AS NVARCHAR) + ', ' + CAST(SellerId AS NVARCHAR) + ', N'''
+ REPLACE(Brand, '''', '''''') + ''', N''' + REPLACE(Model, '''', '''''') + ''', '
+ CAST(Year AS NVARCHAR) + ', ' + CAST(Price AS NVARCHAR) + ', '
+ CAST(Mileage AS NVARCHAR) + ', N''' + ISNULL(FuelType, '') + ''', N'''
+ ISNULL(REPLACE(Description, '''', ''''''), '') + ''', ''' + Status + ''');'
FROM Cars
UNION ALL
SELECT 'SET IDENTITY_INSERT Cars OFF;'
UNION ALL
SELECT 'GO';
" > "$EXPORT_DIR/seed-azure.sql" 2>/dev/null
# 빈 줄/공백 정리
sed -i '/^$/d' "$EXPORT_DIR/seed-azure.sql"
ok "데이터 INSERT 스크립트 생성"
# 행 수 검증
USER_CNT=$(sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -d CarMarket \
-Q "SET NOCOUNT ON; SELECT COUNT(*) FROM Users" -h -1 -W | head -1 | tr -d ' \r')
CAR_CNT=$(sqlcmd -S localhost -U sa -P "$SA_PASSWORD" -C -d CarMarket \
-Q "SET NOCOUNT ON; SELECT COUNT(*) FROM Cars" -h -1 -W | head -1 | tr -d ' \r')
ok "소스 DB: Users=${USER_CNT}건, Cars=${CAR_CNT}건"
echo "$USER_CNT $CAR_CNT" > "$EXPORT_DIR/source_counts.txt"
EXPORT_SCRIPT
ok "마이그레이션 데이터 준비 완료"
# =============================================================
# Step 4: Azure SQL에 스키마 적용
# =============================================================
step 4 "Azure SQL Database에 스키마 적용"
# VM에서 Azure SQL로 직접 sqlcmd 실행
ssh "$USER_NAME@$PUBIP" bash -s "$SQL_FQDN" "$SQL_ADMIN" "$SQL_ADMIN_PASSWORD" "$SQL_DB_NAME" << 'APPLY_SCHEMA'
#!/usr/bin/env bash
set -euo pipefail
SQL_FQDN="$1"; SQL_ADMIN="$2"; SQL_ADMIN_PASSWORD="$3"; SQL_DB_NAME="$4"
export PATH="$PATH:/opt/mssql-tools18/bin"
EXPORT_DIR="$HOME/migration_export"
G='\033[0;32m'; NC='\033[0m'
ok() { echo -e "${G} ✓${NC} $1"; }
echo " → Azure SQL에 스키마 적용..."
sqlcmd -S "$SQL_FQDN" -U "$SQL_ADMIN" -P "$SQL_ADMIN_PASSWORD" -d "$SQL_DB_NAME" \
-i "$EXPORT_DIR/schema-azure.sql" > /dev/null
ok "스키마 적용 완료"
echo " → Azure SQL에 시드 데이터 적용..."
sqlcmd -S "$SQL_FQDN" -U "$SQL_ADMIN" -P "$SQL_ADMIN_PASSWORD" -d "$SQL_DB_NAME" \
-i "$EXPORT_DIR/seed-azure.sql" > /dev/null 2>&1 || true
ok "시드 데이터 적용"
APPLY_SCHEMA
ok "Azure SQL 스키마 + 시드 적용 완료"
# =============================================================
# Step 5: Azure DMS를 통한 온라인 마이그레이션 (선택)
# =============================================================
step 5 "Azure DMS 리소스 생성 (추가 마이그레이션 도구)"
echo " ℹ️ 소규모 DB는 Step 4의 직접 sqlcmd 방식으로 충분합니다."
echo " ℹ️ 대규모·프로덕션에서는 Azure DMS를 사용합니다."
echo ""
read -p " DMS 리소스도 생성하시겠습니까? (y/N): " create_dms
if [[ "$create_dms" =~ ^[Yy]$ ]]; then
# DMS 확장 설치
az extension add --name dms 2>/dev/null || true
echo " → DMS 인스턴스 생성 중 (5~10분)..."
az dms create \
--resource-group "$RG" \
--name "$DMS_NAME" \
--location "$LOC" \
--sku-name Standard_1vCores \
--output none 2>/dev/null || warn "DMS 생성 실패 (수동 생성 필요할 수 있음)"
ok "DMS '$DMS_NAME' 생성"
echo ""
echo " DMS는 Azure Portal에서 마이그레이션 프로젝트를 생성하여 사용합니다."
echo " Portal → Database Migration Service → 새 마이그레이션 프로젝트"
echo " 소스: SQL Server ($PUBIP:1433)"
echo " 대상: Azure SQL Database ($SQL_FQDN)"
else
ok "DMS 생성 건너뜀 (sqlcmd 직접 방식 사용)"
fi
# =============================================================
# Step 6: 마이그레이션 검증
# =============================================================
step 6 "마이그레이션 검증"
echo " → Azure SQL 데이터 검증..."
VERIFY_RESULT=$(ssh "$USER_NAME@$PUBIP" bash -s "$SQL_FQDN" "$SQL_ADMIN" "$SQL_ADMIN_PASSWORD" "$SQL_DB_NAME" << 'VERIFY'
export PATH="$PATH:/opt/mssql-tools18/bin"
SQL_FQDN="$1"; SQL_ADMIN="$2"; SQL_ADMIN_PASSWORD="$3"; SQL_DB_NAME="$4"
# 테이블 수
TABLE_COUNT=$(sqlcmd -S "$SQL_FQDN" -U "$SQL_ADMIN" -P "$SQL_ADMIN_PASSWORD" -d "$SQL_DB_NAME" \
-Q "SET NOCOUNT ON; SELECT COUNT(*) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE='BASE TABLE'" \
-h -1 -W 2>/dev/null | head -1 | tr -d ' \r')
# Users 수
USER_COUNT=$(sqlcmd -S "$SQL_FQDN" -U "$SQL_ADMIN" -P "$SQL_ADMIN_PASSWORD" -d "$SQL_DB_NAME" \
-Q "SET NOCOUNT ON; SELECT COUNT(*) FROM Users" -h -1 -W 2>/dev/null | head -1 | tr -d ' \r')
# Cars 수
CAR_COUNT=$(sqlcmd -S "$SQL_FQDN" -U "$SQL_ADMIN" -P "$SQL_ADMIN_PASSWORD" -d "$SQL_DB_NAME" \
-Q "SET NOCOUNT ON; SELECT COUNT(*) FROM Cars" -h -1 -W 2>/dev/null | head -1 | tr -d ' \r')
# 인덱스 수
IDX_COUNT=$(sqlcmd -S "$SQL_FQDN" -U "$SQL_ADMIN" -P "$SQL_ADMIN_PASSWORD" -d "$SQL_DB_NAME" \
-Q "SET NOCOUNT ON; SELECT COUNT(*) FROM sys.indexes WHERE name LIKE 'IX_%'" \
-h -1 -W 2>/dev/null | head -1 | tr -d ' \r')
echo "$TABLE_COUNT $USER_COUNT $CAR_COUNT $IDX_COUNT"
VERIFY
)
read T_CNT U_CNT C_CNT I_CNT <<< "$VERIFY_RESULT"
ok "Azure SQL 테이블: ${T_CNT}개"
ok "Azure SQL Users: ${U_CNT}건"
ok "Azure SQL Cars: ${C_CNT}건"
ok "Azure SQL 인덱스: ${I_CNT}개"
# 소스와 비교
SOURCE_COUNTS=$(ssh "$USER_NAME@$PUBIP" "cat ~/migration_export/source_counts.txt" 2>/dev/null || echo "5 5")
read S_U S_C <<< "$SOURCE_COUNTS"
if [ "$U_CNT" = "$S_U" ] && [ "$C_CNT" = "$S_C" ]; then
ok "✅ 소스 ↔ 대상 데이터 일치 (Users: $S_U, Cars: $S_C)"
else
warn "데이터 불일치: 소스(U:$S_U, C:$S_C) ↔ 대상(U:$U_CNT, C:$C_CNT)"
fi
# =============================================================
# Step 7: 연결 정보 저장
# =============================================================
step 7 "연결 정보 저장"
# 환경변수 파일 업데이트
cat >> "$HOME/.carmarket-env" <<EOF
# Azure SQL Database
export SQL_SERVER_NAME=$SQL_SERVER_NAME
export SQL_FQDN=$SQL_FQDN
export SQL_DB_NAME=$SQL_DB_NAME
export SQL_ADMIN=$SQL_ADMIN
export SQL_ADMIN_PASSWORD='$SQL_ADMIN_PASSWORD'
EOF
chmod 600 "$HOME/.carmarket-env"
ok "~/.carmarket-env 업데이트"
# =============================================================
# 완료 안내
# =============================================================
banner "마이그레이션 완료!"
cat <<EOF
┌─────────────────────────────────────────────────────────────┐
│ Azure SQL Database 마이그레이션 결과 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 소스 (VM SQL Server): │
│ $PUBIP:1433 / sa │
│ │
│ 대상 (Azure SQL Database): │
│ 서버: $SQL_FQDN │
│ DB: $SQL_DB_NAME │
│ 관리자: $SQL_ADMIN │
│ │
│ SSMS 연결 (Azure SQL): │
│ 서버: $SQL_FQDN │
│ 인증: SQL Server 인증 │
│ 로그인: $SQL_ADMIN │
│ 암호: (설정한 SQL_ADMIN_PASSWORD) │
│ │
│ 검증: 테이블 ${T_CNT}개, Users ${U_CNT}건, Cars ${C_CNT}건 │
│ │
│ 다음 단계: │
│ bash 03-switch-app-to-azure-sql.sh │
│ (Flask 앱을 Azure SQL로 전환) │
│ │
│ 환경변수: source ~/.carmarket-env │
└─────────────────────────────────────────────────────────────┘
EOF
- Azure SQL Server (논리 서버) + Database (S0) 생성
- 방화벽 규칙 설정 (VM IP + 로컬 IP + Azure 서비스)
- VM SQL Server에서 스키마·데이터를 SQL 스크립트로 추출
- Azure SQL Database에 스키마·시드 데이터 적용
- Azure DMS 리소스 생성 (선택)
- 소스 ↔ 대상 데이터 일치 검증
검증
마이그레이션 검증 (SSMS에서)
-- 테이블 구조 비교
SELECT TABLE_NAME,
(SELECT COUNT(*) FROM INFORMATION_SCHEMA.COLUMNS c
WHERE c.TABLE_NAME = t.TABLE_NAME) AS ColumnCount
FROM INFORMATION_SCHEMA.TABLES t
WHERE TABLE_TYPE = 'BASE TABLE'
ORDER BY TABLE_NAME;
-- 행 수 비교 (소스와 동일해야 함)
SELECT 'Users' AS TableName, COUNT(*) AS [RowCount] FROM Users
UNION ALL
SELECT 'Cars', COUNT(*) FROM Cars
UNION ALL
SELECT 'Inquiries', COUNT(*) FROM Inquiries;
-- 데이터 내용 확인
SELECT c.Brand, c.Model, c.Year,
FORMAT(c.Price, 'N0') AS Price,
u.Name AS Seller
FROM Cars c
JOIN Users u ON c.SellerId = u.UserId
ORDER BY c.Price DESC;
-- Azure SQL 특유 정보 확인
SELECT
@@VERSION AS SQLVersion,
DB_NAME() AS DatabaseName,
DATABASEPROPERTYEX(DB_NAME(), 'Edition') AS Edition,
DATABASEPROPERTYEX(DB_NAME(), 'ServiceObjective') AS ServiceTier;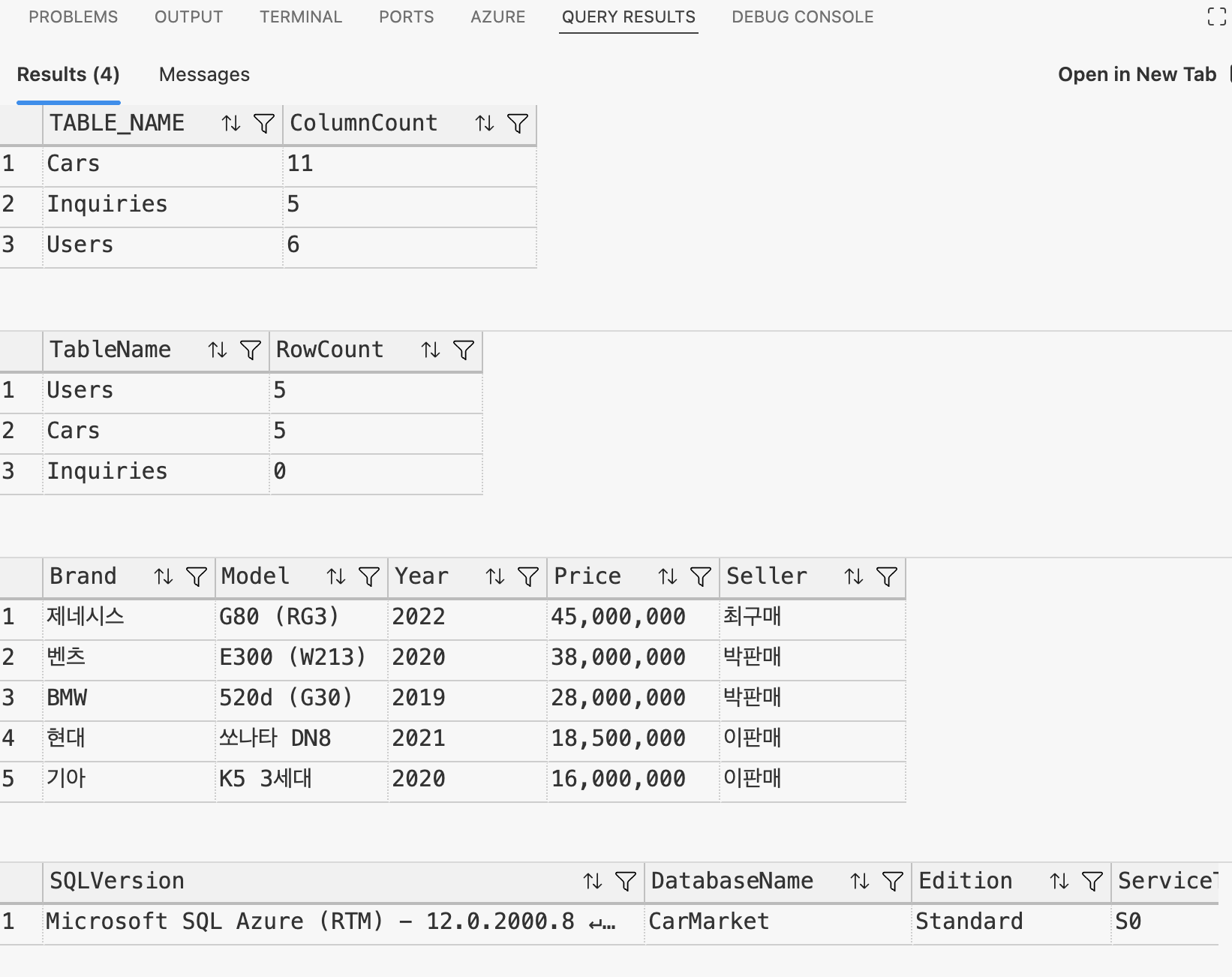
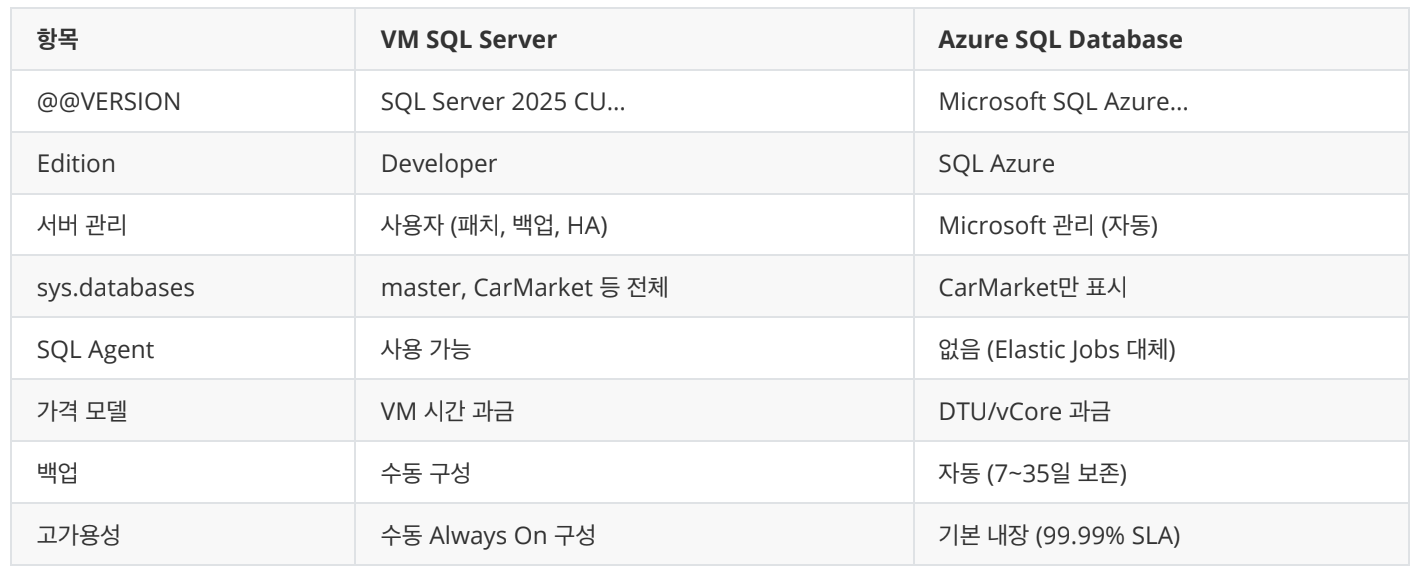
VM SQL Server vs Azure SQL Database 비교
Flask 앱 연결 전환
#!/usr/bin/env bash
# ============================================================
# 03-switch-app-to-azure-sql.sh
# Flask 앱 연결 대상을 VM SQL Server → Azure SQL Database로 전환
#
# 사전 조건:
# - 01, 02 스크립트 완료
# - source ~/.carmarket-env
#
# 사용법:
# source ~/.carmarket-env
# bash 03-switch-app-to-azure-sql.sh
# ============================================================
set -euo pipefail
# 환경변수
RG="${RG:-rg-carmarket-lab}"
VM="${VM:-}"
PUBIP="${PUBIP:-}"
USER_NAME="${USER_NAME:-azureuser}"
SQL_FQDN="${SQL_FQDN:-}"
SQL_DB_NAME="${SQL_DB_NAME:-CarMarket}"
SQL_ADMIN="${SQL_ADMIN:-sqladmin}"
SQL_ADMIN_PASSWORD="${SQL_ADMIN_PASSWORD:-}"
# 색상
G='\033[0;32m'; Y='\033[0;33m'; R='\033[0;31m'; B='\033[0;34m'; NC='\033[0m'
banner() { echo ""; echo -e "${B}═══════════════════════════════════════════════════${NC}"; echo -e "${B} $1${NC}"; echo -e "${B}═══════════════════════════════════════════════════${NC}"; }
ok() { echo -e "${G} ✓${NC} $1"; }
warn() { echo -e "${Y} ⚠${NC} $1"; }
abort() { echo -e "${R}❌ $1${NC}"; exit 1; }
banner "Flask 앱 → Azure SQL Database 전환"
# 검증
[ -z "$SQL_FQDN" ] && abort "SQL_FQDN 환경변수 없음. source ~/.carmarket-env"
[ -z "$PUBIP" ] && abort "PUBIP 환경변수 없음. source ~/.carmarket-env"
[ -z "$SQL_ADMIN_PASSWORD" ] && { read -s -p "Azure SQL Admin 비밀번호: " SQL_ADMIN_PASSWORD; echo ""; }
echo ""
echo " 현재: localhost (VM SQL Server)"
echo " 전환: $SQL_FQDN (Azure SQL Database)"
echo ""
read -p " Flask 앱 연결 대상을 Azure SQL로 전환? (y/N): " ok_proceed
[[ "$ok_proceed" =~ ^[Yy]$ ]] || abort "취소됨"
# =============================================================
# VM에서 .env 수정 + 재시작
# =============================================================
echo ""
echo " → .env 백업 + 수정..."
ssh "$USER_NAME@$PUBIP" bash -s "$SQL_FQDN" "$SQL_DB_NAME" "$SQL_ADMIN" "$SQL_ADMIN_PASSWORD" << 'SWITCH'
#!/usr/bin/env bash
set -euo pipefail
SQL_FQDN="$1"; SQL_DB_NAME="$2"; SQL_ADMIN="$3"; SQL_ADMIN_PASSWORD="$4"
APP_DIR="$HOME/sqlvm_usedcar/app"
G='\033[0;32m'; NC='\033[0m'
ok() { echo -e "${G} ✓${NC} $1"; }
# 백업
cp "$APP_DIR/.env" "$APP_DIR/.env.vm-backup"
ok "기존 .env 백업 → .env.vm-backup"
# Azure SQL 용 .env 생성
cat > "$APP_DIR/.env" <<EOF
# Azure SQL Database 연결
SA_PASSWORD=$SQL_ADMIN_PASSWORD
DB_SERVER=$SQL_FQDN
DB_NAME=$SQL_DB_NAME
DB_USER=$SQL_ADMIN
FLASK_PORT=5000
EOF
chmod 600 "$APP_DIR/.env"
ok ".env 업데이트 → $SQL_FQDN"
# app.py에서 DB_USER 환경변수 지원하도록 패치 (필요시)
if ! grep -q 'DB_USER' "$APP_DIR/app.py"; then
# DB_USER = "sa" → 환경변수에서 읽도록 변경
sed -i 's/DB_USER = "sa"/DB_USER = os.environ.get("DB_USER", "sa")/' "$APP_DIR/app.py"
ok "app.py: DB_USER 환경변수 지원 패치"
fi
# 재시작
sudo systemctl restart carmarket
sleep 3
if sudo systemctl is-active --quiet carmarket; then
ok "carmarket.service 재시작 완료"
else
echo "❌ 서비스 재시작 실패"
sudo journalctl -u carmarket -n 20 --no-pager
exit 1
fi
# 헬스체크
HEALTH=$(curl -s --max-time 10 http://localhost:5000/health || echo '{}')
if echo "$HEALTH" | grep -q '"status":"ok"'; then
ok "Health OK (Azure SQL 연결): $HEALTH"
else
echo "⚠ Health 실패: $HEALTH"
echo " → VM SQL Server로 롤백하려면:"
echo " cp $APP_DIR/.env.vm-backup $APP_DIR/.env"
echo " sudo systemctl restart carmarket"
fi
SWITCH
# 외부 검증
echo ""
echo " → 외부 헬스체크..."
sleep 2
HEALTH=$(curl -s --max-time 10 "http://$PUBIP:5000/health" || echo '{}')
if echo "$HEALTH" | grep -q '"status":"ok"'; then
ok "외부에서 Azure SQL 통해 앱 정상 작동 확인"
else
warn "외부 헬스체크 실패: $HEALTH"
fi
# API 검증
echo " → API 테스트 (차량 목록)..."
CARS=$(curl -s --max-time 10 "http://$PUBIP:5000/api/cars" || echo '[]')
CAR_COUNT=$(echo "$CARS" | python3 -c "import sys,json; print(len(json.load(sys.stdin)))" 2>/dev/null || echo "0")
ok "API 응답: Cars ${CAR_COUNT}건"
banner "전환 완료!"
cat <<EOF
┌─────────────────────────────────────────────────────────────┐
│ Flask 앱이 Azure SQL Database를 사용 중입니다 │
│ │
│ 웹 앱: http://$PUBIP:5000/ │
│ DB: $SQL_FQDN / $SQL_DB_NAME │
│ │
│ 롤백 방법 (VM SQL Server로 복귀): │
│ ssh $USER_NAME@$PUBIP │
│ cp ~/sqlvm_usedcar/app/.env.vm-backup ~/sqlvm_usedcar/app/.env │
│ sudo systemctl restart carmarket │
└─────────────────────────────────────────────────────────────┘
EOF
- 기존 .env 백업 ( .env.vm-backup )
- DB 연결 대상을 Azure SQL Database로 변경
- app.py 에 DB_USER 환경변수 지원 패치
- carmarket 서비스 재시작
- 헬스체크 + API 테스트
이후 ssh로 vm 접속
cd ~/sqlvm_usedcar/app
# 1. 현재 DB_USER 확인
grep 'DB_USER' app.py
# 2. app.py 수정 (DB_USER를 환경변수에서 읽도록)
sed -i 's/DB_USER = "sa"/DB_USER = os.environ.get("DB_USER", "sa")/' app.py
# 3. .env에 DB_USER가 있는지 확인
cat .env
# 4. DB_USER가 없으면 추가
grep -q 'DB_USER' .env || echo 'DB_USER=sqladmin' >> .env
# 5. 서비스 재시작
sudo systemctl restart carmarket
# 6. 확인
curl -s http://localhost:5000/health전환 후 검증
# 헬스체크 — db: connected 확인
curl http://$PUBIP:5000/health
# 차량 목록 — Azure SQL에서 조회
curl http://$PUBIP:5000/api/cars
# 매물 등록 테스트 — Azure SQL에 INSERT
curl -X POST http://$PUBIP:5000/api/cars \
-H "Content-Type: application/json" \
-d '{"seller_id":1,"brand":"기아","model":"카니발","year":2023,"price":38000000,"mileage":10000}'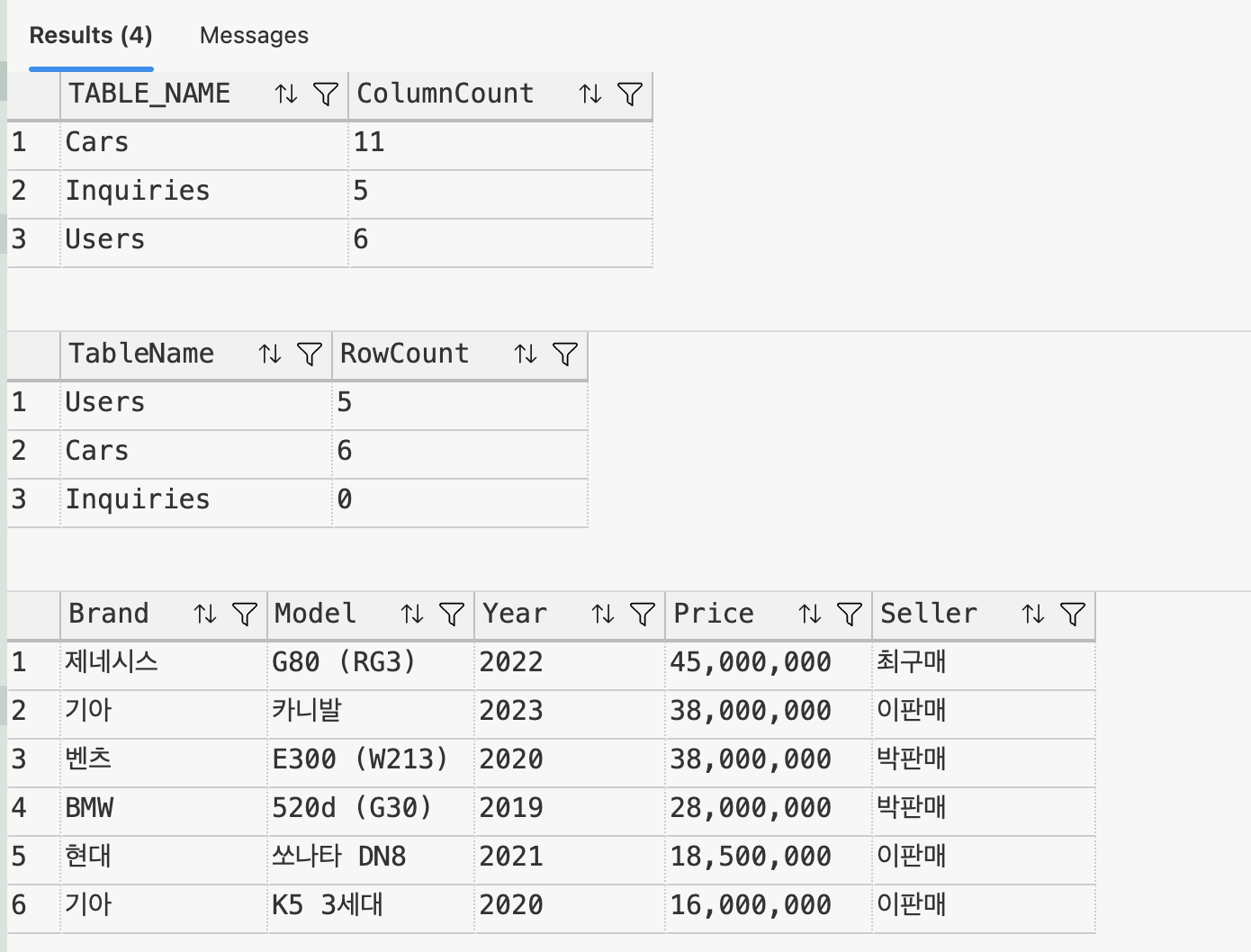
롤백 (VM SQL Server로 복귀)
ssh azureuser@$PUBIP
cp ~/sqlvm_usedcar/app/.env.vm-backup ~/sqlvm_usedcar/app/.env
sudo systemctl restart carmarket리소스 정리
source ~/.carmarket-env
# 방법 1: VM만 중지 (데이터 유지, 비용 중단)
bash scripts/99-cleanup.sh
# 방법 2: 전체 삭제 (되돌릴 수 없음)
bash scripts/99-cleanup.sh --deleteSQL Server on Azure Virtual Machines
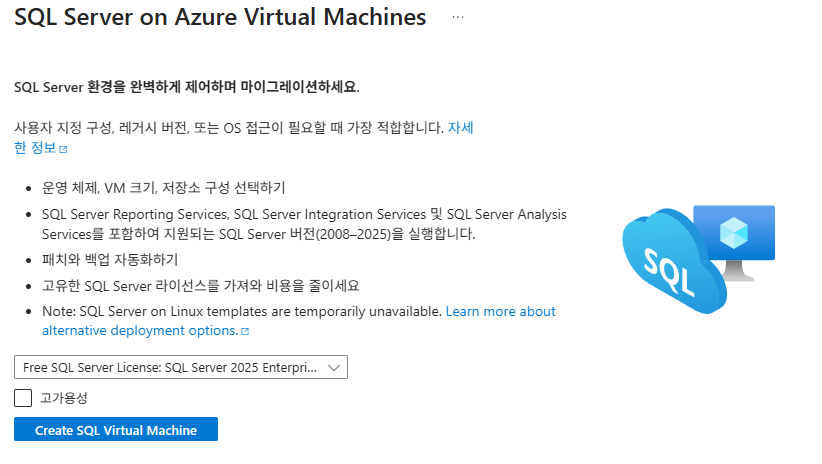
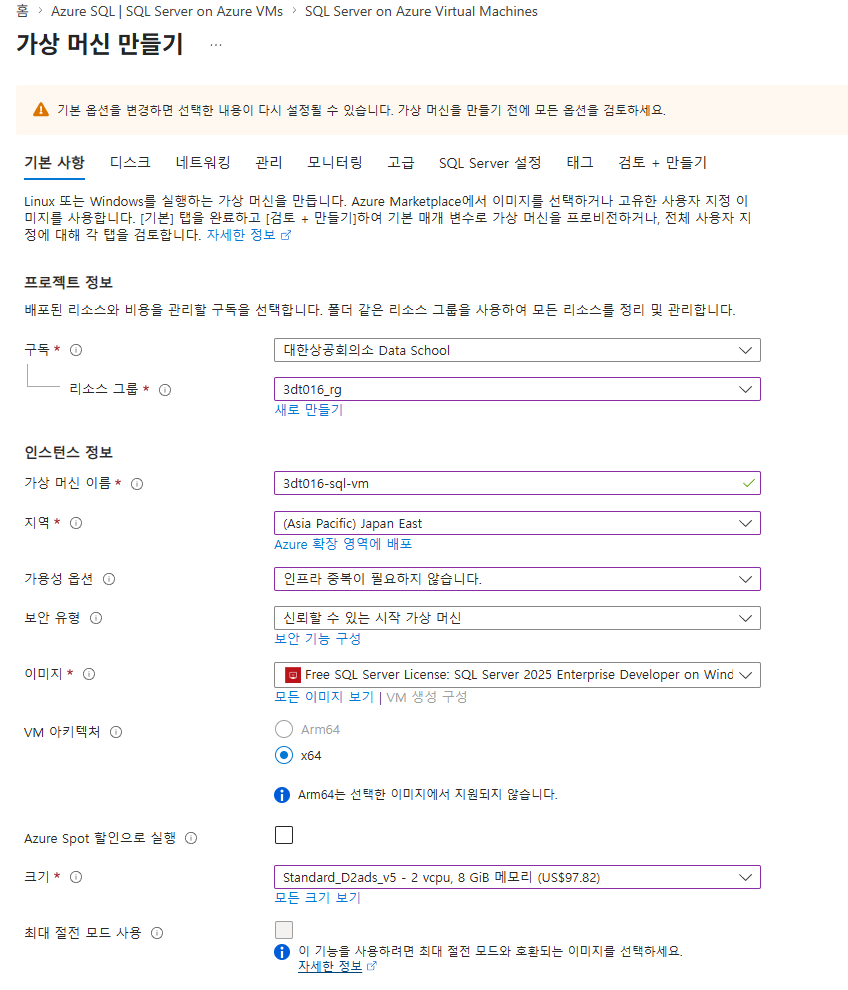
CIDR
사이더
CIDR(Classless Inter-Domain Routing, 클래스 없는 도메인 간 라우팅)은 1993년 도입된 IP 주소 할당 및 라우팅 효율화 방식입니다. 고정된 클래스 기반 체계(A, B, C)를 대체하여 IP 주소 낭비를 줄이고, 접두어(Prefix)를 사용하여 유연하게 네트워크 영역을 나누어 라우팅 테이블 크기를 줄인다.
SQL Server 인덱스 조각화 문제 감지 및 수정 실습
실습 개요
이 실습은 SQL Server에서 인덱스 조각화(Index Fragmentation) 문제를 감지하고, 조각난 인덱스를 다시 작성하여 쿼리 성능 변화를 확인하는 과정이다.
AdventureWorks 데이터베이스를 복원한 뒤, Person.Address 테이블에 데이터를 추가하여 인덱스 조각화를 인위적으로 발생시킨다. 이후 DMV를 사용해 조각화 수준을 확인하고, ALTER INDEX ... REBUILD로 인덱스를 다시 작성한다. 마지막으로 SET STATISTICS IO, TIME ON을 사용해 논리적 읽기 수가 줄어드는지 비교한다.
실습 배경
AdventureWorks는 10년 넘게 자전거와 자전거 부품을 소비자와 유통업체에 직접 판매해 온 회사이다. 최근 고객 요청을 처리하는 데 사용되는 제품의 성능 저하가 발견되었다.
데이터베이스 관리자는 SQL 도구를 사용하여 성능 문제를 식별하고, 발견된 문제를 해결할 수 있는 실행 가능한 솔루션을 제공해야 한다.
이 실습에서는 다음을 수행한다.
- AdventureWorks2017 데이터베이스 복원
- 인덱스 조각화 상태 확인
- 대량 데이터 삽입으로 조각화 유발
- 조각화된 인덱스 확인
- 논리적 읽기 수 측정
- 인덱스 다시 작성
- 조각화 감소 및 논리적 읽기 감소 확인
참고: SSMS에서 라인 번호 표시하기
T-SQL 코드를 복사하여 실행할 때 디버깅을 쉽게 하기 위해 SSMS 편집기에 라인 번호를 표시할 수 있다.
설정 경로:
Tools → Options → Text Editor → Transact-SQL → General → Line numbers 체크데이터베이스 복원
1. AdventureWorks2017 백업 파일 다운로드
랩 가상 머신에서 아래 경로의 데이터베이스 백업 파일을 다운로드한다.
https://github.com/MicrosoftLearning/dp-300-database-administrator/blob/master/Instructions/Templates/AdventureWorks2017.bak다운로드한 파일은 아래 폴더에 저장한다.
C:\LabFiles\Monitor and optimize해당 폴더가 없다면 직접 생성한다.
2. SSMS 실행
Windows 시작 버튼을 선택하고 SSMS를 입력한다.
목록에서 Microsoft SQL Server Management Studio 18을 선택한다.
3. SQL Server 연결
SSMS가 열리면 Connect to Server 대화 상자가 표시된다.
기본 인스턴스 이름이 미리 채워져 있으면 그대로 Connect를 선택한다.
서버가 보이지 않는 경우에는 다음을 선택해 서버를 찾을 수 있다.
<Browse for more>4. New Query 선택
Object Explorer에서 Databases 폴더를 선택한 뒤, 상단의 New Query를 선택한다.
5. 데이터베이스 복원 쿼리 실행
New Query 창에 아래 T-SQL을 복사하여 붙여넣고 실행한다.
RESTORE DATABASE AdventureWorks2017
FROM DISK = 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.bak'
WITH RECOVERY,
MOVE 'AdventureWorks2017'
TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.mdf',
MOVE 'AdventureWorks2017_log'
TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017_log.ldf';백업 파일 이름과 경로는 실제 다운로드한 파일 위치와 일치해야 한다. 경로가 다르면 복원 명령이 실패한다.
6. 복원 성공 확인
복원이 완료되면 메시지 창에 성공 메시지가 표시된다.
예시:
RESTORE DATABASE successfully processed ... pages ...인덱스 조각화 조사
1. 현재 조각화 상태 확인
New Query를 선택한 뒤 아래 T-SQL 코드를 실행한다.
USE AdventureWorks2017
GO
SELECT i.name Index_Name
, avg_fragmentation_in_percent
, db_name(database_id)
, i.object_id
, i.index_id
, index_type_desc
FROM
sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE avg_fragmentation_in_percent > 50
-- find indexes where fragmentation is greater than 50%이 쿼리는 Person.Address 테이블에서 조각화가 50%를 초과하는 인덱스를 조회한다.
처음 실행하면 반환되는 결과가 없다. 즉, 현재는 50%를 초과하는 조각화된 인덱스가 없는 상태이다.
2. 데이터 삽입으로 조각화 유발
다음 T-SQL을 실행하여 Person.Address 테이블에 많은 수의 새 레코드를 삽입한다.
USE AdventureWorks2017
GO
INSERT INTO [Person].[Address]
([AddressLine1]
,[AddressLine2]
,[City]
,[StateProvinceID]
,[PostalCode]
,[SpatialLocation]
,[rowguid]
,[ModifiedDate])
SELECT AddressLine1,
AddressLine2,
'Amsterdam',
StateProvinceID,
PostalCode,
SpatialLocation,
newid(),
getdate()
FROM Person.Address;
GO이 쿼리는 기존 Person.Address 데이터를 다시 읽어 같은 테이블에 추가 삽입한다.
특히 City 값을 'Amsterdam'으로 고정하여 삽입한다. 결과적으로 행 개수가 약 2배로 늘어나고, Person.Address 테이블과 관련 인덱스의 조각화 수준이 증가한다.
3. 조각화 상태 다시 확인
처음 실행했던 조각화 확인 쿼리를 다시 실행한다.
USE AdventureWorks2017
GO
SELECT i.name Index_Name
, avg_fragmentation_in_percent
, db_name(database_id)
, i.object_id
, i.index_id
, index_type_desc
FROM
sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE avg_fragmentation_in_percent > 50
-- find indexes where fragmentation is greater than 50%이제 고도로 조각난 인덱스 4개를 확인할 수 있다.
예시 결과에서는 다음과 같은 인덱스들이 50% 이상의 조각화를 보인다.
| Index_Name | avg_fragmentation_in_percent | 설명 |
|---|---|---|
| AK_Address_rowguid | 약 98% | rowguid 관련 인덱스 |
| IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode | 약 98% | 주소 검색 관련 인덱스 |
| IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode | 약 90% | 주소 검색 관련 인덱스 |
| IX_Address_StateProvinceID | 약 80~81% | StateProvinceID 관련 인덱스 |
논리적 읽기 수 측정
1. STATISTICS IO, TIME 활성화 후 쿼리 실행
다음 쿼리를 실행한다.
SET STATISTICS IO,TIME ON
GO
USE AdventureWorks2017
GO
SELECT DISTINCT (StateProvinceID)
,count(StateProvinceID) AS CustomerCount
FROM person.Address
GROUP BY StateProvinceID
ORDER BY count(StateProvinceID) DESC;
GO이 쿼리는 Person.Address 테이블에서 StateProvinceID별 건수를 집계하고, 건수가 많은 순서대로 정렬한다.
2. Messages 탭에서 logical reads 확인
SQL Server Management Studio의 결과 창에서 Messages 탭을 클릭한다.
여기에서 쿼리에 의해 수행된 논리적 읽기 수를 확인한다.
실습 자료 기준으로 조각화된 상태에서의 논리적 읽기 수는 다음과 같다.
logical reads = 94논리적 읽기(logical reads)는 SQL Server가 버퍼 캐시에서 읽은 데이터 페이지 수를 의미한다.
조각화가 심하면 쿼리가 필요한 데이터를 찾기 위해 더 많은 페이지를 읽게 되고, 이로 인해 성능 저하가 발생할 수 있다.
조각난 인덱스 다시 작성
1. IX_Address_StateProvinceID 인덱스 REBUILD
다음 T-SQL을 실행하여 IX_Address_StateProvinceID 인덱스를 다시 작성한다.
USE AdventureWorks2017
GO
ALTER INDEX [IX_Address_StateProvinceID] ON [Person].[Address] REBUILD PARTITION = ALL
WITH (PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON)ALTER INDEX ... REBUILD는 인덱스를 새로 다시 만드는 작업이다.
이를 통해 인덱스 페이지가 정리되고, 논리적 순서와 물리적 순서가 더 잘 맞춰지며, 페이지 내부의 빈 공간도 정리된다.
2. 인덱스 조각화 감소 확인
아래 쿼리를 실행하여 IX_Address_StateProvinceID 인덱스의 조각화가 더 이상 50%를 초과하지 않는지 확인한다.
USE AdventureWorks2017
GO
SELECT DISTINCT i.name Index_Name
, avg_fragmentation_in_percent
, db_name(database_id)
, i.object_id
, i.index_id
, index_type_desc
FROM
sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps
INNER JOIN sys.indexes i ON (ps.object_id = i.object_id AND ps.index_id = i.index_id)
WHERE i.name = 'IX_Address_StateProvinceID'결과를 비교하면 IX_Address_StateProvinceID 인덱스의 조각화가 약 81%에서 0%로 감소한 것을 확인할 수 있다.
| 항목 | REBUILD 전 | REBUILD 후 |
|---|---|---|
| IX_Address_StateProvinceID 조각화율 | 약 81% | 0% |
인덱스 재작성 후 논리적 읽기 비교
1. 동일한 SELECT 쿼리 재실행
이전 섹션에서 실행했던 집계 쿼리를 다시 실행한다.
SET STATISTICS IO,TIME ON
GO
USE AdventureWorks2017
GO
SELECT DISTINCT (StateProvinceID)
,count(StateProvinceID) AS CustomerCount
FROM person.Address
GROUP BY StateProvinceID
ORDER BY count(StateProvinceID) DESC;
GO2. Messages 탭에서 logical reads 재확인
인덱스를 다시 작성했기 때문에 이전보다 효율적으로 데이터를 읽을 수 있다.
실습 자료 기준으로 인덱스 재작성 후 논리적 읽기는 다음과 같이 감소한다.
logical reads = 70| 상태 | logical reads |
|---|---|
| 인덱스 REBUILD 전 | 94 |
| 인덱스 REBUILD 후 | 70 |
즉, 인덱스 유지 관리가 쿼리 성능에 영향을 줄 수 있다는 것을 확인할 수 있다.
실습 결과 정리
이번 실습에서는 인덱스를 다시 작성하고 논리적 읽기를 분석하여 쿼리 성능을 높이는 방법을 확인했다.
1. 인덱스 조각화의 이해 및 영향 확인
인덱스 조각화(Index Fragmentation)는 데이터베이스에서 데이터가 삽입, 업데이트, 삭제되는 과정에서 발생한다.
인덱스의 논리적 순서와 실제 디스크상의 물리적 순서가 달라지거나, 데이터 페이지 내부에 빈 공간이 생기는 현상을 말한다.
이 실습에서는 대량의 데이터를 삽입하여 인덱스 조각화를 인위적으로 발생시켰다. 이를 통해 조각화가 실제로 어떻게 발생하는지 간접적으로 경험할 수 있었다.
가장 중요한 점은 조각화가 심해지면 SQL Server가 데이터를 읽을 때 더 많은 페이지를 읽어야 한다는 것이다.
그래서 이 실습에서는 SET STATISTICS IO ON을 사용해 논리적 읽기(Logical Reads) 횟수를 측정했다. 조각화된 인덱스를 사용하는 쿼리는 불필요하게 많은 페이지를 읽게 되어 성능 저하를 유발할 수 있다.
2. 조각화 진단 방법 학습
조각화 상태는 sys.dm_db_index_physical_stats 동적 관리 뷰(DMV)를 사용해 확인한다.
이 DMV를 통해 특정 테이블이나 특정 인덱스의 조각화 수준을 퍼센트로 확인할 수 있다.
DBA가 시스템 상태를 진단할 때 사용하는 핵심 도구 중 하나이다.
3. 조각화 해결 방법 학습 및 효과 검증
심하게 조각화된 인덱스는 ALTER INDEX REBUILD 명령어를 사용하여 다시 작성할 수 있다.
인덱스 재구축은 인덱스 페이지를 새로 만들고, 물리적 순서를 논리적 순서에 가깝게 정리하며, 페이지 내부의 빈 공간을 제거한다.
참고로 ALTER INDEX REORGANIZE는 온라인으로 조각화를 일부 정리하는 다른 방법이다.
실습에서는 인덱스를 재구축한 후 동일한 쿼리를 다시 실행했다. 그 결과 논리적 읽기 수가 감소하는 것을 확인했다.
이는 조각화 해결이 실제 쿼리 성능 향상으로 이어질 수 있음을 보여준다.
4. 데이터베이스 유지 관리의 중요성
인덱스 조각화는 시간이 지나면서 자연스럽게 발생한다.
따라서 데이터베이스 성능을 최적으로 유지하려면 정기적인 인덱스 유지 관리가 필요하다.
DBA는 주기적으로 조각화 수준을 모니터링하고, 필요에 따라 인덱스를 재구성하거나 다시 작성해야 한다.
핵심 요약
| 구분 | 내용 |
|---|---|
| 문제 | 인덱스 조각화로 인해 불필요한 페이지 읽기 증가 |
| 진단 도구 | sys.dm_db_index_physical_stats |
| 측정 지표 | avg_fragmentation_in_percent, logical reads |
| 조각화 유발 | Person.Address에 대량 INSERT |
| 해결 방법 | ALTER INDEX ... REBUILD |
| 효과 | 조각화율 약 81% → 0%, logical reads 94 → 70 |
| 의미 | 인덱스 유지 관리가 쿼리 성능에 영향을 미침 |
사용한 주요 T-SQL 모음
데이터베이스 복원
RESTORE DATABASE AdventureWorks2017
FROM DISK = 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.bak'
WITH RECOVERY,
MOVE 'AdventureWorks2017'
TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017.mdf',
MOVE 'AdventureWorks2017_log'
TO 'C:\LabFiles\Monitor and optimize\AdventureWorks2017_log.ldf';조각화 확인
USE AdventureWorks2017
GO
SELECT i.name Index_Name
, avg_fragmentation_in_percent
, db_name(database_id)
, i.object_id
, i.index_id
, index_type_desc
FROM
sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE avg_fragmentation_in_percent > 50
-- find indexes where fragmentation is greater than 50%데이터 삽입으로 조각화 유발
USE AdventureWorks2017
GO
INSERT INTO [Person].[Address]
([AddressLine1]
,[AddressLine2]
,[City]
,[StateProvinceID]
,[PostalCode]
,[SpatialLocation]
,[rowguid]
,[ModifiedDate])
SELECT AddressLine1,
AddressLine2,
'Amsterdam',
StateProvinceID,
PostalCode,
SpatialLocation,
newid(),
getdate()
FROM Person.Address;
GO논리적 읽기 측정
SET STATISTICS IO,TIME ON
GO
USE AdventureWorks2017
GO
SELECT DISTINCT (StateProvinceID)
,count(StateProvinceID) AS CustomerCount
FROM person.Address
GROUP BY StateProvinceID
ORDER BY count(StateProvinceID) DESC;
GO인덱스 다시 작성
USE AdventureWorks2017
GO
ALTER INDEX [IX_Address_StateProvinceID] ON [Person].[Address] REBUILD PARTITION = ALL
WITH (PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON)특정 인덱스 조각화 확인
USE AdventureWorks2017
GO
SELECT DISTINCT i.name Index_Name
, avg_fragmentation_in_percent
, db_name(database_id)
, i.object_id
, i.index_id
, index_type_desc
FROM
sys.dm_db_index_physical_stats(db_id('AdventureWorks2017'),object_id('person.address'),NULL,NULL,'DETAILED') ps
INNER JOIN sys.indexes i ON (ps.object_id = i.object_id AND ps.index_id = i.index_id)
WHERE i.name = 'IX_Address_StateProvinceID'