
1. 개요
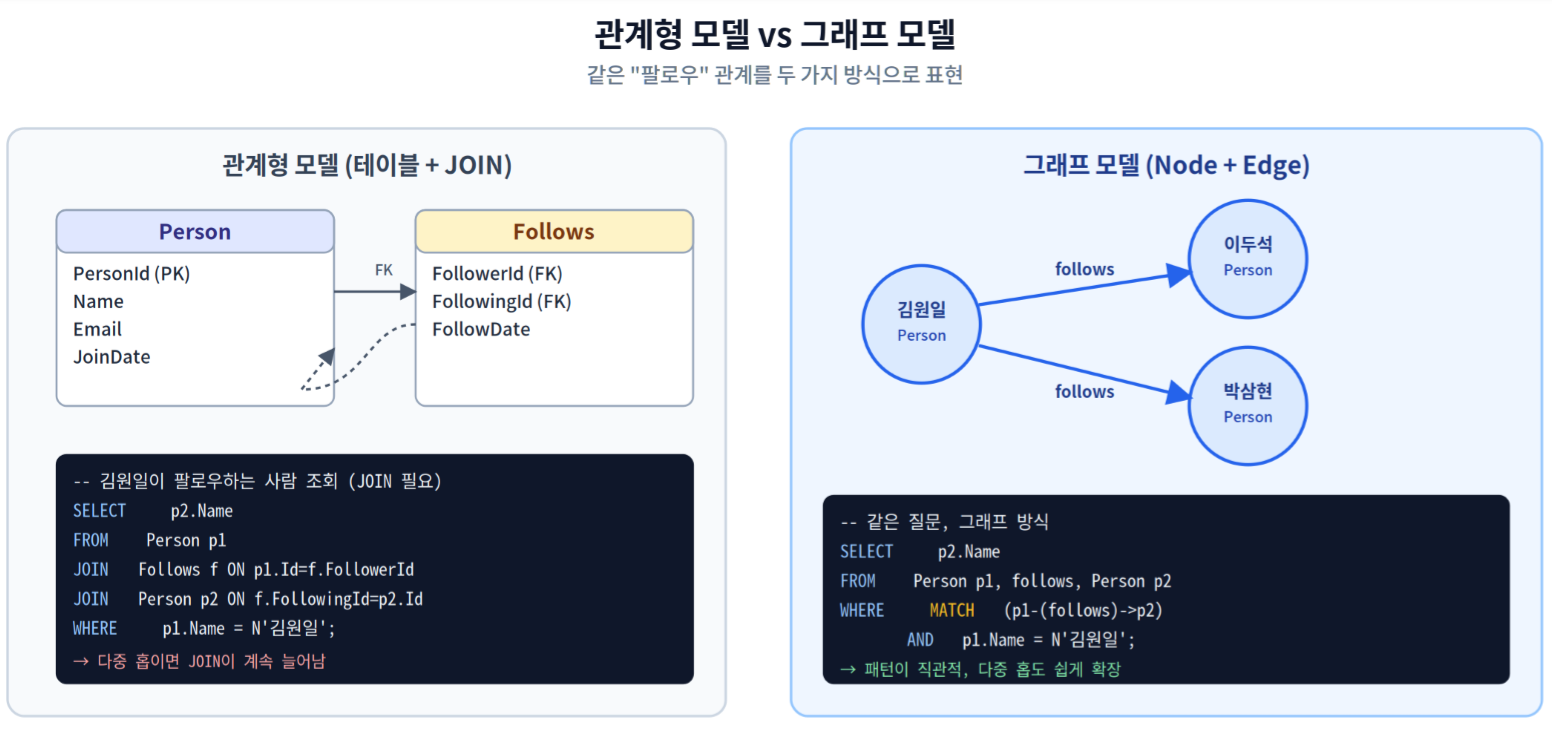
그래프 쪽은 JOIN을 명시적으로 쓰지 않아도 패턴이 곧 쿼리가 됨
1.1 SQL Server Graph Database란?
- SQL Server 2017부터 도입됨
- 노드(Node)와 엣지(Edge)를 사용하여 복잡한 관계형 데이터를 자연스럽게 표현하고 쿼리할 수 있게 해줌
- Azure SQL Database와 Azure SQL VM 모두에서 이 기능을 완벽하게 지원
관계형 모델로도 같은 데이터를 표현할 수 있지만, "친구의 친구의 친구"처럼 여러 단계를 거쳐가는 질의를 JOIN으로 풀려고 하면 SQL이 금세 복잡해집니다. 그래프 모델은 이런 다단계 탐색을 시각적인 패턴 그대로 쿼리로 표현할 수 있게 해 줍니다.
1.2 Graph Database를 사용하는 이유
- 복잡한 관계 표현 — 다대다 관계와 계층 구조를 직관적으로 모델링
- 경로 탐색 — 친구의 친구, 추천 시스템 등 연결 기반 쿼리에 최적화
- 패턴 매칭 — MATCH 절로 복잡한 관계 패턴을 간단하게 표현
- 기존 SQL과 통합 — 관계형 테이블과 그래프 테이블을 함께 사용 가능
💡 언제 그래프 DB가 빛을 발하나요?
- 조직도 / 권한 위임 / 분류 체계처럼 깊이가 가변적인 계층 구조
- 소셜 그래프 (친구·팔로우·차단 등 같은 노드 타입 사이의 다양한 관계)
- 추천 엔진 (콜드 스타트 우회: "비슷한 사람이 좋아하는 것")
- 사기 탐지·자금 흐름 추적 (의심 노드를 시작점으로 N단계 확산 분석)
- 지식 그래프·Knowledge Base (엔티티 + 관계 위주 질의)
1.3 Graph Database 핵심 개념
| 개념 | 설명 / SQL Server 구현 |
|---|---|
| Node (노드) | 엔티티(사람, 게시물, 상품 등)를 표현하는 점. CREATE TABLE ... AS NODE 로 생성하며 내부적으로 $node_id 컬럼이 자동 생성됨 |
| Edge (엣지) | 두 노드를 잇는 방향성 있는 선. CREATE TABLE ... AS EDGE 로 생성하며 $edge_id, $from_id, $to_id 컬럼이 자동 생성됨 |
| $node_id | 노드 고유 ID. JSON 형식({"schema":"...", "table":"...", "id":"..."})이며 시스템이 자동 부여 |
| $edge_id | 엣지 고유 ID. $node_id와 동일한 JSON 형식 사용 |
| $from_id / $to_id | 엣지가 연결하는 시작/끝 노드의 $node_id 값. 엣지 방향 정의 |
| MATCH | WHERE 절에서 그래프 패턴을 명시하는 키워드. 예: MATCH(A-(e)->B) |
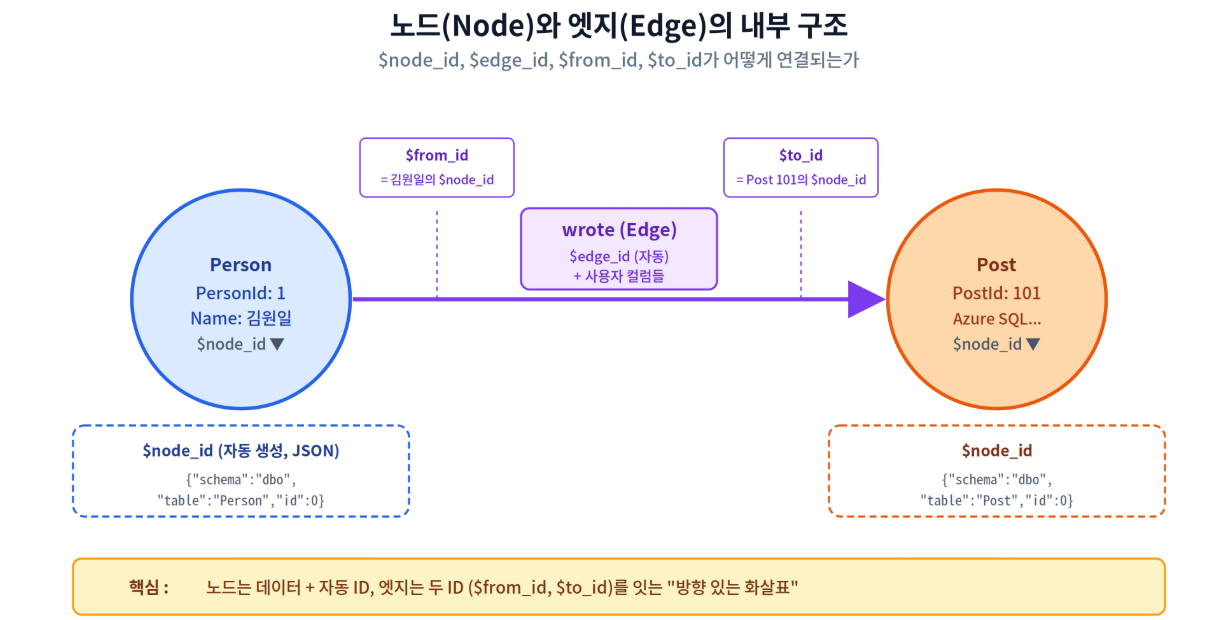
$node_id는 직접 다루면 안됨
$node_id 값은 "{"schema":"dbo","table":"Person","id":0}" 같은 JSON 문자열입니다.
직접 INSERT하거나 비교 키로 외부 시스템에 노출하지 마세요. 대신 PersonId 같은 비즈니스 키로 식별하고, $node_id는 시스템 내부 조인용으로만 씁니다.
2. 환경 설정 및 샘플 데이터
2.1 시나리오: 소셜 네트워크
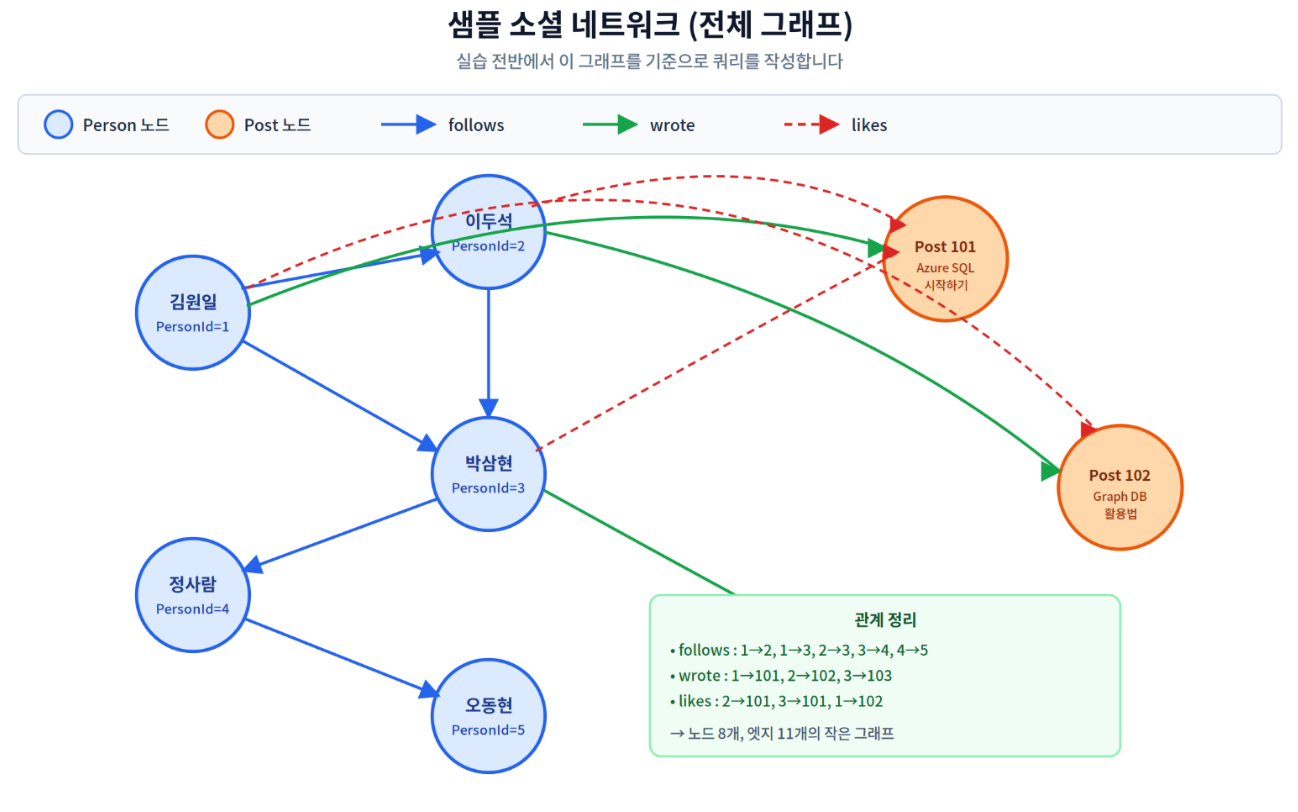
이 실습에서는 작은 소셜 네트워크를 모델링합니다. 사용자(Person) 5명과 게시물(Post) 3개가 있고, 사용자 간에는 팔로우 관계가, 사용자와 게시물 사이에는 작성/좋아요 관계가 형성됩니다. 앞으로 모든 쿼리는 이 한 장의 그래프를 기준으로 다양한 질문을 던지게 됩니다.
나같은경우엔 sql vm 생성 시 이미지 선택을 잘못했는지, SSMS가 설치되어있지 않았다.
별도로 설치한 후, 연결은
- 서버이름: localhost
- 인증서 신뢰 체크
후 진행하였다.
2.2 Node 테이블 생성
핵심 키워드는 끝부분의 AS NODE 입니다.
-- 사용자 노드 테이블
CREATE TABLE Person (
PersonId INT PRIMARY KEY,
Name NVARCHAR(100),
Email NVARCHAR(200),
JoinDate DATE DEFAULT GETDATE()
) AS NODE;
-- 게시물 노드 테이블
CREATE TABLE Post (
PostId INT PRIMARY KEY,
Title NVARCHAR(200),
Content NVARCHAR(MAX),
CreatedAt DATETIME2 DEFAULT GETDATE()
) AS NODE; 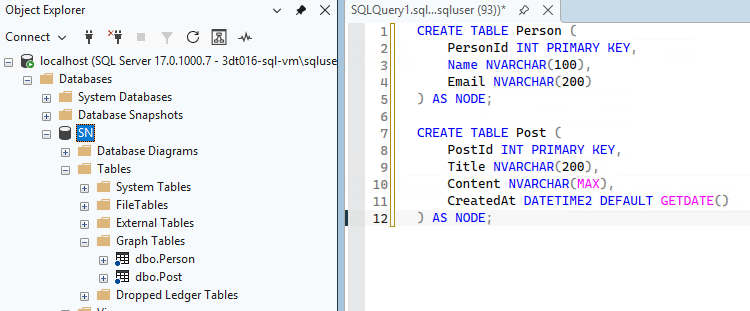
① AS NODE 키워드
테이블 정의 마지막에 AS NODE를 붙이는 것이 그래프 노드 선언의 전부입니다. 이 한 줄로 SQL Server는 내부적으로 $node_id라는 보이지 않는 컬럼을 추가합니다.
② PRIMARY KEY는 별개
PersonId는 우리가 부여하는 비즈니스 식별자, $node_id는 시스템이 부여하는 그래프 식별자입니다. 두 개가 공존하며 역할이 다릅니다.
③ 일반 컬럼은 자유
Name, Email 등 평소 테이블 만들듯이 컬럼을 자유롭게 추가하면 됩니다. 그래프 테이블도 본질은 일반 테이블입니다.
④ Post 테이블도 동일 패턴
Person과 똑같이 AS NODE로 끝맺기만 하면 됩니다. 노드 타입이 두 종류 이상이어도 패턴은 같습니다.
Person, Post 두 테이블이 생성되며, 각 테이블에는 우리가 정의한 컬럼 외에 $node_id가 숨겨진 형태로 추가됩니다.
sys.tables 카탈로그 뷰에서 is_node = 1로 표시되며, sys.columns에서 graph_type 값을 가진 시스템 컬럼들이 함께 보입니다.
아직 데이터는 비어 있고, 두 테이블 사이에는 어떤 관계도 없습니다 — 관계는 다음 단계의 Edge 테이블이 담당합니다.
2.3 Edge 테이블 생성
-- 팔로우 관계 (Person → Person)
CREATE TABLE follows (
FollowDate DATE DEFAULT GETDATE()
) AS EDGE;
-- 좋아요 관계 (Person → Post)
CREATE TABLE likes (
LikedAt DATETIME2 DEFAULT GETDATE()
) AS EDGE;
-- 작성 관계 (Person → Post)
CREATE TABLE wrote AS EDGE; ① AS EDGE 키워드
엣지 테이블이 됨을 선언합니다. 자동으로 $edge_id, $from_id, $to_id 세 개의 컬럼이 생성됩니다.
② 엣지 속성 컬럼
follows의 FollowDate처럼, 관계 자체에 대한 메타데이터(언제 맺어졌는지, 가중치 등)를 컬럼으로 자유롭게 둘 수 있습니다.
③ 컬럼 없는 엣지도 가능
wrote 테이블처럼 사용자 정의 컬럼이 하나도 없어도 됩니다. AS EDGE만 있으면 시스템 컬럼만으로 동작합니다.
④ 방향성
엣지는 항상 $from_id → $to_id 방향을 갖습니다. 양방향 관계를 표현하고 싶다면 동일한 엣지를 반대 방향으로 한 번 더 INSERT 하면 됩니다.
⚠️ 엣지 테이블에는 PRIMARY KEY를 두지 않습니다
$edge_id가 시스템 PK 역할을 자동으로 하므로 굳이 추가 PK를 둘 필요가 없습니다. 추가 PK를 두면 같은 두 노드 사이에 여러 엣지(예: 같은 사람이 같은 게시물을 시점을 달리해 두 번 좋아요)를 만들 수 없게 되어 오히려 모델링이 어색해집니다. PRIMARY KEY가 없다고 해서 취소 여부를 못 아는 게 아니라, 엣지 테이블에 FollowedAt, UnfollowedAt, IsActive 같은 속성을 넣어서 관계 자체를 상태 데이터로 관리하는게 보통입니다.
혹은 SCD를 사용한다.
SCD
데이터 웨어하우스에서 “시간이 지나며 바뀌는 데이터”를 어떻게 관리할지에 대한 패턴
| 구분 | Type 1 | Type 2 |
| -------- | --------- | ---------------- |
| 데이터 변경 시 | 기존 데이터 수정 | 새 행 추가 |
| 과거 데이터 | 사라짐 | 유지 |
| 테이블 크기 | 작음 | 커짐 |
| 구현 난이도 | 쉬움 | 복잡 |
| 분석 용도 | 현재 상태 중심 | 이력 분석 가능 |
| 예시 | 최신 프로필 | 팔로우 이력, 주소 변경 이력 |
2.4 샘플 데이터 삽입
노드 데이터를 먼저 삽입한 후, 엣지 데이터를 삽입합니다. 이 순서는 매우 중요합니다 — 엣지가 참조할 노드가 먼저 존재해야 합니다.
① 노드 데이터
-- 사용자 노드 삽입
INSERT INTO Person (PersonId, Name, Email) VALUES
(1, N'김원일', 'kim@example.com'),
(2, N'이두석', 'lee@example.com'),
(3, N'박삼현', 'park@example.com'),
(4, N'정사람', 'jung@example.com'),
(5, N'오동현', 'oh@example.com');
-- 게시물 노드 삽입
INSERT INTO Post (PostId, Title, Content) VALUES
(101, N'Azure SQL 시작하기', N'Azure SQL의 기본 사용법을 알아봅니다…'),
(102, N'Graph DB 활용법', N'소셜 네트워크 구현 예제입니다…'),
(103, N'성능 최적화 팁', N'쿼리 성능을 향상시키는 방법…'); ② 엣지 데이터 (follows)
-- 팔로우 관계 삽입 (누가 누구를 팔로우하는지)
INSERT INTO follows ($from_id, $to_id) VALUES
((SELECT $node_id FROM Person WHERE PersonId = 1),
(SELECT $node_id FROM Person WHERE PersonId = 2)), -- 김원일 → 이두석
((SELECT $node_id FROM Person WHERE PersonId = 1),
(SELECT $node_id FROM Person WHERE PersonId = 3)), -- 김원일 → 박삼현
((SELECT $node_id FROM Person WHERE PersonId = 2),
(SELECT $node_id FROM Person WHERE PersonId = 3)), -- 이두석 → 박삼현
((SELECT $node_id FROM Person WHERE PersonId = 3),
(SELECT $node_id FROM Person WHERE PersonId = 4)), -- 박삼현 → 정사람
((SELECT $node_id FROM Person WHERE PersonId = 4),
(SELECT $node_id FROM Person WHERE PersonId = 5)); -- 정사람 → 오동현 ① $from_id, $to_id에 직접 INSERT
엣지를 만들 때는 두 시스템 컬럼 $from_id, $to_id에 값을 채워 넣습니다. 이 값들은 노드의 $node_id (JSON)와 동일한 형태여야 합니다.
② 서브쿼리로 $node_id 조회
JSON 값을 직접 입력하긴 어렵기 때문에, (SELECT $node_id FROM Person WHERE PersonId = 1) 형태로 비즈니스 키 → $node_id 변환을 매번 거칩니다. 이 패턴이 그래프 INSERT의 표준 관용구입니다.
③ 한 INSERT에 여러 엣지
VALUES 절에 행을 콤마로 나열하면 한 번의 INSERT로 여러 엣지를 만들 수 있어 트랜잭션 비용이 줄어듭니다.
④ 결과 그래프
실행이 끝나면 그림 2-1의 follows 5개 엣지가 모두 만들어집니다. 5명의 Person 노드를 잇는 사슬과 분기 구조가 형성됩니다.
Edge Table에 중복 안넣는 방법
팔로우 했다가 취소했다가 팔로하면? 삭제하지 않고 그냥 둔다. 따라서 보통은 중복을 허용한다. 굳이 중복방지를 하고싶다면 조건을 걸면 된다. edge table에 굳이 추가 PK를 두지 않는것도 있다.
③ 엣지 데이터 (wrote, likes)
-- 게시물 작성 관계
INSERT INTO wrote ($from_id, $to_id) VALUES
((SELECT $node_id FROM Person WHERE PersonId = 1),
(SELECT $node_id FROM Post WHERE PostId = 101)), -- 김원일 → Post 101
((SELECT $node_id FROM Person WHERE PersonId = 2),
(SELECT $node_id FROM Post WHERE PostId = 102)), -- 이두석 → Post 102
((SELECT $node_id FROM Person WHERE PersonId = 3),
(SELECT $node_id FROM Post WHERE PostId = 103)); -- 박삼현 → Post 103
-- 좋아요 관계
INSERT INTO likes ($from_id, $to_id) VALUES
((SELECT $node_id FROM Person WHERE PersonId = 2),
(SELECT $node_id FROM Post WHERE PostId = 101)),
((SELECT $node_id FROM Person WHERE PersonId = 3),
(SELECT $node_id FROM Post WHERE PostId = 101)),
((SELECT $node_id FROM Person WHERE PersonId = 1),
(SELECT $node_id FROM Post WHERE PostId = 102)); 🎯 실습 과제 1
과제 1-A.
새 사용자 "최여섯"(PersonId=6)을 INSERT한 뒤, 김원일이 최여섯을 팔로우하는 엣지를 추가하세요.
INSERT INTO Person (PersonId, Name) VALUES
(6,N'최여섯');
INSERT INTO follows ($from_id, $to_id) VALUES
((SELECT $node_id FROM Person WHERE PersonId = 1),
(SELECT $node_id FROM Person WHERE PersonId = 6)); -- 김원일 → 최여섯 과제 1-B.
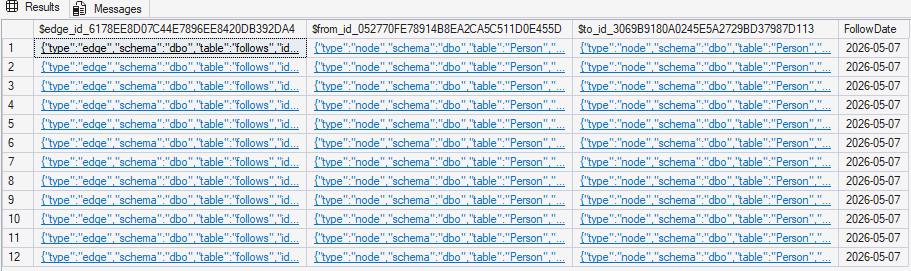
SELECT FROM Person; 과 SELECT FROM follows; 를 각각 실행해서 $node_id, $from_id, $to_id 값이 실제로 어떻게 생겼는지 눈으로 확인해 보세요.
SELECT * FROM Person;
SELECT * FROM follows;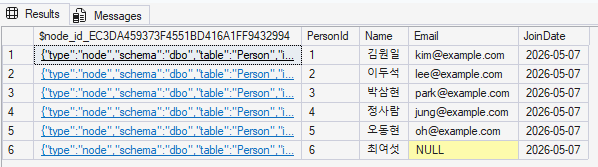
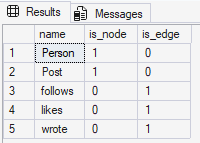
과제 1-C.
시스템 카탈로그를 사용해 이 데이터베이스의 모든 노드 테이블과 엣지 테이블을 나열해 보세요. 힌트: SELECT name, is_node, is_edge FROM sys.tables WHERE is_node = 1 OR is_edge = 1;
3. MATCH — 그래프 패턴 쿼리
3.1 이론
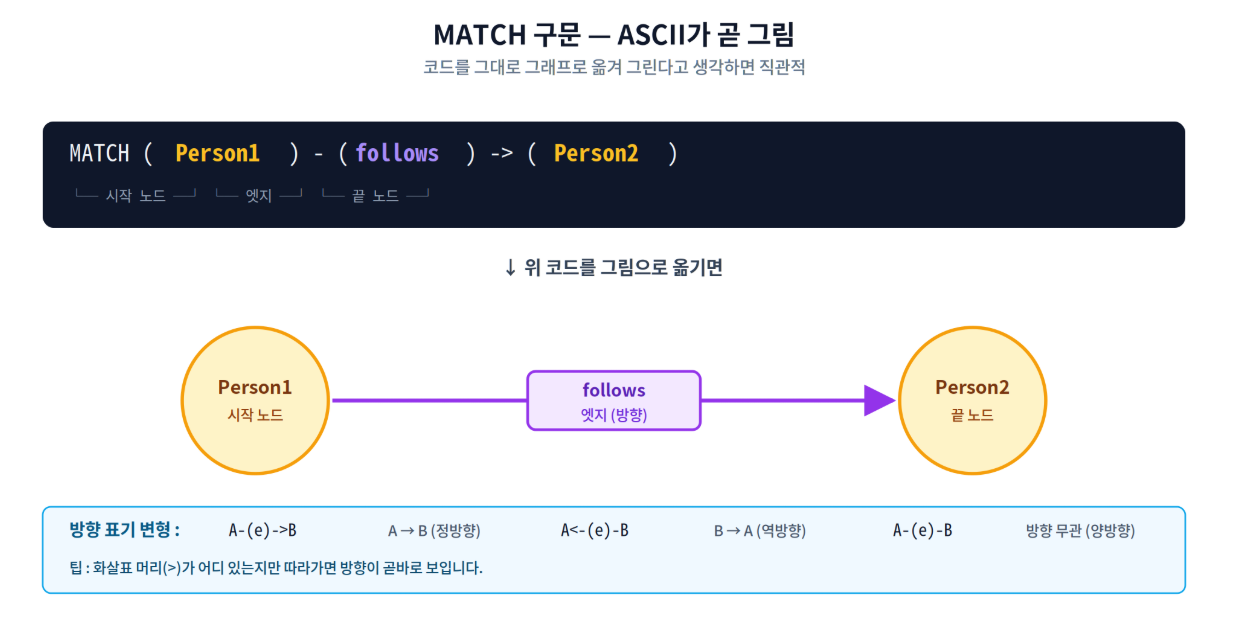
노드와 엣지를 ASCII 아트처럼 그려서 패턴을 정의하면, SQL Server가 그래프를 따라가며 그 패턴에 맞는 모든 경로를 찾아옵니다.
핵심은 "코드에 그린 그림이 곧 찾고자 하는 패턴"이라는 점입니다. (A)-(e)->(B) 라고 쓰면 노드 A에서 엣지 e를 타고 노드 B로 가는 모든 쌍을 찾는다는 의미가 됩니다.
| 구문 요소 | 의미 |
|---|---|
| (node) | 노드. FROM 절에 등장한 노드 테이블의 별칭(alias)을 그대로 사용 |
| -(edge)-> | 정방향 엣지. 왼쪽 노드의 $node_id가 엣지의 $from_id와 같고, 오른쪽 노드의 $node_id가 $to_id와 같은 행 탐색 |
| <-(edge)- | 역방향 엣지. from/to가 반대 방향인 형태 |
| -(edge)- | 방향 무관 탐색 (양방향 시도). SQL Server 2019부터 지원 |
| MATCH(...) | WHERE 절에서 그래프 패턴 전체를 감싸는 표현식. 일반 조건과 AND 결합 가능 |
3.2 기본 패턴 매칭
직접 연결된 노드 찾기
SELECT
Person1.Name AS Follower,
Person2.Name AS Following
FROM Person AS Person1, follows, Person AS Person2
WHERE MATCH(Person1-(follows)->Person2)
AND Person1.Name = N'김원일'; 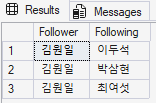
① FROM 절에 노드와 엣지 모두 나열
같은 Person 테이블이지만 시작 노드와 끝 노드 두 역할로 쓰이므로, 별칭 Person1, Person2로 두 번 나타나게 합니다. 가운데 follows는 엣지 테이블 그 자체입니다.
② WHERE MATCH(...) — 패턴 정의
MATCH 절은 "Person1에서 follows 엣지를 타고 Person2로 가는 경로"를 의미합니다. SQL Server는 이 표현을 "follows.node_id AND follows.node_id"라는 조건으로 내부 변환합니다.
③ AND Person1.Name = N'김원일' — 시작점 고정
MATCH 패턴 자체에 비교 조건을 끼워 넣지 않습니다. 시작 노드를 좁히고 싶을 때는 일반 WHERE 절처럼 AND로 추가합니다.
④ SELECT — 무엇을 가져올지 결정
Person1.Name(팔로워), Person2.Name(팔로잉 대상)을 컬럼명으로 반환합니다. 같은 테이블에서 두 행을 동시에 다루는 self-join 같은 효과를 MATCH 한 줄로 깔끔하게 만든 셈입니다.
역방향 탐색
이번엔 반대로, "박삼현을 팔로우하는 사람들"을 조회합니다. 두 가지 동등한 표현이 있습니다.
-- 방법 A : 순방향 패턴 + 끝 노드를 박삼현으로 고정
SELECT Person1.Name AS Follower
FROM Person AS Person1, follows, Person AS Person2
WHERE MATCH(Person1-(follows)->Person2)
AND Person2.Name = N'박삼현';
-- 방법 B : 역방향 화살표 사용
SELECT Person1.Name AS Follower
FROM Person AS Person1, follows, Person AS Person2
WHERE MATCH(Person2<-(follows)-Person1)
AND Person2.Name = N'박삼현'; 💡 두 표현은 어떻게 다른가요?
결과는 동일합니다. SQL Server가 동일한 실행 계획으로 평가하기 때문에 성능 차이도 없습니다.
가독성 차이만 있습니다. "박삼현 입장에서 자기를 팔로우하는 사람"이라는 관점이 자연스러울 때는 방법 B가 읽기 쉽고, "전체 팔로우 관계 중 끝점이 박삼현"이라는 관점이라면 방법 A가 자연스럽습니다.
3.3 다중 홉(Multi-hop) 탐색
관계형으로는 N홉마다 JOIN이 N-1번 늘어나지만, 그래프에서는 패턴에 화살표를 더 이어붙이기만 하면 됩니다.
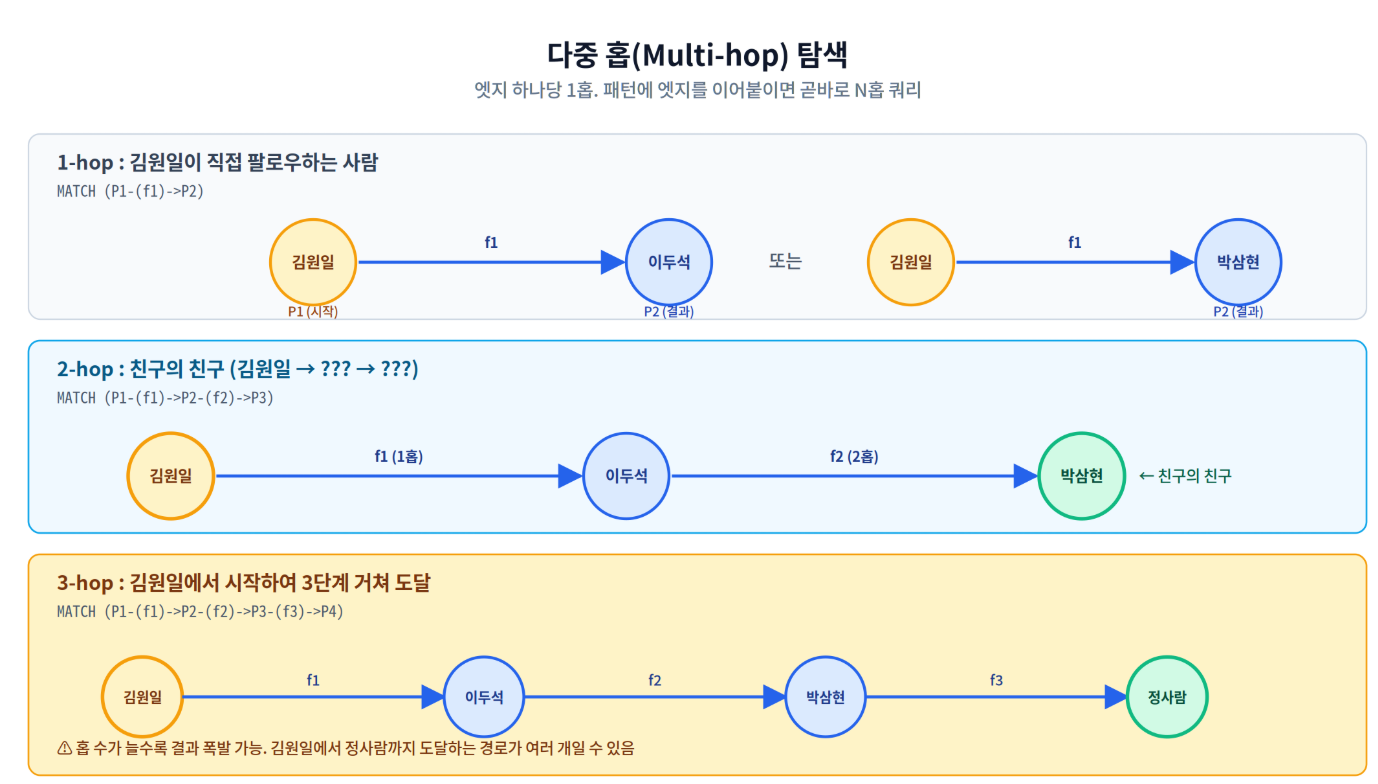
친구의 친구 찾기 (2-hop)
SELECT DISTINCT
Person1.Name AS Person,
Person2.Name AS Friend,
Person3.Name AS FriendOfFriend
FROM
Person AS Person1,
follows AS f1,
Person AS Person2,
follows AS f2,
Person AS Person3
WHERE MATCH(Person1-(f1)->Person2-(f2)->Person3)
AND Person1.Name = N'김원일'
AND Person1.PersonId <> Person3.PersonId; -- 자기 자신 제외 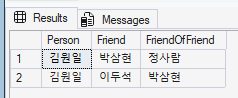
① FROM 절이 길어지는 이유
Person1, Person2, Person3 — 같은 Person 테이블의 별칭이 3개. 엣지도 f1, f2 두 개로 별도 별칭을 부여합니다. 한 패턴 안에 같은 테이블이 여러 번 등장할 수 있기 때문에 별칭은 필수입니다.
② MATCH 패턴 — 화살표 잇기
Person1-(f1)->Person2-(f2)->Person3. 두 엣지가 가운데 노드 Person2를 공유하면서 자연스럽게 이어집니다. 그래프의 ASCII 그림이 곧 우리가 찾고자 하는 경로의 모양.
③ DISTINCT가 필요한 이유
같은 사람이 여러 경로로 도달 가능할 수 있습니다. 예를 들어 X가 다른 두 친구를 통해 동시에 친구의 친구가 되는 경우, DISTINCT 없이는 결과가 중복됩니다.
④ 자기 자신 제외
Person1.PersonId <> Person3.PersonId. 만약 A→B→A라는 상호 팔로우가 있다면 A 자신이 친구의 친구로 잡혀버립니다. 이 조건으로 그런 경우를 제외합니다.
⚠️ 결과 폭발에 주의
N홉 탐색은 평균 차수(degree)의 N제곱에 비례하는 경로 수를 만들어낼 수 있습니다.
평균 팔로우 100명이라면 3홉만 해도 100^3 = 100만 경로 후보가 발생합니다.
실무에서는 보통 2~3홉으로 제한하고, 시작 노드를 명확하게 좁히는 WHERE 조건을 함께 사용합니다.
3단계 연결 탐색 (3-hop)
SELECT DISTINCT
P1.Name AS Start,
P2.Name AS Hop1,
P3.Name AS Hop2,
P4.Name AS Hop3
FROM
Person AS P1, follows AS f1,
Person AS P2, follows AS f2,
Person AS P3, follows AS f3,
Person AS P4
WHERE MATCH(P1-(f1)->P2-(f2)->P3-(f3)->P4)
AND P1.Name = N'김원일'; 
4. 복합 패턴 쿼리
4.1 여러 엣지 타입 결합
한 쿼리 안에서 서로 다른 종류의 엣지를 자유롭게 섞을 수 있습니다. 예를 들어 "내가 팔로우하는 사람이 작성한 게시물"은 follows + wrote 두 엣지 타입을 거치는 패턴입니다.
내가 팔로우하는 사람이 작성한 게시물
SELECT
Person1.Name AS Me,
Person2.Name AS Following,
Post.Title AS PostTitle
FROM
Person AS Person1,
follows,
Person AS Person2,
wrote,
Post
WHERE MATCH(Person1-(follows)->Person2-(wrote)->Post)
AND Person1.Name = N'김원일'; ① 서로 다른 노드 타입의 등장
이 쿼리는 Person 노드 두 개와 Post 노드 하나가 한 패턴에 등장합니다. 노드 별칭만 다르게 잡으면 한 그래프 안에 다양한 종류의 노드를 자유롭게 섞을 수 있습니다.
② 두 엣지 타입을 한 패턴에
follows와 wrote는 의미가 전혀 다른 엣지지만, 가운데 Person2 노드를 공유하면서 자연스럽게 이어집니다. 패턴 표현 그대로 "사람을 따라가서 그 사람이 쓴 글까지" 한 줄로 표현되는 셈.
③ 관계형 모델과 비교
같은 결과를 관계형으로 풀려면 Person ⨝ follows ⨝ Person ⨝ wrote ⨝ Post의 4단계 JOIN이 필요합니다. MATCH 패턴은 이 모든 JOIN 조건을 한 줄로 압축합니다.
4.2 조건부 필터링과 집계
팔로워 수 계산
SELECT
Person2.Name,
COUNT(*) AS FollowerCount
FROM Person AS Person1, follows, Person AS Person2
WHERE MATCH(Person1-(follows)->Person2)
GROUP BY Person2.Name, Person2.PersonId
ORDER BY FollowerCount DESC; ▶ 실행 흐름
1) follows 엣지 전체를 훑어 (시작자, 도착자) 쌍을 모두 만든다.
2) Person2(도착자) 기준으로 그룹화한다.
3) 각 그룹의 행 수를 세면 그 사람이 받은 팔로우 수가 된다.
샘플 그래프에서는 박삼현이 2명(김원일, 이두석)으로 1위, 그 외는 모두 1명
인기 게시물 찾기 (좋아요 수 기준)
SELECT
Post.Title,
COUNT(*) AS LikeCount
FROM Person, likes, Post
WHERE MATCH(Person-(likes)->Post)
GROUP BY Post.PostId, Post.Title
HAVING COUNT(*) >= 2
ORDER BY LikeCount DESC; ① Person 별칭 생략 가능
같은 테이블이 한 패턴에 한 번만 등장하면 별칭(AS …)을 생략하고 테이블명을 그대로 별칭처럼 사용할 수 있습니다. 가독성을 위해 명시하는 것이 보통이지만 짧은 쿼리에서는 생략도 흔합니다.
② GROUP BY에 PK 포함
Title이 같다면 PostId 없이 Title만으로 그룹화하면 잘못 합쳐질 수 있습니다. 비즈니스 키를 GROUP BY에 함께 넣는 습관을 들이세요.
③ HAVING으로 사후 필터
집계 결과에 대한 조건은 WHERE가 아니라 HAVING입니다. "좋아요 2개 이상인 게시물만"이라는 조건이 여기에 해당.
5. 실무 시나리오
5.1 추천 시스템 구현
친구 추천 (공통 친구 기반)
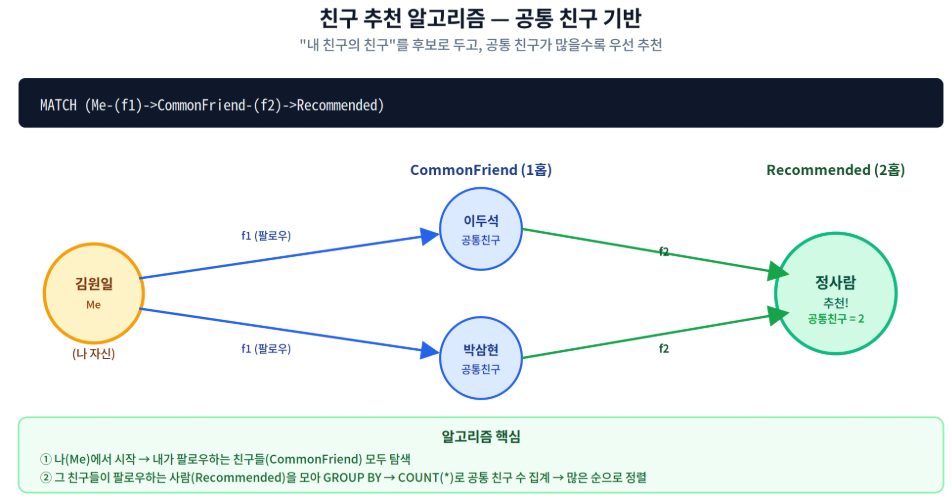
소셜 네트워크의 클래식한 추천 알고리즘 중 하나는 "공통 친구가 많은 사람"을 우선 추천하는 방식입니다. 나의 1-hop 친구(공통 친구)를 거쳐서 도달 가능한 2-hop의 사람을 모두 모은 뒤, 같은 사람이 여러 경로로 도달될수록 점수가 높다고 보는 것이 핵심입니다.
-- 김원일에게 친구 추천: 공통 친구가 많은 사람
SELECT
Recommended.Name AS RecommendedPerson,
COUNT(*) AS CommonFriends
FROM
Person AS Me,
follows AS f1,
Person AS CommonFriend,
follows AS f2,
Person AS Recommended
WHERE MATCH(Me-(f1)->CommonFriend-(f2)->Recommended)
AND Me.Name = N'김원일'
AND Me.PersonId <> Recommended.PersonId
-- 이미 팔로우하는 사람 제외
AND NOT EXISTS (
SELECT 1 FROM follows AS existing -- 데이터 존재 여부(TRUE) 를 확인하는 성능 최적화용
WHERE existing.$from_id = Me.$node_id
AND existing.$to_id = Recommended.$node_id
)
GROUP BY Recommended.PersonId, Recommended.Name
ORDER BY CommonFriends DESC; ① Me-(f1)->CommonFriend-(f2)->Recommended
2-hop 패턴. 가운데 CommonFriend는 "내가 팔로우하는 사람"이자 "Recommended를 팔로우하는 사람" 두 역할을 동시에 수행합니다.
② COUNT(*)의 의미
같은 Recommended가 서로 다른 CommonFriend를 통해 여러 번 도달되면, 그만큼 (Me, CommonFriend, Recommended) 행이 여러 개 나옵니다. 이걸 GROUP BY Recommended로 묶어 COUNT하면 곧 "공통 친구의 수"가 됩니다.
③ 자기 자신 제외
A→B→A 형태의 상호 팔로우가 있을 때 자기가 자기에게 추천되는 것을 막습니다.
④ 이미 팔로우 중인 사람 제외 (NOT EXISTS)
Me.node_id로 가는 follows 엣지가 이미 존재하면 추천 후보에서 빼야 합니다. NOT EXISTS는 결과 1건만 확인되면 빠르게 끝나기 때문에 NOT IN 보다 효율적이고 NULL 안전합니다.
⑤ 결과 해석
샘플 그래프에서 김원일에게 추천될 수 있는 후보는 정사람뿐(박삼현 → 정사람 경로). 이두석 → 박삼현 경로는 박삼현이 이미 팔로우 중이라 NOT EXISTS에서 걸러집니다.
select 1
- 데이터 값 자체는 필요 없고, 조건을 만족하는 행이 존재하는지만 확인하고 싶을 때
- DB 연결 테스트
- 쿼리 동작 확인용
콘텐츠 추천 (팔로우하는 사람들이 좋아한 게시물)
SELECT
Post.Title,
COUNT(DISTINCT Following.PersonId) AS LikedByFollowing
FROM
Person AS Me,
follows,
Person AS Following,
likes,
Post
WHERE MATCH(Me-(follows)->Following-(likes)->Post)
AND Me.Name = N'김원일'
-- 내가 이미 좋아요한 게시물 제외
AND NOT EXISTS (
SELECT 1 FROM likes AS myLikes
WHERE myLikes.$from_id = Me.$node_id
AND myLikes.$to_id = Post.$node_id
)
GROUP BY Post.PostId, Post.Title
ORDER BY LikedByFollowing DESC; 💡 COUNT(*) vs COUNT(DISTINCT …) 차이
여기서 COUNT()를 쓰면 "내 팔로우 친구 한 명이 같은 게시물에 두 번 좋아요한 경우"가 잘못 가중되어 계산됩니다.
COUNT(DISTINCT Following.PersonId)는 "이 게시물을 좋아한 (서로 다른) 친구 수"라는 정확한 지표가 됩니다. 데이터 모델상 한 사람이 같은 게시물을 두 번 좋아요 할 수 없다면(원천적으로 안된다면) COUNT()도 무방하지만, 안전한 기본값은 DISTINCT.
5.2 영향력 분석
인플루언서 찾기
"받은 팔로워 수"와 "내 글이 받은 좋아요 수"를 합산해 영향력 점수를 계산합니다. CTE(공통 테이블 표현식)로 두 지표를 따로 구하고 마지막에 LEFT JOIN으로 합치는 패턴입니다.
-- 팔로워 수와 게시물 좋아요 수를 합산한 영향력 점수
WITH FollowerCounts AS (
SELECT
Person2.PersonId,
COUNT(*) AS Followers
FROM Person AS Person1, follows, Person AS Person2
WHERE MATCH(Person1-(follows)->Person2)
GROUP BY Person2.PersonId
),
LikeCounts AS (
SELECT
Author.PersonId,
COUNT(*) AS TotalLikes
FROM Person AS Liker, likes, Post, wrote, Person AS Author
WHERE MATCH(Liker-(likes)->Post<-(wrote)-Author)
GROUP BY Author.PersonId
)
SELECT
p.Name,
ISNULL(f.Followers, 0) AS Followers,
ISNULL(l.TotalLikes, 0) AS TotalLikes,
ISNULL(f.Followers, 0) + ISNULL(l.TotalLikes, 0) AS InfluenceScore
FROM Person p
LEFT JOIN FollowerCounts f ON p.PersonId = f.PersonId
LEFT JOIN LikeCounts l ON p.PersonId = l.PersonId
ORDER BY InfluenceScore DESC; ① CTE 1 — FollowerCounts
4.2의 팔로워 수 쿼리를 그대로 가져와 "PersonId별 팔로워 수"를 임시 테이블처럼 다룹니다. CTE는 메인 쿼리에서 한 번만 사용해도 가독성을 크게 높입니다.
② CTE 2 — LikeCounts와 역방향 패턴
Liker-(likes)->Post<-(wrote)-Author. 좋아요한 사람으로부터 게시물로 가고, 그 게시물을 누가 썼는지 역방향으로 가져옵니다. 한 패턴 안에서 "정방향 + 역방향" 혼용이 가능합니다.
③ LEFT JOIN으로 모든 사람 보존
글을 쓴 적 없거나 팔로워가 0인 사람도 결과에 나타나야 합니다. INNER JOIN으로 묶으면 이런 사람이 사라지므로 LEFT JOIN + ISNULL 패턴이 정석.
④ ISNULL로 NULL을 0으로
집계 결과가 없는 사람은 Followers/TotalLikes가 NULL입니다. ISNULL(…, 0)로 0 처리해야 더하기 연산이 망가지지 않습니다.
⚠️ 실무 단순화 주의
"팔로워 수 + 좋아요 수" 단순합은 학습용 예시입니다.
실무에서는 PageRank, HITS, Eigenvector centrality 같은 지표가 훨씬 견고합니다 — "유명한 사람을 많이 팔로우하는 게 단순히 무명인 사람 100명을 팔로우하는 것보다 점수가 높아야" 하기 때문입니다.
SQL Graph 자체는 PageRank 내장 함수를 제공하지 않으므로, 본격 분석은 외부 그래프 엔진(Neo4j GDS, Spark GraphFrames 등)이나 Python(networkx)으로 옮겨 수행하는 것이 일반적입니다.
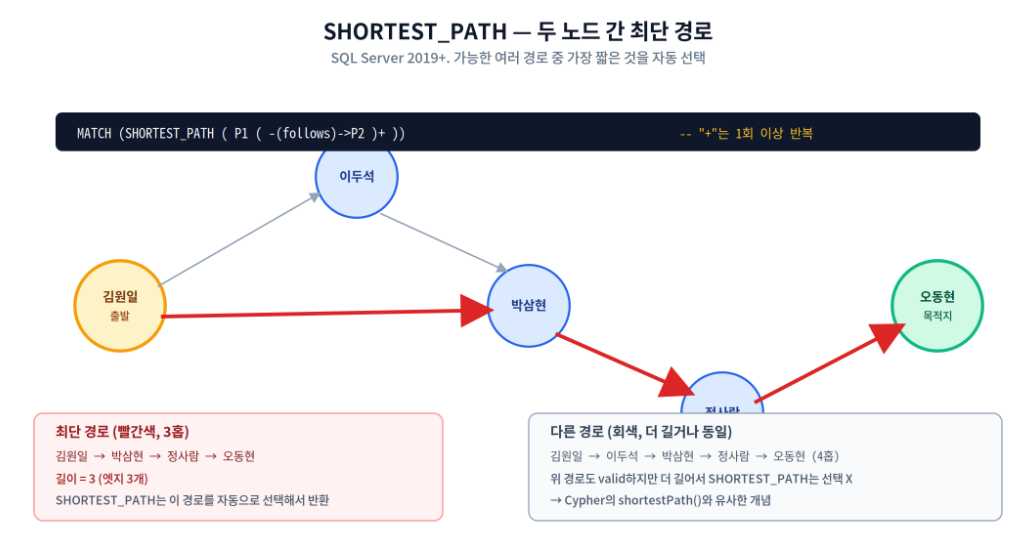
6. SHORTEST_PATH — 최단 경로 탐색
SQL Server 2019부터는 두 노드 간의 최단 경로를 자동으로 찾아주는 SHORTEST_PATH 키워드가 추가되었습니다. "6단계 분리 이론"을 직접 검증해 볼 수 있는 강력한 기능입니다. (Azure SQL Database도 동일한 호환성 레벨에서 지원합니다.)
6.1: "X명까지의 모든 도달 가능 노드"
-- 김원일에서 출발해 follows 경로상 모든 도달 가능한 사람과 거리
SELECT
LAST_VALUE(Person2.Name) WITHIN GROUP (GRAPH PATH) AS Reachable,
STRING_AGG(Person2.Name, ' → ') WITHIN GROUP (GRAPH PATH) AS Path,
COUNT(Person2.PersonId) WITHIN GROUP (GRAPH PATH) AS Distance
FROM
Person AS Person1,
follows FOR PATH AS f,
Person FOR PATH AS Person2
WHERE MATCH( SHORTEST_PATH( Person1( -(f)->Person2 )+ ) )
AND Person1.Name = N'김원일'
ORDER BY Distance; 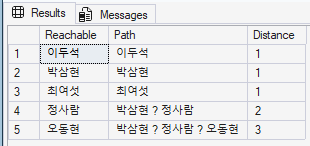
이 쿼리는 김원일이 follows 경로로 도달 가능한 모든 사람과 그 사람까지의 최단 거리, 그리고 거치는 경로를 한꺼번에 반환합니다. 거리 1(직접 팔로우), 거리 2(친구의 친구), 거리 3 형태로 자연스럽게 묶입니다.
⚠️SHORTEST_PATH 사용상 주의
SHORTEST_PATH는 "엣지 가중치"를 고려하지 않는 단순 BFS입니다. 가중치가 있는 최단 경로(다익스트라)가 필요하면 SQL Graph로는 직접 구현할 수 없고, 외부 그래프 엔진을 사용해야 합니다.
하나의 패턴 안에 SHORTEST_PATH는 한 번만 사용 가능합니다.
큰 그래프에서는 시작 노드를 매우 좁게 좁히지 않으면 (예: WHERE Person1.Name = …) 폭발적으로 느려질 수 있습니다.
데이터베이스 호환성 레벨이 140 이상(SQL Server 2019, Azure SQL DB 최신)이어야 합니다.
7. 성능 최적화
7.1 인덱스 전략
그래프 테이블도 결국 일반 테이블이므로, 일반 SQL Server의 인덱스 전략이 그대로 적용됩니다. 다만 자주 검색되는 시작 노드의 비즈니스 키와, 엣지의 $from_id, $to_id 시스템 컬럼에 인덱스가 잘 걸려 있는지가 핵심입니다.
-- 노드 테이블의 자주 검색되는 컬럼에 인덱스
CREATE INDEX IX_Person_Name ON Person(Name);
CREATE INDEX IX_Post_Title ON Post(Title);
-- 엣지 테이블의 시스템 컬럼에 인덱스 (★ 가장 중요)
CREATE INDEX IX_follows_from ON follows($from_id);
CREATE INDEX IX_follows_to ON follows($to_id);
CREATE INDEX IX_likes_from ON likes($from_id);
CREATE INDEX IX_likes_to ON likes($to_id);
CREATE INDEX IX_wrote_from ON wrote($from_id);
CREATE INDEX IX_wrote_to ON wrote($to_id); ① 시작점 좁히기용 인덱스
IX_Person_Name 같은 비즈니스 컬럼 인덱스는 "Name = N'김원일'" 같은 조건이 시작 노드를 빠르게 찾도록 도와줍니다. 시작 노드를 좁히지 못하면 그래프 전체를 훑게 되어 성능 저하의 가장 흔한 원인이 됩니다.
② $from_id, $to_id 인덱스
그래프 탐색은 본질적으로 "엣지의 한쪽 끝 ID를 기준으로 다른 쪽을 찾는" 연산의 반복입니다. 이 두 컬럼이 인덱스 없이 풀 스캔되면 N홉 쿼리가 N제곱으로 느려집니다. 엣지 테이블을 만들면 거의 자동 반사로 두 인덱스를 함께 만드세요.
③ 복합 인덱스 고려
특정 조건(예: 특정 기간의 follows만)이 자주 함께 들어간다면 ($from_id, FollowDate) 같은 복합 인덱스가 더 유리할 수 있습니다. 단순 단일 컬럼 인덱스만 무한정 만드는 것이 능사는 아닙니다.
7.2 모범 사례
1. 명명 규칙
Node는 단수 명사 단수형(Person, Post), Edge는 동사 또는 관계명(follows, likes, wrote). 엣지가 동사형이면 패턴이 자연어처럼 읽힙니다.
2. 데이터 무결성
엣지 제약 조건을 적극 활용해 잘못된 노드 타입 사이에 엣지가 만들어지지 않도록.
3. 성능 모니터링
실행 계획에서 Edge Scan, Filter 비용이 큰 단계를 찾아내고, 인덱스/통계 갱신을 주기적으로 수행.
4. 홉 수 제한
가능한 한 명시적인 N-hop 쿼리(2~3홉)로 작성하고, 무제한 SHORTEST_PATH는 시작 노드가 충분히 좁혀진 경우에만.
8. 관계형 + 그래프 통합
8.1 하이브리드 쿼리
Graph DB의 가장 큰 장점 중 하나는 기존 관계형 테이블과 자유롭게 결합할 수 있다는 점입니다. 그래프 패턴 + 일반 JOIN을 한 쿼리에 섞을 수 있어, 별도 NoSQL 그래프 DB로 ETL할 필요 없이 같은 데이터베이스 안에서 모든 분석을 할 수 있습니다.
-- 가정: 일반 관계형 테이블 UserActivity가 있다
CREATE TABLE UserActivity (
ActivityId INT IDENTITY PRIMARY KEY,
PersonId INT,
ActivityType NVARCHAR(50),
ActivityDate DATETIME2 DEFAULT GETDATE()
);
-- 그래프 패턴 + 관계형 JOIN을 한 쿼리에 섞기
SELECT
p.Name,
COUNT(DISTINCT f2.$to_id) AS FollowingCount,
COUNT(DISTINCT ua.ActivityId) AS RecentActivities
FROM Person p
LEFT JOIN follows f2 ON f2.$from_id = p.$node_id
LEFT JOIN UserActivity ua
ON p.PersonId = ua.PersonId
AND ua.ActivityDate >= DATEADD(day, -7, GETDATE())
GROUP BY p.PersonId, p.Name; ① $node_id로 직접 JOIN
MATCH 절을 쓰지 않고도, follows 엣지의 $from_id와 Person의 $node_id를 직접 ON 조건으로 묶을 수 있습니다. 그래프 패턴 표현이 어색한 상황에서 유용한 우회로.
② 관계형 테이블과 자연스럽게 결합
UserActivity는 그래프와 무관한 일반 테이블이지만, PersonId라는 비즈니스 키로 자연스럽게 LEFT JOIN됩니다. 같은 데이터베이스 안에 있다는 것의 큰 이점.
③ COUNT(DISTINCT)의 두 용도
f2.$to_id를 DISTINCT 카운트하면 "팔로잉 인원"을, ua.ActivityId를 DISTINCT 카운트하면 "활동 건수"를 동시에 한 GROUP BY 안에서 산출할 수 있습니다. 두 측면을 각각 별도 쿼리로 만들고 합치는 수고를 덜어줍니다.
8.2 그래프 데이터를 JSON으로 내보내기
그래프를 외부 시스템(D3.js, 시각화 도구 등)에 전달할 때 흔한 형식은 nodes/edges가 분리된 JSON입니다.
-- 노드를 JSON 배열로
SELECT
PersonId AS id,
Name AS label,
'Person' AS type
FROM Person
FOR JSON PATH, ROOT('nodes');
-- 엣지를 JSON 배열로
SELECT
Person1.PersonId AS source,
Person2.PersonId AS target,
'follows' AS type
FROM Person AS Person1, follows, Person AS Person2
WHERE MATCH(Person1-(follows)->Person2)
FOR JSON PATH, ROOT('edges'); 💡 FOR JSON PATH의 결과 형태
{ "nodes": [ {"id":1,"label":"김원일","type":"Person"}, … ] } 형태가 한 줄로 반환됩니다.
필요하면 두 쿼리 결과를 애플리케이션 단에서 합쳐 { nodes:[…], edges:[…] } 형태로 만든 뒤 D3.js force layout 등으로 렌더링하면 됩니다.
대용량 그래프라면 FOR JSON 결과가 행당 2GB 한도에 부딪힐 수 있으므로 페이지 단위로 잘라 내보내는 패턴이 안전합니다.
9. 자주 하는 실수 / 트러블슈팅
9.1 노드/엣지 정의 실수
⚠️ 실수 1: AS NODE / AS EDGE 키워드 누락
증상: 평범한 테이블이 만들어지지만, 이후 MATCH 쿼리에서 "테이블이 그래프 노드/엣지가 아닙니다" 류 에러가 발생.
원인: CREATE TABLE 마지막의 AS NODE 또는 AS EDGE를 빠뜨림.
해결: 테이블을 DROP한 뒤 다시 생성하거나, 새 그래프 테이블을 만들고 데이터를 옮긴 뒤 교체. (일반 테이블 → 그래프 테이블로의 자동 변환은 지원되지 않음.)
⚠️ 실수 2: 엣지 테이블에 PRIMARY KEY 추가
증상: 같은 두 노드 사이에 여러 엣지를 만들 수 없게 됨. 예) "한 사람이 같은 게시물을 두 번 좋아요"가 안 됨.
원인: $edge_id가 시스템 PK 역할을 하는데, 추가로 사용자 PK를 두면 의도치 않은 유일성 제약이 걸림.
해결: 엣지 테이블에는 일반 PK를 두지 않습니다. 유일성이 정말 필요하면 UNIQUE INDEX로 명시적으로 표현.
9.2 INSERT 단계의 실수
⚠️ 실수 3: $node_id를 직접 INSERT하려 함
증상: "$node_id 컬럼에 직접 값을 삽입할 수 없습니다" 류 에러.
원인: $node_id는 시스템이 자동 생성하는 컴퓨티드 컬럼. 사용자가 값을 넣을 수 없습니다.
해결: INSERT INTO Person (PersonId, Name, …) VALUES … 형태로, 시스템 컬럼은 빼고 비즈니스 컬럼만 명시.
⚠️ 실수 4: 엣지 INSERT 시 NULL $from_id / $to_id
증상: 엣지가 만들어졌지만 MATCH 쿼리에서 잡히지 않음.
원인: 서브쿼리 (SELECT $node_id FROM Person WHERE PersonId = 999)가 매칭 행이 없어 NULL을 반환했고, NULL인 채로 INSERT됨.
해결: 서브쿼리 작성 시 비즈니스 키가 실제 존재하는지 먼저 확인. 또는 INSERT 전에 EXISTS 체크를 추가하거나, 트랜잭션 + RAISERROR 패턴으로 안전망 구성.
9.3 MATCH 절 작성 실수
⚠️ 실수 5: MATCH를 SELECT 절에 적음
증상: "MATCH 절은 WHERE 절에서만 사용할 수 있습니다" 에러.
원인: 익숙한 SQL 사고방식으로 SELECT나 FROM 위치에 MATCH를 두려고 함.
해결: MATCH는 반드시 WHERE 절 안에 위치. 일반 비교 조건은 AND로 자유롭게 결합.
⚠️ 실수 6: FROM 절에 같은 테이블 별칭 누락
증상: "Person이 두 번 사용되었지만 별칭이 없습니다" 류 에러.
원인: 한 패턴에 같은 노드 타입이 여러 번 등장할 때 별칭(AS Person1, AS Person2)을 부여하지 않음.
해결: 같은 테이블이 한 패턴에 두 번 이상 나오면 반드시 다른 별칭을 부여.
⚠️ 실수 7: MATCH 패턴 안에 비교 연산자
증상: 컴파일 에러.
원인: MATCH(Person1.Name = N'김원일'-(follows)->Person2) 처럼 패턴 안에 일반 비교를 넣으려 함.
해결: MATCH 안에는 그래프 패턴만. 일반 비교는 AND로 분리.
9.4 SHORTEST_PATH 관련 실수
⚠️ 실수 8: FOR PATH 키워드 누락
증상: "SHORTEST_PATH 함수의 인수에는 FOR PATH 별칭이 필요합니다" 류 에러.
원인: 가변 길이 패턴 안의 노드/엣지 변수에 FOR PATH 표시가 빠짐.
해결: follows FOR PATH AS f, Person FOR PATH AS Person2 형태로 모든 반복 패턴 변수에 FOR PATH 추가.
⚠️ 실수 9: 호환성 레벨이 낮음
증상: SHORTEST_PATH 키워드 자체를 인식하지 못함.
원인: 데이터베이스 호환성 레벨 < 140.
해결: ALTER DATABASE [DBName] SET COMPATIBILITY_LEVEL = 140; (또는 더 높음). Azure SQL DB에서는 보통 자동으로 최신 레벨이지만, 마이그레이션된 DB는 확인 필요.
9.5 성능 관련 실수
⚠️ 실수 10: 시작 노드를 좁히지 않은 N-hop 쿼리
증상: 데이터가 조금만 커져도 쿼리가 수십 초 ~ 수 분.
원인: WHERE 절에 시작 노드를 좁히는 조건이 없어, 모든 노드 쌍에 대해 N-hop 패턴을 평가함.
해결: AND Person1.Name = …, Person1.PersonId = … 같은 시작 노드 식별 조건을 반드시 함께 사용. 인덱스(7.1)도 함께 점검.
⚠️ 실수 11: $from_id / $to_id 인덱스 부재
증상: 작은 그래프에서는 빠르지만 데이터 증가에 따라 N제곱으로 느려짐.
원인: 엣지의 $from_id, $to_id에 인덱스가 없어, 매 홉마다 풀 스캔.
해결: 7.1의 모든 엣지 테이블에 (to_id) 인덱스를 만들고, 통계를 최신 상태로 유지.
9.6 진단용 SQL 모음
-- (1) 모든 그래프 테이블 목록
SELECT name, is_node, is_edge
FROM sys.tables
WHERE is_node = 1 OR is_edge = 1;
-- (2) 그래프 테이블의 시스템 컬럼 확인
SELECT t.name AS TableName, c.name AS ColumnName, c.graph_type_desc
FROM sys.tables t
JOIN sys.columns c ON t.object_id = c.object_id
WHERE (t.is_node = 1 OR t.is_edge = 1) AND c.graph_type IS NOT NULL
ORDER BY t.name, c.column_id;
-- (3) 엣지 제약 조건 목록
SELECT OBJECT_NAME(parent_object_id) AS EdgeTable, name AS ConstraintName
FROM sys.edge_constraints;
-- (4) 호환성 레벨 확인
SELECT name, compatibility_level
FROM sys.databases
WHERE name = DB_NAME(); Neo4j와 Azure 기반 금융 사기 탐지 실습
1장. 그래프 데이터베이스 이론
1.4 LPG vs RDF — 두 가지 그래프 모델
LPG(Labeled Property Graph) 는 노드와 엣지에 ‘라벨(타입)’을 붙이고 ‘속성(key=value)’을 자유롭게 달 수 있는 모델로, Neo4j가 대표적입니다. RDF(Resource Description Framework) 는 W3C 표준으로 모든 데이터를 ‘주어-서술어-목적어(triple)’로 표현하며, 시맨틱 웹과 지식 그래프 분야에서 강세입니다.
실무에서는 표현력과 학습 곡선의 균형이 좋은 LPG가 더 널리 채택되고 있습니다.
1.5 그래프 DB를 써야 할 ‘세 가지 신호’
모든 데이터를 그래프에 담으려는 것은 망치를 든 사람에게 모든 것이 못으로 보이는 함정입니다. 다음 중 둘 이상이 해당될 때 그래프 DB가 적합합니다.
- 관계의 깊이가 3-hop 이상. SNS의 친구 추천, 사기 탐지의 우회 거래 등.
- 관계 자체가 분석 대상. ‘무엇이 연결되어 있는가’가 ‘무엇이 있는가’보다 중요한 도메인. 지식 그래프, 추천 시스템, 사회망 분석.
- 스키마가 자주 변하거나 다양한 관계 타입이 등장. 새로운 관계 타입을 추가하려고 매번 ALTER TABLE을 하지 않아도 됨.
단순 트랜잭션 처리(OLTP), 회계장부형 데이터, 전통적 보고서 생성, 컬럼 단위 집계 분석 등은 RDB나 데이터 웨어하우스가 훨씬 효율적입니다. 그래프 DB를 강제로 도입하면 오히려 복잡도만 늘어납니다.
1.6 주요 제품 비교
| 제품 | 모델 | 특징 | 운영 형태 |
|---|---|---|---|
| Neo4j | LPG | Cypher 표준, 가장 큰 생태계 | 셀프호스팅 / AuraDB |
| Amazon Neptune | LPG + RDF | AWS 통합, Gremlin/SPARQL 지원 | AWS 매니지드 |
| Azure Cosmos DB (Gremlin API) | LPG | Azure 통합, 글로벌 분산 | Azure 매니지드 |
| TigerGraph | LPG | 분산 처리 강점, GSQL | 엔터프라이즈 |
| ArangoDB | 다중모델 | 그래프 + 문서 + KV 동시 지원 | 오픈소스 |
2장. Neo4j 핵심 개념
2.1 Neo4j 아키텍처 한눈에
Neo4j는 JVM 위에서 동작하는 단일 프로세스 데이터베이스입니다. 클라이언트는 두 가지 프로토콜로 접속합니다. HTTP(7474)는 웹 브라우저 기반 Neo4j Browser용이고, Bolt(7687)은 애플리케이션 드라이버용 바이너리 프로토콜입니다.
스토리지는 ‘기록 파일(record store)’ 구조로, 각 노드와 관계는 고정 크기 레코드로 저장되어 ID 기반 직접 접근(O(1))이 가능합니다. 이것이 N-hop 트래버설이 빠른 핵심 비결입니다 — JOIN 비용 없이 인접 관계의 메모리 주소를 바로 따라갑니다(‘index-free adjacency’).
2.2 LPG 데이터 모델
| 구성요소 | 설명 | 예시 |
|----------|------|------|
| Node | 개체, 라벨로 타입 구분 | (:Account) |
| Relationship | 노드 사이의 방향성 있는 관계 | [:TRANSFER] |
| Property | 노드/관계에 붙는 key=value 데이터 | {amount: 89500000} |
| Label | 노드의 분류 태그 (다중 부착 가능) | :Account:HighRisk |2.3 Cypher 쿼리 언어
Cypher는 Neo4j가 만든 그래프 질의 언어로, 2018년 ISO/IEC GQL 표준의 기반이 되었습니다. 핵심 아이디어는 ‘ASCII 아트로 패턴을 그린다’ 입니다.
// '계좌 A가 계좌 B에게 송금했다'를 그림으로
MATCH (a:Account)-[:TRANSFER]->(b:Account)
RETURN a, b
LIMIT 5;| 절 | 역할 | SQL 대응 |
|---|---|---|
| MATCH | 패턴 매칭 (데이터 찾기) | FROM + JOIN + WHERE |
| WHERE | 조건 필터 | WHERE |
| RETURN | 결과 반환 | SELECT |
| CREATE | 노드/관계 생성 | INSERT |
| MERGE | 있으면 매칭, 없으면 생성 | UPSERT |
| WITH | 중간 결과 파이프라인 | 서브쿼리 + AS |
2.4 인덱스와 제약조건
인덱스 없는 그래프 DB는 인덱스 없는 RDB보다도 더 빨리 느려집니다. 첫 노드를 어떻게 ‘찾을 것인가(seek)’가 트래버설의 시작점이기 때문입니다. Neo4j 5.x에서는 다음 두 가지를 거의 항상 만들어 둡니다.
// 고유성 제약 (자동으로 인덱스 생성됨)
CREATE CONSTRAINT account_id IF NOT EXISTS
FOR (a:Account) REQUIRE a.accountId IS UNIQUE;
// 일반 인덱스 (자주 조회하는 속성)
CREATE INDEX account_country IF NOT EXISTS
FOR (a:Account) ON (a.country);2.5 GDS — Graph Data Science 라이브러리
Neo4j의 진가는 단순 패턴 매칭을 넘어 그래프 알고리즘까지 한 자리에서 실행할 수 있다는 점입니다. GDS 라이브러리는 다음과 같은 알고리즘을 한 줄로 호출할 수 있게 해 줍니다.
| 분류 | 알고리즘 | 활용 예 |
|---|---|---|
| 중심성 | PageRank, Betweenness | 허브 계좌 탐지, 영향력 분석 |
| 커뮤니티 | Louvain, Label Propagation, WCC | 공모 집단, 클러스터링 |
| 경로 | Shortest Path, A* | 최단 자금 흐름 |
| 유사도 | Node Similarity, Jaccard | 추천 시스템 |
| 임베딩 | FastRP, GraphSAGE, Node2Vec | ML 피처 생성 |
📌 GDS의 동작 원리
GDS는 디스크의 그래프를 그대로 쓰지 않고, 분석 대상 부분을 ‘메모리에 투영(project)’한 뒤 알고리즘을 돌립니다. 큰 그래프에서도 빠른 이유이자, 분석이 끝나면 명시적으로 drop하지 않으면 메모리에 남는 이유이기도 합니다.
3장. Azure 환경 구축
NSG로 본인 IP만 허용 → 7474, 7687 포트 한정 개방

이후 vm 내에서 neo4j 설치
- APT 업데이트 + Java 21 설치 — Neo4j 5.x는 OpenJDK 21을 요구합니다.
- Neo4j 공식 GPG 키 + APT 저장소 등록 — debian.neo4j.com을 신뢰 저장소로 추가.
- apt install neo4j — 5.26.x 안정 버전 설치.
- 외부 접속 허용 — 기본은 127.0.0.1만 listen하므로 0.0.0.0으로 변경. 보안은 NSG가 담당.
- 서비스 시작 + 검증 — systemctl로 부팅 시 자동 시작 등록.
💡 메모리 튜닝의 황금률
Neo4j 성능의 80%는 메모리 설정이 좌우합니다. 일반적으로 'heap size 2~4GB' + '나머지 메모리는 page cache'에 할당합니다. 본 실습은 8GB VM 기준 heap 2GB + page cache 1GB로 설정합니다
4장. OpenPay 시나리오
4.1 도메인 모델링
| 구성 | 분류 | 노드/관계 |
|---|---|---|
| 계좌 | 노드 | (:Account {accountId, name, country, createdAt}) |
| 디바이스 | 노드 | (:Device {deviceId, type, fingerprint}) |
| IP 주소 | 노드 | (:IPAddress {ipId, address, country, isProxy}) |
| 계좌가 디바이스를 소유 | 관계 | (:Account)-[:OWNS]->(:Device) |
| 계좌가 IP에서 접속 | 관계 | (:Account)-[:USED]->(:IPAddress) |
| 계좌가 계좌에 송금 | 관계 | (:Account)-[:TRANSFER {amount, timestamp, channel}]->(:Account) |
💡 모델링 원칙
‘속성으로 표현할 수 있는 것은 노드로 만들지 마라.’ 처음 입문하면 거래 채널(MOBILE/WEB/ATM)도 노드로 만들고 싶어지지만, 이는 트래버설을 무겁게 만들 뿐입니다. 채널은 TRANSFER 관계의 속성으로 충분합니다. 반면 ‘디바이스’는 여러 계좌가 ‘공유’할 가능성이 핵심이므로 반드시 노드여야 합니다.
4.2 데이터 적재
부속 코드 02-data-generation/generate_data.py는 결정론적 시드(SEED=20260506)로 다음 데이터를 생성
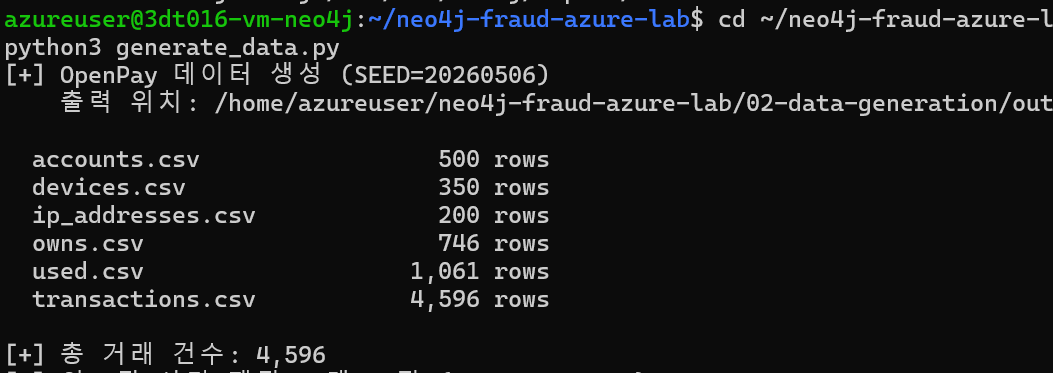
// CSV 파일을 한 줄씩 읽어 노드 생성
LOAD CSV WITH HEADERS FROM 'file:///accounts.csv' AS row
CREATE (a:Account {
accountId: row.accountId,
name: row.name,
country: row.country,
createdAt: datetime(row.createdAt)
});
// 관계는 양 끝 노드를 MATCH로 찾고 CREATE
LOAD CSV WITH HEADERS FROM 'file:///transactions.csv' AS row
CALL {
WITH row
MATCH (src:Account {accountId: row.fromAccount})
MATCH (dst:Account {accountId: row.toAccount})
CREATE (src)-[t:TRANSFER {
txId: row.txId,
amount: toFloat(row.amount),
timestamp: datetime(row.timestamp),
channel: row.channel
}]->(dst)
} IN TRANSACTIONS OF 1000 ROWS;
⚠ Neo4j 5.x의 변화
Neo4j 4.x에서 쓰던 'USING PERIODIC COMMIT'은 5.x에서 deprecated되었습니다. 대신 'CALL { ... } IN TRANSACTIONS OF N ROWS' 패턴을 사용해야 큰 CSV도 메모리 부족 없이 적재됩니다.
MATCH (a:Account) RETURN 'Account' AS label, count(a) AS cnt
UNION ALL
MATCH ()-[r:TRANSFER]->() RETURN 'TRANSFER' AS label, count(r) AS cnt;
5장. Cypher 사기 탐지 실습
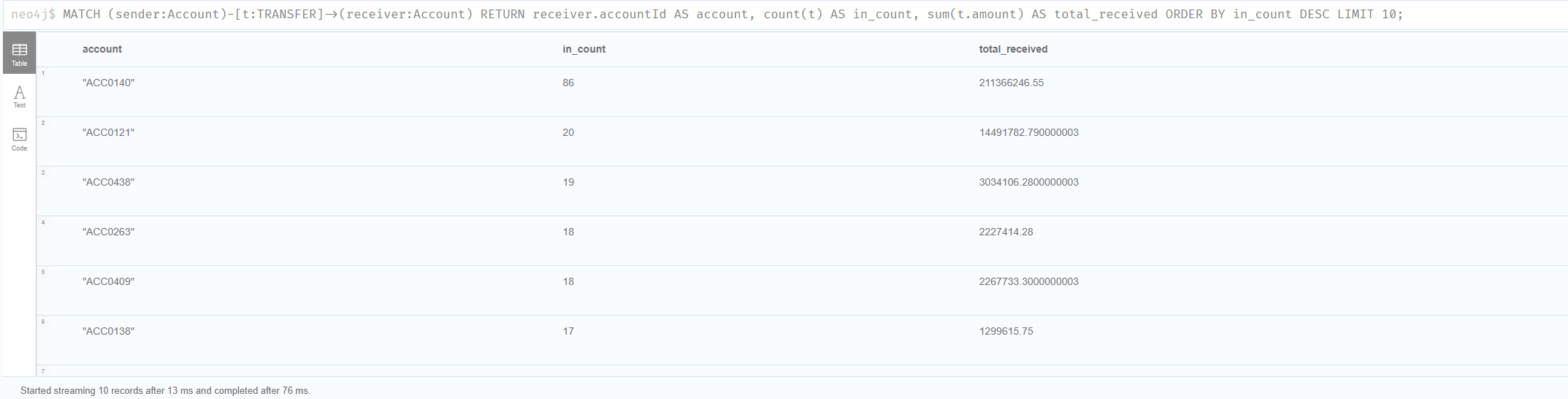
5.1 [ORG-5] 허브 계좌 — 단순 집계로 시작
가장 쉬운 패턴은 ‘비정상적으로 많이 받는 계좌’입니다. RDB의 GROUP BY와 본질적으로 같습니다.
MATCH (sender:Account)-[t:TRANSFER]->(receiver:Account)
RETURN receiver.accountId AS account,
count(t) AS in_count,
sum(t.amount) AS total_received
ORDER BY in_count DESC
LIMIT 10;
5.2 [ORG-3] SMURFING — WHERE 조건으로 패턴 좁히기
‘100만원 미만 거래를 같은 수신자에게 10회 이상’ — CTR(고액현금거래보고) 기준선을 회피하려는 분할 송금 패턴입니다. WHERE로 금액 임계값을 걸고 count()로 횟수를 셉니다.
MATCH (s:Account)-[t:TRANSFER]->(r:Account)
WHERE t.amount < 1000000
WITH s, r, count(t) AS n_tx, sum(t.amount) AS total
WHERE n_tx >= 10
RETURN s.accountId AS sender,
r.accountId AS receiver,
n_tx AS tx_count,
round(total) AS total_amount
ORDER BY n_tx DESC;

5.3 [ORG-2] 디바이스 공모 — 양방향 패턴
‘한 디바이스를 여러 계좌가 공유한다’는 SQL로 표현하면 GROUP BY device + HAVING count(*) >= N입니다. Cypher에서는 패턴이 거의 그림 그대로 — (a)-[:OWNS]->(d)<-[:OWNS]-(b) 가 ‘서로 다른 두 계좌가 같은 디바이스를 가리킨다’는 뜻입니다.
MATCH (a:Account)-[:OWNS]->(d:Device)
WITH d, collect(DISTINCT a.accountId) AS accounts
WHERE size(accounts) >= 8
RETURN d.deviceId AS device,
size(accounts) AS n_accounts,
accounts
ORDER BY n_accounts DESC;

💡 노이즈는 학습 자료다
결과에 의도 외 계좌가 섞여 있는 것은 버그가 아닙니다. 현실 데이터에는 ‘우연히’ 같은 디바이스를 쓴 가족, 한 디바이스를 두 명이 공유하는 부부 등이 늘 섞여 있습니다. 이런 노이즈와 진짜 사기를 구분하는 능력 자체가 분석가의 몫입니다.
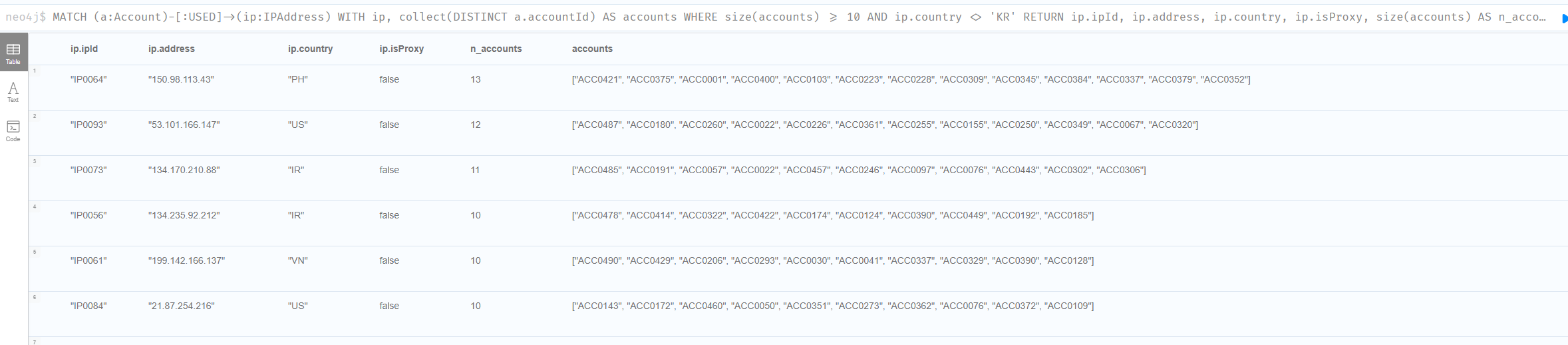
5.4 [ORG-4] 해외 IP 공모 — 다중 조건 결합
디바이스 공모와 같은 패턴이지만 IP가 대상이고, 추가로 ‘국가가 한국이 아님’이라는 조건이 붙습니다.
MATCH (a:Account)-[:USED]->(ip:IPAddress)
WITH ip, collect(DISTINCT a.accountId) AS accounts
WHERE size(accounts) >= 10
AND ip.country <> 'KR'
RETURN ip.ipId, ip.address, ip.country, ip.isProxy,
size(accounts) AS n_accounts, accounts
ORDER BY n_accounts DESC;
5.5 [ORG-1] 자금세탁 순환 — 그래프 DB의 강점
여기까지의 패턴은 RDB도 어떻게든 풀 수 있습니다. 하지만 ‘N개 계좌를 거쳐 자금이 출발지로 돌아오는 순환’은 RDB로는 사실상 불가능합니다. 자기 조인 4번을 짜야 하고, 각 단계마다 시간 순서까지 비교해야 하기 때문입니다.
Cypher에서는 단 한 줄. 시작 노드와 끝 노드를 같은 변수 a로 묶기만 하면 됩니다.
MATCH path = (a:Account)-[t1:TRANSFER]->(b:Account)
-[t2:TRANSFER]->(c:Account)
-[t3:TRANSFER]->(d:Account)
-[t4:TRANSFER]->(a)
WHERE a <> b AND b <> c AND c <> d AND d <> a
AND t1.timestamp < t2.timestamp
AND t2.timestamp < t3.timestamp
AND t3.timestamp < t4.timestamp
AND t1.amount > 10000000
RETURN a.accountId, b.accountId, c.accountId, d.accountId,
round(t1.amount) AS amt1,
round(t4.amount) AS amt4,
duration.between(t1.timestamp, t4.timestamp).hours AS hours;
의심도 점수 매기기
탐지를 넘어 우선순위를 매기는 것이 분석가의 다음 일입니다. 다음 두 신호가 강할수록 의심도가 높습니다.
(1) 거래 간격이 짧을수록 — 자동화된 자금세탁일 가능성, (2) 금액이 비슷할수록 — 수수료 정도만 빠지는 패턴.
6장. GDS 알고리즘 응용
gds 설치
cd /var/lib/neo4j/plugins/
sudo wget https://github.com/neo4j/graph-data-science/releases/download/2.13.2/neo4j-graph-data-science-2.13.2.jar -O neo4j-graph-data-science.jar
sudo systemctl restart neo4j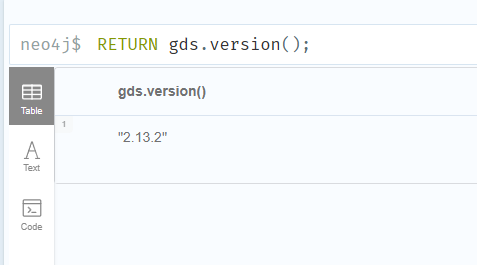
6.1 그래프 프로젝션 — GDS의 첫 단계
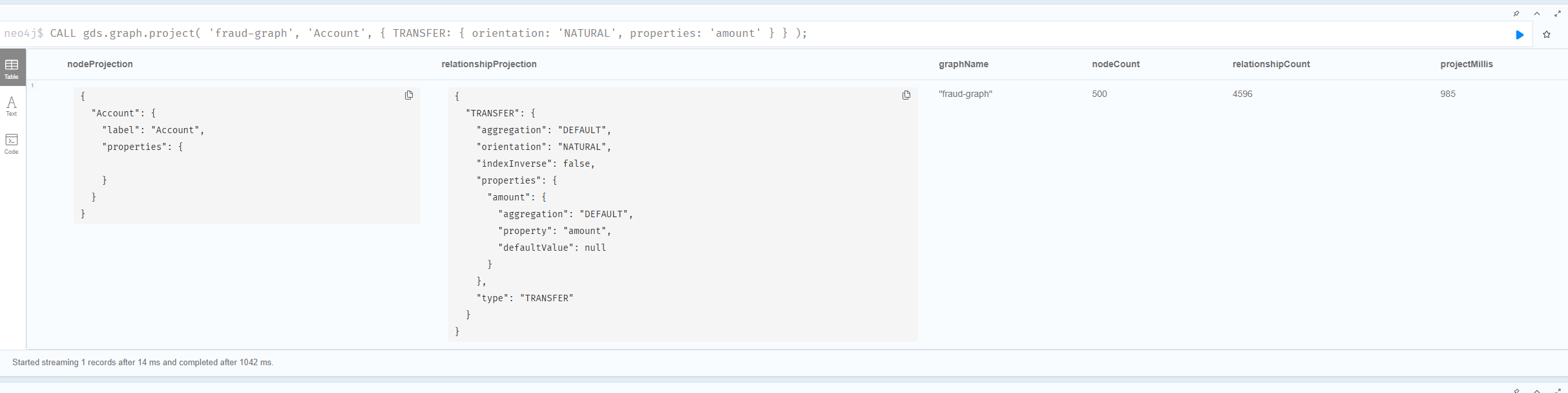
GDS는 디스크 그래프가 아닌 ‘메모리 투영본’에서 알고리즘을 돌립니다. 분석할 부분만 골라 메모리에 올리는 작업이 프로젝션입니다.
CALL gds.graph.project(
'fraud-graph',
'Account',
{
TRANSFER: {
orientation: 'NATURAL',
properties: 'amount'
}
}
);
6.2 PageRank — 허브 식별의 정교한 버전
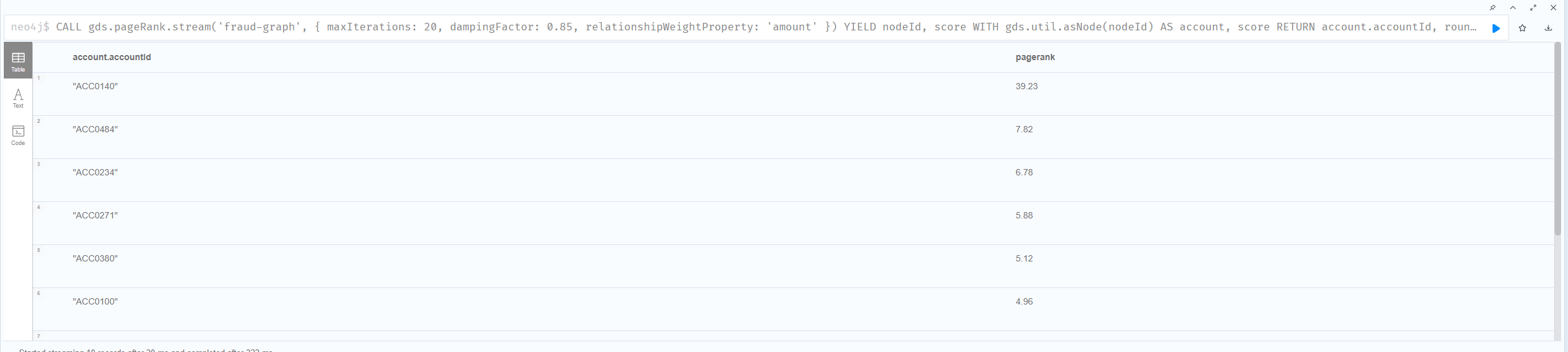
PageRank는 본래 1998년 구글 검색이 등장하면서 ‘웹페이지 중요도’를 매기기 위해 만들어졌습니다. 핵심 직관은 ‘중요한 페이지로부터 링크받은 페이지는 중요하다’ 입니다. 이 직관을 거래 그래프에 적용하면, 단순 ‘수신 건수’를 넘어 ‘중요한 계좌로부터 송금받은 계좌’가 더 높은 점수를 받습니다.
CALL gds.pageRank.stream('fraud-graph', {
maxIterations: 20,
dampingFactor: 0.85,
relationshipWeightProperty: 'amount'
})
YIELD nodeId, score
WITH gds.util.asNode(nodeId) AS account, score
RETURN account.accountId, round(score * 100) / 100 AS pagerank
ORDER BY pagerank DESC LIMIT 10;
6.3 Weakly Connected Components — 공모 집단
WCC는 ‘방향 무시하고 한 덩어리로 연결된 노드들’을 찾는 알고리즘입니다. 디바이스/IP 공유 그래프에서 연결된 컴포넌트는 곧 ‘같은 자원을 통해 연결된 계좌 집단’ — 즉 잠재적 공모 그룹입니다.
CALL gds.graph.project.cypher(
'shared-resource-graph',
'MATCH (a:Account) RETURN id(a) AS id',
'
MATCH (a1:Account)-[:OWNS]->(:Device)<-[:OWNS]-(a2:Account)
WHERE id(a1) < id(a2)
RETURN id(a1) AS source, id(a2) AS target
UNION
MATCH (a1:Account)-[:USED]->(:IPAddress)<-[:USED]-(a2:Account)
WHERE id(a1) < id(a2)
RETURN id(a1) AS source, id(a2) AS target
'
);
CALL gds.wcc.stream('shared-resource-graph')
YIELD nodeId, componentId
WITH componentId, collect(gds.util.asNode(nodeId).accountId) AS members
WHERE size(members) >= 6
RETURN componentId, size(members) AS size, members
ORDER BY size DESC;

6.4 Louvain — 거래 흐름 기반 커뮤니티
Louvain은 모듈러리티 최적화 기반 커뮤니티 탐지 알고리즘입니다. ‘안에서는 빽빽하게 연결되어 있고, 밖으로는 듬성듬성 연결된’ 노드 집단을 찾습니다. 거래 흐름에 적용하면 ‘끼리끼리 거래하는 그룹’이 드러납니다.
CALL gds.louvain.stream('fraud-graph', {
relationshipWeightProperty: 'amount'
})
YIELD nodeId, communityId
WITH communityId, collect(gds.util.asNode(nodeId).accountId) AS members
WHERE size(members) >= 3 AND size(members) <=30
RETURN communityId, size(members) AS size, members[0..10] AS sample
ORDER BY size DESC LIMIT 10;

📌 알고리즘의 한계 이해하기
Louvain은 거래 흐름을 보지 디바이스/IP는 보지 않습니다. 즉 ORG-2/ORG-4(자원 공모)는 Louvain만으로는 잡히지 않습니다.
6.5 메모리 정리
CALL gds.graph.drop('fraud-graph') YIELD graphName RETURN graphName;
CALL gds.graph.drop('shared-resource-graph') YIELD graphName RETURN graphName;
