
두 번째 TIL
어제 TIL을 작성했는데 깔끔하게 쓰고 가독성 있게 쓰려고 노력했다. 다른 사람이 봤을 때 내 의도와 맞게 보이는지는 잘 모르겠지만.. 오늘도 열심히 기록해보려고 한다. 🔥🔥
파이썬
파이썬은 인터프리터 언어처럼 동작하나 사용자가 모르는 사이에 스스로 파이썬 소스 코드를 컴파일하여 바이트 코드(Byte code)를 만들어 냄으로써 다음에 수행할 때에는 빠른 속도를 보여 준다.
파이썬에서는 들여쓰기를 사용해서 블록을 구분하는 독특한 문법을 채용하고 있다. 이 문법은 파이썬에 익숙한 사용자나 기존 프로그래밍 언어에서 들여쓰기의 중요성을 높이 평가하는 사용자에게는 잘 받아들여지고 있지만, 다른 언어의 사용자에게서는 프로그래머의 코딩 스타일을 제한한다는 비판도 많다. 이 밖에도 실행 시간에서뿐 아니라 네이티브 이진 파일을 만들어 주는 C/C++ 등의 언어에 비해 수행 속도가 느리다는 단점이 있다. 그러나 사업 분야 등 일반적인 컴퓨터 응용 환경에서는 속도가 그리 중요하지 않고, 빠른 속도를 요하는 프로그램의 경우에도 프로토타이핑한 뒤 빠른 속도가 필요한 부분만 골라서 C 언어 등으로 모듈화할 수 있다(ctypes, SWIG, SIP 등의 래퍼 생성 프로그램들이 많이 있다). 또한 Pyrex, Psyco, NumPy 등을 이용하면 수치를 빠르게 연산할 수 있기 때문에 과학, 공학 분야에서도 많이 이용되고 있다. 점차적인 중요성의 강조로 대한민국에서도 점차 그 활용도가 커지고 있다.
파이썬 requests 라이브러리
파이썬에는 HTTP 요청을 처리할 수 있는 urllib라는 내장 라이브러리가 기본으로 있고 설치해서 사용할 수 있는 requests 라이브러리가 있다.
설치
pip install requestsimport
import requestshttp 요청
r = requests.get('https://')
r = requests.post('https://')
r = requests.put('https://')
r = requests.patch('https://')
r = requests.delete('https://')이외에도 head와 options 메서드가 있다.
r = requests.head('https://')
r = requests.options('https://')HEAD 메서드는 특정 리소스를 GET 메서드로 요청했을 때 돌아올 헤더를 요청한다.
OPTIONS 메서드는 목표 리소스와의 통신 옵션을 설명하기 위해 사용된다. 클라이언트는 OPTIONS 메소드의 URL을 특정지을 수 있다.
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
json = r.json()
print(json)따라서 requests 라이브러리를 사용해 json 형태의 공공데이터를 json 형태로 가져올 수도 있다.
크롤링? 스크래핑?
인터넷에서 데이터를 검색해 필요한 정보를 가져오려면 어떻게 해야할까?
웹 크롤링(Crawling)은 웹 크롤러(조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램)가 일정 규칙으로 웹페이지를 브라우징 하는 것이고, 웹 스크래핑(Scraping)은 웹 사이트 상에서 원하는 데이터를 추출하는 기술이라고 한다. 둘의 차이가 나뉘긴 하지만 보통 크롤링이라고 많이 부르기 때문에 크롤링이라는 용어로 사용하려고 한다. 자세한 건 이곳에서 확인할 수 있다.
BeautifulSoup
BeautifulSoup은 HTML과 XML에서 데이터를 쉽게 처리하게 해주는 라이브러리다.
bs4 라이브러리를 설치한다.
pip install bs4import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title)
print(title.text)
print(title.attrs)
print(title['href'])
네이버 영화 랭킹 사이트에서 1등인 영화를 가져오는 코드다.
print(title)
print(title.text)
print(title.attrs)
print(title['href'])⬇️
< a href="/movie/bi/mi/basic.naver?code=171539" title="그린 북">그린 북< /a>
그린 북
{'href': '/movie/bi/mi/basic.naver?code=171539', 'title': '그린 북'}
/movie/bi/mi/basic.naver?code=171539meta 태그 크롤링
카카오톡에서 링크를 전송했을 때 뜨는 화면을 보면 썸네일 이미지와 제목, 내용이 뜬다. meta 태그는 이를 가능하게 해준다. meta 태그에 등록만 해놓으면 자동으로 불러와질 수 있게 한다는 것이다. meta 태그는 웹 사이트의 속성을 설명해주는 태그들이다.
여러 가지 meta 태그들이 있지만 og:image, og:title, og:description을 크롤링하려고 한다.
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')위에서 크롤링 할 때는 셀렉터에 >로 태그 및 속성을 이어서 사용했다. meta 태그는 이렇게 하면 원하지 않는 내용이 크롤링 되거나 아무것도 크롤링 되지 않을 수 있다. 따라서 다른 방법으로 크롤링 하는 것이 좋다.
title = soup.select_one('meta[property="og:title"]')['content']
ogimage = soup.select_one('meta[property="og:image"]')['content']
ogdescription = soup.select_one('meta[property="og:description"]')['content']이런 방법으로 크롤링을 하면 정상적으로 동작한다!
파이썬 pymongo 라이브러리
mongoDB를 파이썬에서 쉽게 사용할 수 있게 한 pymongo 라이브러리가 있다.
Oracle이나 MySQL로 RDBMS를 사용해본 적은 있지만 NoSQL은 사용해본 경험이 없었다. 그래서 이번 기회에 NoSQL을 직접 사용해볼 수 있어서 좋았다.
우선 라이브러리를 설치해야 한다. 설치하는 방법은 위 라이브러리들과 같다.
pip install pymongofrom pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta우선 mongoDB와 python을 연결시킨다. 위 코드는 dbsparta라는 DB를 생성한다.
Collection은 Database의 하위에 속하는 개념이다.
Field는 모여서 하나의 컬렉션을 구성하게 된다.
Document는 위의 항목으로 구성된 데이터베이스의 실제 데이터다.
mongoDB는 기본적으로 CRUD 연산이 가능하다.
삽입하는 insert, 조회하는 find, 수정하는 update, 삭제하는 delete
insert
doc = {'name':'kim','age':25}
db.users.insert_one(doc)DB의 users Collection에 key value 형식으로 name 필드에 'kim', age 필드에 25라는 데이터가 삽입된다.
find
user = db.users.find_one({'name':'kim'})name 필드 값이 'kim'인 하나의 데이터를 조회하는데 가장 첫 번째 데이터가 조회된다.
same_ages = list(db.users.find({'age':21},{'_id':False}))find_one 대신 find를 사용하면 해당되는 데이터들을 모두 조회한다.
update
db.users.update_one({'name':'kim'},{'$set':{'age':20}})name 필드 값이 'kim'인 데이터의 age 필드 값을 20으로 변경하는데 가장 첫 번째 데이터가 변경된다.
update_one 대신 update를 사용하면 해당 조건의 필드들의 데이터를 전부 변경한다.
delete
db.users.delete_one({'name':'kim'})name 필드 값이 'kim'인 데이터를 삭제한다.
delete도 마찬가지로 해당 조건의 필드들의 데이터를 전부 삭제한다.
지니 실시간 차트 크롤링 후 MongoDB에 넣기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.main-wrap.clearfix > div.chart > div > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text
title = tr.select_one('td.info > a.title.ellipsis').text
singer = tr.select_one('td.info > a.artist.ellipsis').text
doc = {
'rank': rank,
'title': title,
'singer': singer
}
db.realTimeChart.insert_one(doc)
print(rank, title, singer)지니 홈페이지에서 실시간 차트 10위까지 크롤링하는 코드다.
trs = soup.select('#body-content > div.main-wrap.clearfix > div.chart > div > div > table > tbody > tr')순위들이 공통적으로 포함되어 있는 selecor들을 trs 변수에 담았고 for 반복을 통해 rank, title, singer 정보를 각 변수에 담았다. 그리고 realTimeChart 컬렉션에 위 정보들을 insert 했다.
mongoDB 결과
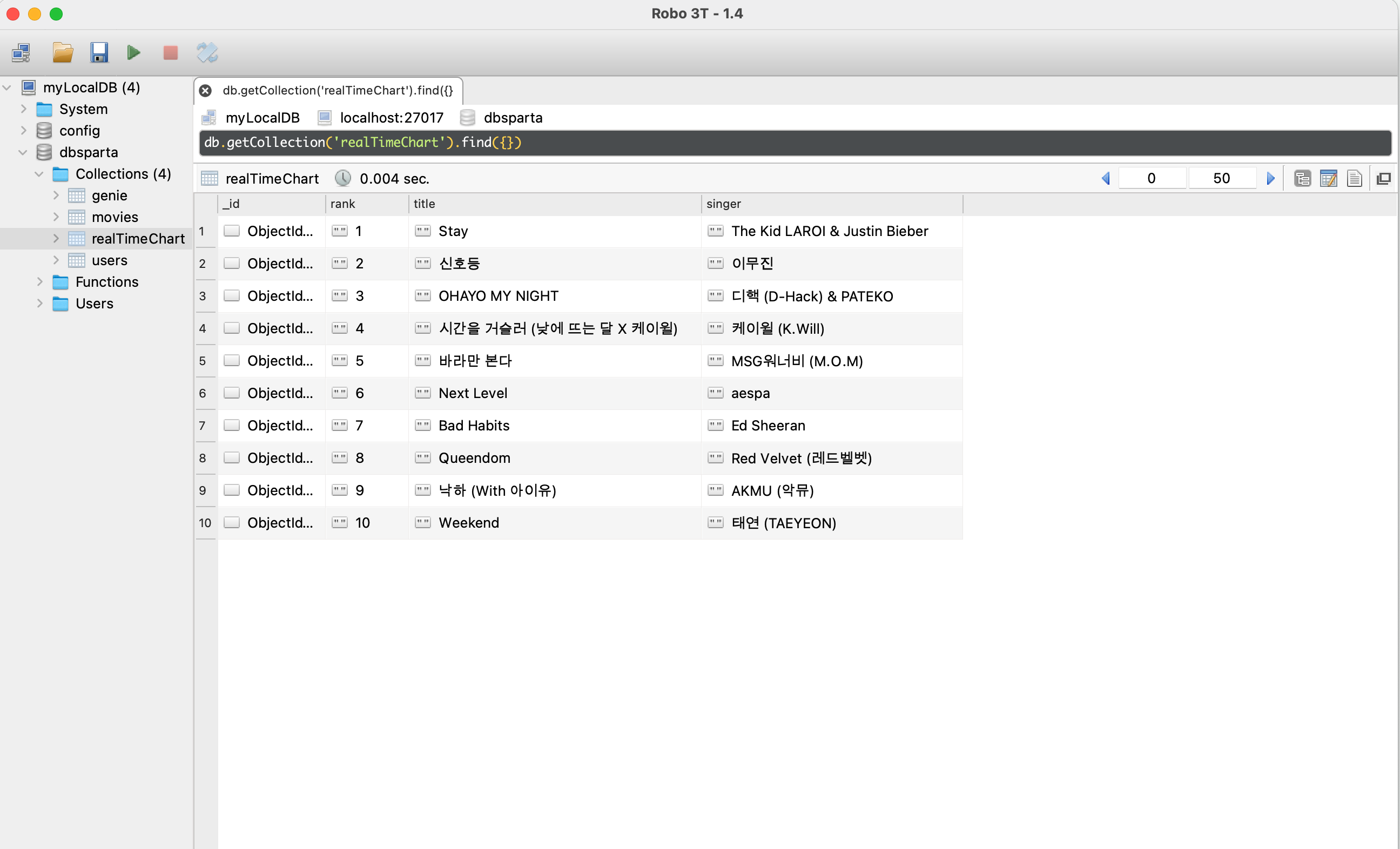
정상적으로 데이터들이 담긴 것을 확인할 수 있다!!
Flask
웹 프레임워크로 python을 사용하는 Django와 java를 사용하는 Spring을 사용해본 경험이 있다. Django를 사용했을 때 Flask라는 프레임워크가 있다는 것은 알았지만 사용해본 경험이 없었다. 하지만! 이번에 Flask를 사용해볼 수 있어서 엄청 좋았다😊
우선 Flask를 사용해보기 전에 Flask가 무엇인지 알 필요가 있다.
Django vs Flask
Django

Django는 복잡한 python 기반 웹 앱 구축에 사용되었기 때문에 확장성을 제공하는 강력한 아키텍처를 가지고 있다. MVT(Model-View-Template) 구조로 풀스택 개발을 위한 완벽한 프레임워크다. 따라서 웹 개발의 프런트 엔드 및 백엔드 측면을 파악하고 파이썬을 서버측 언어로 사용할 수 있는 것을 선호하면 Django가 좋을 것이다.
ORM(Object-Relational-Mapper)을 내장하여 다양한 데이터베이스에 유연하게 접근할 수 있다. 기본적으로 데이터베이스에서 개체를 삽입하거나 호출하기 위해 많은 쿼리를 작성할 필요가 없다.
Django에서 Model을 통해 테이블을 생성할 때 개별 개체 내에서 데이터베이스에 있는 테이블의 속성만 정의하면 된다. 그 후에 테이블을 만드는 원시 쿼리는 테이블을 데이터베이스로 이동한 후 마이그레이션 파일에 자동으로 커밋된다.
Flask

Flask는 마이크로 프레임워크인 만큼 Django와 비교했을 때 최소한의 구조를 제공한다.
Django의 MVT 구조와 달리 Flask는 일반적인 MVC(Model-View-Controller) 구조를 따른다.
MVT의 View, MVC Controller는 같은 의미라고 생각하면 된다. 즉, (MVT)Model = (MVC)Model, (MVT)View = (MVC)Controller, (MVT)Template = (MVC)View이다.
Django와 다르게 가상환경에 Flask를 설치하고 프로젝트를 열면 빈 파일 디렉토리가 나타나는데 이 말은 수동으로 파일을 만들어야 한다는 뜻이다. 따라서 Django의 복잡한 구조를 피하려면 Flask 사용을 고려해보는 것도 좋은 선택이다. 하지만 Flask는 마이크로 프레임워크이기 때문에 장고만큼 많은 내장 패키지를 제공하지 않는다. ORM 기능을 사용하기 위해서는 SQLAlchemy라는 타사 데이터베이스 주입 패키지가 필요하다.
그리고 API 빌드를 위한 REST 확장 기능도 있지만 Django가 제공하는 모든 기능을 갖춘 내장 API 구조는 제공하지 않는다. 이런 점을 고려해보았을 때 초보자에게 Flask가 더 사용하기 쉬울 수 있다. Django와는 다르게 파일 연결 방식에 대한 제어권을 잃지 않고 의도대로 빌드하는 데 초점을 맞췄다.
참고: 파이썬 웹 프레임워크 종류
파이썬에는 많은 웹 프레임워크가 있다.
Django
Flask
Tornado
FastAPI
AIOHTTP
Bottle
Pyramid
WebPy
Sanic
Web2py
CherryPy
Falson
Gnok
Zope
TurboGrears
Guart
Masonite
등등...
참고
리뷰어 I love tech 별별. “파이썬 웹 프레임워크 비교하기, 장고 vs 플라스크.” IT, 테크 분석가, TISTORY, 11 Mar. 2021, https://tech95.kr/164.
“Python 웹프레임워크 끝판왕 가리기 (Django, Flask, Fastapi, Sanic)” 딩그르르-Dingrr.com, https://dingrr.com/blog/post/python-%EC%9B%B9%ED%94%84%EB%A0%88%EC%9E%84%EC%9B%8C%ED%81%AC-%EB%81%9D%ED%8C%90%EC%99%95-%EA%B0%80%EB%A6%AC%EA%B8%B0-django-flask-fastapi-sanic.
