
8주차
8주차는 지난 주에 시작한 "케창딥"을 계속해서 공부하는 주차였다.
하루에 한 챕터씩 공부를 하여 다음 날 퀘스트를 봐야한다.
한 챕터에 해당하는 양이 은근 많고, 챕터가 진행될 수록 내용이 어려워지기 때문에 이해하는 데에 시간이 더더욱 많이 걸렸다...
케라스 창시자에게 배우는 딥러닝
chapter 4 ~ 8
chapter 4. 신경망 시작하기: 분류 / 회귀
4장에서는 신경망이 어떻게 구성되는 지에 대해 간단하게
예제를 통해 알아보게 되었다.
이전 "Exploration"노드나, "딥러닝 한 번에 끝내기" 노드에서
한 번씩은 했거나 적어도 데이터 셋은 한 번 이상은 봤다.
IMDB, Reusters, Boston housing dataset을 이용하여
영화 감성 분류(이진 분류), 뉴스 토픽 분류(다중 분류), 주택 가격 예측(회귀) 의 문제를
해결하는 task가 주어진다.
각 문제들은 분류, 회귀 문제에서 아주 클래식하고 기본적인 문제이기 때문에
이를 토대로 딥러닝에 첫 걸음을 내딛는데에 큰 도움이 될 것 같다!
각각에 대해 설명과 코드를 깃허브에 올려뒀다!
케창딥 리뷰 깃허브
chapter 5. 머신 러닝의 기본 요소
5장은 머신 러닝에서 중요한 최적화, 일반화에 대해 다루는 챕터였다.
최적화란 훈련 데이터에서 최고의 성능을 얻기 위해 train되는 과정을 의미한다.
반면 일반화는 훈련된 모델에서 사용되지 않은 즉, 새로운 데이터에 대해서 얼마나 좋은 성능으로 예측하는지를 의미한다.
케창딥의 표현을 빌리자면
"머신 러닝은 최적화와 일반화 사이에서 줄다리기를 하는 것과 같다" 라고 한다.
결국 머신 러닝의 목표는 일반화의 성능을 높이는 것이지만 일반화 성능만 높이는 기법은 없다. 다만, 훈련 데이터에서 학습된 모델으로 새로운 데이터를 맞추는 일을 할 뿐이다. 여기서 과소적합과 과대적합의 개념이 등장한다.
과소적합은 모델이 아직 개선될 여지가 있는 상태에서 학습이 끝난 것을 의미하고, 과대적합은 너무 훈련 데이터에 꼭 맞도록 모델이 학습한 경우를 의미한다. 아래의 그림을 보면 이해하기가 직관적으로 이해할 수 있다.
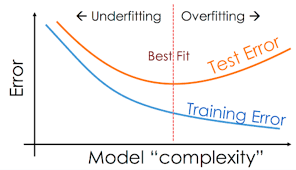
줄다리기라는 표현을 한 것이 여기서 드러난다.
best fit의 부분(sweet spot)을 보면,
training error가 낮아지면서, test error가 높아지기 시작하는 지점임을 알 수 있다.
어떠한 요소가 과대적합을 유발하는 것일까?
1. 잡음 섞인 데이터 - 이상치 다루기
2. 불확실한 특성 - 입력으로 들어오는 특성의 불확실성
ex) 바나나 -> 덜 익은 바나나 / 다 익은 바나나는 무슨 기준으로 나눌까?
3. 드문 특성과 가짜 상관관계 - 드문 특성이 있거나, 가짜 상관관계가 있는 데이터가 입력으로 들어오면 그 특성과 상관관계가 훈련에 크게 기여하게 된다.
이를 해결하고자 특성 선택(feature selection)을 수행한다.
일반화의 본질은 매니폴드 가설에서 시작된다.
매니폴드 가설 공간에서 데이터 보간(interpolation)을 통해
우리가 예측한 값들이 적절히 매핑될 수 있도록 하는 것이다.

그렇다면 딥러닝 모델의 평가는 어떻게 할 수 있을까?
정답은 훈련, 검증, 테스트 세트로 데이터 세트를 분할 하는 것이다.
일반화 성능을 신뢰있게 측정하기 위해 훈련 데이터는 훈련에만 사용하고,
최종적으로는 테스트 데이터로 이를 검증하는 것이다.
검증 세트는 테스트 데이터의 역할을 학습 iter마다
수행할 수 있도록 하는 데이터 세트이다.
하지만 검증 세트를 통해 성능을 파악하고 이를 토대로 모델 튜닝을 하다보면 정보 누설(information leak)의 문제가 발생한다.
정보 누설로 인해 검증 세트에 대해
어느정도 과대적합이 되는 모습을 보일 수 있는 것이다.
이를 해결하고자, 홀드 아웃 검증이 나타났다.
k-fold cross validation이 홀드 아웃 검증이 가장 대표적이다.
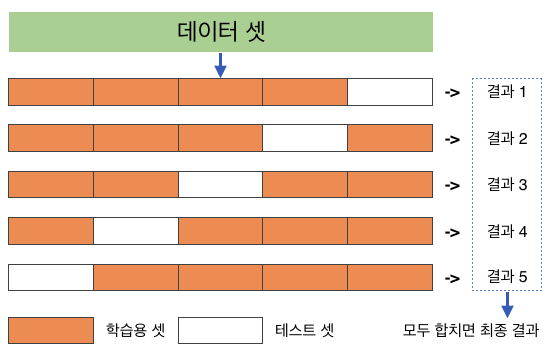
이렇게 최적의 성능을 보이게 하기 위해서 다음과 전반적으로 같은 방법이 필요하다.
-훈련 성능 향상-
1. 파라미터 튜닝
2. 모델 구조에 대한 더 나은 가정
3. 모델 용량 늘리기
-일반화 성능 향상-
1. 데이터 큐레이션
2. 특성 공학
3. 조기종료
4. 모델 규제 : L1, L2 / dropout
chapter 6. 일반적인 머신 러닝 워크플로
머신 러닝 프로젝트를 기획하고 실행할 때, 어떠한 것들을 염두해 두어 중점 사항으로 체크해야 하는 지에 대해 잘 설명해준다. 천천히 읽기만 해도 이해가 되는 부분이 많기 때문에 이를 잘 정리한 블로그를 첨부하고 마무리하겠다!
chapter 6 blog
chapter 7. 케라스 완전 정복
케라스 모델을 만드는 다양한 방법에 대해 공부하는 챕터였다.
1. sequential api
2. functional api
3. subclassing api
이것들은 이론적인 것들 보다는 코드를 직접 보면서 이해하는 것이 중요했다.
이에 대한 코드를 깃허브에 정리했다.
케창딥 리뷰 깃허브
chapter 8. 컴퓨터 비전을 위한 딥러닝
8장에서는 합성곱 신경망으로 컴퓨터 비전(CV) 관련 문제를 설명하고,
그 예시를 보여준다.
합성곱 신경망 즉 convnet에서 합성곱 연산이 갖는 의미가 무엇일까?
간단하게 요약하면 다음과 같을 것이다.
1. 합성곱 연산을 통해 학습된 패턴은 평행 이동 불변성을 가진다.
2. 합성곱 연산 기반의 network는 공간적 계층 구조를 학습할 수 있다.
평행 이동 불변성을 쉽게 설명하면, 어떠한 패턴을 갖는 특징은 다른 위치에서 나타나도 이를 인식할 수 있게하는 성질을 의미한다. Fully connected layer에서는 새로운 위치에서의 패턴은 새로운 패턴으로 인식하기 때문에 평행 이동 불변성이 없다고 할 수 있다.
공간적 계층 구조는 네트워크의 밑단부터 시작해서 깊어질수록 합성곱 신경망이 표현하는 범위가 계층 구조를 갖는 다는 것을 의미한다. 예를 들어 사람의 이미지에서 밑단에서 사람 얼굴의 선, 모양, 질감과 같은 패턴을 학습하면, 더욱 깊어지면서 얼굴의 눈, 코, 입의 패턴을 인식하는 것과 같다.
케창딥에서는 고양이를 예시로 들었다. 아래의 그림을 보면 직관적으로 이해하기 쉽다.
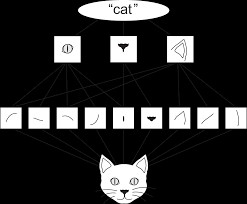
그렇다면 합성곱 연산의 계산 과정은 어떻게 될까?
합성곱 연산의 계산 과정을 이해하기 위해서는 몇가지 요소의 개념을 알 필요가 있다.
- filter(필터)
- feature map(특성 맵)
- padding(패딩)
- stride(스트라이드)
이를 기반으로 합성곱 연산에 대해 설명한 블로그 포스팅을 첨부하겠다!
합성곱 연산
이 개념을 바탕으로 사전 훈련된 모델을 사용하여 얼마나 효율적으로 모델 예측을 수행할 지에 대한 예시가 코드와 함께 설명되어 있다.
이 부분은 개념적인 것도 중요하지만 코드를 보는 것이 이해하기에 훨~씬 용이하다고 판단 되어 깃허브 주소를 올리도록 하겠다!
convnet model training code repo
출처
1. 과대적합, 과소적합 그래프:
https://heytech.tistory.com/125
2. 데이터 보간 예시 그림:
https://velog.io/@xuio/TIL-Data-Manifold-%ED%95%99%EC%8A%B5%EC%9D%B4%EB%9E%80
