간단한 소개
Triton 추론 서버를 설치해주고, 이를 통해 모델의 입출력을 HTTP/gRPC 요청 및 응답으로 처리해준다. 또한, 기존 Triton에 있던 최적화, 모델 앙상블 등의 기능도 얼마든지 쉽게 사용할 수 있다.
대략적인 구조
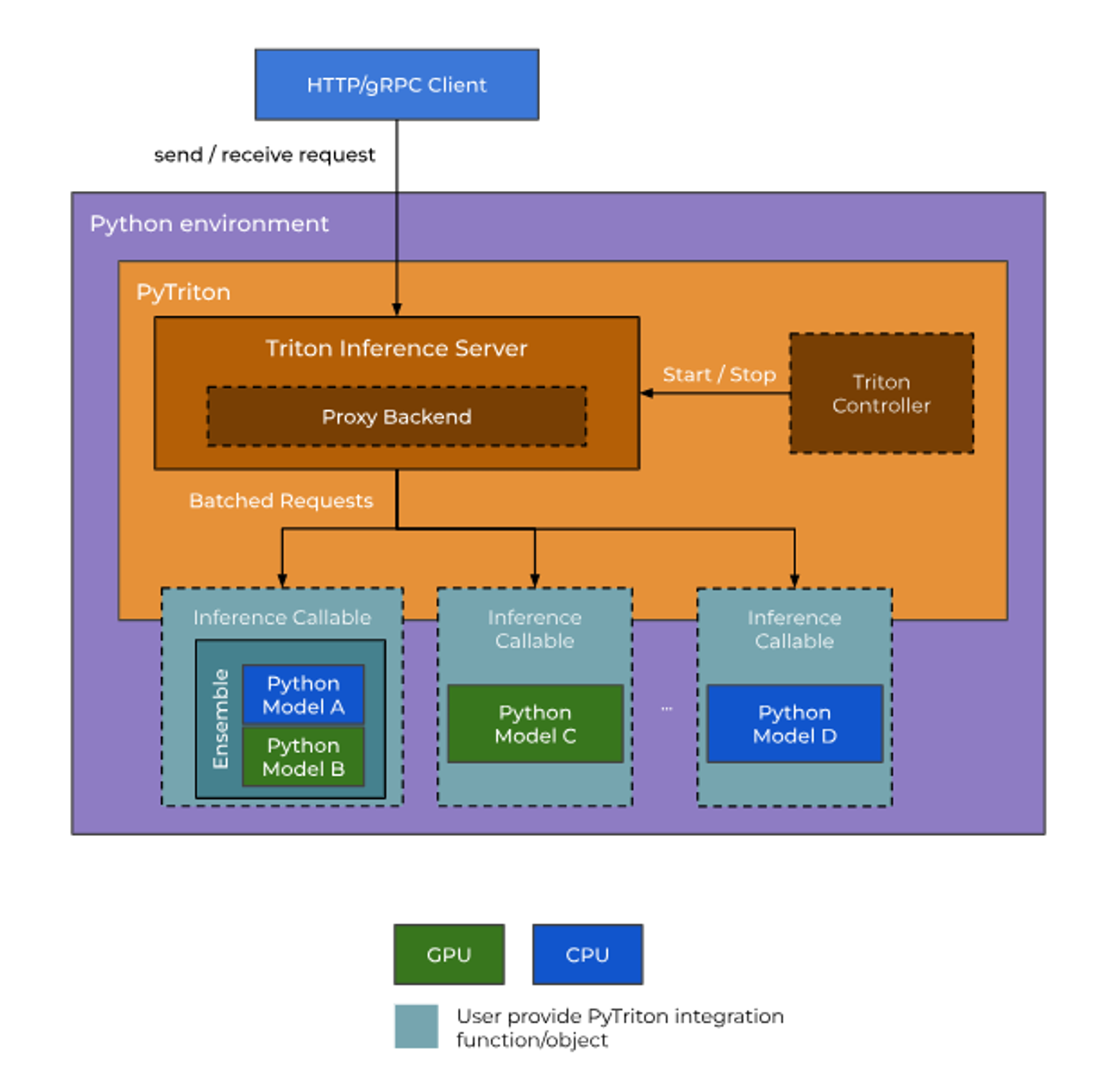
1. Triton 추론 서버
- HTTP/gRPC API를 통해
dynamic batchingorresponse cache사용 가능 Proxy Backend라는 곳에서Inference Callable과 모델의 입출력을 전달하고, 받는다.
2. Python 모델 환경
- 사용할 모델이 잘 정의되어 있어야 한다. 앙상블이면 앙상블로 잘 정의해놓기. ⇒
Inference Callable⇒ 이곳으로 입력 데이터(numpy 형태)를 보냄. - 이 안에 PyTriton을 트로이의 목마🐴마냥 설치해두고, 그 안에 있는
Triton Controller로 Triton 추론 서버와 통신을 할 수 있다.
모델 서빙하기
-
infer_fn()정의하기PyTriton은 HTTP/gRPC 통신을 통해 모델에 입력 텐서를 보내거나 출력 텐서를 받아오는 모델 서빙 기능을 제공한다. 그 기능을 하는 게 이 함수다!!
inference callback function => infer_fn()
infer_fn은 배치단위로 잘린 입력 데이터를 받고, 출력 데이터를 return한다.
import numpy as np from pytriton.decorators import batch @batch def infer_fn(**inputs: np.ndarray): input1, input2 = inputs.values() outputs = model(input1, input2) return [outputs] -
bind()Triton 추론 서버와 infer_fn 연결해주는 역할!!
쿼리를 받아서 냠냠 해치우는 infer_fn
Triton에 의해 어떻게 모델이 수행해야 되는지, 모델이 있는 주소는 어디인지 명시를 해줘야 한다.
⇒
model_name,infer_func,input과 output 형식,config
from pytriton.triton import Triton
from pytriton.model_config import ModelConfig, Tensor
with Triton() as triton:
triton.bind(
model_name="MyModel",
infer_func=infer_fn,
inputs=[
Tensor(dtype=bytes, shape=(1,)), # sample containing single bytes value
Tensor(dtype=bytes, shape=(-1,)), # sample containing vector of bytes
],
outputs=[
Tensor(dtype=np.float32, shape=(-1,)),
],
config=ModelConfig(max_batch_size=16),
) 모델 서빙하는 데 마무리로 triton.serve()를 해줘야 하는데, 이러면 추론 쿼리가 지정된 로컬호스트 포트 주소로 보내지고 infer_fn이 이 쿼리를 받으며 등장하게 된다..
어떻게든 blocking mode에 대해 알아내고야 말겠다!!
Blocking mode
항상 HTTP/gRPC 요청을 기다리고 있는 상태. 이 요청대로 실행하는 게 우선순위기 때문에, 현재 실행되고 있는 게 있다면 이를 멈추고 오로지 기다림. 상태로 머물게 된다.
→ 마치 pure.. server.. 처럼 보이게 한다고..
from pytriton.triton import Triton
with Triton() as triton:
... # Load models here
triton.serve()바인딩 구성
ModelConfig 를 내 맘대로~!! 하고 싶을 때.
ModelConfig에서 바꿀 수 있는 것.
-
DynamicBatcher를 사용하는가?
⇒
batching = True(default) -
DynamicBatcher 클래스의 내부 구성
from typing import Dict, Optional
from pytriton.model_config.common import QueuePolicy
class DynamicBatcher:
max_queue_delay_microseconds: int = 0
preferred_batch_size: Optional[list] = None
preserve_ordering: bool = False
priority_levels: int = 0
default_priority_level: int = 0
default_queue_policy: Optional[QueuePolicy] = None
priority_queue_policy: Optional[Dict[int, QueuePolicy]] = Nonemax_batch_size: 최대 배치 크기
Reference
