🔗paper link : Context-Aware Attentive Knowledge Tracing
💭리뷰 목적 : 2023-2학기 동안 기업현장실습을 교육 기업에서 했었는데, 이때 지식추적 모델 논문 리서치 업무를 맡았었다! AKT는 지식추적 모델 중 Transformer 구조를 활용하는 기본적인 모델이라 꼭 짚고 넘어갈 필요가 있다.
✅본 리뷰는 논문 중 3. AKT Method 부분을 위주로 정리되어 있습니다.
PREVIEW
transformer를 활용하는 만큼 key, value, query 값이 무엇인지에 대한 이해가 우선적으로 필요하다.
key: 지식 개념value: 각 학습자의 지식 수준query: 특정 시점의 문제
ABSTRACT에서 소개하는 핵심적인 기술은 무엇일까?
monotonic attention→ attention weights 계산 방법(지수적 감쇠, 상대적 거리 측정, 문제 간의 비슷함을 이용)rasch model활용을 통한 개념과 문제 raw embedding 계산 → 같은 개념을 가진 문제들 사이의 차이를 포착해 볼 수 있다.
Embedding(Real-valued) 개념 정리
D: (문제→문제 정보), (문제-응답 쌍→ 해당 질문에 학생이 응답함으로써 얻어지는 지식) , 임베딩의 차원(Dimension)을 의미함.Q: 문제 갯수 ⇒ Q개의 문제 embedding vector , 2Q개의 문제-응답 embedding vector- 대부분 교육 환경에서는 지식 개념 수보다 문제 수를 훨씬 많이 가지는 양상이다.
- 그러므로, 현존하는 KT 메소드 대부분은 문제 번호를 개념 번호로 할당하여 파라미터를 줄이려고 한다. (개념 수가 더 적으니까 경우의 수가 줄어들게 됨.) 이로써, 다른 문제라도 같은 개념을 가지는 것들은 하나의 문제로 치환되고, 문제 고유의 특성이 고려되지 못한다.
⇒ 이 논문에서는 이것을 문제점으로 생각!
3. 본격적이고, 대략적인 AKT에 대한 소개
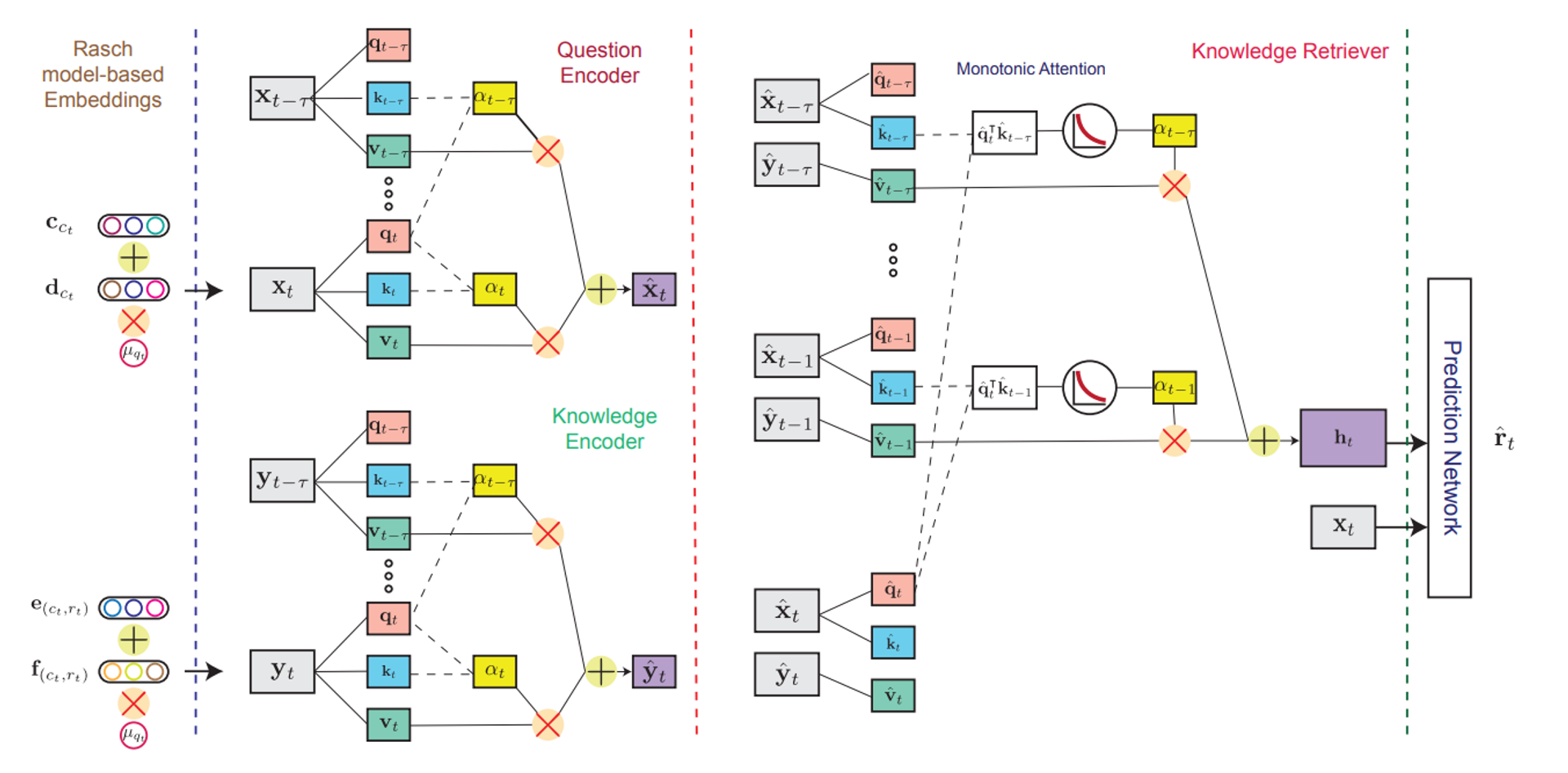
- 4가지 구성요소
- 2개의 self-attentive encoders (문제용, 지식용)
- 1개의 knowledge retriever(지식 검색기)
- 1개의 feed-forward response prediction model (마지막 출력 부분)
- 2개의 self-attentive encoders 질문과 응답 정보를 어떠한 수치 데이터로써 잘 표현할 수 있도록 해줌. 이것을 context-aware하다고 표현함. 물론, 선행 연구들처럼 이렇게 인코딩하지 않고 질문과 응답의 raw embedding을 이용하는 방법도 사용 가능함. 하지만 이렇게 context-aware한 표현으로 만들었을 때, 더 좋은 성능을 보여줌.
-
The question encoder
: 학습자가 이전에 푼 문제들의 시퀀스가 주어졌을 때, 각 문제의 문맥화된 표현을 만들어줌.
-
The knowledge encoder
: 이전 질문들에 응답하며 학습자가 얻은 지식들의 문맥화된 표현을 생성해줌.
-
- The knowledge retriever : attention mechanism을 이용하여 현재 문제와 관련된 이전에 얻었던 지식들을 검색해줌.
- The response prediction model : 검색된 지식을 이용하여 현재 질문에 대한 학습자의 응답을 예측해줌.
3.1 Context-aware Representations and The Knowledge Retriever
- The question encoder
- input : raw question embeddings {}
- ouput : monotonic attention을 통해 context-aware해진 question embeddings {}
- 이때 는 자기 자신()과 그 이전에 풀었던 문제들{}에 따라 결정된다.
- The knowledge encoder
- input : raw question-response embeddings {}
- output : monotonic attention을 통해 context-aware해진 실제 습득한 지식 시퀀스 임베딩 {}
- 이때, 이 임베딩은 학생들이 현재 문제와 이전 문제들에서 어떻게 응답했는지에 따라 결정된다.
-
context-aware embeddings를 raw embeddings 대신 사용하려는 이유
⇒ 각 학생들이 문제를 풀면서 이해하고 배우는 방법이 학생에게 달려있다.
⇒ 그래서 학생들의 문제 풀이 데이터를 이용함으로써, 각 학생들의 실제 이해도와 지식을 반영하도록 설계함.
ex) 상이한 과거의 응답 시퀀스를 가진 두 학생은 같은 문제와 같은 지식에서 이해하는 방식이 다를 수 있다는 점..
-
The knowledge retriever (좀 더 많은 정보 필요. 어떻게 를 구하는지?)
- input : context-aware question()과 question-response pair embedding() ⇒ 즉, 위의 두 encoder에서 반환한 값들을 가져오면 된다.
- output : 현재 문제에 대한 검색된 지식 상태
- 지식 상태 또한 monotonic attention+alpha을 통해 구하는 듯하다.
- 학습자의 현재 지식 상태 또한 context-aware하다. 왜냐면 학생들이 응답하고 있는 현재 문제에 따라 달라지기 때문이다.
- context-aware하다는 것은 어떠한 문제를 푸는 행위 자체를 반영할 경우, 학생들의 실제 이해도와 지식 또한 반영되어 그 수치가 의미를 갖는다는 것 같다. (위의 섹션에서 설명하는 저자의 논리를 정리해보면 그렇다.)
- the knowledge retriever는 과거 풀었던 문제들, 그에 대한 학생의 응답, 현재 문제에 대한 question embedding에서 가져온 정보를 입력받는데, 이때 현재 문제에 대한 학습자의 응답은 반영되지 않는다. (input 부분)
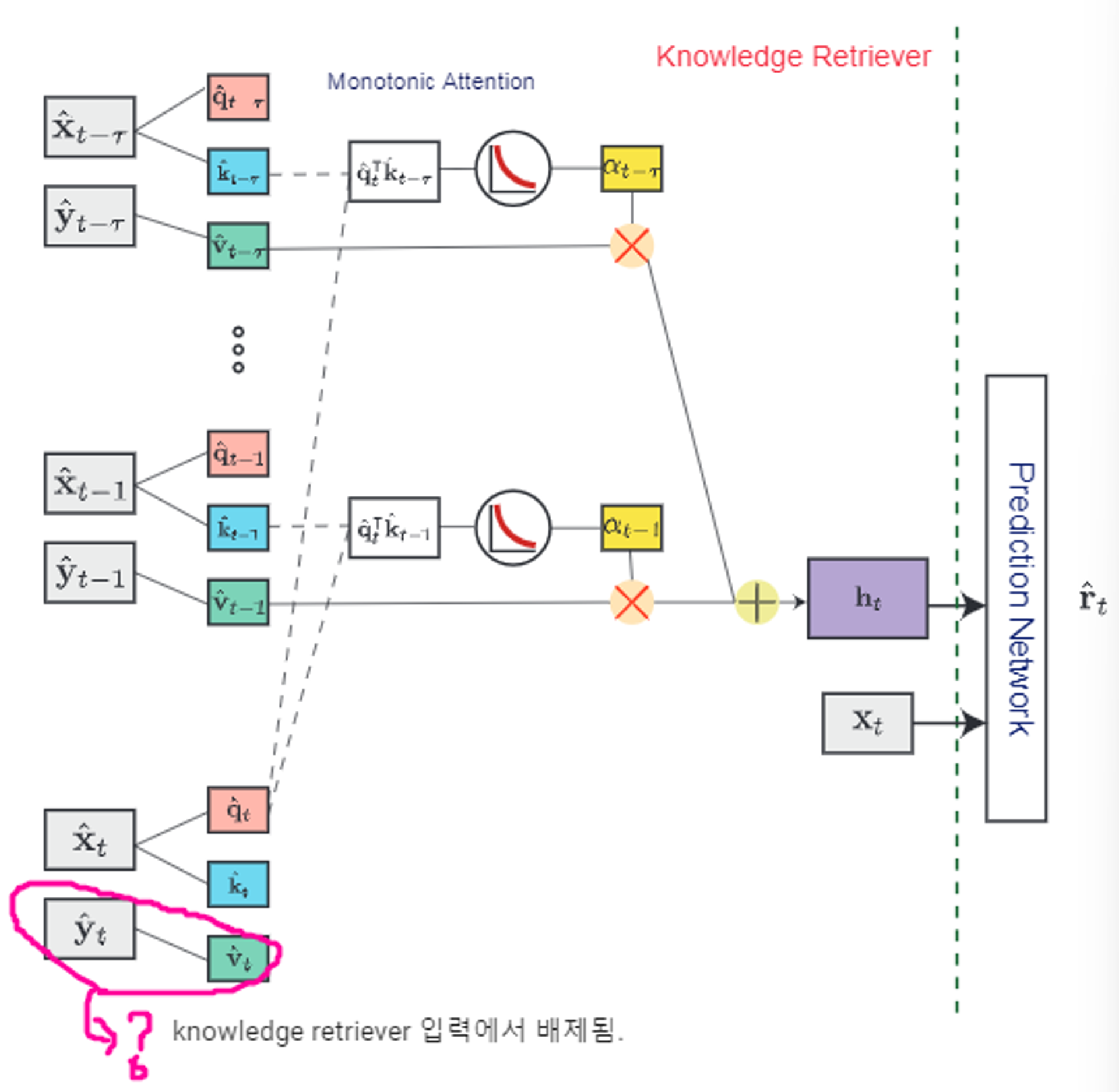
- 이 값(현재 문제에 대한 학습자의 응답)은 이제 다음 AKT의 요소인 ‘The response prediction model’에서 구할 것이다.
3.2 Monotonic attention
Monotonic attention의 쓰임
- 두 개의 self-atttentive Encoder 부분에서 context-aware하게 만들어 줄 때 필요
- Knowledge Retriever 부분에서 ⇒ 입력 받은 두 벡터 context-aware question()과 question-response pair embedding() 에서 t 시점의 을 도출해내는 과정에서 필요한 것 같다.
Monotonic attention의 동작
-
Key, Query, Value로의 mapping (+ the scaled dot-product attention mechanism)
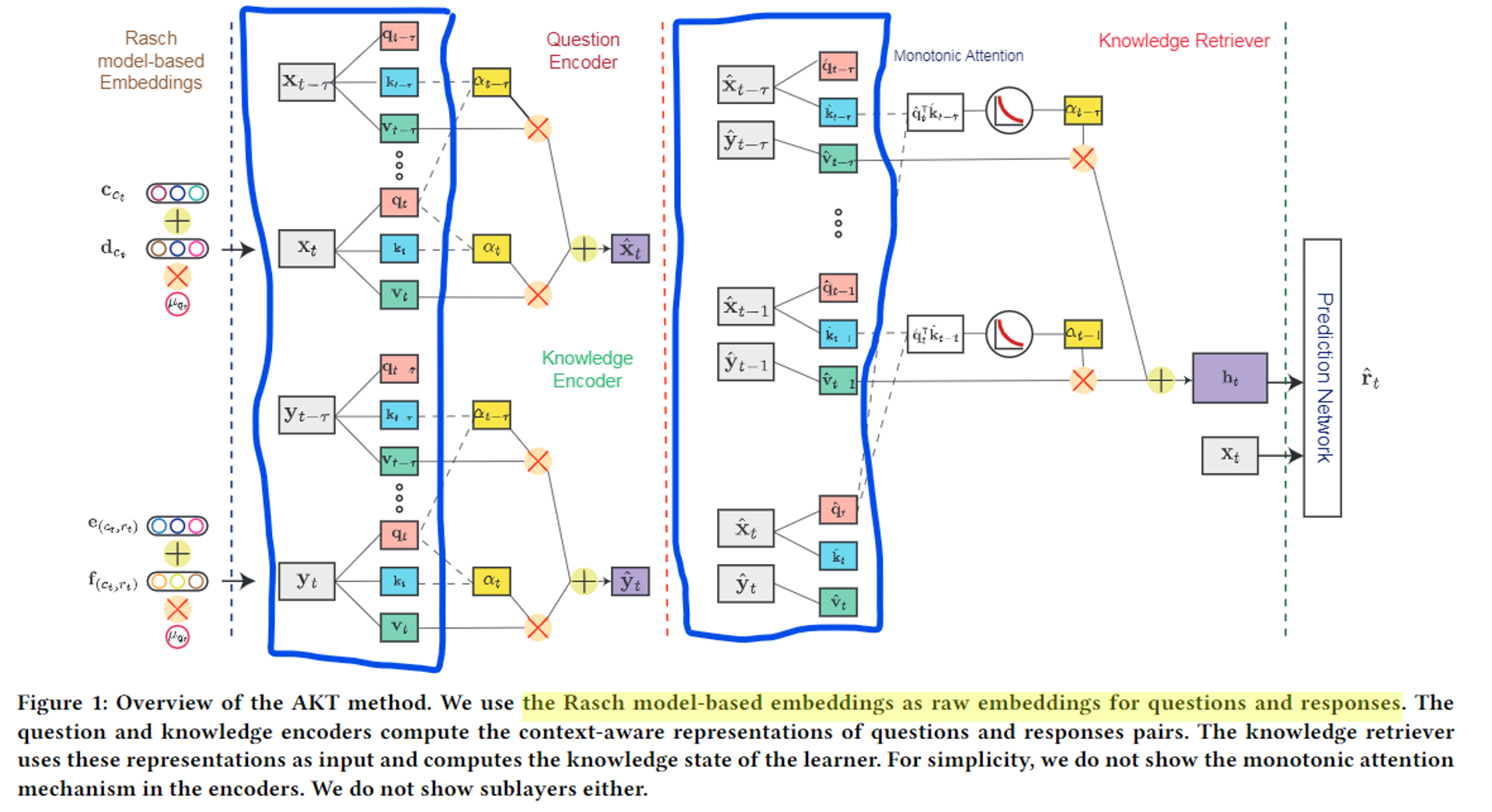
두 개의 encoder와 knowledge retriever에 key, query, value embedding 층이 있어서 각 구조에 입력값들이 이 3가지로 매핑된다. attention 연산을 해주기 위한 전처리 작업이라고 생각하면 쉽다. 이때, key랑 query의 dimension은 동일.
- 두 개의 Encoder 부분의 mapping : 문제 임베딩이든, 응답 임베딩이든 상관없이 모두 self-attention을 통해 q, k, v를 도출한다.
- 셀프 어텐션은 쿼리(query), 키(key), 밸류(value) 3개 요소 사이의 문맥적 관계성을 추출하는 과정
- Knowledge Retriever 부분의 mapping : self-attention을 수행하지 않음.
- SAKT의 경우: 문제 임베딩(x) - query / 응답 임베딩(y) - key, value
- AKT의 경우: 문제 임베딩(x) - query, key / 응답 임베딩(y) - value
⇒ mapping한 값을 알파 값으로 모으는 것이 dot-product…. 여기에 value를 곱한게 attention?
- 두 개의 Encoder 부분의 mapping : 문제 임베딩이든, 응답 임베딩이든 상관없이 모두 self-attention을 통해 q, k, v를 도출한다.
-
Exponential Decay
-
새로운 문제를 풀 때, 과거에 학습했던 경험 중 지금 이 문제와 관련이 없는 개념을 학습했거나, 너무 오래된 경우, 지금 이 문제와 매우 관련이 높다고 할 수는 없다.
-
따라서 두 가지 요소를 추가적으로 고려하고자 하였다.
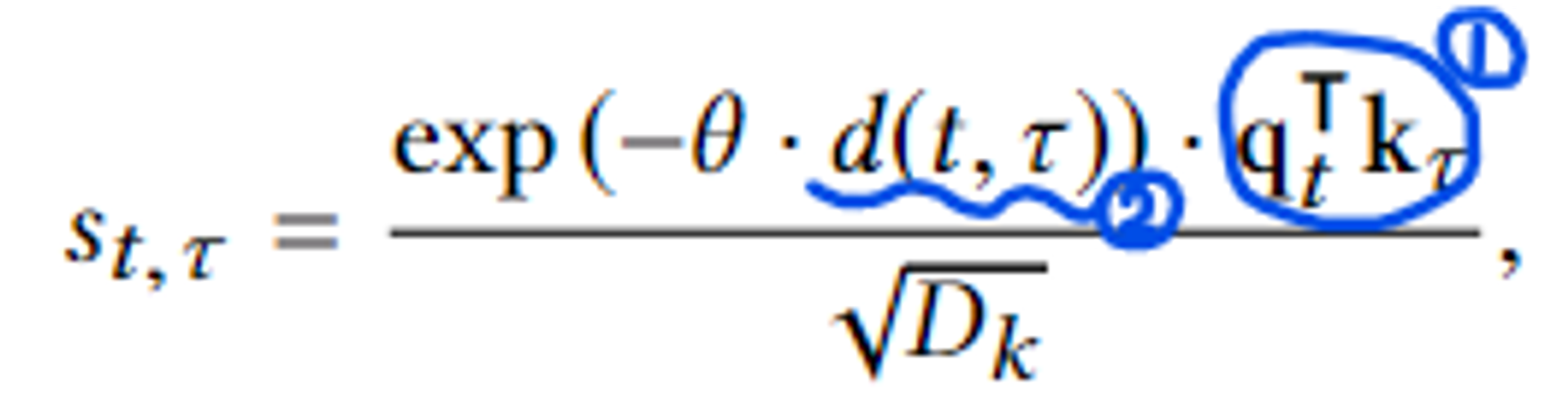
1. query(문제)와 key(개념) 사이의 관련성
2. 두 문제 사이의 시간 간격-
이때, theta 값은 learnable한 decay rate ⇒ 이것을 multi-head attention으로 경우를 나눠서 계산한 듯 하다. (Figure 2 참조)
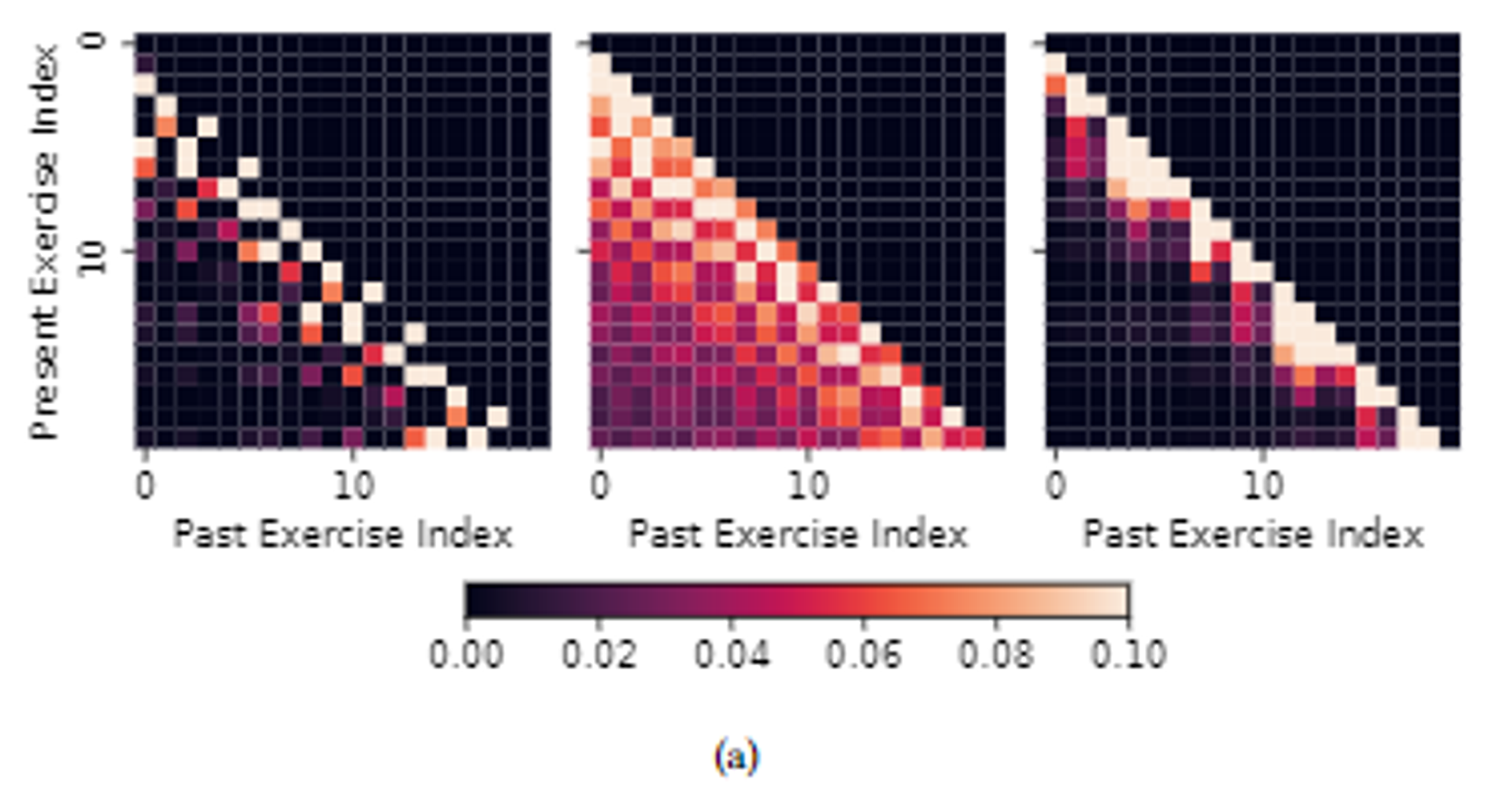
여기서, 두 번째 그림은 대각선 아래가 거의 다 밝은 색인 것으로 보아, 과거의 풀이 기록까지도 연관성이 있음을 알 수 있다.
세 번째 그림은 현재에서 가까운 것들만 밝은 색인 것으로 보아, 먼 과거의 풀이 기록의 경우 거의 연관성이 없는 경우임을 알 수 있다.
이와 같은 차이는 위의 세 attention heads에서 각각 다른 decay rates를 가지고 있기 때문이라고 한다.
-
먼 과거의 풀이 기록도 현재 (T) 문제 개념과 낮지 않은 연관성을 가질 수 있다.
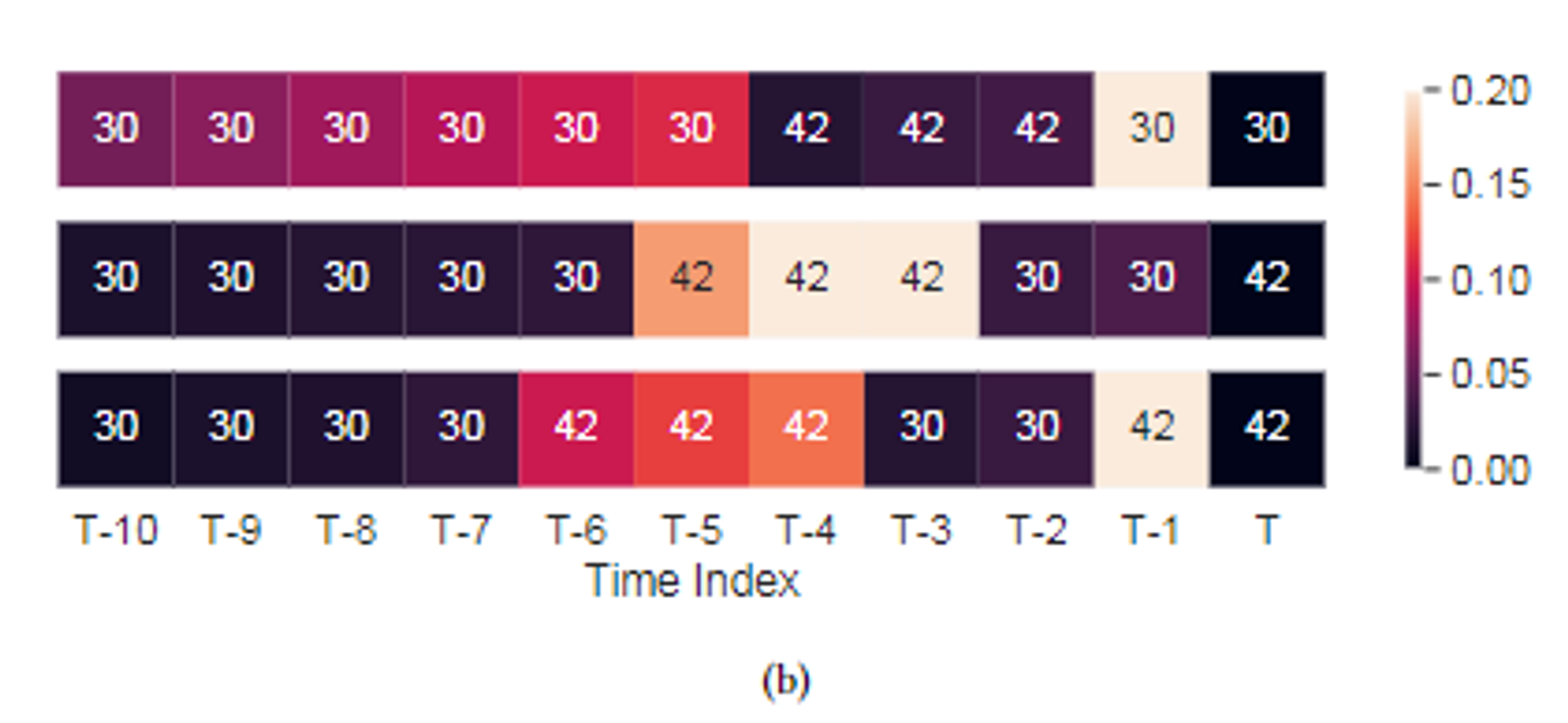
-
-
3.3 Response Prediction
-
출력 : t 일 때, 학생 i가 올바르게 현재 문제에 답할 확률().
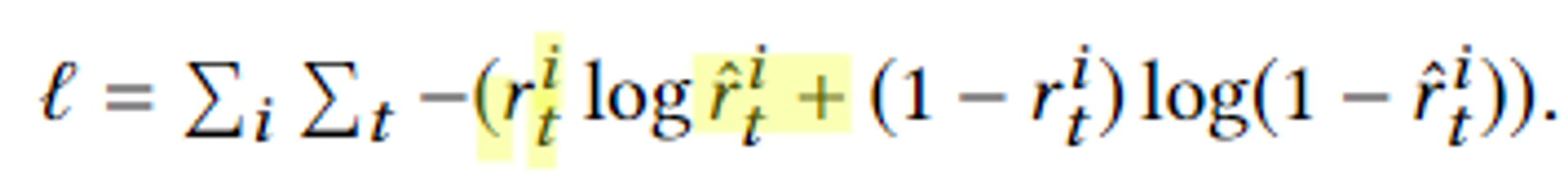
cross entropy 함수를 써서 에러를 최소화.
3.4 Rasch Model-Based Embeddings
- Rasch model의 쓰임 : raw question & knowledge embedding 생성
- raw question embedding계산
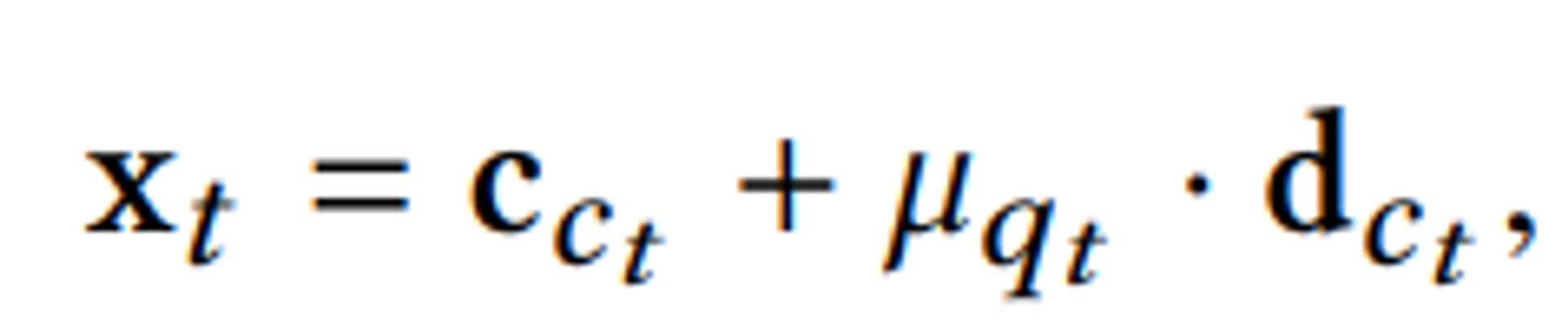
- raw knowledge(=question-response) embedding 계산
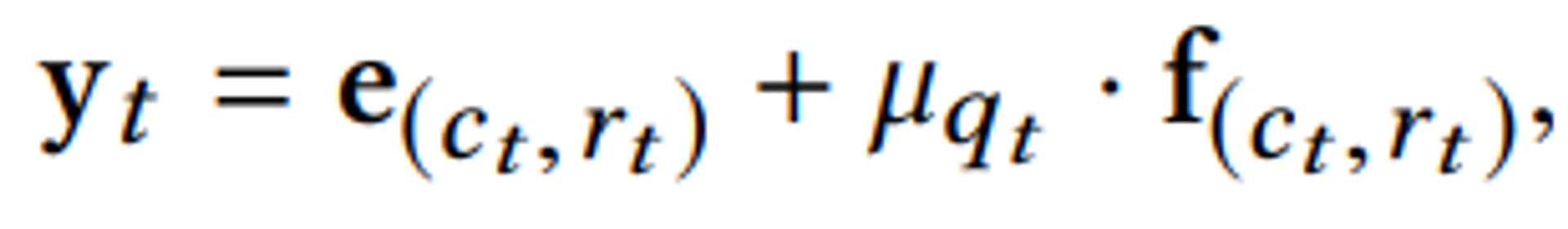
- 변수 정리
가 Rasch model의 난이도 변수값이다.var def concept id, question id, 정답 여부(0,1) 이 문제가 가지는 개념 임베딩 문제 변동성(?) 벡터 concept-response 임베딩 변동성 벡터 문제와 개념 사이가 얼마나 떨어져 있는지 조절하는 난이도 변수 
- Rasch 모델을 임베딩에 써서 좋은 점
- 같은 개념을 가진 서로 다른 질문 간의 차이를 모델링 할 수 있다.
- 그와 동시에, 파라미터 과부화를 피할 수 있다.
