✨중요 포인트
- 한국어 기반 NLP 연구
- 데이터 : 대부분 네이버/다음 카페 및 블로그 글을 가져옴. (소셜 미디어 활용)
- 우울증 진단 기준 : PHQ-9 (자가설문 방식, 심각성 측정) 이용
- 0-4 : 비우울
- 5-9 : 약함
- 10-14 : 보통
- 15-19 : 치료 요함.
- 20-27 : 심각 + 치료 활발히.
전체 연구 구조
소셜 미디어 사용자들의 우울증 분석을 위한 3가지 part‼
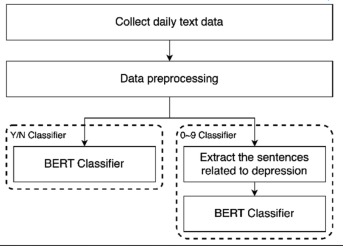
1. Sentence Classifier Training [SCT]
: 각각의 문장을 Y/N Classifier와 0-9 symptom Classifier를 거치게 하기 위해 이들을 BERT(+비교용 여러 모델들~)로 훈련시킴.
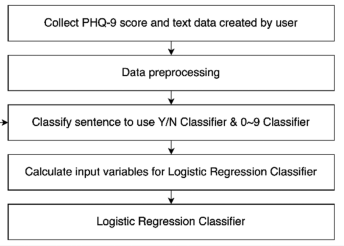
2. Depression Classifier Training [DCT]
: 선별한 텍스트 데이터를 [SCT]에서 훈련시킨 2가지 분류기에 넣고, 그 출력인 (Y/N, 0-9)를 로지스틱 분류기에 넣고 훈련시킴.
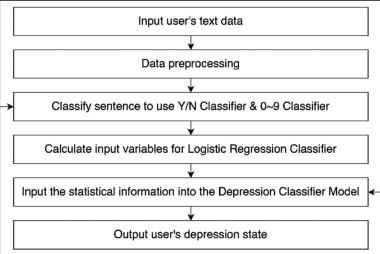
3. User’s Depression Classification [UDC]
: [SCT]과 [DCT]에서 훈련시킨 모델들에 실제 text data를 넣고 분류해봄.
사용된 데이터
[SCT]
- 출처: Naver Blog, Naver Cafe, Daum Cafe (+ 우울증 관련 카페)
- 데이터 전처리: stop word, spell checking ⇒ KSS 라이브러리 사용해 문장 단위로 자름 ⇒ 총 249,103개의 문장
- 라벨링 작업 : 손수작업 방식… ⇒ “Y/ N” 우울증 여부 ⇒ Y라면 …”0~9” ’0’(무소속) +PHQ-9의 9가지 증상
[DCT]
- 출처: 블로그 사용자 60명(우울증 의심 30 / 비우울 30, 기준: PHQ9 score ≥5)의 2주동안의 글들
- 데이터 전처리: [SCT]와 동일
- 라벨링 작업 : 각 참여자들의 PHQ-9 점수를 기준(≥5)으로 Y/N으로 나눔. (target)
[UDC]
- 출처: [DCT]와 동일한 듯..? 다만 글은 다르겠지..?
- 전처리도 동일.
- just classify…니까 훈련은 필요❌ → 라벨링 ❌
결과
- [SCT]에서 쓰인 분류 모델 중 최고성능👍 : BERT
- [DCT]에서 logistic regression 결과…
baseline (Y/N 분류기만 씀)<제안된 모델 (Y/N+0-9 classifier)
⇒ 역시 PHQ-9 증상 정보도 같이 고려되어야 한다…
➡ 논문 링크 : [Analysis of depression in social media texts through the Patient Health Questionnaire-9 and natural language processing](https://repository.hanyang.ac.kr/bitstream/20.500.11754/176492/1/85865_%EA%B9%80%EC%A2%85%EC%9A%B0.pdf)

매일매일이 새로운 시작점