ABSTRACT
3D facial scan video, audio Log-mel spectrograms, speech text 세 종류의 데이터를 이용하는 멀티모달 방식으로 우울증을 예측하고자 함.
-
Dataset
- 출처: DAIC-WOZ dataset
- 형식: (a) 68개의 3D facial landmark points (from video) (b) log-mel spectrogram (from audio) (c) Word2Vec embeddings (from text)
-
Model 구조
- C-CNN (causal CNN) : multimodal sentence-level embedding을 만들어주는 모델. 위의 세 종류 데이터를 하나의 벡터로 압축시키는 역할을 한다. dilated convolution을 포함하고, TCN, RNN과도 모종의 관계가 있는 것 같다…
- depression classifier : softmax 같은거로라도 쓴거여서 말을 안한 거였을까..하나의 함수 느낌. 우울증 여부(binary) 반환.
- PHQ regression model : 뭐 그냥 linear 모델이라도 썼냐..? 분류, 회귀 모델을 무엇을 썼는지는 나오지 않았다. 우울증 점수 값 반환.
-
학습 과정 (Appendix에 있었음.)
1) ‘어떤 모델을 써야 성능이 좋을까?’에 대한 연구
데이터는 위에 소개된 3가지 모두 사용. 기타 하이퍼파라미터에 대한 내용은 appendix 참고. 사용한 라이브러리는 Pytorch.
2) ‘어떤 조합으로 multimodal을 만들어야 성능이 좋을까?’에 대한 연구
총 8가지 조합으로 만듬.. 크게는 이렇게 나뉜다. ⇒ 단순 계산 임베딩 방법/ pre-trained 모델을 활용한 임베딩 방법/ long sequence처리 가능한 sentence-level 임베딩 방법
-
학습 결과
1) 어떤 모델을 써야 성능이 좋을까? ⇒ C-CNN이 짱이다
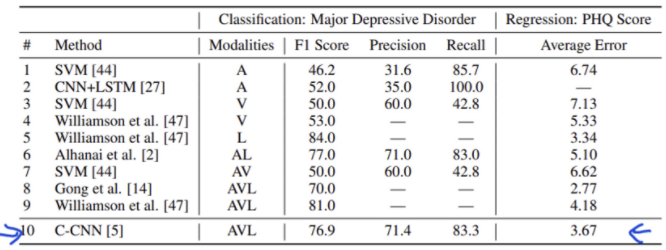
2) 어떤 조합으로 multimodal을 만들어야 성능이 좋을까? ⇒ 3가지 데이터셋을 모두 활용하고 모델은 C-CNN을 사용하였을 때가 짱이다..
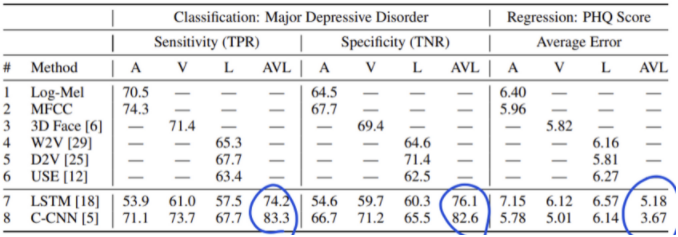
-
연구 의의 그리고 한계
- 인터뷰 문맥에 의존하지 않았다는 점.
- 기존의 배경지식들을 bias로 활용하지 않았다는 점. (오로지 데이터로만 승부를 보겠다)
- text 임베딩 시 보통 단어 단위로 많이 하는데, 문장 단위로 하여 보다 긴 시퀀스를 처리해보았다는 점.
- 한계라면 PHQ 점수를 평가 기준으로 삼는데, 실제 이것으로 공식적인 우울증 진단을 하는 건 아니라는 점.
-
내가 생각하는 연구 의의
SAME HERE…
- 우울증 연구에서 long sequence + multimodal 의 시작점같은 느낌.
새로 알게 된 내용 정리
-
sensitivity와 specificity: 민감도와 특이도. 의학계 쪽에서 쓰는 단어인듯?.. TP / TN / FP / FN 과 관련이 있다.
P가 질병 有, N이 정상으로 치자.
- 민감도 : 실제 질병이 있는 사람을 발견하는 정도 ⇒ 실제 질병 있는 사람들 중에서 질병 있다고 판단하는 비율 ⇒ TP / (TP+FN)
- 특이도 : 정상인 사람을 발견하는 정도 ⇒ 실제 정상인 사람들 중에서 질병 없다고 판단하는 비율 ⇒ TN / (TN+FP)
- 민감도 : 실제 질병이 있는 사람을 발견하는 정도 ⇒ 실제 질병 있는 사람들 중에서 질병 있다고 판단하는 비율 ⇒ TP / (TP+FN)
-
PHQ
: 비슷한 연구들에서도 우울증 평가 척도로 쓰이는데 실제로 우울증을 진단하는데 주로 쓰이지는 않음. 그래서 주의해야함❗
-
phoneme
: 음소 단위. 하나의 알파벳 느낌. 자연어 처리 분야에서 많이 쓰일 것 같다.
-
embedding
그냥 자연어 처리 분야에서는 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과로 생각한다.
하지만 이 논문에서는 멀티모달이니까 통합적으로 임베딩이란 어떠한 데이터들을 수치로 변환(요약)하는 것으로 생각하는 듯 하다.
-
Ablation Study
얘는 사실 나와 구면인데 되게 어려운 말이었던 것 같아서 이해를 못했었다.
하지만 다시보니 대충 감은 온다...
그냥 사전에 ablation만 치면 침식? 융삭? 과 같이 화학 용어가 등장하신다.
하지만 ‘Ablation Study’ 하면 이것은..
모델이나 알고리즘의 ‘feature’들을 제거해 나가면서 그 행위가 성능에 얼마나 영향을 미치는지 실험하는 것이다.
독립변수를 여러 개 바꿔보면서 하는 실험같다.
예를 들어서, 모기장이 모기 물리는데 어떤 영향을 받을까 궁금하면 한번 모기장을 없애고 취침하고, 한번은 모기장 있이 취침해서 실험해보는 거임.
-
Log-mel spectrograms
: 음성을 푸리에 변환 시킨거라고. 주파수로 나타내기! 특별한 무언가 메소드가 있겠지만 그정도까지 공부하면 나는 물리학과가 되기 때문에 싫다. 무슨 필터도 필요한 듯 하다.. cepstral coefficient가 뭔지 궁금하지만 안 찾아볼래..😵
-
Dropout
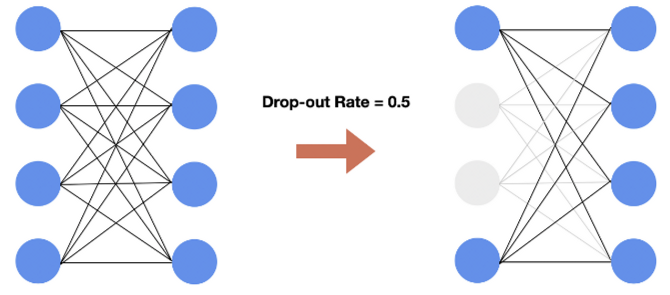
: Drop-out은 서로 연결된 연결망(layer)에서 0부터 1 사이의 확률로 뉴런을 제거(drop)하는 기법. 예를 들어, 위의 그림과 같이 drop-out rate가 0.5라고 가정한다. Drop-out 이전에 4개의 뉴런끼리 모두 연결되어 있는 완전연결 계층(Fully Connected Layer)에서 4개의 뉴런 각각은 0.5의 확률로 제거될지 말지 랜덤하게 결정된다. 위의 예시에서는 2개가 제거된 것을 알 수 있다... 즉, 꺼지는 뉴런의 종류와 개수는 오로지 랜덤하게 drop-out rate에 따라 결정된다. Drop-out Rate는 하이퍼파라미터이며, 일반적으로 0.5로 설정.
-
C-CNN(causal CNN)
: Causal convolution. wavenet에서 나온 개념인 듯 하다.
-
Wavenet
: caual + dilated 개념 합침
.
.
.
📝논문 링크: https://arxiv.org/abs/1811.08592
