이전에 AI hub 데이터를 이용해 만든 base 모델의 성능향상을 위해 다양한 시도를 해 보았다.
1. 텍스트 전처리
- 이모지 및 특수문자 제거
- 반복문자 정규화(최대 2개로) (ex. ㅋㅋㅋㅋ - > ㅋㅋ, 우와아아아아-> 우와아아)
- 영어 및 숫자 제거
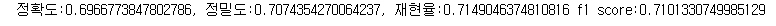
2. Back-translation
- 구글에서 제공하는 무료 api인 gooletrans api 이용하여 한글 -> 영어 -> 한글 거쳐 데이터 증폭
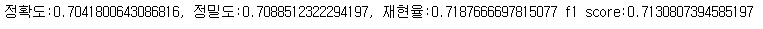
3. 분류 복잡도 줄이기
- 기존 7가지 감정 (neutral, happiness, sadness, angry, disgust, fear, surprise)을 분류하는 Task를 쪼개서 긍정, 부정, 중립, 놀람 4가지를 먼저 분류한 뒤, 부정일 때만 다시 sadness, angry, disgust, fear를 분류
- 놀람 라벨을 가진 데이터에 긍정과 부정이 섞여 있어서 긍정, 부정, 중립, 놀람 4가지로 나눴다.
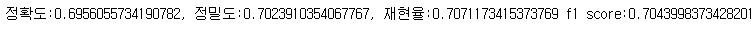
4. 품질 우려라벨 문제 보완
- 3번에서 얘기한 것처럼 놀람 라벨에 긍정과 부정 데이터가 섞여 있어서 성능이 잘 안 나오나 싶어서 전체 데이터셋에서 놀람을 제거한 뒤
(1) 중립인지 아닌지 판단하는 모델
(2) 긍정인지 아닌지 판단하는 모델
(3) 부정인지 아닌지 판단하는 모델 -> 부정이면 부정 감정 4중 분류(sadness, angry, disgust, fear)
(4) (3)번까지 모두 False이면 해당 문장은 놀람으로 판단
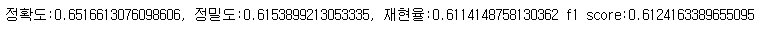
5. K-Fold cross validation
- fold를 5로 하여 모델 학습 후, 5개의 모델 앙상블
- 모델의 성능이 전부 비슷하여 hard-voting
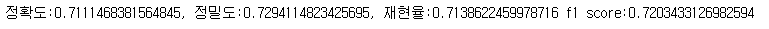
Conclusion
-
텍스트 전처리에서 성능향상이 없었는데, 그 이유로 현재 AI hub 데이터가 Emoji나 noise가 많이 들어가지 않은 데이터라 이런 결과가 나오지 않았나 하는 생각이 든다.
-
개인적으로 Back-translation에서 어느 정도의 성능 향상을 기대했는데 오히려 떨어지는 결과를 보여서 실망스러웠다. Data Imbalance 문제를 해결하기 위해 부족 label에 대해서만 Back-translation을 적용해 보기도 하고, 가장 많은 neutral 데이터를 제외하고 나머지를 증폭시켜보기도 했지만, base 모델의 f1-score를 넘지 못했다. 여러 논문과 다른 사람들의 연구를 살펴보니, Back-translation을 사용했을 때 기존 문장의 의미가 바뀌어 버리는 경우가 있어 주의해야 한다고 한다.
-
분류 복잡도를 줄이면 성능이 오를까 하여 체를 거르는 식으로 실험을 진행하였지만, 역시 base model의 성능을 넘지 못했다.
-
Train data를 조금 더 늘리면 성능이 오를까 하여, K-fold Cross Validation 기법을 이용하여 fold를 5로 나누어 hard-voting 방식으로 앙상블이 진행했을 때 미세하게 base보다 성능이 오르는 것을 확인했다.
-
아쉬웠던 건 오픈 데이터 중 그나마 품질이 좋았던 AI hub 데이터를 사용했지만, 동일한 문장을 교묘하게 특수문자를 추가하거나, 글자 하나만 바꾸는 식으로 데이터가 구성되어 있어 조금 더 양질의 데이터를 이용했으면 실험이 조금 더 의미 있지 않았을까 하는 아쉬움이 있다.
향후 연구방향
-
Data augmentation 방식 중, Back-translation만을 사용해서 실험을 진행했는데 다른 기법들도 적용하여 성능의 변화가 있는지 확인
-
K-Fold Cross Validation에 Soft-voting 방식 적용하여 결과 확인
