현재 졸업 프로젝트로 진행중인 감성 다이어리에 사용하기 위해 감성분류 모델을 만들고 있다.
이를 위해, 기존 BERT의 한국어 성능 한계를 극복하기 위해 SKT -brain에서 공개한 KoBERT를 이용해 Fine-tuning 하는 과정을 기록하려고 한다.
1. 데이터셋
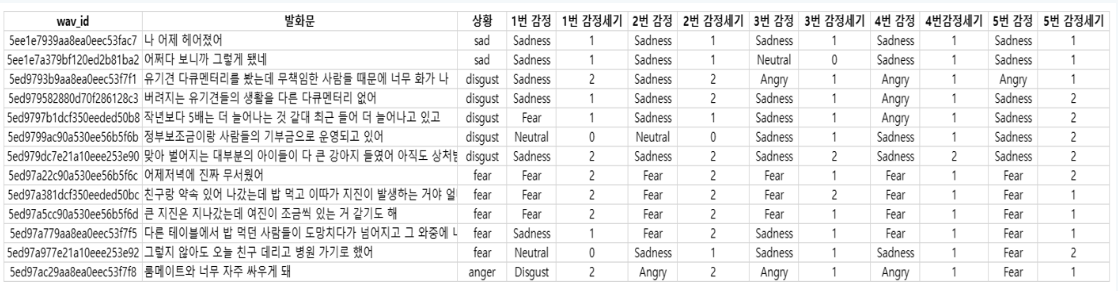
AI hub의 감정 분류를 위한 대화 음성 데이터셋을 이용했다.
해당 데이터셋은 총 7개의 감정(happiness, angry, disgust, fear, neutral, sadness, surprise)으로 레이블링이 되어있다.
4차년도, 5차년도, 5차년도_2차로 나눠서 csv 파일로 제공되는데, 우선 5차년도_2차 데이터만을 사용해서 성능을 확인했다. 단발성 대화 데이터셋을 이용해서 실험을 진행해 봤는데, 데이터셋의 라벨링이 이상하게 된 경우가 많아 성능이 너무 안 나왔다...ㅠ
대화 데이터셋이다 보니 한 문장만을 보는 것이 아닌 대화 문맥에서의 상황을 적어 놓은 것 같다.
"상황" 열을 정답 레이블로 사용하기엔 적절하지 않아 보였다.
데이터셋 설명에서 5명이 이 데이터에 대해 라벨링을 진행했다고 적혀 있는 것을 보니 1번~5번 감정이라고 적혀 있는 것은 라벨링을 진행하신 분들마다 해당 문장을 보고 판단한 감정 레이블인 것 같다.
내가 필요한 것은 단순히 한 문장을 봤을 때의 감정이 필요한 것이므로 1~5번까지의 감정을 이용해 정답 레이블을 새로 만들고자 한다.
우선, 중복 데이터들이 있어 중복 제거를 한 뒤, 다음의 기준으로 정답 레이블을 새로 만들고자 한다.
- 1~5번까지의 감정 중 다수결로 많이 나온 감정을 정답으로 채택
- 만약 1~5번까지 감정이 다수결로 나오지 않으면, "상황"열의 감정값까지 이용하여 다수결을 구한다.
기존 19374개의 데이터에서 중복 제거를 하니, 18,651개로 데이터 갯수가 줄었다.
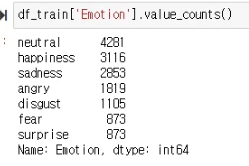
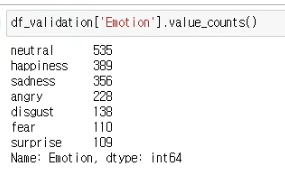
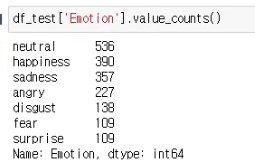
18,651개의 데이터를 sklearn의 train_test_split 함수를 이용해 8:1:1의 비율로 나눴다.
Train set
Validation set
Test set
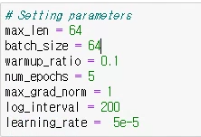
2. 하이퍼 파라미터 세팅
3. 실험 결과


Conclusion
Test data에 대해 f1 score가 0.71 정도 나왔다. 7개 라벨에 대해 분류하는 거 치고 성능이 꽤 괜찮게 나온 것 같다.
한 문장씩 넣어서 테스트를 진행해 봤을 때도 나쁘지 않은 것 같다.
이 수치를 베이스로 삼아서 성능을 향상시켜봐야겠다.
현재 데이터가 불균형하므로, 그걸 해결하면 성능 향상을 기대해 볼 수 있을 것으로 보인다.
Data augmentation을 진행하기 전에, Weighted-loss를 CrossEntropy 함수에 적용하여 학습을 진행하고 결과를 확인해 봐야겠다.
앞으로 시도해 볼 것들
- Weighted-loss 적용 후 결과 확인
- 감정분류를 위한 대화 데이터셋에서 총 3개의 데이터셋 중 1개만 사용했는데 3개를 다 합쳐서 학습 후 결과 확인, 데이터 불균형 해소를 위해 부족 라벨만 보충해서 진행하는 것도 의미가 있어 보임
- 데이터 불균형을 해소하기 위해, 부족 Label에 대해 Data augmentation 적용 후 결과 확인
- Kaggle Emotion Dataset을 번역한 데이터를 추가하여 결과 확인
Insight
한 문장에 여러 감정이 들어간 경우를 판단할 수 있는 모델을 만들고 싶었는데, 위 데이터를 잘 이용하면 가능할 것 같기도 하다. 뭔가 5가지 사람의 판단을 다 넣어버리면 이것도 저것도 안 되는 결과가 나와버릴지도...실험을 해봐야 알 것 같다.
우선 Single-label-classification에 집중하고, 나중에 Multi-label-classification을 시도해 봐야겠다.
