21년도 초에 작성한 글을 이전.
1. 구현할 것
관계형 데이터베이스 환경에서 99단계의 깊이를 지원하는 계층형 게시판을 구현할 것이다. 구조의 단순화를 위해서 내용만을 가지는 덧글 게시판의 형태를 취할 것이다. 또한 실제 구현 완성본과 달리 게시글에 삭제와 인증 기능에 대해서도 다루지 않는다. 계층형 데이터의 생성과 조회를 중점으로 다룰 것이다.
요구 사항
- Root 덧글은 최신글이 가장 위로 올라오도록 구현한다.(내림차순 정렬)
- 그 외 답글은 가장 오래된 글이 가장 위로 올라오도록 구현한다.(오름차순 정렬)
- 데이터가 1억개가 넘어가도 느려지지 않도록 페이징을 구현한다.
계층형 게시판이란?
계층형 게시판이란 게시글과 그에 대한 답글이 계층 관계(혹은 종속 관계)를 가지는 게시판 구조를 의미한다.
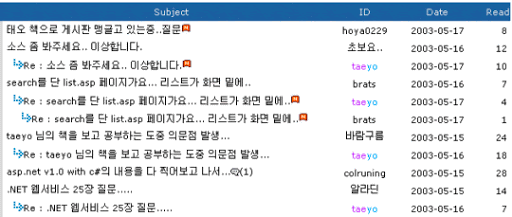
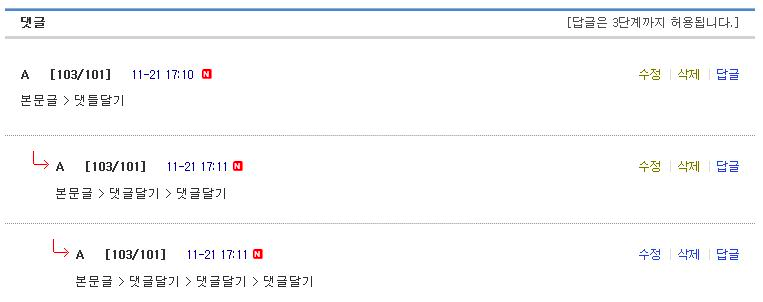
덧글 게시판이란?
일반적인 게시글은 타이틀과 본문 내용을 갖는다. 그러나 덧글 게시판은 별도의 타이틀을 갖지 않고 아래와 같이 본문 내용만을 갖게된다.
2. 사용할 기술 스택
- Backend
- Spring Boot 2.4.5
- JDK 11
- Spring Data JPA
- MySQL 5.7
- Frontend (단순 작동 확인용)
- Node.js 14
- React.js
- Axios
Spring Boot
Spring boot란 별도의 WAS 설치 없이 단독 실행되는, 상용화 가능한 수준의 Spring Framework 기반의 애플리케이션을 쉽게 만들어낼 수있게 하는 도구이다.
JDK11
JDK란 Java Development Kit의 약자로 자바 애플리케이션을 구축하기 위한 핵심 플랫폼 구성요소이다. 개발자가 자바 기반 애플리케이션 개발을 위해 다운로드 하는 소프트웨어 패키지라고 할 수있다. 이는 자바 JVM과 JRE를 포함하고 있다. 본 구현에선 11버전을 사용한다.
Spring Data JPA
Spring Data JPA란 ORM(Object Relational Mapping)의 일종으로 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스이다. 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑해주는 도구로 관계형 데이터베이스의 테이블을 클래스와 같은 형태로 다룰 수 있게 해준다. 본 구현에선 MySQL 5.7을 Spring Data JPA로 래핑하여 사용한다.
MySQL 5.7
세계에서 가장 많이 쓰이는 오픈 소스 관계형 데이터베이스 관리 시스템(RDBMS)이다.
Frontend
동작 여부를 시연하기 위해 React.js를 사용한다. Spring Boot로 구현된 Backend Server와 통신하기 위해 Axios 라이브러리를 사용한다.
3. RDB에서 계층형 데이터 구조를 저장하는 방법
DB Schema
CREATE TABLE 'board' (
'id' BIGINT AUTO_INCREMENT PRIMARY KEY,
'content' VARCHAR(2000) NOT NULL,
'group_id' BIGINT NOT NULL,
'groud_order' INT NOT NULL,
'depth' INT NOT NULL
)- id: 각 Row를 고유하게 식별하는 기본 키이다.
- content: 덧글의 내용이 담겨 있다.
- group_id: Root 덧글(depth 0)을 기준으로 답글들을 하나의 그룹으로 묶기 위한 값이다. 한 Root 덧글 아래의 모든 답글들은 깊이에 상관없이 Root 덧글과 같은 group_id를 갖는다.
- group_order: 같은 group_id를 갖는 덧글들 간의 순서를 식별하기 위해 사용하는 값이다.
- depth: 덧글의 깊이를 나타낸다. Root 덧글의 경우 0을 갖고, 그 이후 답글들은 부모 덧글의 depth+1한 값을 갖는다.
계층형 구조로 조회(READ) 방법
아래의 SQL 문을 사용하여 요구사항에서 주어진 계층형 구조로 덧글들을 조회할 수 있다.
SELECT * FROM board
ORDER BY group_id DESC, group_order ASC위와 같이 조회하면 최상위 Root 덧글을 최신글부터 조회(내림차순)되도록 하며 같은 Root 덧글을 갖는 답글들을 오름차순으로 정렬할 수 있다. 아래 DB 상태를 위 쿼리문으로 조회하면 예시 사진과 같은 결과가 나올 것이다.

<사진. 위 DB 상태에 대한 결과>
이 계층형 DB 구조의 핵심은 group_id와 group_order라고 할 수 있다. 아래 예시를 통해 덧글 작성시 group_id와 group_order가 어떻게 초기화되고 변화되는 지 확인해보자.
생성(CREATE) 방법
1) Root 덧글 작성(최상위 덧글)
Root 덧글을 하나 작성해보겠다. 작성 후 DB 상태는 아래와 같이 될 것이다.
위의 표는 Root 덧글 생성 직후 DB의 상태이다. id는 Auto Generation 된 값이니 논외로 하고 group_id와 group_order, depth를 중점으로 살펴보겠다. 일전에 group_id는 root 덧글을 기준으로 답글을 포함하여 하나의 그룹으로 묶기위해 사용하는 값이라고 했다. 각 root 덧글마다 하나의 그룹을 갖기에 Root 덧글 생성 시마다 group_id는 고유한 값이 들어간다.
Oracle DB를 사용할 경우엔 group_id 생성을 위한 Sequence를 사용했겠지만 본 구현에선 MySQL을 사용하므로 Sequence와 같은 요소가 없다. group_id의 maximum value를 조회해서 생성할 경우 동시성 문제가 발생할 수 있으므로 Root 덧글의 id컬럼 값을 그대로 group_id로 사용하였다. Root 덧글의 그룹 내 순서는 가장 앞이므로 group_order는 0을 갖도록 하였고, depth또한 0으로 초기화하였다.
만약 추가로 Root 덧글을 작성한다면 DB 상태는 아래와 같이 될 것이다.
<사용자 관점에서 덧글 게시판의 상태>
- test 2
- test 1
위 상황에서 살펴본 Root 덧글 생성 알고리즘을 코드로 작성하면 아래와 같다.
@Transactional
public Board writeComment(User writer, CommentRequest commentRequest) {
String content = commentRequest.getContent();
Board board = boardRepository.save(Board.create(content));
board.setGroupId(comment.getId());
return board;
}
// 아래는 Board.create() - 정적 생성자
public static Board create(String content) {
Board instance = new Board();
instance.content = content;
instance.depth = 0;
instance.groupOrder = 0;
instance.groupId = 0; // Not NULL이므로 일단 0으로 초기화
return instance;
}2) 답글 작성
Root 덧글(id:1, content: test 1)에 대해 답글을 하나 작성해보겠다. 작성 후 DB의 상태는 아래와 같이 될 것이다.
**<사용자 관점에서 덧글 게시판의 상태>**
- test 2
- test 1
- reply 1test 1(id:1) 덧글에 대한 답글인 reply 1(id:3)은 부모인 test 1과 같은 group_id를 가지게 되었다. 그리고 depth로 test의 depth + 1인 1을 가지게 되었다. group_order는 현재 그룹 내 maximum value 의 +1한 값(1)을 가지게 되었다.
여기서 test 1에 대한 답글을 추가로 작성하면 DB는 아래와 같이 될 것이다.
**< 사용자 관점에서 덧글 게시판의 상태>**
- test 2
- test 1
- reply 1
- reply 2그룹 내 같은 depth를 갖는 덧글들은 오름차순(오래된 덧글 우선)으로 조회되야 하므로, group_order로 현재 그룹 내 maximum value 의 +1한 값(2)을 가지게 되었다. group_id는 root 덧글인 test 1과 같다(1). depth는 test 1의 depth의 +1한 값(1)을 가지게 되었다.
이 상태에서 reply 1에 대한 답글을 작성해보자. 그러면 DB 상태는 아래와 같이 될 것이다.
**< 사용자 관점에서 덧글 게시판의 상태>**
- test 2
- test 1
- reply 1
- reply 1-1
- reply 2reply 1에 대한 답글인 reply 1-1이 reply 1에 바로 아래에 위치하게 하기 위해서 reply 2의 group_order가 바뀌었다. (2→3) 그리고 기존 reply 2의 group_order를 reply 1-1이 가지게 되었다.
위의 답글 생성 예시를 통해 답글의 group_order가 어떻게 할당되고 변화되는지 확인할 수 있었다. 그리고 group_order를 계산해내는 방법이 아래와 같이 2가지 케이스가 있음을 확인할 수 있었다.
케이스 1
reply 2가 생성될 때 group_order는 현재 같은 group_id 내 group_order의 maximum value + 1임을 설명하였다. 이 상황을 그림으로 나타내면 아래와 같다. (Max값 계산에 따른 동시성 문제는 Table Lock으로 해결하였으나 여기선 다루지 않겠다.)
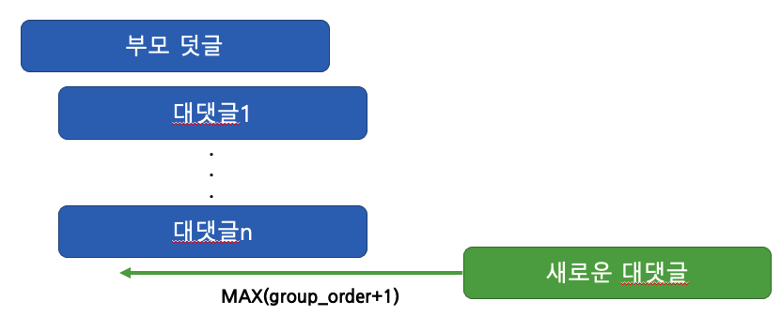
케이스 2
reply 1-1가 생성될 때 reply 2의 group_order가 +1 되었고 기존의 group_order를 reply 1-1에 적용함을 보았다. 이 상황을 그림으로 나타내면 아래와 같다.
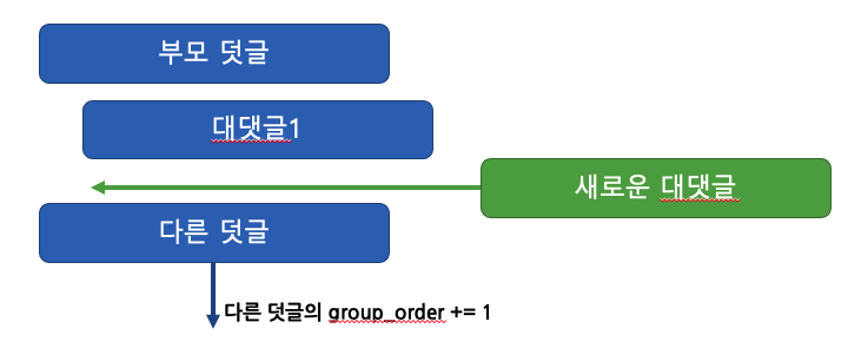
두 케이스를 고려한 답글 생성 알고리즘을 코드로 작성하면 아래와 같다.
@Transactional
public Comment writeReplyComment(int parentBoardId, CommentRequest commentRequest) {
Board parentBoard = getBoardById(parentBoardId);
if(parentComment.getDepth() >= 98) {
throw new MaxDepthException("Max reply depth is 99!");
} // 99단계 제한을 위한 예외 발생
String content = commentRequest.getContent();
int nextGroupOrder = getNextGroupOrder(parentComment);
Board board = Board.createReply(
content,
parentBoard,
nextGroupOrder); // 답글 DB에 기록
}
// group_order를 계산하는 알고리즘.
private int getNextGroupOrder(Board parentBoard) {
int nextGroupOrder = boardRepository
.getNextGroupOrder(
parentBoard.getGroupId(),
parentBoard.getGroupOrder(),
parentBoard.getDepth()
);
if(nextGroupOrder == -1) { // 케이스 1번의 경우.
nextGroupOrder = commentRepository
.getMaxGroupOrder(parentComment.getGroupId()) + 1;
} else { // 케이스 2번의 경우
commentRepository.addGroupOrderAfter(
parentComment.getGroupId(),
nextGroupOrder
); // reply 2와 같이 새로운 답글이 가지게 될 group_order 이상인 덧글들의
// group_order를 ++1한다.
}
return nextGroupOrder;
}4. 페이징 쿼리 개선
1) 페이징 쿼리 속도 개선을 위한 인덱스 생성
create index IDX_HIERARCHY
on boards (group_id desc, group_order asc);
-- SELECT * FROM board
-- ORDER BY group_id DESC, group_order ASC 를 위함.위 조회 쿼리는 계층형 구조로 결과를 만들기 위해서 정렬이 필요하다. 인덱스가 없으면 조회 시마다 모든 데이터를 가져오는 FULL TABLE SCAN과 정렬하는 FILE SORT가 발생하므로 조회 시간이 상당히 소요된다. 이를 개선하기 위해 인덱스를 생성하였다.
2) Spring Data JPA의 페이징 쿼리
Spring Data JPA의 PagingAndSortingRepository 인터페이스는 SELECT문의 페이징을 위해 기본적으로 Pageable이라는 인터페이스의 구현체를 매개변수로 받는다.
public interface PagingAndSortingRepository<T, ID extends Serializable>
extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}따라서 이를 사용한 페이징 요청 코드는 기본적으로 아래와 같다.
PagingAndSortingRepository<Board, Long> repository = // … get access to a bean
Page<Board> boards = repository.findAll(new PageRequest(1, 20));
// 20개 단위로 데이터를 나눴을 때 1번 페이지에 해당하는 값들을 가져옴. (결과 개수는 최대 20개)
// 페이지 번호 기본값은 0. 1번 페이지는 2번째 페이지이다.이 메소드는 SQL로 변환되어 MySQL과 같은 RDB에 요청되는데 아래와 같이 요청된다.
SELECT * FROM boards LIMIT 20, 20; -- 20번째 데이터부터 20개의 데이터를 가져온다.3) 예제에 적용된 Spring Data JPA의 페이징 쿼리 문제점
select * from boards order by group_id, group_order limit ?, ? -- offset, size본 구현에 기본적인 Spring Data JPA로 페이징 쿼리를 보냈을 때 위의 쿼리가 요청된다. MySQL은 offset이 작을 때는 아래와 같이 필요한 데이터에만 접근하여 원하는 결과를 만들어낸다.

그러나 offset이 커지면 MySQL이 Index를 참조하는 것보다 Full Table Scan & File Sort 후 참조하는 것을 더 나은 성능이 나올 것이라 판단하게 된다. 따라서 아래와 같이 비효율적인 방식으로 조회하게 된다. 소요시간은 2.554초가 걸렸다.

4) 페이징 쿼리 개선
SELECT * FROM boards b
JOIN (SELECT id FROM comment
ORDER BY group_id, group_order
LIMIT ?, ?) AS temp
ON temp.id = b.id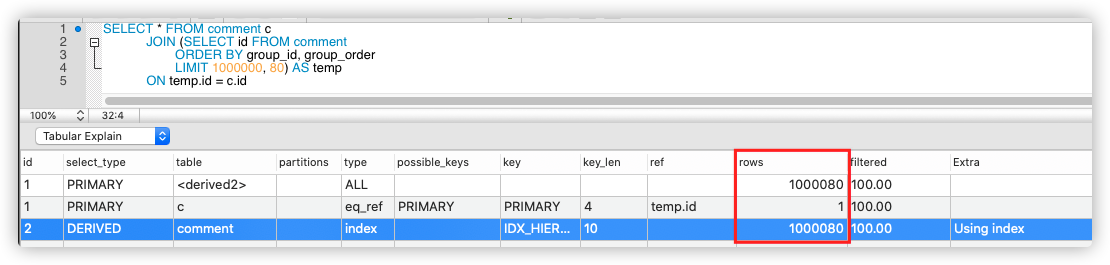
위와 같이 쿼리를 변경 후 데이터 블록에 접근하지 않고 Index Scan만으로 원하는 결과를 만들어 내는 모습을 볼 수있다. 조회 소요된 시간은 기존의 1/20정도인 0.158초가 되었다.
기존의 방식의 경우 앞서 말했듯 Limit의 Offset 값이 커지게 되면 단순 Full Scan이 더 빠르다고 판단하여 인덱스를 사용하지 않게 된다. 따라서 Order by 를 위해 데이터 블록에서 모든 데이터를 가져온 후 File Sort 수행하게 된다. 그 결과, 데이터 블록 접근 횟수가 전체 row의 개수가 되고, File sort 비용까지 발생하게 되어 데이터가 많아질 수록 느려지게 된다.
현재 IDX_HIERARCHY의 인덱스 페이지는 다음과 같이 구성되어 있을 것이다.

변경된 방식의 경우 정렬된 PK 목록(서브쿼리의 결과)을 가져오는데 IDX_HIERARCHY 인덱스에 있는 데이터만을 사용하게 된다. 인덱스 내에서 데이터가 이미 정렬되어 있기 때문에 File Sort의 비용도 들지 않는다. 조회 쿼리에서 요구하는 모든 컬럼을 포함하고 있는 인덱스를 커버링 인덱스라고 하는데, IDX_HIERARCHY가 바로 커버링 인덱스가 된다. 커버링 인덱스가 사용될 경우, 해당 페이지 접근만으로 결과를 추출할 수 있게 된다. PK는 기본적으로 클러스터 인덱스로 설정되어 있어, 바로 데이터블록에 접근하여 원하는 값을 가져올 수 있다. 따라서 Full Table Scan도 발생하지 않는다. 결과적으로 데이터 블록 접근 횟수가 서브 쿼리의 row 개수가 되고 File Sort 비용도 빠지므로 쿼리 성능이 증가하게 된다.
5. 정리
지금까지 RDB 환경에서 계층형 구조(트리)의 데이터를 저장하는 방법에 대해 작성하였고, 대량 데이터 DB에서 페이징 쿼리 조회 시 성능 개선 방안에 대해 작성하였다. 이 구현에선 group_id와 group_order라는 컬럼을 주로 사용하여 계층형 구조를 구성하였다. 이 구조는 조회 성능면에선 상당한 강점을 보인다. 하지만 답글 생성시, 최악의 경우 모든 데이터를 업데이트 해야한다는 단점을 가지고 있다. 여기서 다루지 않았지만 이를 개선하기 위해 Materialized Path라는 방식을 활용하여 구조를 변경하였다. 커버링 인덱스는 페이지 숫자를 필요로 하는 페이징 방식에서 강점을 발휘하지만, 인덱스의 크기가 커져 DB의 공간을 많이 차지할 수 있다는 단점이 있다. 이를 개선 하기 위해선 페이지 숫자를 사용하지 않는 인피니티 스크롤 방식의 페이징을 활용하는 것이 좋다. 이 구현 방식은 추후 더 연구해볼 예정이다.
