Spark는 분산 처리 컴퓨팅 엔진이므로 일반적인 RDMS보다 조금 더 폭 넓게 Join Strategy를 지원
- Broadcast Hash Join
- Broadcast Nested Loop Join
- Shuffle Hash Join
- Shuffle Sort Merge Join
- Cartesian Product Join
Spark SQL을 사용하여 Join을 할 때, 여러 타입의 힌트가 지원
- BROADCAST
- 힌트 사용시 autoBroadcastJoinThreshold 옵션을 무시하고 동작
- MERGE (SHUFFLE_MERGE 과 동일)
- Sort-mege 조인을 사용
- SHUFFLE_HASH
- SHUFFLE_REPLICATE_NL
만약 JOIN 대상 양쪽 테이블에 Join 을 위한 다른 Hint 가 각각 지정된다면 Spark 는 다음의 우선순위를 이용해 결정
- BROADCAST > MERGE > SHUFFLE_HASH > SHUFFLE_REPLICATE_NL
- 양쪽 테이블에 모두 똑같은 Join Hint 가 지정된다면 (Broadcast 및 Shuffle Hash) Spark 는 테이블의 사이즈를 고려해 작은쪽을 기반 테이블로 사용
Join Strategy
Spark에서는 사용자가 직접 Hint로 지정하지 않는 경우 Join 시 양 테이블의 데이터 사이즈를 고려해 최적화된 Join 전략을 사용
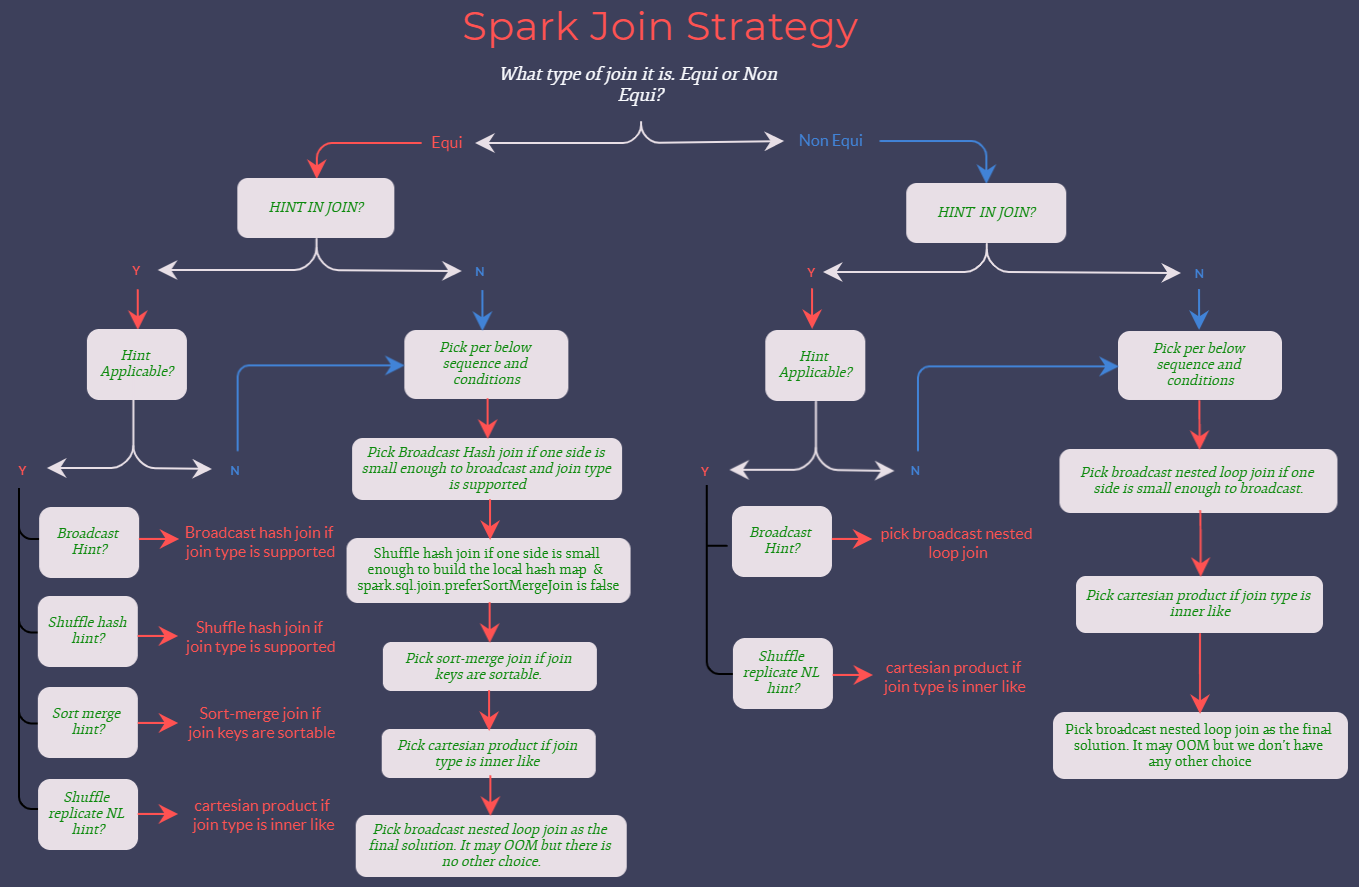
=을 이용한 동등 조인일 경우와 아닐 경우에 따라 사용할 수 있는 Join 전략이 다름- Equi Join의 경우 Broadcast, Shuffle Hash, Sort Merge, Shuffle Replicate NL 사용 가능
- Non Equi Join의 경우 Broadcast, Shuffle Replicate NL 사용 가능
Join 과정에서 가장 먼저 생각해야 할 것은 데이터의 이동
- 데이터를 어떻게 이동시킬 것이냐에 따라 Broadcast / Shuffle 방식으로 구분
- 그 이후에 Hash, Sort Merge, Nested Loop 등 구체적인 Join 알고리즘이 구분
Broadcast Join
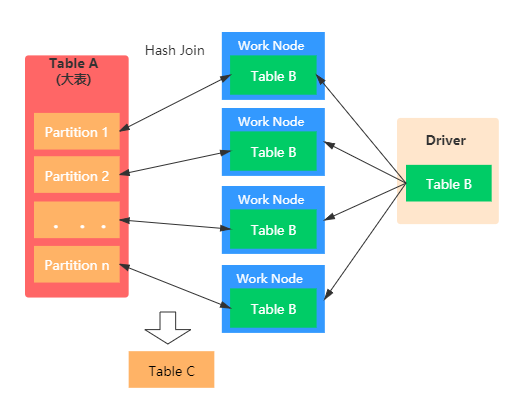
Broadcast 방식은 작은 사이즈의 테이블을 Driver를 거쳐 각 Worker 노드에 전부 뿌린 뒤 Shuffle 없이 Join을 진행
- 따라서 Broadcast 되는 대상 테이블이 크다면 Driver의 메모리가 터질 수 있음
- Shuffle이 없으므로 네트워크를 통한 데이터 이동이 없어 Join 속도가 매우 빠름
Shuffle Join
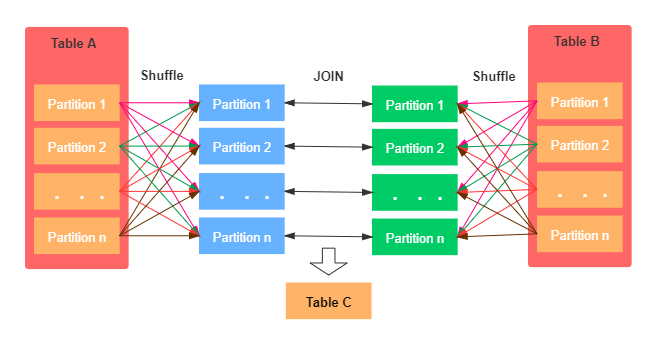
Shuffle을 이용한 Join은 데이터를 각 노드마다 이동 시키므로 네트워크 비용이 들어 속도가 느린 반면 큰 데이터까지 Join 가능
Hash Join
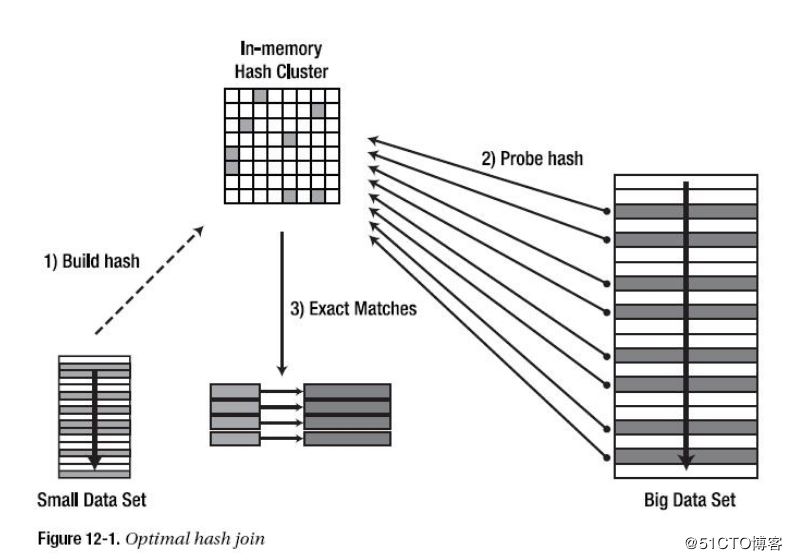
Hash Join은 작은 데이터 셋의 키를 조회하면서 자주 접근될 메모리에 Hash 셋을 만들고, 큰 테이블을 순회하면서 Hash 셋을 조회하면서 Join
Broadcast Hash Join
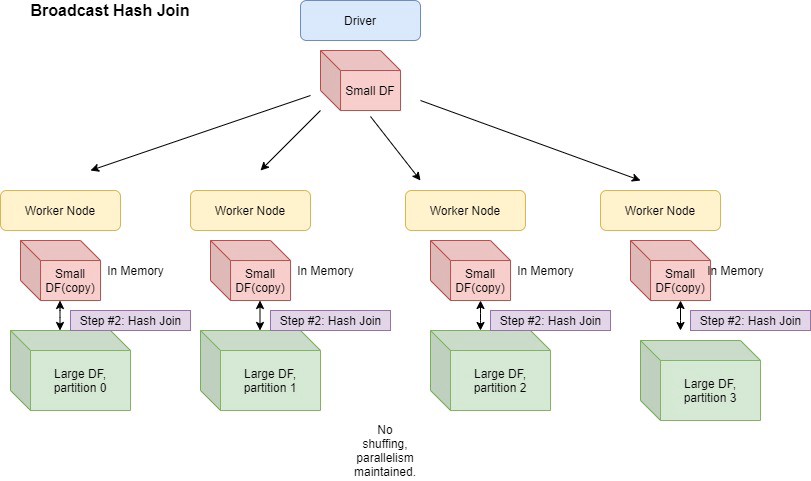
Broadcast Hash Join은 작은 데이터셋을 Broadcast 한 후에 Executor에서 Hash Join을 수행
- Broadcast Hash Join은 사용자가 Hint를 지정하거나, 지정하지 않았더라도 한쪽 테이블 사이즈가
spark.sql.autoBroadcastJoinThreshold = 10 MiB(Default) 보다 작으면 실행 - Broadcast될 대상 테이블이 클 경우 Driver를 거쳐서 Broadcasting 이 발생하므로 Driver OOM 또는 해시 테이블로 인한 Executor OOM이 발생할 수 있음
- 그러나 한쪽 데이터의 사이즈가 매우 작다면 Shuffle이 발생하지 않고 상대적으로 적은 양의 데이터만 Executor로 이동하면 되므로 네트워크 비용이 매우 저렴
Shuffle Hash Join
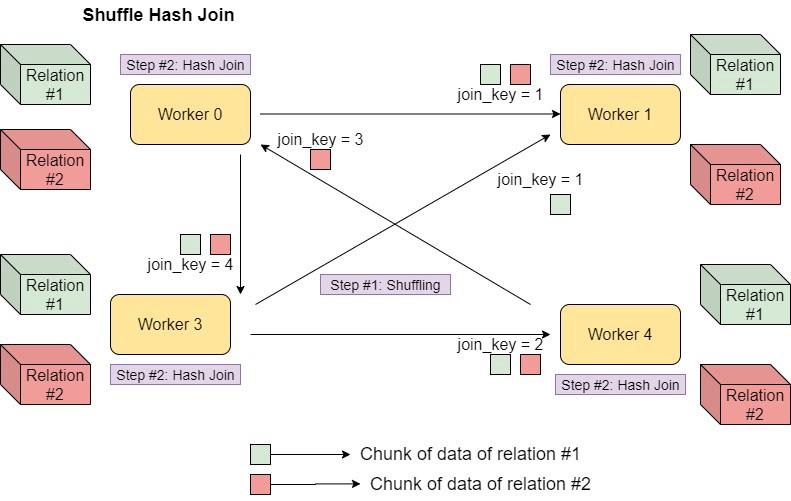
Shuffle Hash Join은 Shuffle을 발생시켜 데이터를 이동한 뒤 Hash Join을 수행
- 작은 쪽, 즉 메모리에 Hash 셋을 만들 테이블은
spark.sql.autoBroadcastJoinThreshold(10MiB, Default) *spark.sql.shuffle.partitions(200, Default) = 2GiB 보다 작아야 함- Spark 2.3부터 Shuffle Hash Join 대신 Shuffle Sort Merge Join이 기본 전략으로 세팅됨(
spark.sql.join.preferSortMergeJoin= true, Default)
- Spark 2.3부터 Shuffle Hash Join 대신 Shuffle Sort Merge Join이 기본 전략으로 세팅됨(
- Shuffle Hash Join은 큰 데이터셋을 다룰 수 있으나 Hash 셋을 빌드할 때 메모리에 올려야 하므로 너무 크다면 Executor OOM이 발생할 수 있음
Sort Merge Join
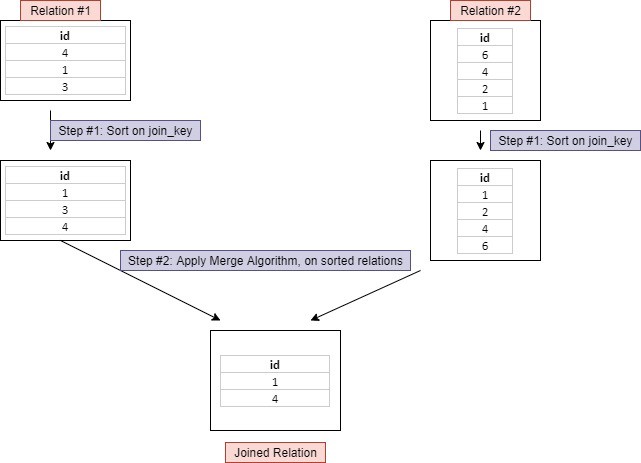
Shuffle Sort Merge Join
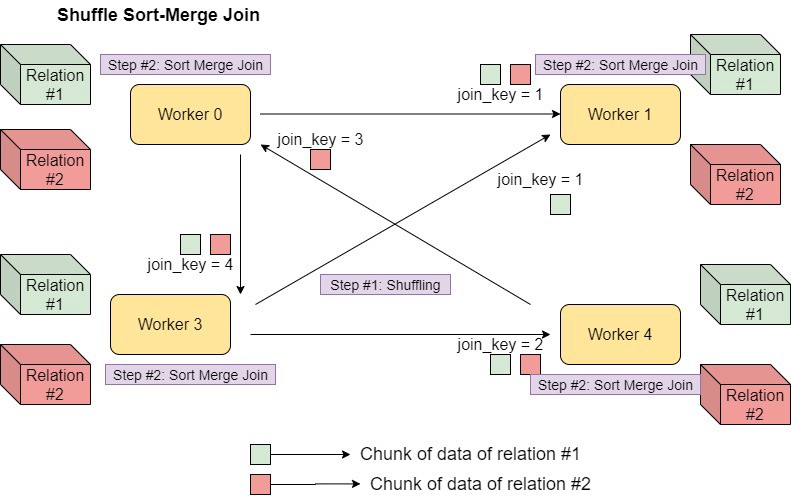
Shuffle Sort Merge Join은 데이터를 Shuffle 시켜 정렬(Sort)한 후 Join을 수행
- Spark 2.3부터
spark.sql.join.preferSortMergeJoin= true로 활성화 되어있어, 큰 데이터셋에 대해 주로 사용 - Join Key가 정렬 가능해야함
- Join 과정에서 Shuffle Hash Join과 달리 Memory가 아닌 Disk를 이용할 수 있기 때문에 OOM이 발생하지 않음
Broadcast Nested Loop Join
Broadcast Nested Loop Join은 선택할 수 있는 전략이 없을 경우 마지막으로 선택되는 Join 전략
작은 데이터셋을 Broadcast한 후 이중 반복문을 돌며 하나씩 데이터를 비교해 Join하는 방식
