러닝스푼즈 - Practical Spark 강의와 스파크 완벽 가이드 를 요약한 내용입니다.
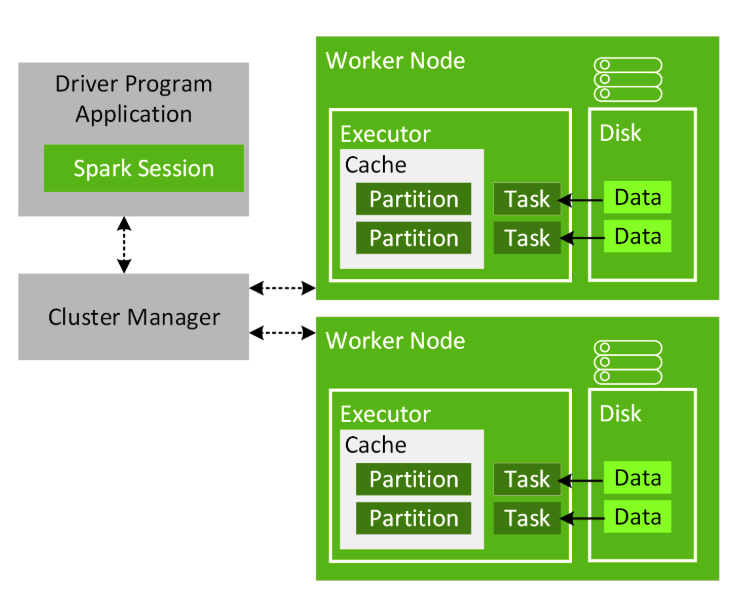
Cache
- Spark 데이터 가공을 빠르고 효율적으로 하기 위한 기능
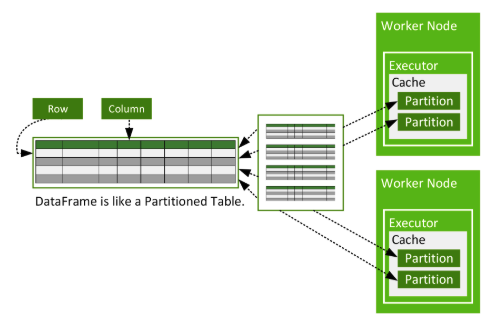
- Spark는 논리적인 수준에서 데이터를 파티션 단위로 나누어 처리
-
개별 Executor 내의 설정에 의해 허용된 메모리량 만큼 Partition 데이터를 캐싱하는 것이 가능
-
BlockManager에 의해 관리
-
만약 데이터가 메모리에 들어가기 충분하지 않으면 Disk를 사용할 수 있음
-
cache()함수는persist(storageLevel = MEMORY_AND_DISK)함수와 동일 (참고 : Storage Level )# 첫번째 Action df.count() # cache dfCached = spark.read.format("parquet").load("./airbnb_listings_parquet").cache() # 두번째 Action dfCached.count() dfCached.rdd.getNumPartitions() -
cache()함수 사용 시,-
Spark Executor 내에 분산되어 DataFrame이 저장
-
storageLevel = MEMORY_AND_DISK이므로 메모리가 부족할 경우 Disk를 사용할 수 있음
-
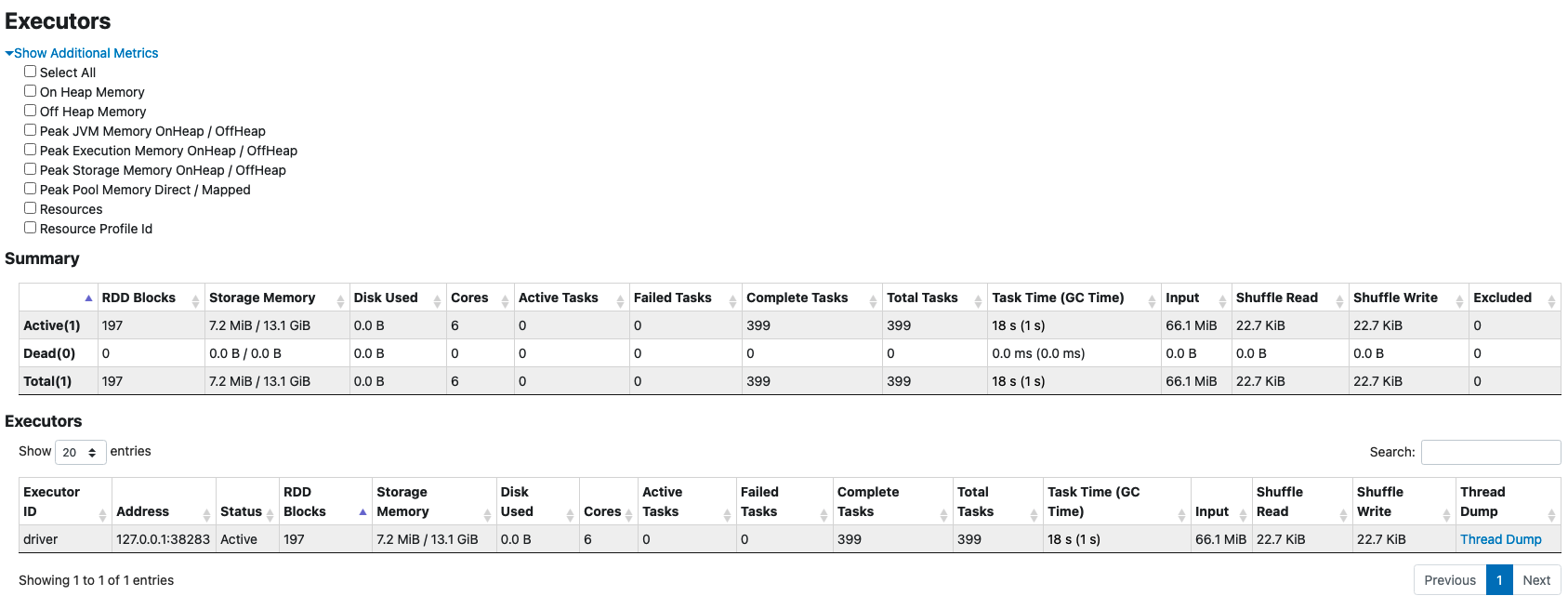
Executor 탭에서는 cache를 호출하기 이전에 비해 Storage Memory가 늘었음

-
Storage 탭에서는 197개 만큼의 Cached Partitions이 7.1MB 만큼 메모리에 존재(=파티션 숫자와 동일)
.png)
-
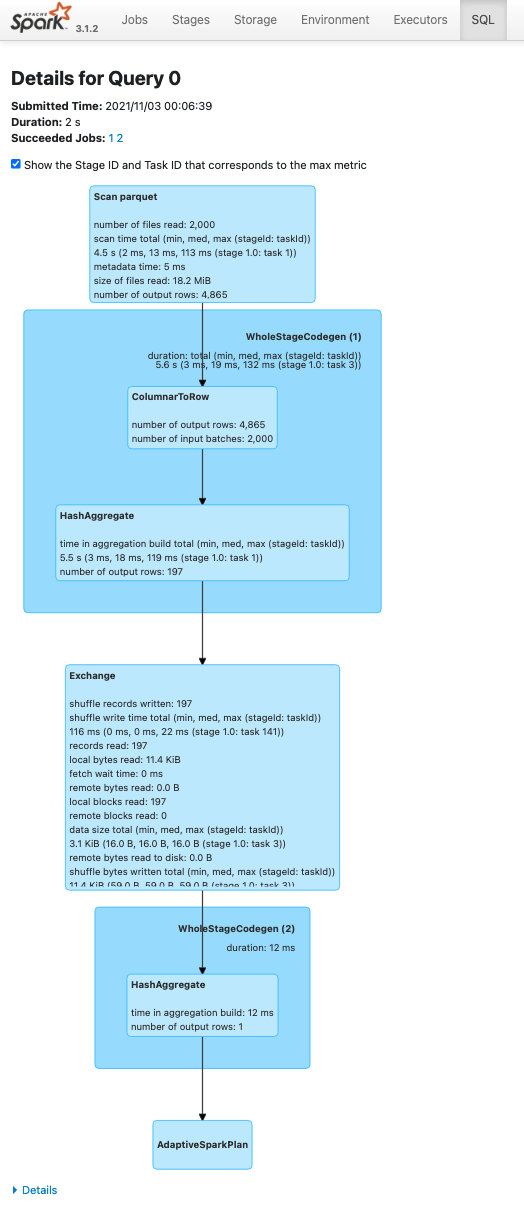
SQL 탭에서 나오는 두 개의 count() Action을 살펴보면 두번째 count() 호출, 즉 dfCached.count()에 InMemoryTableScan이라는 단계가 추가되었음
-
좌측의 Details for Query 0 은 cache() 를 호출하지 않은 df.count() 의 실행 계획이고, 우측의 Details for Query 1 은 cache() 를 호출한 dfCached() 의 실행 계획이라는 단계가 추가
-
하단의 Details 버튼을 누르거나 explain("FORMATTED") 를 통해 텍스트로 된 실행 계획을 확인 시
-
InMemoryTableScan 을 통해 데이터를 다시 Parquet 로 부터 읽지 않고 메모리에 캐싱된 영역에서 데이터를 읽어 집계
-
더이상 해당 데이터를 캐싱해서 사용하지 않는다면 unpersist() 함수를 통해 제거 가능
dfCached.unpersist() ```
-
Persistence
- Spark 는 다양한 형태의 파일을 읽어 DataFrame, 즉 테이블 형태의 논리적인 추상을 제공
- 수 많은 파일들을 묶어, 하나의 테이블처럼 사용 가능
- 대규모 처리가 필요할 경우 원하는 수준으로 Partition 을 분할해 복수 개의 Executor 에서 나누어 처리
- CSV 뿐만 아니라 JSON, Parquet, JDBC 등에서 데이터를 읽어 여러 DataFrame 을 만든뒤 Join 을 수행해 복합적인 데이터 가공 및 분석도 가능
CSV & JSON
# CSV 파일 읽기
dfListing = spark.read.load("./airbnb_listings.csv",
format="csv",
inferSchema=True,
header=True,
quote='"',
escape='"',
sep=',',
multiline=True)
# JSON 파일 읽기
dfListingJson = spark.read.format("json").load("./airbnb_listings")- Spark는 JSON 파일을 읽으면서 각 칼럼의 타입을 추론
- csv 파일을 읽을 때
inferSchema=True설정해주면 각 칼럼의 타입을 추론
- csv 파일을 읽을 때
- 칼럼 타입을 정하려면 각 칼럼 별로 전체 값을 읽어야 함
- 따라서 파일이 매우 크고 이미 타입을 알고 있다면 추론을 Spark가 하는 대신
primitivesAsString값을 이용해 String으로 값을 세팅하고cast()등의 함수를 이용해 직접 타입을 지정하면 추론에 들어가는 시간을 줄일 수있음
Parquet, ORC - Columnar Format
- 데이터를 빠르게 가공하기 위해선 CPU, Memory와 같은 리소스와 Spark같은 분산 처리 프레임워크도 중요하지만, 데이터가 어디에 어떻게 저장되어 있는지도 매우 중요
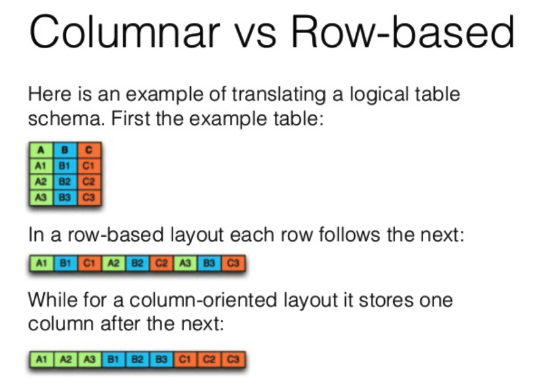
Parquet의 장점
- 압축률이 좋음
- 칼럼 단위로 구성하면 데이터가 균일하므로 압축률이 높아 파일의 크기가 작음
- 디스크 I/O가 적음
- 칼럼 단위로 데이터가 저장되어 필요한 칼럼만 읽음
- 선택하지 않은 칼럼의 데이터는 디스크에서 읽지 않기 때문에 디스크 I/O가 적음
- 칼럼 별로 적합한 인코딩 사용
- 각 칼럼의 데이터들은 동일한 타입의 데이터를 저장하기 때문에 칼럼마다 데이터 타입에 유리한 인코딩을 사용할 수 있음
- (Column Pruning) 대부분의 경우, 데이터는 몇몇 칼럼 단위로 이용되므로
SELECT a, b칼럼 기준으로 데이터를 읽을 수 있다면 I/O 등 물리 비용을 줄일 수 있음 - (Column Encoding) 칼럼 중심으로 데이터를 저장할 경우 타입에 특화된 인코딩을 통해 저장 공간을 줄일 수 있음
- (Predicate PushDown) 데이터를 Spark로 가져오기 전 미리 필터링이 가능해 네트워크 비용을 포함한 데이터 가공 비용을 크게 줄일 수 있음
- 컴퓨팅 프레임워크 구현에 따라 벡터화된 연산이 가능
- 한 번에 한 Row 만 연산을 수행하는 것이 아니라 다수의 Row를 묶어 덧셈을 수행하는 등 묶음 연산을 통해 컴퓨팅 시간을 줄일 수 있음
- Spark, Hive 에서는 Parquet를 통한 벡터화 연산을 지원
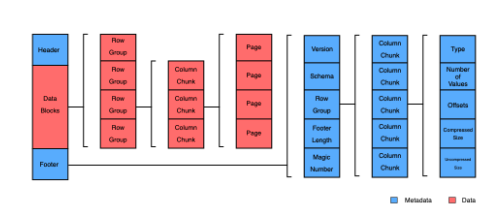
Parquet 파일 포맷으로 데이터를 저장하면, 내부적으로는 Row를 묶어 Row Group을 만들어 저장
Row Group 내의 각 칼럼 별로 통계치를 가질 수 있음
- Column Pruning(혹은 Projection Pushdown) 을 이용해 필요한 칼럼 값만 뽑아내고
- Predicate Pushdown을 이용해 Row 그룹 내 값을 미리 필터링 할 수 있음
- WHERE A < 2 라는 조건이 있다면, Row Group 2번은 읽지 않을 수 있음
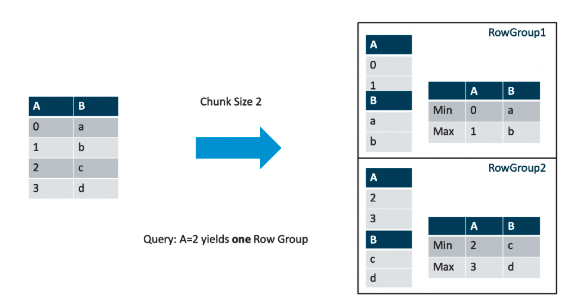
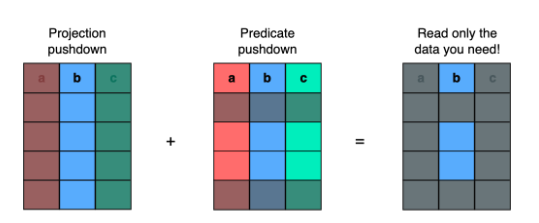
- WHERE A < 2 라는 조건이 있다면, Row Group 2번은 읽지 않을 수 있음
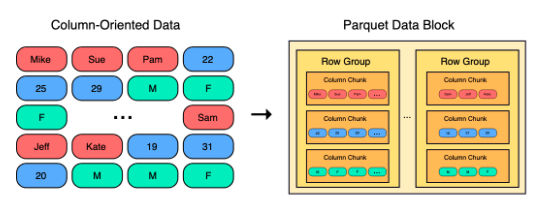
- 하나의 Row Group 내에는 Column Chunk가 여러 개 존재하며, Column Chunk는 다시 여러 개의 Page로 구성
- Parquet는 파일의 Footer Metadata 내에 칼럼의 통계 정보를 가지고 있음
# Parquet 파일 읽기
dfListingParquet = spark.read.format("parquet").load("./airbnb_listings")Avro - Data Serialization
- Apache Avro는 데이터 직렬화 도구
- JSON을 전송하고 받아서 사용하는 것에 비해 Avro, Protobuf, Thrift와 같은 중립적인 데이터 직렬화 시스템을 사용하는데는 몇가지 이유가 있음
- 언어 중립적이므로 어떤 언어를 사용하는지 상관없이 직렬화 도구가 지원한다면 다양한 언어로 데이터를 읽고 쓸 수 있음 (e.g, Kafka Producer & Consumer)
- 스키마를 미리 정의하고 사용하므로 실수로 변경될 부분을 방지하고 미래의 변경도 기존 소비자 (Consumer 등) 를 위한 스키마 호환을 (Avro Schema Evoluation) 지원
- 타입이 정해져 있으므로 Encoding 을 통한 사이즈 축소 및 효율적인 조회 (Columnar 의 경우 Colume Pruning, Predicate Pushdown 등) 이 가능
- Thrift, ProtoBuf (gRPC) 와 같은 프레임워크는 RPC API 를 제공
많은 경우에 다음과 같이 사용
- S3, HDFS 등에 저장된 대규모의 읽기를 위한 데이터는 Parquet, ORC 등 읽기 및 압축 효율이 좋은 Columnar 포맷을 사용
- 읽기가 빈번하고 사이즈가 매우 커질 수 있기 때문
- Kafka / API 등 실시간으로 데이터를 주고 받는 경우에는 Avro 처럼 Schema 관리가 편리하거나 (Registry 등 도구 제공) Protobuf w/ gRPC 처럼 통신을 위한 라이브러리가 지원되는 포맷을 활용하는 경우가 많음
단점
- 멀쩡한 데이터를 Header (Schema / Meta) + Payload (Data) 로 변경하고 인코딩을 수행해야 하므로 CPU 리소스를 사용
- 다만 사이즈는 작아질 수 있기에 네트워크 비용에서 이점을 볼 수 있음
Avro 를 사용하기 위해서는
- Data Serialization 포맷은 IDL (Interface Definition Language) 이라 불리는 스키마 파일을 작성
- Protobuf / Thrift / Avro 의 경우에는 IDL 을 바탕으로 코드를 생성
Avro 의 경우에는 다른 프레임워크와 다르게, Data 자체에 Schema 를 포함
- 따라서 코드 생성을 통해 빌드 타임에 데이터 클래스를 생성할 수 있지만 (Avro SpecificRecord)
- 런타임에도 Deserialization 을 수행
- 다만 런타임에 예외가 발생할 수 있음 (Avro GenericRecord)
- 피치 못한 경우가 아니라면 빌드 타임에 데이터 클래스를 생성해 사용하는 편이 좋음
Avro 는 주로 Kafka 와 함께 활용
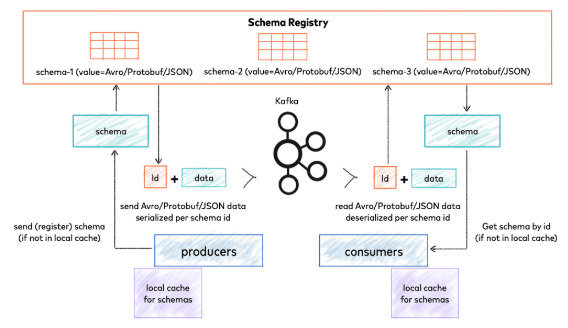
- Avro 로 Serialized 된 데이터를 Kafka Broker 로 직접 보내고 읽을 수 있음
- 만약 Schema Registry 를 이용하면 업타임에 Producer / Consumer 에서 스키마를 등록하거나 받아올 수 있음
- Confluent Schema Registry 의 경우 Avro 뿐만 아니라 Protobuf, JSON 형식의 스키마도 지원
JDBC(MySQL, Postgres 등)
- Generic Load / Save 함수를 이용하면 JDBC드라이버를 이용해 MySQL과 같은 RDB에 데이터를 넣을 수 있음
- Spark가 쓸 수 있도록 JDBC Driver를 Spark Class Path에 추가해주어야 함
JDBC Write 설정
mode- 기존 File을 write하는 것과 매우 다르게 동작
- overwrite를 사용하면 기본 설정으로는 Table을 Drop하고 DataFrame의 Schema를 기반으로 테이블을 다시 생성
- 따라서 Index 등 중요한 설정 정보가 삭제될 수 있어서 매우 유의해 사용
truncate = Truemode = overwrite라 하더라도 테이블은 삭제하지 않고 데이터만 삭제- 그러나 여전히 데이터가 통채로 삭제될 수 있어 서비스 중인 DB에서는 문제가 될 수 있음
numPartitions- 이 값은 JDBC 커넥션 숫자로, repartition(3)이고 numpartitions(2)인 경우 coalesce(2 = numPartitions)를 통해서 파티션 숫자를 줄인 후 Executor 마다 JDBC Connection 1개 씩을 할당해 Write
- 일반적으로
mode = append를 이용하고 Update나 Upsert가 필요한 경우 다른 방식으로 구현- foreach 내 직접 Statement 실행 등
JDBC Read 설정
partitionColumn- 명시된 칼럼을 이용해 numPartitions 숫자만큼 분산처리 가능
lowerBound,uppserBound는 각 파티션 당 얼마나 많은 데이터를 가져올지 분할량(파티셔닝)을 결정- 칼럼 타입은 RA numeric(숫자), date, timestamp 값만 가능
customSchema- 칼럼별 스키마를 지정
- Spark는 RDB스키마를 Spark 호환 타입으로 변경하나, 일부 지원되지 않는 타입이나 잘못 변경될 경우
customSchema옵션을 이용하거나 직접 DataFrame에서cast()함수를 사용
fetchsize- 너무 작으면 여러번 네트워크 통신이 필요하고 너무 많으면 DB에 부하가 갈 수 있음
