러닝스푼즈 - Practical Spark 강의와 스파크 완벽 가이드 를 요약한 내용입니다.
Spark를 사용하여
- 데이터를 다양한 저장소(eg. Kafka, MySQL 등)에서 원하는 Format(eg.CSV, Avro, Parquet 등) 으로 읽기
- 데이터를 다른 데이터와 합치거나 필터링 및 선택
- 데이터를 집계 (GROUP BY AGG)
- 가공한 데이터를 다양한 저장소에 원하는 Format 으로 저장
가 가능한데, 이러한 작업들을 할 때 Spark의 내부 동작 과정이 발생
Transformation과 Action
- Spark의 DataFrame / SQL / DataSet API를 사용할 때, 내부적으로 RDD로 코드가 생성되어 실행
- RDD의 동작은 크게 Transformation과 Action으로 구분
- Spark의 핵심 데이터 구조는 불변성(Immutable) 을 가져 한 번 생성하면 변경 불가
- '변경'하려면 원하는 변경 방법을 Spark에 알려줘야 하는데, 이 때 사용하는 명령이 Transformation
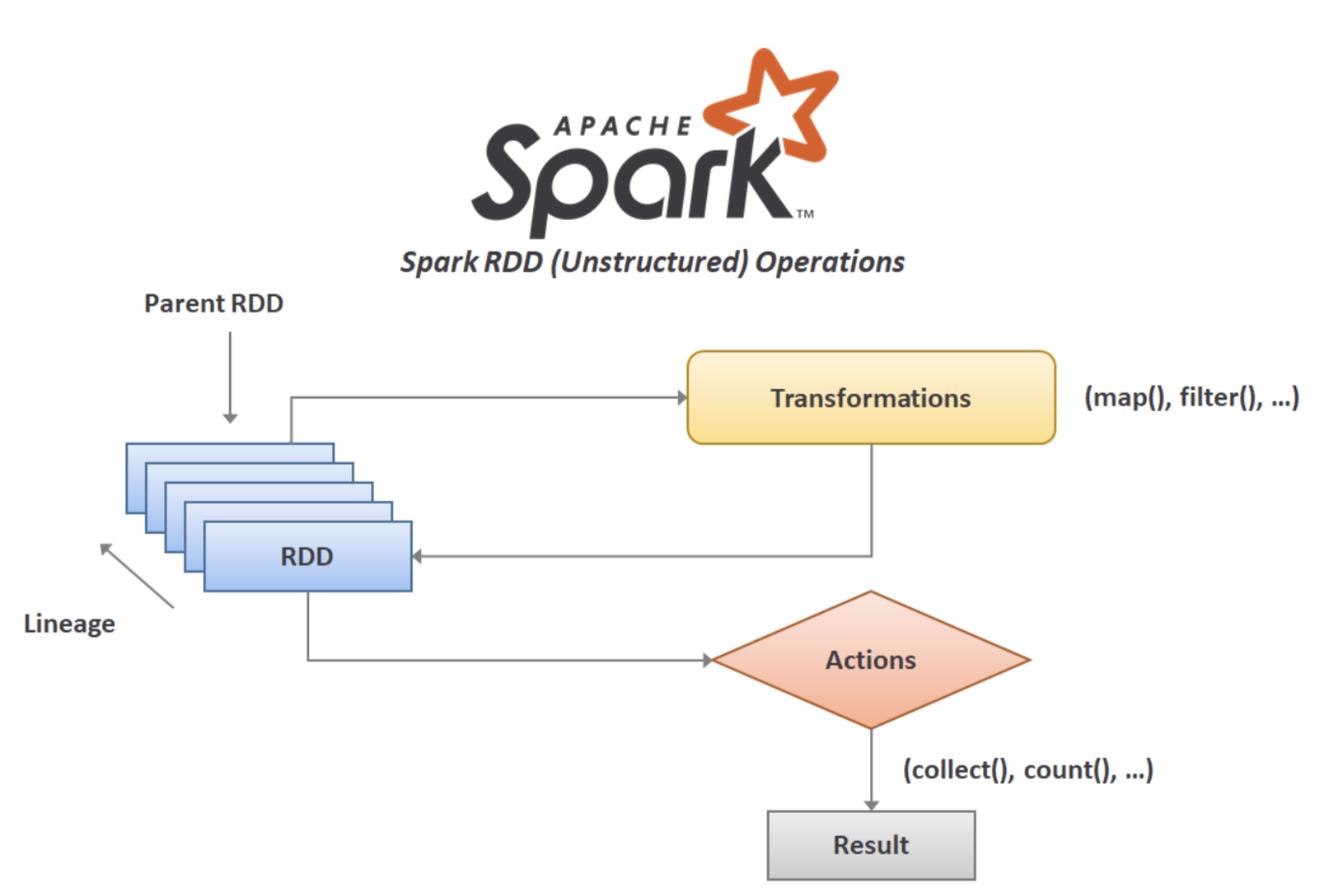
filter(),map()등 다양한 Transformation을 적용하는 것을 반복count()와 같은 Action을 호출해 결과를 만들어 내는데 이를 지연연산(Lazy Evaluation)이라 함
지연연산(Lazy Evaluation)은 Spark가 연산 그래프를 처리하기 직전까지 기다리는 동작 방식을 의미한다. 특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고, 적용할 Transformation 의 실행 계획을 생성하고 그것을 기반으로 분석하고 최적화 한 뒤 실제 데이터 처리를 물리적으로 실행한다.
explain()함수를 통해 Spark DataFrame의 실행계획을 확인할 수 있다.
- Transformation이 누적되면서 데이터를 어떻게 가공할 지가 DataFrame의 실행 계획으로 기록
- 사용자는 최종 시점에 여태까지 작업했던 데이터에 대한 어떠한 행동을 취하는데, 이 때 사용하는 명령이 Action
- Action을 실행하는 순간 이제까지 명령을 내렸던 Transformation이 적용
Optimization
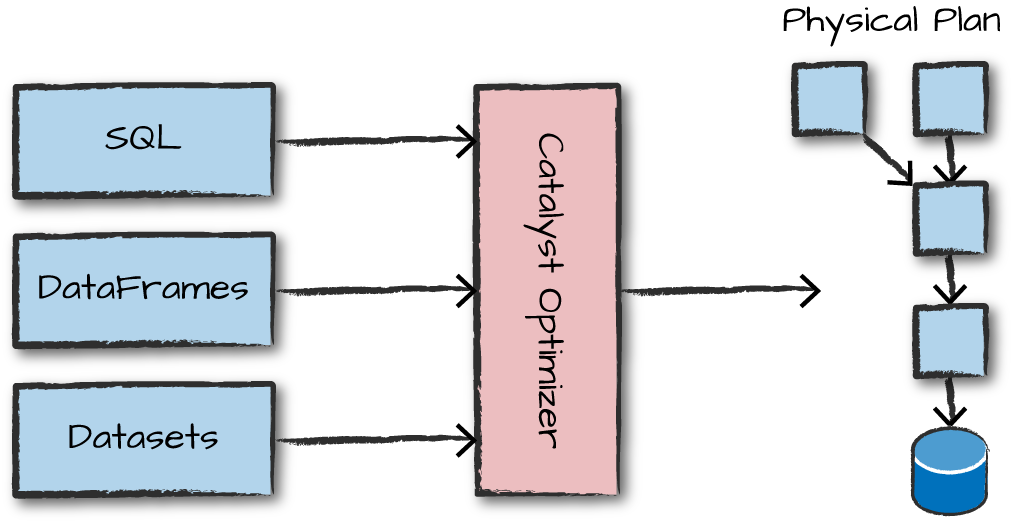
Spark는 DataFrame / SQL / DataSet API를 Catalyst Optimizer를 통해 최적화하고 최종적으로 RDD를 위한 코드를 생성
-
DataFrame/Dataset/SQL을 이용해 코드를 작성
-
스파크가 논리적 실행 계획(Logical plan)으로 변환
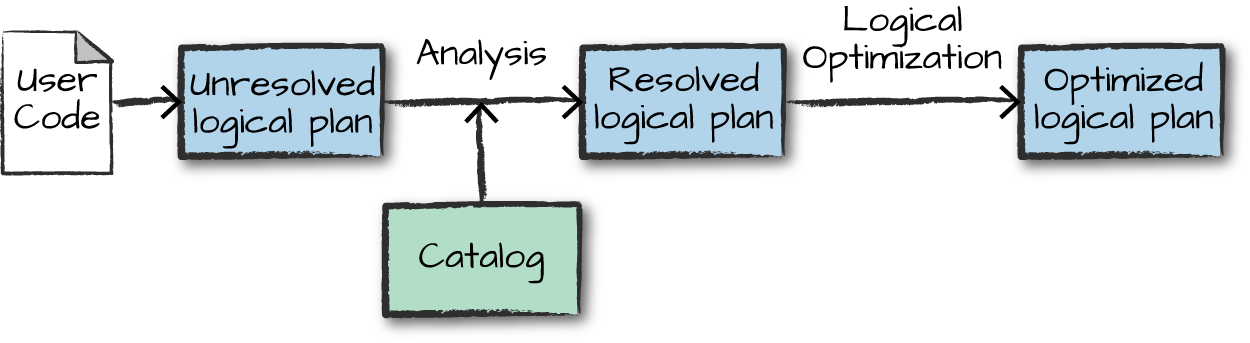
- 물리 정보(Driver나 Executor 정보)를 고려하지 않은 추상적 트랜스포메이션 Phase
- 사용자 코드를 검증 전 논리적 실행 계획(unresolved logical plan) 으로 변환하며 코드 유효셩 및 컬럼 존재 여부 등 판단
- 분석기(analyzer)는 검증을 위해 카탈로그, 테이블 저장소, DataFrame 정보를 활용
- 테이블과 컬럼에 대한 검증 결과는 카탈리스트 옵티마이저(Catalyst Optimizer)로 전달
- 카탈리스트 옵티마이저는 조건절 푸쉬 다운(predicate pushing down)이나 선택절 구문을 이용해 논리적 실행 계획을 최적화하는 규칙을 모음
-
논리적 실행 계획을 물리적 실행 계획(Physical plan)으로 변환하며 최적화
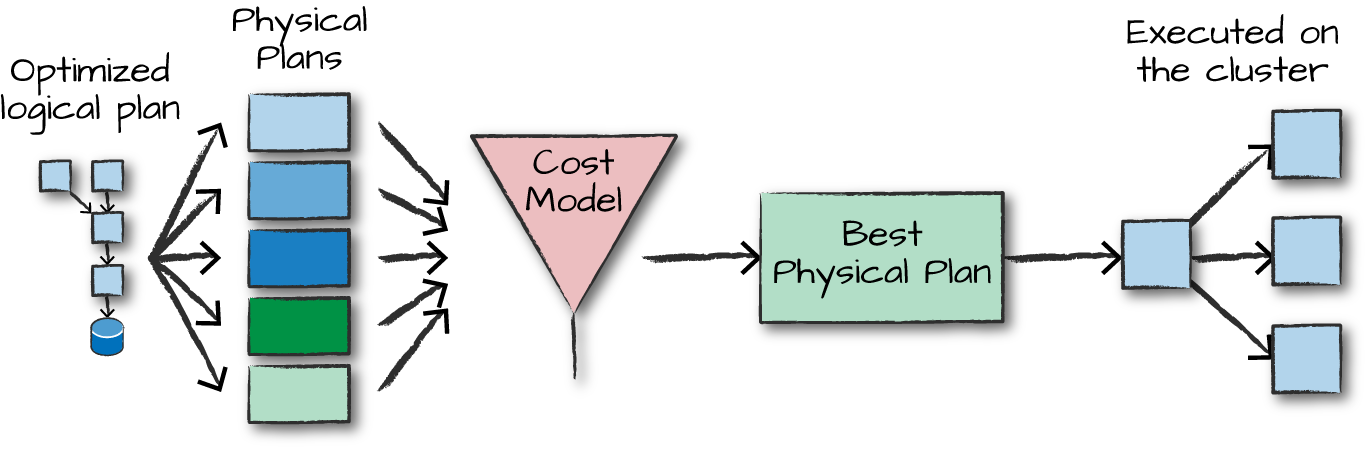
- 논리적 실행 계획을 클러스터 환경에서 실행하는 방법을 정의
- 예를 들어 Logical Plan 에서는 Join 이라고 표시 되었지만 Physical Plan 에서는 Sort-merge Join 을 사용한다는 정보가 표시
- 다양한 실행 전략을 생성하고 비용 모델을 통해 비교 후 최적의 전략을 선택
df.explain("cost"),df.explain("codegen")을 통해 비용 확인 가능
- 물리적 실행 계획은 구조적 API(DataFrame, Dataset, SQL)를 일련의 RDD와 트랜스포메이션으로 변환
- 논리적 실행 계획을 클러스터 환경에서 실행하는 방법을 정의
-
클러스터에서 물리적 실행 계획(RDD 처리)을 실행
Partition
- 일반적으로 Spark는 단일 머신에서 처리하기 어려운 큰 사이즈의 데이터를 사용
- 사용자는 DataFrame 같은 추상화된 API를 통해 데이터를 ‘하나’처럼 다룸
- 그러나 Spark는 데이터를 분할해 Partition 단위로 처리
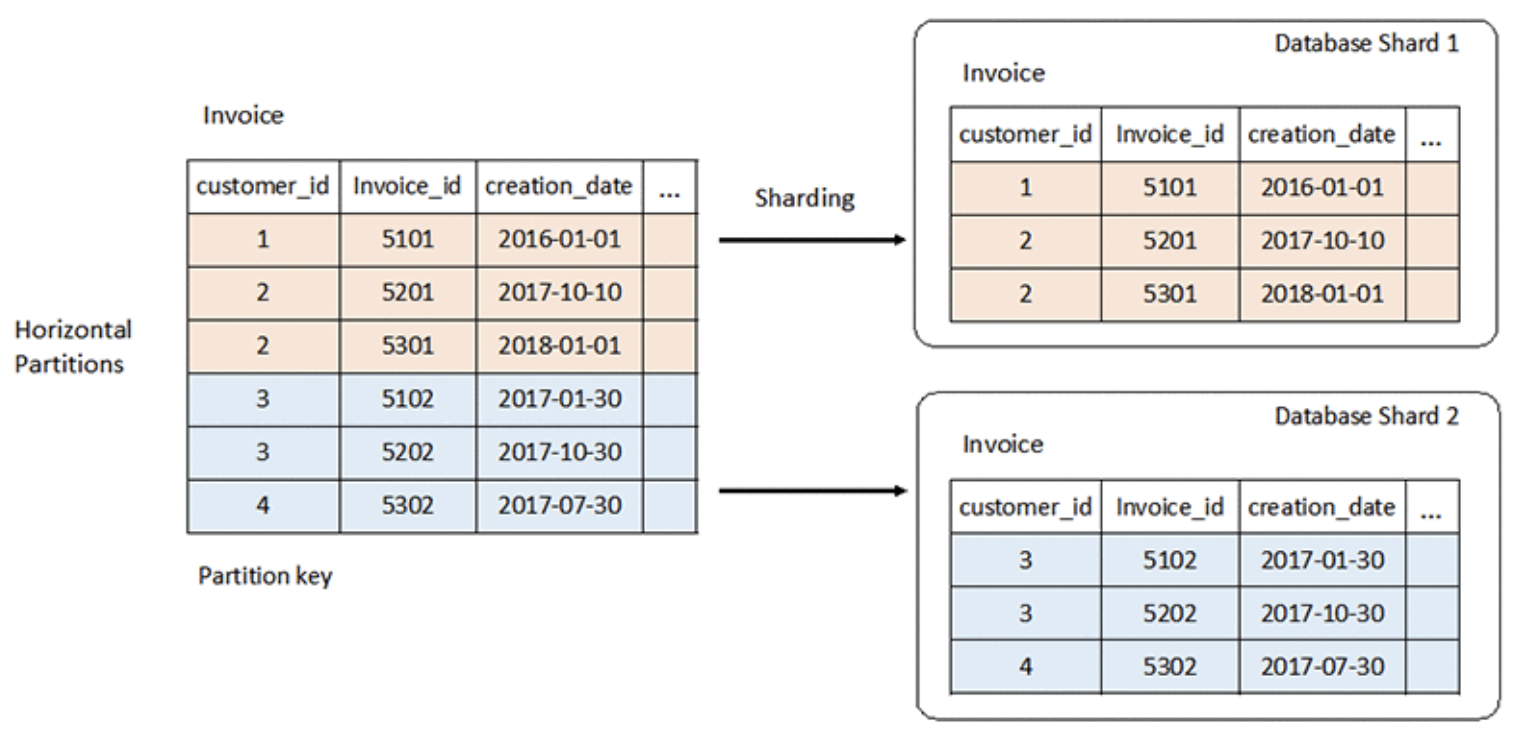
이미지 출처 - Spark에서 데이터를 잘게 쪼개서 Partition이 많다면 Executor가 많을 경우 동시에 여러 Executor에서 처리가 될 수 있으므로 빠르지만, Executor 숫자가 적다면 Partition을 아무리 잘게 쪼개도 병렬 처리가 불가능하므로 급격한 성능 향상을 보기 어려움
Partition 관련 설정들
spark.default.paralleism: 주로 spark-default.conf에 세팅되어 초기값으로 사용spark.sql.shuffle.partitions:DataFrame.repartition()에서 지정된 숫자가 없을 경우나 Join 이나 Aggregation 등 Shuffle이 발생할 경우 사용spark.sql.files.maxPartitionBytes,spark.sql.files.minPartitionNum: 파일을 읽을 때 파일 사이즈를 기반으로 파티션 숫자를 동적으로 계산하기 위해 사용
DataFrame의 Partition을 변경하는 함수
DataFrame.repatition()은 Partition 을 늘리고 줄일 수 있지만 이 경우 전체 데이터, 즉 전체 Partition 대해 균등하게 배분하기 위해 재배치가 (relocation) 이 발생- 이 과정에서 머신 간 데이터의 이동이 발생하며 이는 비용이 매우 비싼 네트워크 연산
DataFrame.coalesce()는 Partition 을 현재 숫자 이하로만 줄이는 것이 가능DataFrame.repartition()과 달리 줄이는 과정에서 만약 옮길 필요가 없는 데이터가 있다면 옮기지 않아서 비싼 네트워크 연산을 피할 수 있음
repartition()을 호출하는 경우
- DataFrame 을 가공하는 과정에서 데이터의 불균형 (Skew) 이 발생할 수 있음
- 데이터 가공 후 특정 Partition 데이터만 많이 남아있다면 분산 처리를 한다 해도 특정 Partition 데이터의 양이 많아 상대적으로 늦게 끝날 수 있음
- 가공하는 과정에서 충분한 필터링으로 인해 데이터의 양이 줄었을 경우 Partition 을 줄일 수 있음
- 반대로, DataFrame 을 가공하는 과정에서 Join, Union 등 을 통해 추가적으로 데이터가 늘었을 경우 Partition 을 늘릴 수 있음
- 실제 데이터 가공 시에는 사용자 ID 기준, 상품 ID 기준 등 특정 데이터를 기준으로
Group By,window function등을 수행하는 경우가 많으며, 이로인해 잦은 데이터의 이동이 발생할 수 있음 - 따라서 Column 기준으로
Dataframe.repartition()을 작업 해놓고, 이후 Transformation 에서 해당 Column 을 기준으로 연산을 수행한다면 추가적인 데이터의 이동을 줄일 수 있음
df.repartition(col('id'))Shuffle
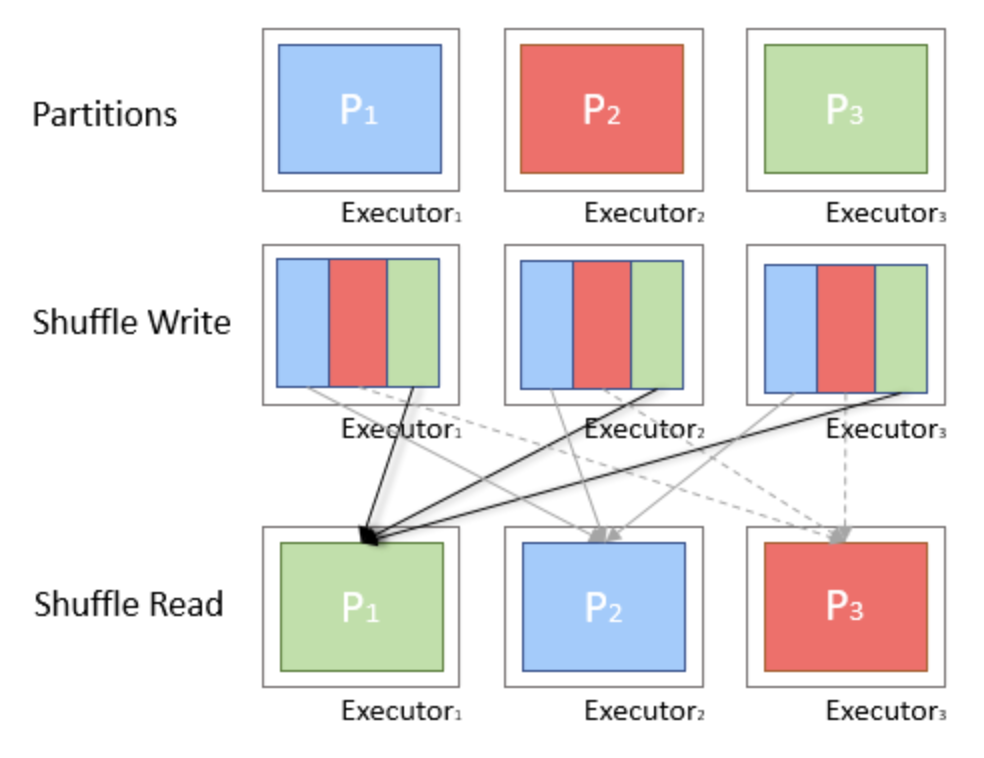
- Shuffle은 특정 연산을 수행하기 위해 여러 Partition 내의 데이터가 그룹화되어 다른 Partition 들로 이동하는 것
- 이 과정에서 어떤 데이터를 이동해야 할지 모르므로 전체 데이터에 대한 탐색이 필요할 수 있음
- 또한 데이터를 그룹화하기 위해 특정 파티션을 담당하는 머신으로의 데이터 전송이 발생할 수 있으므로 Disk IO, 데이터 직렬화 / 네트워크 IO 등 많은 비용이 발생
- Shuffle 로 인해 Memory / Disk / Network 등 많은 자원이 소모하므로 Shuffle 을 적게, 필요한 만큼만 수행해 자원을 덜 소모하고 실행 시간도 짧아지도록 하는게 중요
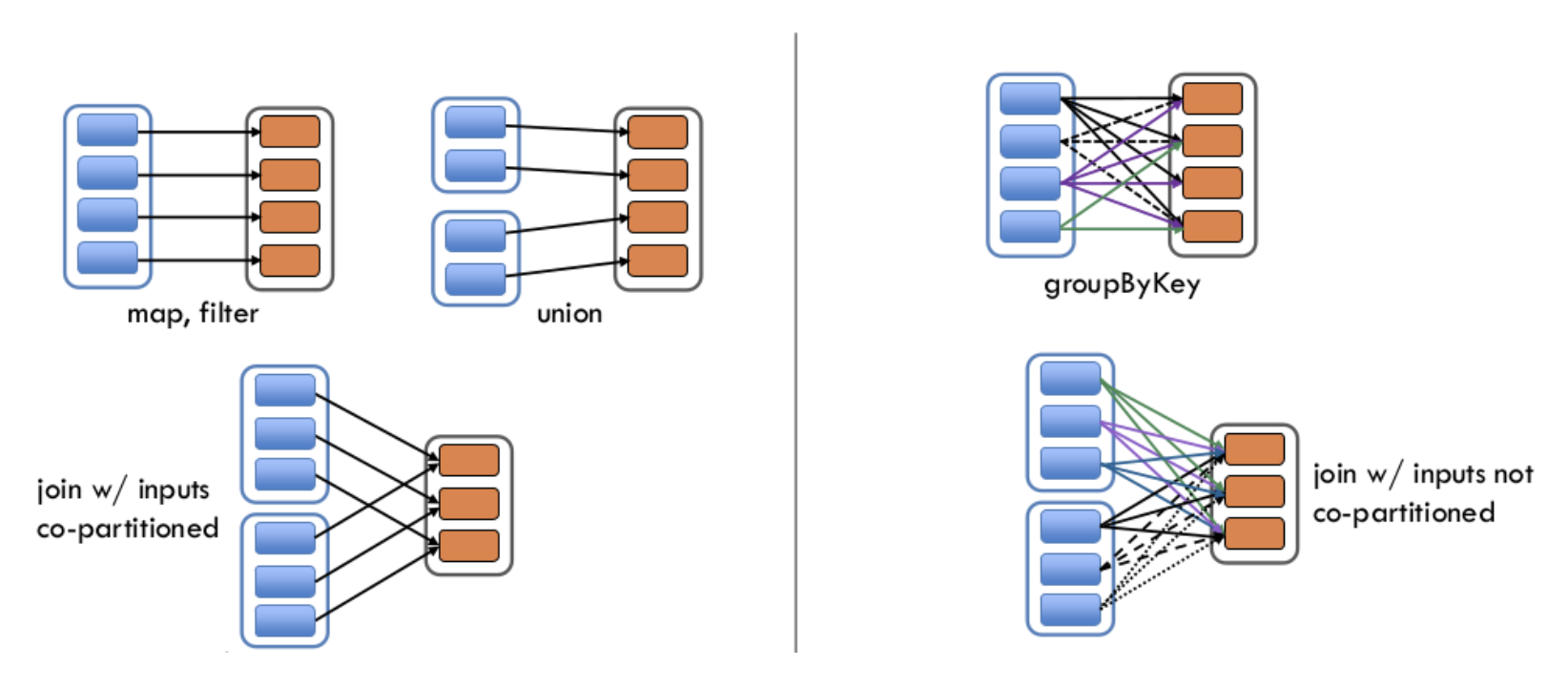
트랜스포메이션에는 두 가지 유형이 존재
- 좁은 의존성(Narrow dependency)
- 좁은 의존성을 가진 Transformation은 각 입력 Partition이 하나의 출력 Partition에만 영향을 미침
- 즉 데이터의 이동이 필요없는, Shuffle이 발생하지 않는 Transformation으로
map,filter,union등이 여기에 해당- 넓은 의존성(Wide dependency)
- 넓은 의존성을 가진 Transformation은 하나의 입력 Partition이 여러 출력 Partion에 영향을 미침
group by distinct count처럼 특정 키를 기준으로 데이터를 모은 후 집계하는 경우
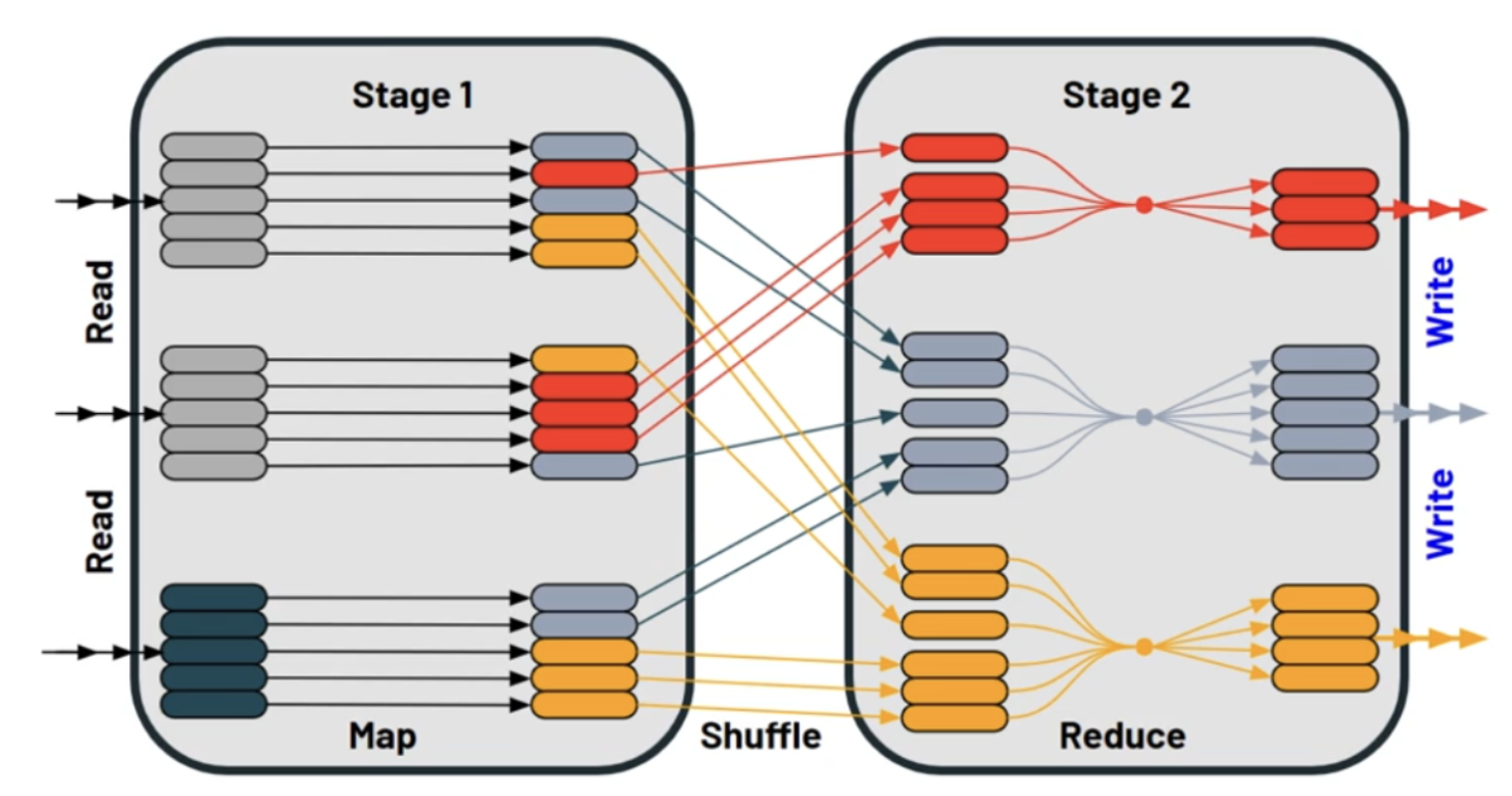
- Spark 에서 RDD Operation 은 물리적 실행 단위인 Task 로 변환되는데, Task 의 묶음이 Stage
- Stage 를 구분하는 기준이 바로 Wide Transformation 인 Shuffle
- 한 Stage 내에서 Task 는 병렬로 실행될 수 있으나, Stage 는 Shuffle 로 구분되고 이 Shuffle 은 데이터 이동을 전제로 하기 때문에 다음 Stage 가 시작되기 위해서는 이전 Stage 가 종료가 되어야 함

# data engineering