러닝스푼즈 - Practical Spark 강의와 스파크 완벽 가이드 를 요약한 내용입니다.
- 한 대의 컴퓨터는 대규모 정보를 연산할 만큼 자원이나 성능을 가지지 못함
- 클러스터는 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있도록 해줌
- Cluster Manager는 다수의 Spark 작업을 실행할 수 있도록 리소스를 관리해주는 Hadoop, AWS EMR의 YARN 혹은 Kubernetes와 같은 클러스터를 말함
- 사용자는 Cluster Manager에 Spark Application을 submit 하고, 이를 제출받은 Cluster Manager는 Application 실행에 필요한 자원을 할당하며 우리는 할당받은 자원으로 작업을 처리
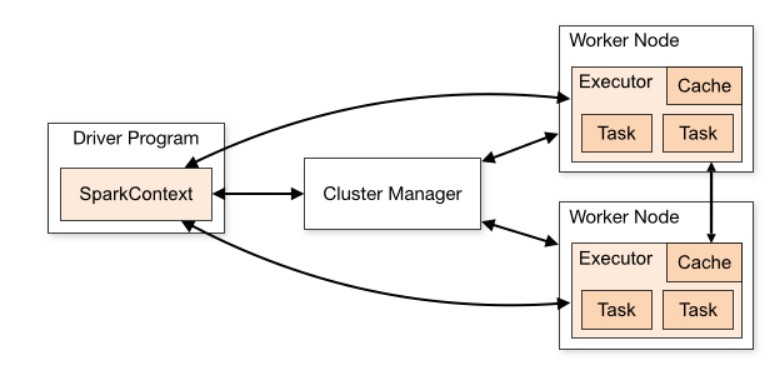
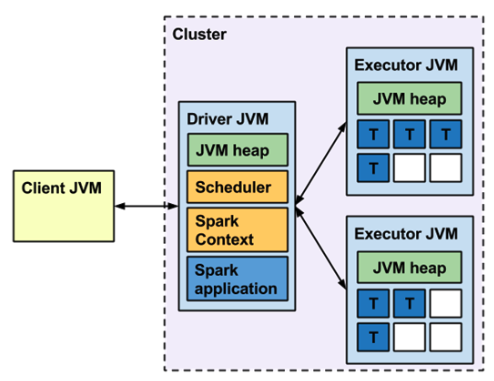
- Spark Application은 Driver 프로세스와 다수의 Executor 프로세스로 구성
Driver
- Spark Application 정보의 유지 관리, 사용자 프로그램이나 입력에 대한 응답, 전반적인 Executor 프로세스의 작업과 관련된 분석, 배포 그리고 스케줄링 역할을 수행
- Driver는 1개로 사용자의 Main 함수, 사용자가 작성한 로직을 실행
- 이 과정에서 실행 계획을 생성해 Executor에게 Task를 할당
- Driver는 Cluster Manager와 통신하며 Spark Application을 관리
- Executor는 여러 개가 가능, 분산처리를 위해 Driver가 요청한 Task를 수행하고 결과는 Action에 따라(
collect,foreachPartition) Driver로 다시 돌려 보낼 수 있음 - Executor는 사용자가
cache()와 같은 함수 호출 시 데이터를 메모리(또는 디스크)에 저장할 수 있음 - Driver는 다음과 같은 설정을 통해 리소스를 조절할 수 있음
spark.driver.core # Driver에서 사용할 CPU Core 숫자
spark.driver.memory # Driver에서 사용할 메모리 GBExecutor
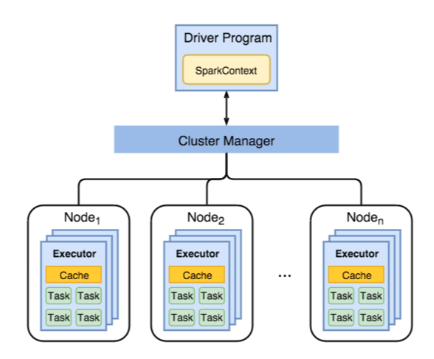
- Driver에서 요청한 작업을 분산 처리 하거나
cache()로 데이터를 분산 저장한 값을 들고 있음 - 사용자 요청에 따라 다음과 같은 설정을 통해 갯수와 리소스를 조절할 수 있음
spark.executor.instances # 하나의 Spark 작업에서 사용할 Executor 수
spark.executor.core # 개별 Executor에서 사용할 CPU Core 수
spark.executor.memory # 개별 Executor에서 사용할 Memory GB
spark.scheduler.maxRegisteredResourcesWaitingTime = 30s #default
spark.scheduler.minRegisteredResourcesRatio = 0.8 # for Kubernetes, Yarn- Driver는 Executor가 기다리기 위해 위에 지정한 옵션만큼 대기
- 80%의 Executor가 사용할 수 있는 상태가 되기까지 기다리거나,
- 30초가 넘을 경우 Task를 할당
- Executor가 준비가 되었을 때 Task를 할당해, 데이터가 특정 Executor로 초기에 몰리는 것을 방지
Cluster Manager
- Cluster Manager는 Spark가 실행될 수 있는 리소스를 제공
- Driver를 통해 Spark가 Cluster Manager에 연결되면 Executor 실행에 필요한 리소스를 얻어올 수 있음
- 다양한 Cluster Manager를 지원
- Standalone
- Apache Mesos
- Hadoop Yarn
- Kubernetes
Mode
- Spark는 사용자의 환경에 맞추어 여러가지 실행 모드를 지원
- 실행위치 기준
- Local
- 현재 머신에서만 Spark를 실행(분산 처리 X)
- 개발 및 테스트 용도로 사용
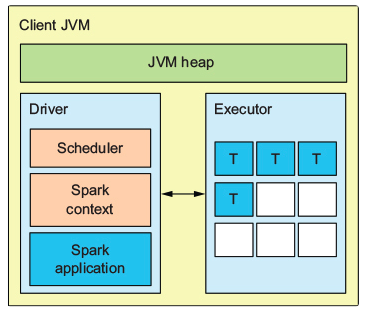
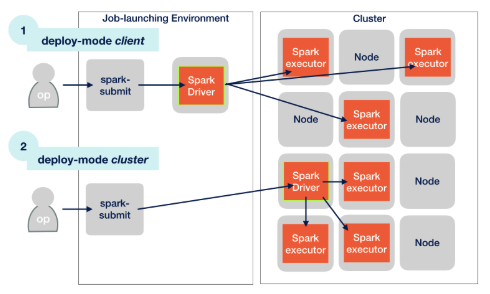
- Client
- 작업 요청은 사용자가 Submit 명령을 실행하는 위치에서 발생
- Driver 또한 Submit이 요청된 위치에서 동작
- 한 머신에서 여러 개의 Spark Application을 실행하는 경우, 수 많은 Driver로 인해 Submit을 요청하는 머신의 리소스가 부족할 수 있음
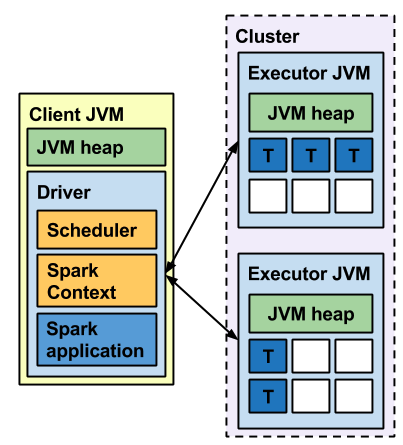
- Cluster
- Driver가 Cluster에서 동작
- 요청과 실제 Dirver가 분리
- Local
- 실행위치 기준

# data engineering