PostgresSQL InternalError_: variable not found in subplan target list와 Vacuum

to 개발팀 from sentry
InternalError_: variable not found in subplan target list
지난 주, 운영 백오피스 서비스에서 발생한 에러와 이를 해결하는 과정에서 새롭게 알게된 내용을 공유하려고 합니다. sentry를 통해 확인된 에러 메시지는 아래와 같습니다.
InternalError_: variable not found in subplan target list
File "django/db/backends/utils.py", line 84, in _execute
return self.cursor.execute(sql, params)
InternalError: variable not found in subplan target list쿼리 단계에서 발생한 에러였고, PostgreSQL 내부에서 발생한 에러로 에러 트래킹이 쉽지 않았습니다. 에러의 원인 지점을 찾아 실행하는 쿼리를 확인해보니, 테이블 전체 행의 개수를 가져오는 COUNT 쿼리인 것을 확인했습니다. 해당 쿼리를 실제 DB Shell에서 동일하게 쿼리를 진행하니 역시나 같은 에러만 반환되는 것을 확인했습니다.
SELECT COUNT(*) AS "__count" FROM "테이블 명"출력된 InternalError_: variable not found in subplan target list 를 바탕으로 stackoverflow를 비롯하여 여러 페이지에 대한 리서치를 진행했음에도 명쾌한 답을 찾기 어려웠고, 문제 해결에 대한 작은 단서나 힌트를 발견하기 어려웠습니다. 하지만 신기하게도 stackoverflow에서의 한 분이 임시 방편으로 진행한 방법을 참고하여 쿼리를 하니 정상적으로 COUNT 쿼리에 대한 결과과 반환되었습니다. 참조한 내용과 링크는 아래와 같습니다.
본인도 동일한 에러가 발생했고, 임시 방편으로 쿼리를 수정하여 트러블 슈팅했다라고 남겨주시며 아래 코드를 첨부해주셨습니다. 🧷 stackoverflow
class ProblemAdmin(admin.ModelAdmin):
def get_queryset(self, request):
return Problem.objects.filter(id__gte=0)위 코드는 파이썬 장고 ORM을 통한 쿼리이며, SELECT * FROM problem WHERE id > 0 와 같은 동작을 하는 코드입니다.
id > 0 ≠ all ?
우선 에러가 발생한 테이블은 id라는 속성을 pk로 설정하고 있어 모든 행이 생성될 떄 자동으로 id값이 부여됩니다. 때문에 조건이 id > 0 라는 것은 전체 테이블을 호출하는 것과 같은 결과가 출력되야합니다.(라고 생각했었습니다.. 🥲 )
하지만 결과적으로 한 개의 쿼리는 성공, 다른 한 개의 쿼리는 실패의 결과를 얻게 되었습니다. 기존에 사용한, 그리고 새롭게 사용한 쿼리는 아래와 같습니다.
기존 쿼리 → SELECT COUNT(*) FROM 테이블 명
조건을 추가한 쿼리 → SELECT COUNT(*) FROM 테이블 명 WHERE id > 0
Solution.. !?
그렇게 팀원분과 위의 결과에 대한 의문만을 가진채 다시 각자 에러 트래킹을 진행했습니다. 그렇게 서로가 발견한 단서들을 정보가 조금씩 더해가던 그 때, 들리던..
🙋♂️ 해결했습니다. Vacuum을 진행 했어요. 이제 정상적으로 동작하네요.
정말 기존에 사용하던 쿼리가 정상작동했고, 그 결과 값 또한 예상한 값과 일치했습니다. 그렇게 트러블 슈팅에 대한 결과를 공유 받으며 Vacuum이라는 새로운 개념을 알게 되었습니다.
TroubleShooting 과정에서 만난 주요 개념들
MVCC
MVCC(Multi Version Concurrency Control): 다중 버전 동시성 제어. 동시접근을 허용하는 데이터베이스에서 동시성을 제어하기 위해 사용하는 방법. 데이터에 접근하는 사용자는 접근한 시점에서의 데이터베이스의 snapshot을 읽는데, 이 snapshot 데이터에 대한 변경이 완료될 때까지 만들어진 변경사항은 다른 데이터베이스 사용자가 볼 수 없습니다. 한마디로 lock을 사용하지 않고 데이터 읽기의 일관성을 보장해주는 방법. lock을 하지 않기 때문에 타 RDBMS 보다 빠르게 동작합니다.
PostgreSQL, MVCC
MVCC에는 2가지 구현방식이 있는데 PostgresSQL에서 사용하는 방식은 MGA(Multi Generation Architecture)입니다.(다른 방식은 Rollback Segment, Oracle에 적용) 이는 어떤 데이터의 업데이트(UPDATE, DELET)가 일어나면 기존의 데이터는 그대로 두고 새로운 데이터가 추가되는 방식입니다.
한마디로 기존의 데이터가 지워지지 않는다는 특징을 가지고 있으며 더 단순하게는 PostgreSQL에서의 UPDATE 동작은 결과적으로 INSERT와 같으며, DELETE 동작 또한 실제로 삭제가 행해지는 것이 아닌 감춰지는 것입니다.
따라서 만약에 대량에 업데이트 작업이 진행된 후 확인해보면, 실제 데이터의 양은 매우 적지만 테이블 사이즈 자체는 매우 커지는 결과를 얻을 수 있습니다. 테이블 사이즈가 커지는 만큼 당연히 쿼리에 대한 성능 또한 저하가 됩니다.
tuple
PostgreSQL에서 모든 데이터는 tuple(이하 튜플)이라고 불리는 형태로 저장이됩니다. 그리고 모든 튜플은 live tuple, dead_tuple로 나뉘게 됩니다. 어감에서도 알 수 있듯이, dead_tuple은 더 이상 참조되지 않는 튜플입니다.
PostgreSQL은 select에 대한 트랜잭션이 발생할 때 live_tuple을 읽어드리기 위해 일정한 용량의 chunk 단위로 파일을 읽어들입니다. 만약 이 때 chunk에 정리되지 않은 dead_tuple이 포함되어 있다면 원하는 결과값을 만들기 위해 더 많은 I/O가 발생하게 됩니다.
FSM
PostgreSQL에서 업데이트와 관련된 트랜잭션이 일어나는 경우, 위에서 설명했던 것처럼 물리적인 공간은 삭제되지 않고 남게 됩니다. 따라서 오래된 행 중에서 어느 곳에서도 참조되지 않고 안전하게 재사용할 수 있는 행을 찾아, FSM(Free Space Map)이라는 메모리 공간에 위치와 크기를 기록합니다.
PostgreSQL은 삽입이나 수정등 새로운 행을 추가될 경우 FSM영역에서 여유 공간을 확인, 새로운 데이터를 저장할 수 있는 row를 찾고 그곳을 재사용합니다. 만약 없다면 FSM을 추가적으로 확보합니다.
기록이 완료되면, 기존의 데이터를 가르키는 포인터를 새로 새록된 tuple로 변경하고, 이전 정보가 기록된 공간을 더 이상 참조하지 않습니다. 이렇게 참조되지 않는 tuple을 dead_tuple이라고 하는 것입니다. 이런 dead_tuple은 무의미 할 뿐만 아니라 저장공간만을 차지하게 되는데 dead_tuple이 점유하고 있는 공간을 정리하여 FSM으로 반환하여 재사용 가능하도록 하는 작업이 바로 Vaccum입니다.
Vaccum
Vaccum의 정의는 아래와 같습니다.
💡 Vaccum: PostgresSQL에만 존재하는 개념으로서, PostgresSQL의 쓰레기 데이터를 정리하여 쾌적하게 청소하는 역할. PostgresSQL을 안정적으로 운용하기 위해서 반드시 이해해야하는 개념.
Vaccum의 가장 중요한 역할은 dead_tuple이 차지하는 공간을 FSM으로 반환하여 재사용 할 수 있도록 하는 것입니다. 하지만 알아두어야 할 점은, Vacuum은 해서 전체 테이블의 크기가 줄이는 개념이 아니라 전체 테이블 크기는 동일하지만 내부 공간 정리를 진행함으로써 내부 공간을 확보 하는 것입니다.
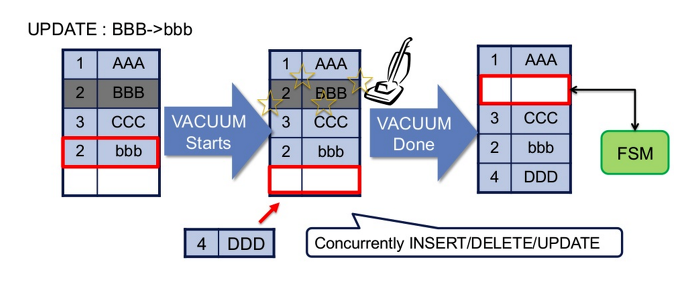
따라서 테이블 내의 빈번한 수정작업이 예상된다면 주기적으로 Vaccum을 진행하는 것이 운용의 측면에서도, 성능에 측면에서도 상당한 이점을 가져갈 수 있습니다. (AutoVaccum이 존재.. 한 번 알아보기 .. !)
이번에 발생한 에러 또한 Vacuum을 진행하므로써 기존 dead_tuple을 정리하고 원하는 값을 얻을 수 있었습니다. 지금까지의 트러블슈팅의 결과, COUNT(*)의 명령어가 테이블의 dead_tuple까지에 대한 값까지 SELECT 함으로서 이번의 에러가 발생했다고 생각합니다. (아니라면 댓글 꼭꼭 부탁드릴게요 !!)
Vaccum을 진행하지 않는다면..
Vacuum을 주기적으로 진행하지 않는다면 발생할 수 있는 우려사항은 아래와 같습니다.
- 데이터베이스 저장소의 불필요한 증가/팽창 문제
- 데이터 베이스 성능의 전반적인 하락
- I/O의 증가
- 트랜잭션 id 충돌(겹침)
- PostgreSQL에서는 하나의 tuple은 두 개의 트랜잭션 id를 가짐.
- tuple이 처음 생성되었을 때는 xmin이라는 id, update/delete 작업이 진행된다면 xmax라는 id
- PosgreSQL에서는 트랙잭션 id로 40억 개(xmin, xmax 각각 20억 개씩)를 사용가능.
- 만약 트랜잭션 id를 모두 사용한다면 다시 1부터 생성됨
- 이 때 이전의 데이터를 조회할 수 없음. 트랜잭션 id 충돌 문제 발생
- 불필요한 혹은 부적절한 인덱스 증가
- PostgreSQL의 모든 정보는 pg_category에 쌓이고 있는데, 튜플에 대한 정보도 포함됨
- 그 정보를 기반으로 쿼리 플랜에 활용
- dead_tuple로 인해 쿼리 성능이 저하되는 경우가 자주 발생(사용을 하지 않으니까 인덱스에서 제외, 혹은 자주 사용하는 줄 알고 인덱스 생성)
마무리
생각해보면 이번 이슈의 가장 큰 트리거는 DB 스케일 업에 있습니다. 서비스의 확장으로 인해 DB 스케일업을 진행했고 이전까지는 AutoVacuum이 진행되다가 이번에 스케일업을 진행하면서 별도의 AutoVacuum 설정을 진행하지 않아 발생했다.(했다고 생각하고 있다. 이유는 이전까지는 이러한 이슈가 없었음)
이번 에러는 운영 백오피스 단에서 발생한 에러여서 팀 내의 크리티컬한 데미지는 없었지만, PostgreSQL을 사용하는 개발자로서 Vacuum이라는 개념을 알게 된 것에 큰 의미를 가지게 되었습니다.
