개요
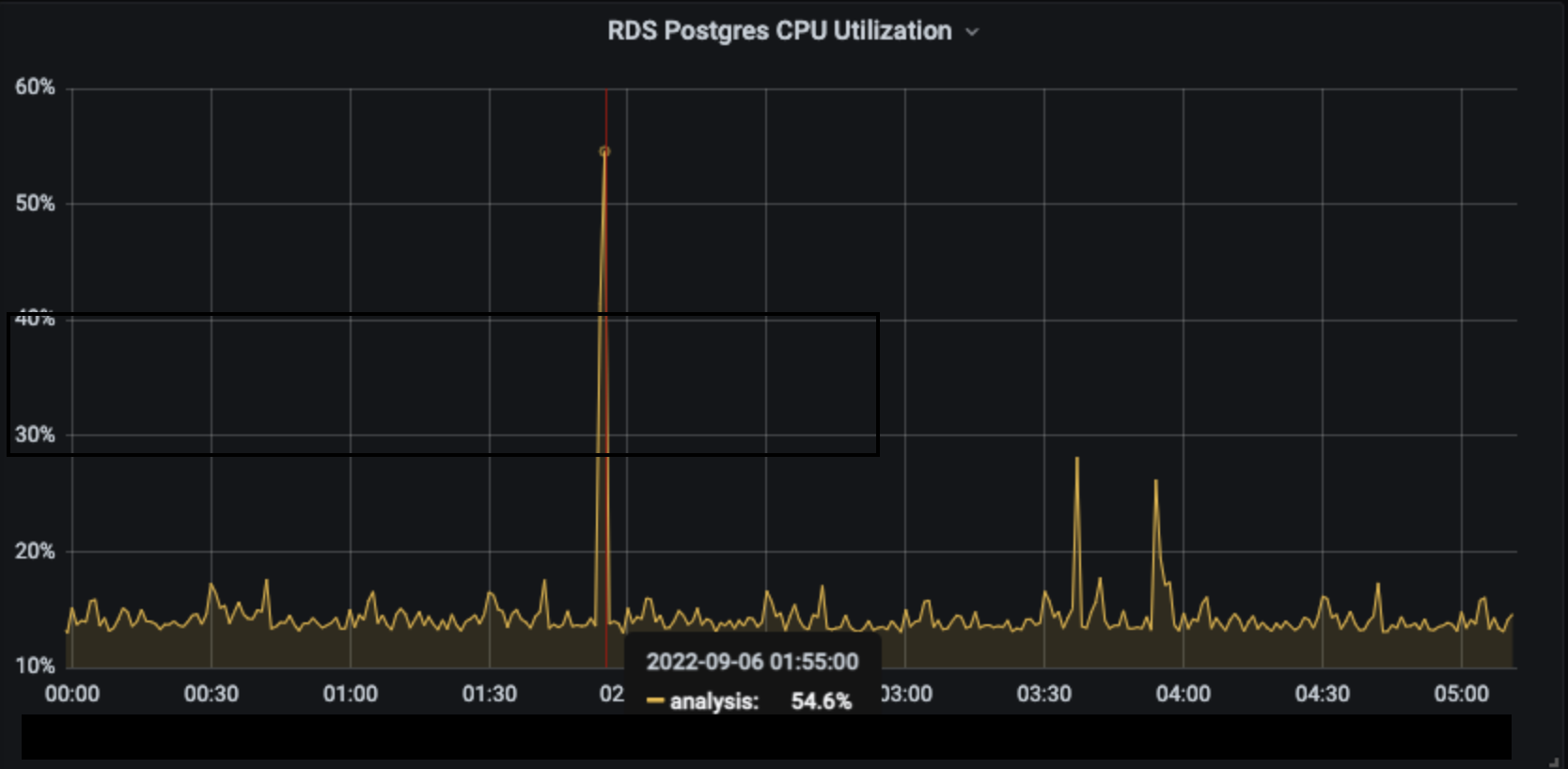
하루에 한 번, 전 날의 데이터를 AWS S3로 올리는 데이터 서빙 작업이 있습니다. 데이터의 수가 그렇게 많지 않음에도 아래와 같이 순간적인 부하가 발생했습니다. 아래의 그라파나 모니터링 지표와 slack alert를 통해서 확인할 수 있습니다.
- 그라파나 모니터링 지표
- 쿼리 로컬 테스트 부하 경보
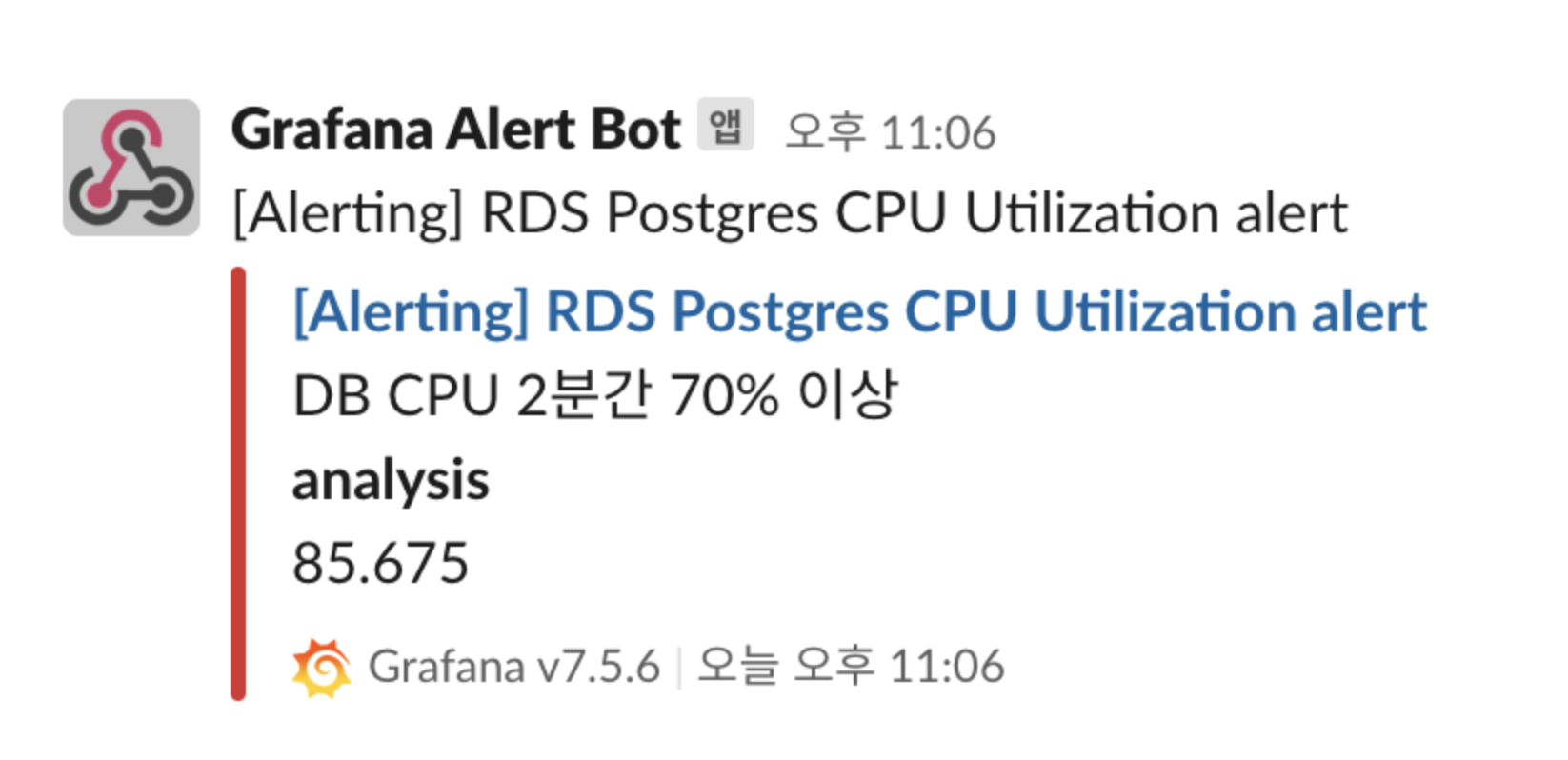
분석을 위한 데이터베이스이기 때문에 순간적인 부하가 전체 서비스에 대한 영향을 미치는 것은 아니지만, 쿼리 대비 예상보다 큰 부하가 발생한 점, 향후 데이터가 늘어날 것을 대비하여 이번 기회에 이를 개선하고 원인을 탐색해보았습니다.
as-is query
데이터를 서빙하게 위해 사용했던 쿼리는 매우 간단합니다. 데이터 서빙 작업 시간을 기준으로 어제 날짜의 데이터를 모두 조회합니다. 이 때 조건에 되는 timestamp 컬럼에 대한 timezone을 UTC에서 KST로 timezone casting을 진행했고, timestamp에서 date로 type casting을 진행했습니다.
SELECT * FROM public.table WHERE (timestamp at time zone 'Asia/Seoul')::timestamp::date = '2022-09-16'Postgresql EXPLAIN
postgresql은 EXPLAIN이라는 쿼리 플랜 및 성능 측정 기능을 제공합니다. EXPLAIN을 사용하면 쿼리를 진행하는데 발생하는 예상 코스트와 탐색에 필요한 기본적인 플랜을 확인 할 수 있습니다.
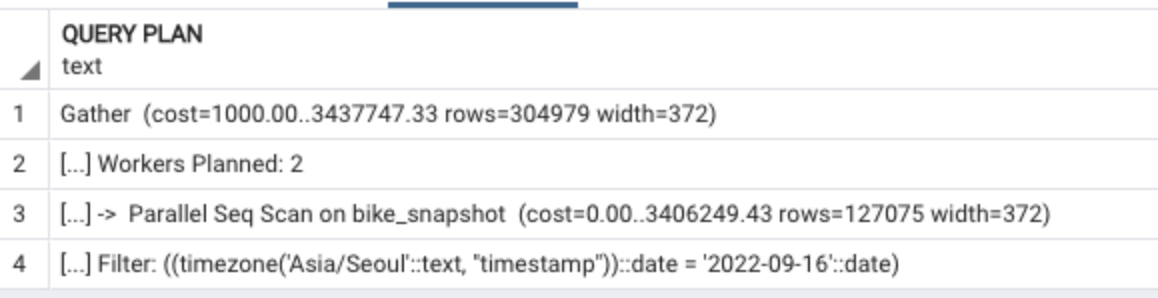
인덱스를 타지 않는다.. ?
제가 가장 의아한 부분은 QUERY PLAIN의 3번 째 행을 확인해보면 Parallel Seq Scan 입니다. 이는 테이블 풀 스캔을 하며 조회가 진행되고 있다는 것입니다. 하지만 조회하는 테이블은의 경우 timestamp 컬럼에 시계열 조회에 특화된 brin index가 설정되어 있습니다. 당연히 설정된 인덱스를 타면서 쿼리가 효율적으로 진행될 줄 알았는데 이상하게 테이블을 풀 스캔하며 조건에 해당 하는 데이터를 조회하고 있었습니다.
인덱스를 타지 않는 이유
우선적으로 쉽게 발견한 이유는 인덱스 컬럼의 내부적인 데이터 변환을 진행하면 설정한 인덱스를 타지 않는다 는 것이었습니다. 아마 위의 쿼리에서 인덱스가 설정되어 있는 timestamp 컬럼을 date로 변경하면서 발생했다고 생각했습니다. (참고로 이외에도 여러 이유로 쿼리가 인덱스를 타지 않을 수 있습니다. 자세한 내용은 Index를 타지않는 쿼리 포스팅을 참고하시면 좋을 것 같습니다.)
재도전
희망찬 마음에 date로 형변환 되는 부분을 제거하고 BETWEEN을 통해 동일한 결과의 쿼리로 변경했습니다.
SELECT * from public.table WHERE (timestamp at time zone 'Asia/Seoul')
BETWEEN '2022-09-16 00:00:00' and '2022-09-16 23:59:59'하지만 여전히 DB부하는 발생했고, postgresql EXPLAIN의 결과 또한 같았습니다. 여전히 Parallel Seq Scan를 진행되었으며 인덱스를 타지 않고 테이블 풀 스캔을 통해 데이터를 조회하고 있었습니다.

그렇다면 남은 것은 .. ?
인덱스가 설정된 컬럼에 대한 형 변환도 제거했지만 지속적으로 비효율적인 쿼리가 발생했습니다. 정렬을 다시해보는 등 여러가지 시도를 해보았지만 결과적으로 인덱스를 타지 않았습니다. 그러면서 발견한 것이 timezone 변경이었습니다.
현재 저희 서비스 데이터베이스에는 별도의 timezone이 설정되지 않은 UTC의 시간대로 timestamp를 저장하고 있습니다. 따라서 쿼리 할 때는 timezone 부여하면서 보다 사용자 친화적인 쿼리를 하곤 했습니다.
혹시나 하는 마음에 timezone 변경을 제외하고 쿼리를 진행했더니 인덱스를 타는 EXPLAIN 결과를 얻을 수 있었습니다.
select * from public.table where timestamp
between '2022-09-16 00:00:00' and '2022-09-16 23:59:59'
타임존 변경 쿼리가 인덱스를 타지 않았던 이유
pg 상에서는 시간을 저장하는 타입은 크게는 네 가지, 작게는 두 가지가 있습니다.
time [without timezone]
time [with timezone]
timestamp [without timezone]
timestamp [with timezone]
우선 이번 이슈에서는 별도의 time 타입을 사용하지 않으니 제외하겠습니다. 중요한 것은 timezone을 포함하냐, 하지 않느냐 입니다. timezone 포함여부에 따라 데이터 타입이 달라집니다. (이제 보니 timezone을 포함한 timestamp는 timestampz 라고 표기..)
현재 저희가 사용하는 timestamp는 별도의 timezone이 설정되지 않는 timestamp[without timezone] 였고, 일반적으로 쿼리할 때 timestamp 컬럼에 대해서 at time zone을 통해 타임존을 UTC -> KST로 timezone을 부여하여 쿼리를 진행했습니다. 여기서 놓쳤던 부분이 timezone을 부여되게 되면 데이터 타입이 timestamp[without timezone]에서timestamp[with timezone]로 형 변환이 진행 된다는 것이었습니다.
결국 timestamp를 date으로 데이터 타입을 변경해 인덱스가 타지 않았던 것처럼, timestamp 컬럼에 timezone을 부여하면서 timestampz로 데이터 타입이 변경되면서 인덱스를 타지 않았던 것이었습니다.
마무리
결과적으로 쿼리 시간도 약 60초에서 6초로 1/10으로 줄어들었고, DB부하도 기존 60%정도에서 20%정도로 큰 성과를 얻을 수 있었습니다. 효율을 높이기위해 선택했던 인덱스를 이제서야 제대로 활용하다니.. !이런 발견을 할 수 있음에 뿌듯하면서도 아쉬웠던 배움이었습니다
