INTRODUCTION
추천시스템에서 사용되는 Collaborative Filtering(CF)은 비슷한 행동을 가진 유저들이 비슷한 아이템을 선호할 것이라고 가정하는 것이다.
CF모델에는 두 가지 핵심 구성 요소가 있다.
- 사용자와 아이템을 벡터화된 표현으로 변환하는 임베딩
- 임베딩을 기반으로 과거의 유저와 아이템 간의 상호작용을 재구성하는 상호작용 모델링(interaction modeling)
지금까지 CF모델의 예시로 MF, collaborative deep learning, neural collaborative filtering, translation-based CF 모델과 같은 여러 방법이 제시됐지만 우리는 CF에 대해 만족스러운 임베딩을 생성하기에 충분하지 않다고 주장한다.
그 이유는 임베딩 기능에 중요한 Collaborative signal을 명시적으로 인코딩해주지 않았기 때문이다. 결과적으로 임베딩이 충분하지 않다면 interaction function에 의존해야 한다.
현실에 있는 데이터는 100만개 혹은 그 이상의 interaction을 갖기 때문에 유저와 아이템 간의 interaction을 임베딩 함수에 포함시키는 것은 쉬운 일이 아니다. 이에 따라 본 논문에서는 High-order connectivity라는 새로운 특성을 모델에 반영하고자 한다.
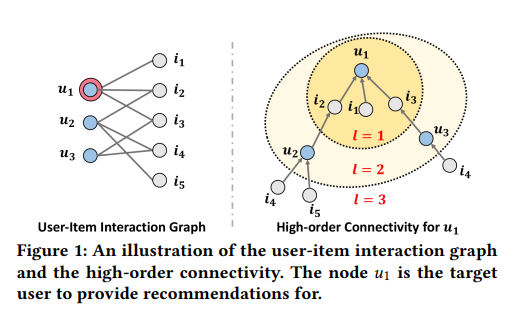
위의 그림은 high-order connectivity의 개념을 보여준다.
왼쪽 그림은 유저와 아이템간의 interaction, 오른쪽 그림은 유저 을 기준으로 high-order connectivity가 형성됨을 보여주는 그림이다.
기준이 되는 노드로부터 크기만큼 퍼지는 것을 알 수 있다. 예를 하나 들자면 과 는 로 연결되어 있어 둘 사이의 행동에 유사성이 있다고 할 수 있다. 이에 따라 에게 가 구매했던 를 추천할 수 있다.
또한 관점을 통해 이 보다 에 더 큰 관심을 가질 가능성이 높은 것 또한 알 수 있다.
이처럼 high-order connectivity의 형태로 Collaborative signal을 명시적으로 표현하기 위해 GNN의 아이디어를 embedding propagation layer에서 실현한다.
METHODOLOGY
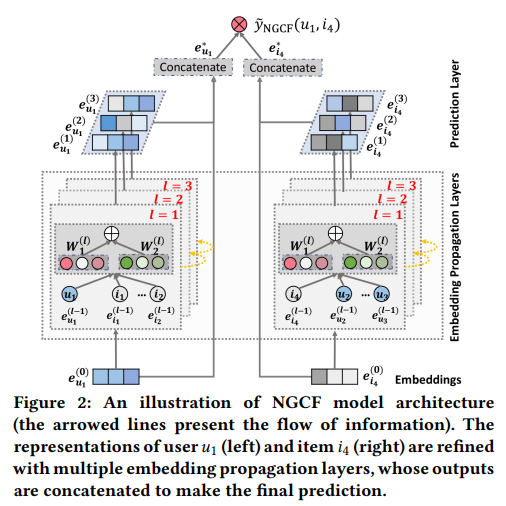
NGCF모델은 세 가지 구성 요소가 있다.
- 사용자 임베딩 및 아이템 임베딩을 제공하고 초기화하는 임베딩 계층.
- high order connectivity를 이용해 임베딩을 개선하는 multiple embedding propagation layer
- 각각 다른 propagation layer에서 정제된 임베딩을 집계하고 사용자-아이템 쌍의 선호도 점수를 출력하는 prediction Layer
Embedding Layer
user와 item에 대해 embedding vector를 생성해주는 layer이다.
MF, NCF와 달리 interaction graph를 통한 임베딩 전파를 통해 값들을 개선해 나간다. 즉 collaborative signal을 주입한다.
embedding propagation layers
Collaborative signal을 포착하여 embedding을 개선하기 위해 GNN의 message-passing 구조를 사용한다.
First-order propagation
graph의 에 해당하며 사용자의 선호도에 대한 직접적인 정보를 제공한다.
First-order propagation을 구성하는 두 가지 주요 작용은 Message Construction과 Message Aggregation이다.
- Message Construction
message construction은 유저와 아이템의 쌍에서 아이템으로부터 유저에게 전달되는 메세지를 의미한다.
는 학습 가능한 가중치 매트릭스를 의미한다.
아이템 임베딩과 유저 임베딩의 element-wise 곱을 더해 비슷한 아이템으로부터 많은 메세지를 전달할 수 있도록 한다.
는 graph Laplacian Norm 을 의미하며 와 는 유저와 아이템의 first-hop 이웃들을 나타낸다. 이를 통해 과거의 아이템들이 사용자의 선호도에 얼마나 반영했는지 나타낸다.
- Message Aggregation
message aggregation은 유저의 이웃들로부터 생성되는 message construction을 aggregation한다.
이웃노드로부터 온 message 뿐만 아니라 본래 자신에 대한 정보인 까지 input으로 넣어 를 도출해낸다.
활성 함수 를 통해 positive와 약간의 negative를 갖는 결과를 얻게 된다.
High-order Propagation
first-order connectivity에서 변환된 벡터 표현을 가지고, high-order connectivity 정보를 탐색하기 위해 더 많은 embedding propagation layers를 쌓는다.
개의 embedding propagation layer를 쌓으면 유저 노드는 - 이웃으로부터 전파된 메세지를 받을 수 있다.
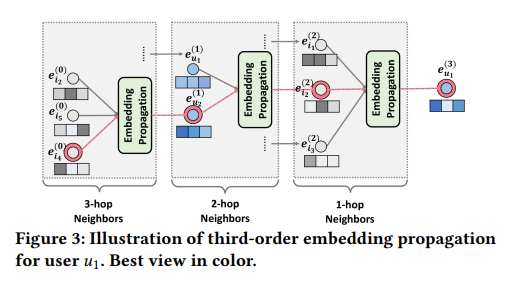
위 그림의 빨간 선이 의 임베딩 벡터를 찾아나가는 과정이다.
Model Prediction
개의 embedding propagation layer를 거쳐 나온 output은 이다.
각각의 embeddings를 concatenate함으로써 최종 유저에 대한 임베딩을 구성한다.
최종적으로 유저와 아이템의 임베딩 값의 내적을 통해 target 아이템에 대한 유저의 선호도를 예측할 수 있다.
Optimization
- Loss function : Pairwise BPR Loss
- Optimizer : Adam
- Model Size : 모델 매개변수가 매우 적다. (MF가 450만개일 때 NGCF는 24000개면 된다.)
Message & node dropout
학습과정에서 Message & node dropout이 사용된다.
message dropout: 유저와 아이템의 연결이 single connections일 경우 출력되는 message를 랜덤하게 dropout하여 모델이 robustness할 수 있도록 만든다.
node dropout: 특정 유저와 아이템의 영향력이 많은 노드들에 대해서, 해당 노드들을 삭제함으로써 영향력을 감소시킨다.
EXPERIMENTS
embedding propagation layer를 평가하기 위해 3개의 실제 데이터 셋에 대한 실험을 수행했다. 실험 목표는 다음과 같다.
- RQ1: NGCF는 최신 CF 방법과 비교하여 어떤 성능을 냈는지?
- RQ2: 다양한 하이퍼파라미터 설정이 NGCF에 영향을 주는지?
- RQ3: high-order connectivity의 이점을 무엇인지?
데이터셋으론 Gowalla, Yelp2018, Amazon-book을 사용하였다.
Experimental settings
- Evaluation Metrics: , ,
- Model: MF, NeuMF, CMN, HOP-Rec, PinSage, GC-MC
Performance Comparison (RQ1)
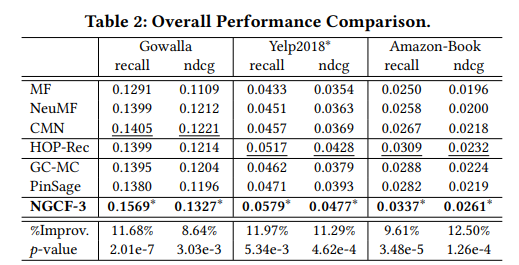
- NGCF는 모든 데이터셋 및 평가지표에서 가장 우수한 성능을 보였다. 또한 HOP-Rec 모델에 비해 NGCF-3의 성능이 더 좋은 것을 근거로 임베딩 함수에서 명시적으로 Collaborative signal을 인코딩하는 것이 성능을 개선했음을 알 수 있다.
Study of NGCF (RQ2)
- embedding propagation layer의 개수
- NGCF-4의 경우 일부 데이터에서 과적합되는 것을 확인. 따라서 3개의 propagation layer를 사용하는 것이 적합하다는 것을 알 수 있었다.
- 레이어의 개수에 상관없이 NGCF가 다른 모델에 비해 더 성능이 좋았다.
- dropout
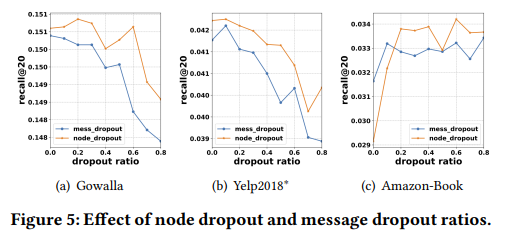
앞서 설명했던 message dropout, node dropout 중에 node dropout이 더 나은 성능을 제공하는 것을 알 수 있었다.
예시로 Gowalla의 경우 0.2로 설정했을 때 가장 높은 리콜이 발생하며 이는 특정 사용자 및 아이템에서 발생하는 모든 messgae를 삭제하면 특정 가장자리의 영향뿐만 아니라 노드의 영향에 대해서도 표현이 robust해지기 때문일 수 있다.
이는 node dropout이 그래프 신경망의 과적합을 해결하는 효과적인 전략이 될 수 있다.
- Test Performance w.r.t Epoch
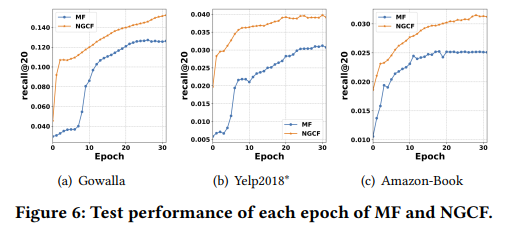
NDCG는 모든 데이터셋에 대해 MF보다 빠른 수렴을 보이는 것을 알 수 있다.
Effect of High-order Connectivity (RQ3)
high-order connectivity의 효과를 알아보기 위해 embedding propagation이 embedding space에서 어떻게 representation learning을 증진시키는지 TSNE를 이용해 확인했다.
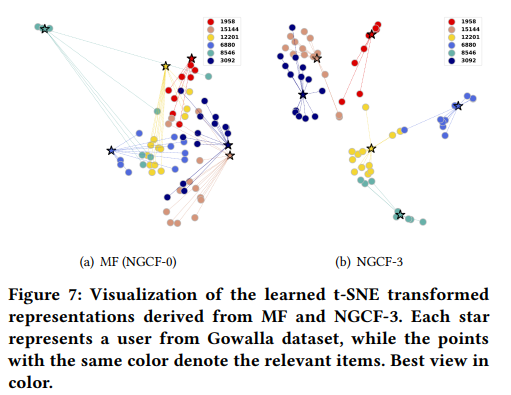
유저와 관련된 임의의 아이템 ★을 6개 추출하였다.
MF에 비해 NGCF-3이 군집을 잘 형성하고 있는 것을 확인할 수 있다.
