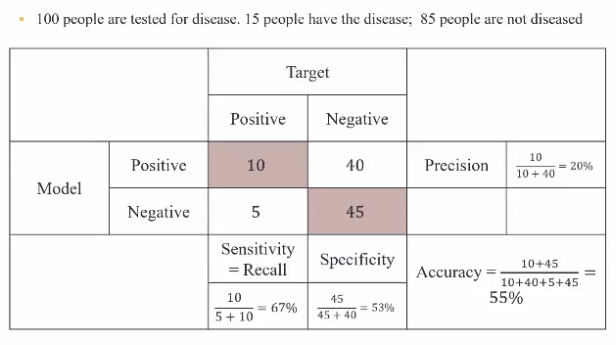
이 표는 질병 진단 테스트의 성능을 평가하는 혼동 행렬(Confusion Matrix)과 관련 지표들을 보여줍니다.
100명을 대상으로 한 테스트 결과를 나타냅니다.
-
데이터 구성:
- 총 100명 중 15명이 실제로 질병이 있고, 85명은 건강합니다.
-
모델 예측 결과:
- 진양성(TP): 10명 (질병이 있다고 정확히 진단)
- 위양성(FP): 40명 (건강한데 질병이 있다고 잘못 진단)
- 위음성(FN): 5명 (질병이 있는데 건강하다고 잘못 진단)
- 진음성(TN): 45명 (건강하다고 정확히 진단)
-
성능 지표:
-
정밀도(Precision): 20%
= TP / (TP + FP) = 10 / (10 + 40) = 10 / 50 = 20%
의미: 모델이 양성이라고 예측한 것 중 실제 양성인 비율 -
민감도(Sensitivity) 또는 재현율(Recall): 67%
= TP / (TP + FN) = 10 / (10 + 5) = 10 / 15 ≈ 67%
의미: 실제 양성 중 모델이 양성이라고 예측한 비율 -
특이도(Specificity): 53%
= TN / (TN + FP) = 45 / (45 + 40) = 45 / 85 ≈ 53%
의미: 실제 음성 중 모델이 음성이라고 예측한 비율 -
정확도(Accuracy): 55%
= (TP + TN) / 전체 = (10 + 45) / 100 = 55%
의미: 전체 예측 중 올바르게 예측한 비율
-
이 모델은 정확도가 55%로 그리 높지 않습니다. 특히 건강한 사람을 질병이 있다고 잘못 진단하는 경우(위양성)가 많아 정밀도가 낮습니다. 반면 질병이 있는 사람을 찾아내는 능력(민감도)은 상대적으로 높습니다. 이런 분석을 통해 모델의 강점과 개선이 필요한 부분을 파악할 수 있습니다.
1. Precision (정밀도)
- 의미: 모델이 양성이라고 예측한 것 중 실제 양성인 비율
- 공식: TP / (TP + FP)
- 어원: 라틴어 'praecisio'에서 유래, '정확히 자르다'는 뜻
- 이름의 이유: 모델의 양성 예측이 얼마나 '정확하게' 실제 양성을 '잘라내는지'를 나타내기 때문
2. Sensitivity (민감도) 또는 Recall (재현율)
- 의미: 실제 양성 중 모델이 양성이라고 예측한 비율
- 공식: TP / (TP + FN)
- 어원:
- Sensitivity: 라틴어 'sensitivus'에서 유래, '감지할 수 있는'이란 뜻
- Recall: 라틴어 're-' (다시) + 'calare' (부르다)에서 유래
- 이름의 이유:
- Sensitivity: 모델이 실제 양성 케이스에 얼마나 '민감하게' 반응하는지를 나타내므로
- Recall: 모델이 실제 양성 케이스를 얼마나 잘 '다시 불러내는지(회상하는지)'를 나타내므로
3. Specificity (특이도)
- 의미: 실제 음성 중 모델이 음성이라고 예측한 비율
- 공식: TN / (TN + FP)
- 어원: 라틴어 'specificus'에서 유래, '종에 특유한'이란 뜻
- 이름의 이유: 모델이 음성 케이스를 얼마나 '특정하게' 잘 식별하는지를 나타내므로
4. Accuracy (정확도)
- 의미: 전체 예측 중 올바르게 예측한 비율
- 공식: (TP + TN) / (TP + TN + FP + FN)
- 어원: 라틴어 'accuratus'에서 유래, '주의 깊게 행해진'이란 뜻
- 이름의 이유: 모델의 전체적인 예측이 얼마나 '정확한지'를 나타내므로
이 지표들의 중요성:
- Precision: 양성 예측의 신뢰성을 측정. 거짓 경보를 최소화하고자 할 때 중요
- Sensitivity: 실제 양성 케이스를 놓치지 않는 능력을 측정. 질병 스크리닝 등에서 중요
- Specificity: 실제 음성 케이스를 정확히 식별하는 능력을 측정. 불필요한 추가 검사를 줄일 때 중요
- Accuracy: 전체적인 모델의 성능을 한눈에 보여줌. 하지만 불균형한 데이터셋에서는 misleading할 수 있음
이 지표들을 종합적으로 고려하면 모델의 성능을 다각도로 평가할 수 있습니다. 특정 상황이나 문제의 특성에 따라 어떤 지표에 더 중점을 둘지 결정하게 됩니다.
threshold를 증가시키면 일반적으로 recall은 감소하고 precision은 증가합니다.
먼저, threshold란 모델이 양성으로 판단하는 기준값입니다. 이 값을 높이면:
- 양성으로 판단하는 기준이 더 엄격해집니다.
- 따라서 양성으로 예측되는 경우가 줄어듭니다.
표의 예시를 그대로 활용해 보겠습니다:
현재 상태:
- TP (진양성): 10
- FP (위양성): 40
- FN (위음성): 5
- TN (진음성): 45
Precision = 10 / (10 + 40) = 20%
Recall = 10 / (10 + 5) = 67%
이제 threshold를 높인다고 가정해봅시다:
변경 후 (가상의 수치):
- TP: 8 (감소)
- FP: 20 (크게 감소)
- FN: 7 (증가)
- TN: 65 (증가)
새 Precision = 8 / (8 + 20) = 29% (증가)
새 Recall = 8 / (8 + 7) = 53% (감소)
설명:
-
Precision 증가:
- threshold가 높아지면 양성으로 예측하는 기준이 엄격해져 FP가 크게 줄어듭니다.
- TP도 약간 줄지만, FP가 더 많이 줄어 전체적으로 Precision이 증가합니다.
-
Recall 감소:
- threshold가 높아지면 일부 실제 양성 케이스를 놓치게 되어 TP가 줄고 FN이 증가합니다.
- 따라서 Recall이 감소합니다.
이런 변화는 모델이 "더 확실할 때만 양성이라고 예측"하게 되기 때문입니다.
결과적으로 양성이라고 예측할 때 더 정확해지지만(Precision 증가), 실제 양성 중 일부를 놓치게 됩니다(Recall 감소).
이 관계는 Precision-Recall 트레이드오프라고 불리며, 실제 응용에서는 문제의 특성에 따라 적절한 threshold를 선택하게 됩니다.
