
OpenAI에서 사람이 입력한 지시문을 잘 이해하고 좋은 답변을 내기 위한 방법으로 "강화학습"을 활용해 기술적 혁신을 이끌었다.
RHLF(Reinforcement Learning from Human Feedback)
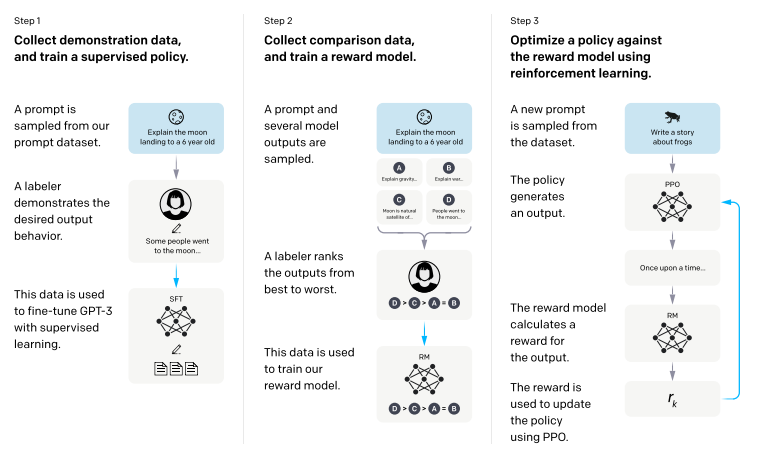
step0. 기본 GPT 모델 준비
대규모 텍스트 데이터로 사전학습된 GPT 모델을 사용한다. 이 모델은 단어를 예측하거나 문장을 생성할 수 있지만, 아직 구체적인 지시를 잘 따르지는 못한다.
step1. SFT(Supervised Fine-tuning)
사람이 작성한 답변 데이터를 준비한다. (예를 들어, 어떤 prompt에 대해 사람이 작성한 고품질의 답변을 데이터로 준비한다.)
이 데이터를 모델에 학습시켜, 사람이 작성한 답변과 유사한 답변을 생성할 수 있도록 모델을 미세조정(Fine Tuning)한다.
이렇게 만들어진 모델을 SFT(Supervised Fine-Tuned) 모델이라고 부른다.
SFT Model: 기본적으로 사람의 답변을 흉내내는 모델
step2. Reward Model(RM) 학습
-
SFT 모델로 답변을 생성한다.
Step1에서 만든 SFT 모델의 여러 버전을 준비한다.
동일한 질문(prompt)을 입력하고, 각각의 SFT 모델이 생성한 다양한 답변을 수집한다. -
사람의 평가 데이터 생성
수집된 답변들 중에서, 사람이 어떤 답변이 더 좋은 평가하여 순위를 매긴다. -
쌍(pair) 데이터를 샘플링
위에서 만든 순위를 활용해, 답변 K개 중 임의로 두 개의 답변 쌍을 만든다.
두 답변 중에서 사람이 더 선호한 답변을 기준으로 모델에게 학습을 시킨다. -
보상 모델(RM) 학습
보상 모델(RM)은 입력된 질문(prompt)와 답변에 대해 "이 답변이 얼마나 좋은가"를 예측하는 역할을 한다.
아래의 수식에 따라, 사람이 더 선호한 답변과 그렇지 않은 답변의 차이를 예측하도록 RM을 훈련한다.
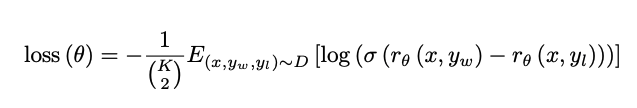
rθ(x,y): 질문 x와 답변 y에 대해 보상 모델이 출력한 점수(스칼라 값).
𝑦𝑖,𝑦1−𝑖: 인간이 선호한 답변과 그렇지 않은 답변.
이 과정을 통해 보상 모델은 어떤 답변이 더 "좋은" 답변인지 판단하는 능력을 갖추게 됩니다.RM: 어떤 답변이 좋은지 평가하는 모델
step3. 강화학습
- PPO 정책 모델 초기화
step1에서 만든 SFT 모델을 기반으로 새로운 정책(policy) 모델을 초기화한다. (초기화된 모델을 기반으로 행동 규칙을 설정한다.)
이 모델은 다양한 답변을 생성하며 학습할 준비가 되어있다. - 답변 생성 및 평가
정책 모델은 질문(prompt)에 대해 여러가지 답변을 생성한다.
각 답변에 대해 step2에서 학습된 보상 모델(RM)이 "얼마나 좋은 답변인지" 점수(reward)를 제공한다. - 강화 학습 진행
모델은 RM에서 제공한 보상을 최대화하려고 노력한다.
PPO 알고리즘을 사용하여, 사람이 선호할 가능성이 높은 답변을 생성하도록 모델을 강화학습한다.
이때, 학습이 지나치게 한쪽으로 치우치지 않도록 KL divergence를 사용해 SFT 모델과 차이를 제한한다.
이를 통해 모델이 안정으로 학습하면서도 더 나은 답변을 생성할 수 있도록 돕는다.PPO Policy Model: 실제로 질문에 대해 사람이 선호하는 답변을 생성하는 모델
RL에서의 용어정리
왜 policy(정책)이라는 용어를 사용하는가?
강화학습은 본질적으로 미래의 보상을 극대화하는 방법을 학습하는 과정이다. 이 과정에서 정책(policy)은 "결정을 내리는 규칙" 또는 "행동 방침"에 해당한다.
ex. PPO 알고리즘은 "답변을 생성하는 방식(policy)"을 점진적으로 개선하여 보상을 최대화하려고 한다.
상태(state): 현재 환경의 상황정보(예. 주어진 질문 또는 프롬프트)
행동(action): 모델이 생성하는 답변이나 출력
정책(policy): 상태에 따라 행동을 결정하는 전략(예. 정책은 어떤 질문이 들어오면 어떤 방식으로 답변을 생성해야 가장 높은 보상을 받을지를 결정한다.)
참고자료
Training language models to follow instructions with humanfeedback
Learning to summarize from human feedback
chatGPT에 사용된 RLHF와 PPO 알고리즘 뜯어보기
