
PPO(Proximal Policy Optimization Algorithms)
Gradient Descent and step size
Gradient Descent
머신러닝에서 모델을 학습시킬 때, Gradient Descent(경사하강법)는 손실을 줄이기 위해 매번 최적의 방향으로 조금씩 나아가는 방식이다. (ex.산의 정상/최적의 모델 파라미터에 도달하기 위해 경사를 따라 올라가는 것)
step size
경사를 따라 이동할 때 한번에 얼마나 이동할지를 결정하는 값이 step size(학습률)이다.
이 값이 너무 작거나 크면 문제가 생길 수 있다.
step size가 너무 작을 경우: 정상에 도달하는 시간이 너무 오래 걸려 학습이 비효율적이다.
step sie가 너무 클 경우: 경사를 넘어가 길을 잃거나, 최적의 경로에서 벗어나 오히려 나쁜 위치로 갈 위험이 높다.
강화학습에서 학습 안정성 문제
강화학습에서는 단순히 손실을 줄이는 것이 아니라 정책을 업데이트하여 모델이 더 좋은 행동을 하도록 만든다. 하지만 gradient descent 방식만으로 다음과 같은 문제가 발생할 수 있다.
잘못된 방향으로 큰 업데이트가 이루어지면 학습이 불안정해질 수 있다.
특히 정책을 업데이트할 때 너무 크게 변하면, 모델이 예전의 행동 패턴을 완전히 잊어버리거나 성능이 크게 저하될 수 있다.
이러한 문제를 해결하기 위해 TRPO와 같은 방법로이 개발되었다.
TRPO(Trust Region Policy Optimization)
TRPO는 업데이트를 안전구역(Trust Region)으로 제한한다.
너무 큰 변화로 인해 학습이 실패하는 위험을 줄이고 정책이 조금씩 안정적으로 개선되도록 돕는다.
하지만, TRPO는 안전 구역을 계산하기 위해 복잡한 수학적 계산이 필요하다.
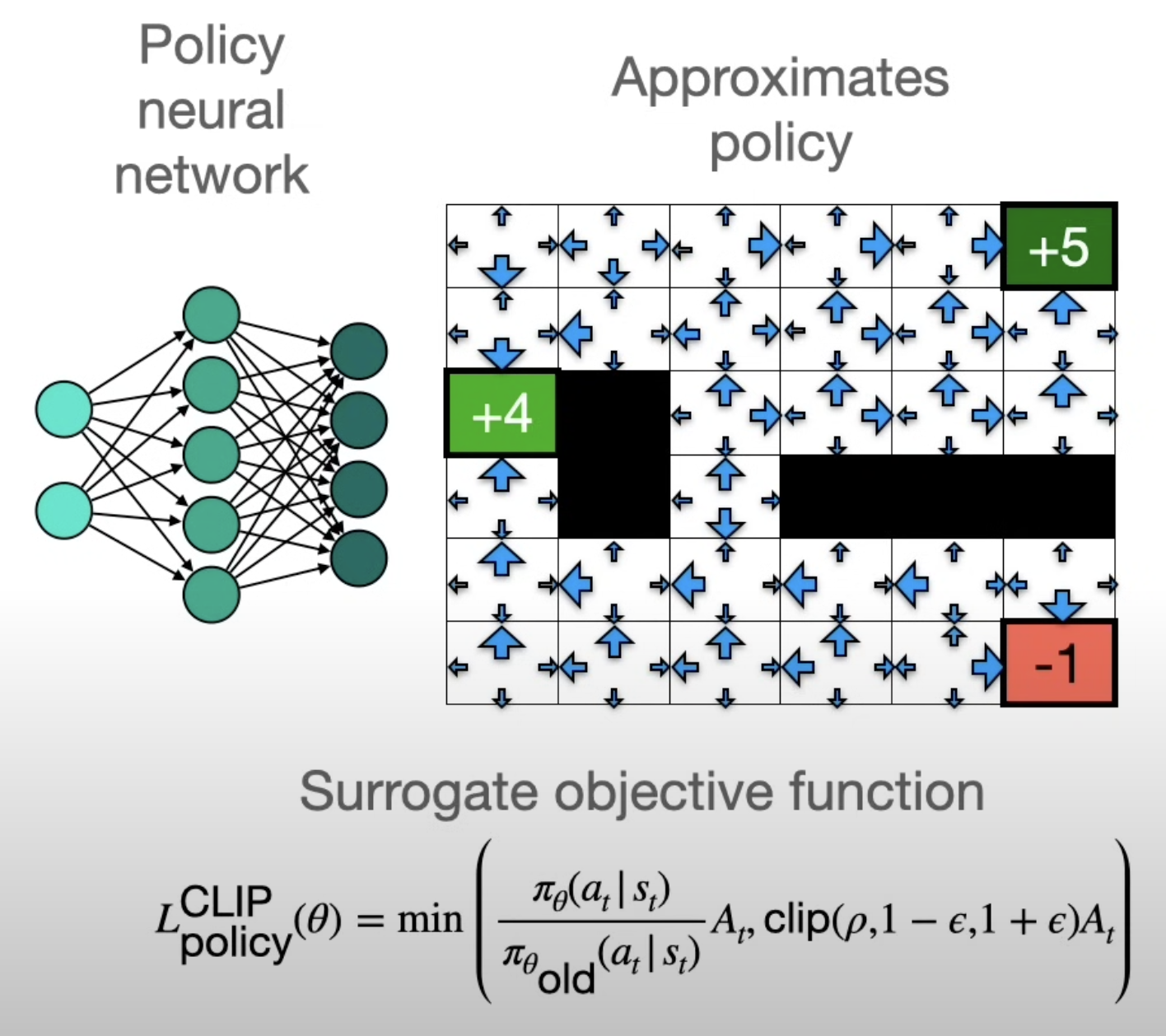
PPO
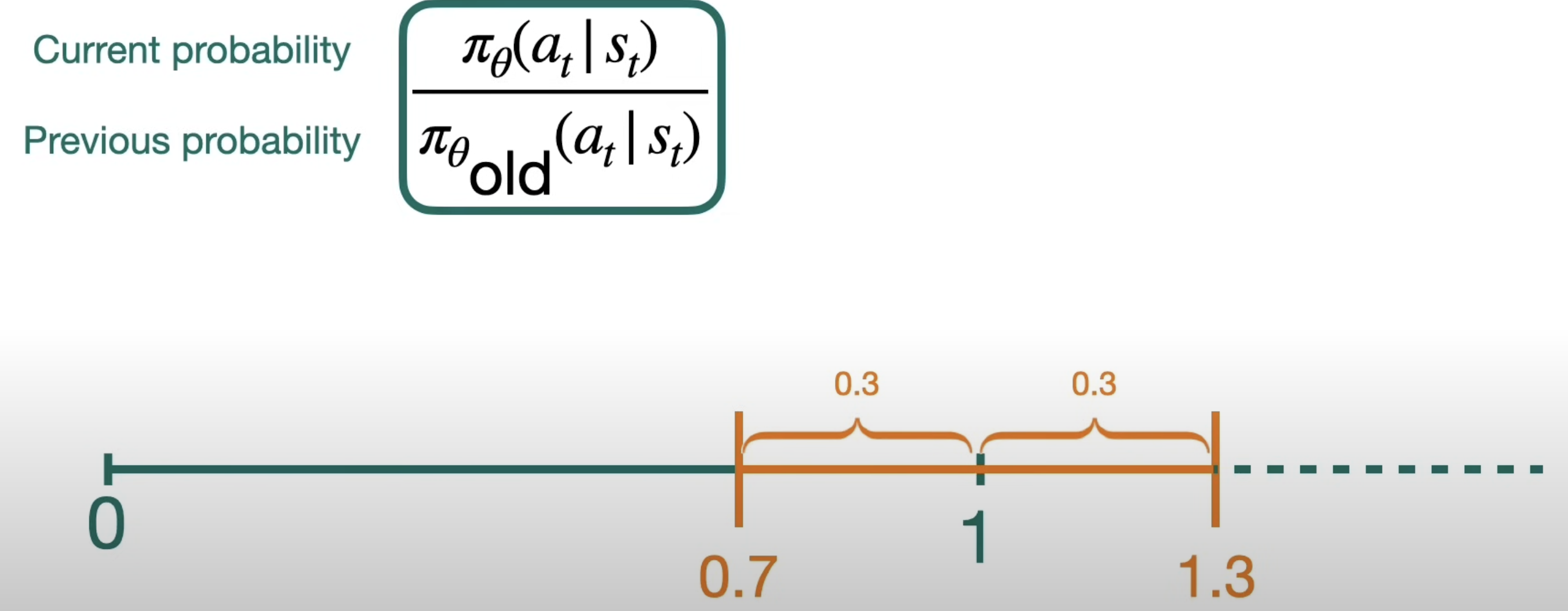
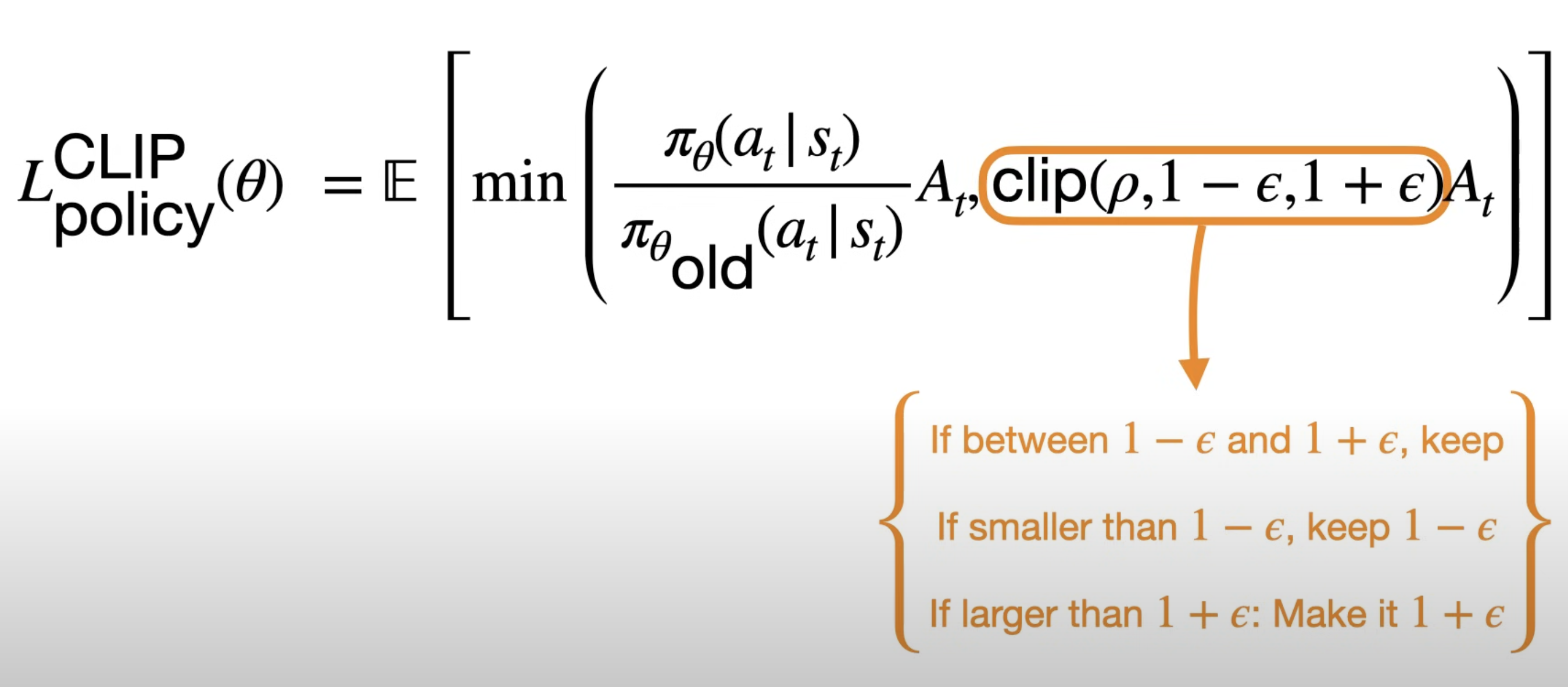
TRPO처럼 안전 구역을 계산하는 대신, r_t(θ) 값을 제한된 범위로 Clipping.
r_t(θ)는 새로운 정책이 기존 정책과 얼마나 다른지 나타내는 비율으로, 이 값을 1 근처의 작은 범위(예. 1±𝜖)로 제한하여 정책이 너무 많이 변하지 않도록 한다.
PPO는 간단한 방식으로 학습 안정석을 유지하면서도 정책을 효율적으로 업데이트할 수 있는 알고리즘이다.
참고자료
Proximal Policy Optimization Algorithms
chatGPT에 사용된 RLHF와 PPO 알고리즘 뜯어보기
Proximal Policy Optimization (PPO) - How to train Large Language Models
