[논문] Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts
논문

Similarity is Not All You Need: Endowing Retrieval-Augmented Generation with Multi–layered Thoughts
abstract
LLM의 지식 업데이트가 제대로 이루어지지 않는 점과 높은 비용, 환각 문제는 지식 집약적인 작업에서 활용을 제한해왔다. 이에 대한 문제는 RAG가 도움을 줄 수 있는데, 기존 RAG 모델들은 일반적으로 쿼리와 문서 간의 유사성을 매개체로 사용하며, 정보를 검색한 후 읽는 (retrieve-then-read) 절차를 따른다.
본 연구에서는 유사성이 항상 만능 해결책이 아니며, 유사성에만 전적으로 의존할 경우 RAG의 성능이 저하될 수 있다고 주장한다. 이를 해결하기 위해 METRAG(Multi–layEred Thoughts enhanced RetrievalAugmented Generation)라는 다층적 사고를 활용한 RAG 프레임워크를 제안한다.
먼저, 기존의 유사성 지향 사고(similarity-oriented thought)를 넘어, LLM의 지도를 받아 효용성을 평가하는 소규모 효용 모델을 도입하여 효용성 지향 사고(utility-oriented thought)를 구현한다. 그리고 유사성과 효용성을 종합적으로 결합하여 더 똑똑한 모델을 설계한다.
더 나아가, 검색된 문서 집합이 방대하고 이를 개별적으로 사용하는 경우 문서들 간의 공통점과 특성을 파악하기 어렵다는 사실을 고려하여, LLM을 작업 적응형 요약기(task-adaptive summarizier)로 활용한다. 이를 통해 RAG에 간결성 지향 사고를 부여한다.
마지막으로, 이전 단계에서 얻은 다층적 사고를 기반으로, LLM을 활용한 지식 증강 생성(knowledge-augmented generation)을 수행한다.
Introduction
유사성은 항상 RAG의 만능 해결책은 아니다. 오히려 전적으로 유사성에 의존할 경우 성능이 저하될 수 있다.
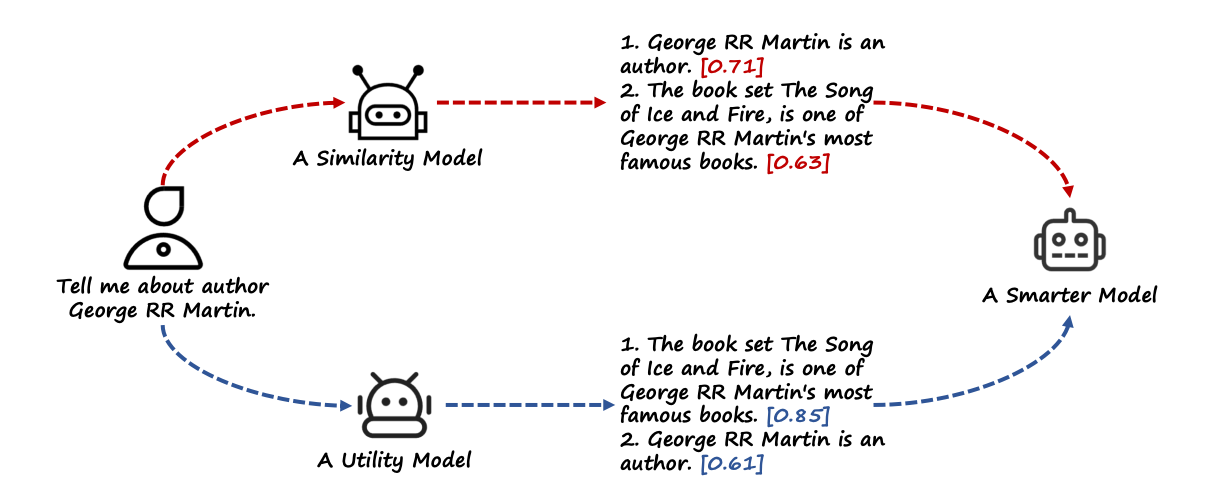
예를 들어, "Tell me about author George RR Martin,"라는 쿼리를 입력했을 때, 유사성 기반 검색 시스템은 코퍼스 내 문서를 유사성 점수(semantic relevance or TFIDF)에 따라 정렬한다. 높은 유사성을 가진 문제(ex. George RR Martin is an author)는 적은 정보량에도 상위에 랭크될 수 있다. 반면, 더 유익한 정보를 담고 있지만 유사성 점수가 낮은 문서(ex. "the book set The song of Ice and Fire" is one of George RR Martin's most famous books.)는 하위에 밀릴 수 있다.
검색된 문서가 다수인 경우, LLM의 컨텍스트 제한으로 이를 개별적으로 사용하는 것이 일반적이다. 하지만 문서 간의 관계를 고려하지 않고 Top-K 문서를 단순히 결합하면 문서의 공통점과 특성을 포착하기 어려워진다. 또한 과도한 텍스트 길이로 인해 정보 손실이 발생하거나, LLM이 혼란을 겪어 성능이 저하될 수 있다.
따라서, 이 논문에서는 기존의 유사성 기반 접근을 넘어, 다층적 사고를 활용하여 RAG의 성능을 향상시키고자 한다. 여기에는 효용성 지향 사고와 간결성 지향 사고가 포함된다. 그러나 이를 구현하기 위해서는 다음과 같은 주요 도전 과제가 존재한다.
C1: 효용성 지향 사고 모델 훈련
효용성을 인식할 수 있는 모델을 훈련하려면 외부 레이블 데이터가 필요하지만 이를 얻는 것이 어렵다. LLM을 데이터 레이블링 도구로 사용할 수는 있지만, 이 과정에서 LLM의 불안정성과 통제 불가능한 특성으로 인해 성능 저하가 발생할 수 있다.
C2: 간결성 지향 사고를 가진 요약 모델 훈련
검색된 문서의 수가 많을 경우, LLM에 부하를 줄이고 문서 간의 공통점과 특성을 더 잘 포착하기 위해 문서 요약이 필요하다. 그러나 단순 요약만으로는 쿼리와 관련된 가장 중요한 정보를 보장할 수 없다. 따라서 작업에 맞게 조정된 모델이 필요하며, 이 모델은 간결성 지향 사고를 가져야한다.
제안된 접근법: METRAG
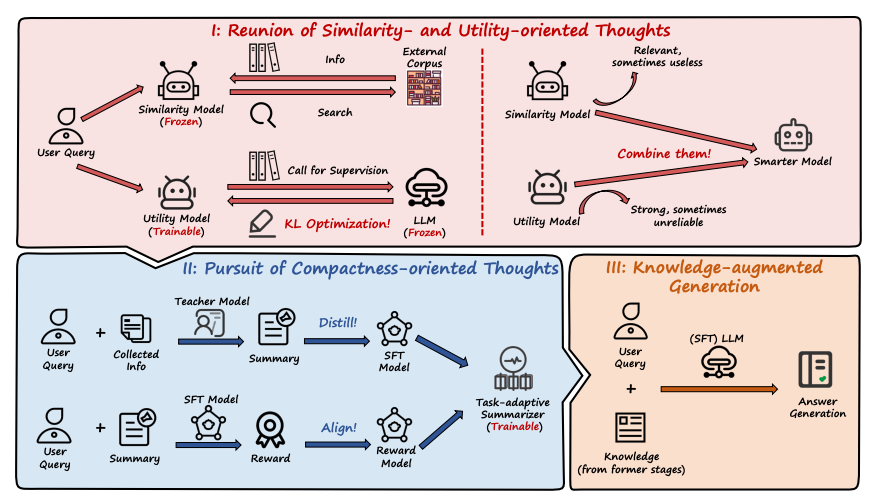
효용성 모델의 도입
LLM이 쿼리와 문서의 효용성을 판단하는 감독을 제공하도록 활용한다. 이를 통해 유사성만이 아니라 효용성 지향 사고를 갖춘 효용성 모델을 설계한다. LLM은 대부분의 경우 강력한 성능을 보이지만 가끔 통제 불가능한 경우가 있기 때문에, 안정적인 유사성 모델과 효용성 모델을 결합한다. 위의 그림과 같이 두 모델의 출력을 함께 고려한다.
간결성 지향 사고를 가진 요약 모델 훈련
강력한 교사 모델(ex. GPT-4)로부터 요약 모델을 증류(distillation)한다. 여러 요약본을 생성한 후, 보상 모델을 활용하여 요약 모델이 최종 작업에 맞게 조정되도록 추가로 제약을 가한다.
다층적 사고 시반의 지식 증강 생성
앞선 단게에서 얻은 다층적 사고(효용성과 간결성)을 활용하여 지식 증강 생성을 수행한다.
Related work
RAG는 입력 쿼리가 주어졌을 때 retrieve-then-read 파이프라인을 따라 LLM의 성능을 향상시키는 접근법이다. 이 파이프라인은 크게 두 단계로 이루어진다.
1. 문서 검색 단계: 외부 코퍼스에서 관련 문서를 검색한다.
2. 문서 활용 단계: 검색된 문서를 LLM이 최종 예측을 수행하는데 참고 정보로 활용한다.
기존 RAG 방식의 한계
1. 검색된 문서 품질의 중요성:
RAG 방식의 핵심은 검색된 문서의 품질이다. 그러나 많은 기존 접근법은 유사성을 기반으로 문서를 검색하며, 이 과정에서 문서의 실제 효용을 간과하는 경향이 있다.
2. LLM에만 의존한 검색의 위험성
Self-RAG와 REPLUG와 같은 최신 방법은 LLM의 강력한 능력을 활용해 검색 능력을 강화하거나 적용형 검색을 가능하게 했다. 그러나 LLM에만 전적으로 의존하는 것은 위험할 수 있다. LLM은 본질적으로 통제 불가능한 특성을 가지므로, 이로 인해 성능 저하가 발생할 수 있다.
3. 검색된 문서 간의 관계 무시
검색된 문서들이 가지고 있는 잠재적인 내적관계를 무시하고 문서를 개별적으로 활용하는 경향이 있다. 이러한 방식은 문서 간의 시너지를 발휘하지 못하고 결과적으로 RAG 성능 저하로 이어질 수 있다.
작업 지향 요약
대규모 상용 LLM을 사용하는 것은 높은 비용을 초래하며, 데이터 유출 문제가 발생할 가능성도 있다. 이러한 이유로, 대규모 LLM(ex. ChatGPT)의 능력을 소규모 LLM(Liama2)으로 증류하여 후속 작업에서 성능을 향상시키려는 접근법들이 등장했다.
문제점
1. 단순 요약의 한계
지식 집약적 작업에서 단순한 요약은 최적의 결과를 제공하지 못한다.
단순 요약 방식은 입력 쿼리와 관련된 가장 중요한 정보를 보장할 수 없다.
따라서, 후속 작업에 적합한 요약을 생성할 수 있어야 한다.
2. RECOMP의 제한점
질문 응답 및 언어 모델링과 같은 작업에서 성능 향상을 위해 요약 모델을 훈련하려는 시도를 했다. 그러나 복잡한 샘플을 설계하고 증류를 수행하는데 초점을 맞췄을뿐, 성능 향상을 위한 추가적인 정렬 전략은 도입하지 않았고 이로 인해, RECOMP는 실제 애플리케이션에서의 성능이 저하되었다.
따라서, 단순 요약을 넘어 입력 쿼리와 관련성이 높은 정보를 효과적으로 포함하는 작업 지향 요약이 필요하며, 대규모 LLM의 증류를 통해 소규모 LLM의 능력을 강화하되, 요약 과정이 후속 작업과 잘 정렬되도록 설계된 전략이 필요하다. 이러한 접근은 질문 응답, 언어 모델링, 기타 지식 집약적 작업에서 보다 높은 성능을 보장할 수 있다.
The proposed approach
METRAG는 유사성, 효용성 간결성을 결합한 다층적 사고를 기반으로 하여, 기존 RAG 모델보다 향상된 성능을 제공한다.
3.2. A Tale of Two Models
3.2.1. similarity model as an off-the-shelf-retriever
주어진 입력 쿼리 q에 대해, off-the-shelf dense retriever R을 사용하여 입력을 저차원 임베딩 E(⋅)으로 매핑한다. 이를 통해 주어진 코퍼스 D={d_1, d_2 ,…,d_n}에서 쿼리 q와 관련된 문서를 효율적으로 검색할 수 있다.
작동방식
유사성 점수 계산: 미리 정의된 유사성 척도 M(예: 코사인 유사도 등)을 사용하여 쿼리q와 각 문서 d_i 사이의 유사성 점수를 계산한다.
Top-K 문서 선택: 계산된 유사성 점수를 기반으로, 입력 쿼리 q와 가장 높은 유사성을 가진 문서 상위 k개를 선택한다.
후속 작업 강화: 선택된 D 문서들은 후속 작업(답변 생성, 정보 요약 등)을 강화하기 위한 입력 정보로 사용된다.
3.2.2. LLM의 감독을 통한 효용성 모델 강화
LLM의 강력한 능력을 활용하여 문서의 효용성에 대한 감독을 제공한다. 문서의 효용성은 쿼리에 대해 LLM이 올바른 답변을 생성하는데 기여하는 정도로 정의한다. 이를 모델링하기 위해, 특정 LLM을 사용해 정답을 생성할 확률을 정규화하여 문서의 효용성을 나타낸다.
검색기 R에 의해 쿼리 q와 가장 유사하다고 간주된 상위 n개의 문서 집합 D를 생성한다. 문서 효용성에 대한 LLM의 통찰을 검색기 R에 제공하여, 유사성 외에 문서가 제공하는 효용성도 고려하도록 학습된 효용성 모델을 생성한다.
유사성 분포를 효용성 분포로 점짐적으로 이동시키는 최적화 과정을 통해, 검색기 R가 단순히 유사성에 의존하지 않고 LLM의 감독을 반영한 효용성 지향 검색을 수행할 수 있도록 만든다.
3.2.3. Reunion of Similarity- and Utility oriented Thoughts
이 접근법을 통해 검색 성능을 최적화하면서도 RAG의 최종 결과 품질을 보장하는데 중요한 역할을 한다.
3.3. Pursuit of Compactness-oriented Thoughts
Task-adaptive Summarizer는 검색된 문서들을 처리하고 LLM의 효율성을 높이기 위해 설계된 요약 모델로, 다음과 같은 기능을 제공한다.
작업 정렬 요약: 단순 요약이 아닌, 답변 생성과 같은 후속 작업에 적합한 요약을 생성한다. 이를 통해 쿼리와 관련성이 높은 정보만을 유지한다.
LLM이 대량의 검색된 문서를 처리할 필요를 줄여, 계산 비용을 낮춘다.
LLM 부하 감소: 요약을 통해 간결성 지향 사고를 구현하여, LLM이 중요한 정보를 더 잘 식별할 수 있도록 돕는다.
3.3.1. Distilling from Strong Teacher Models
교사 모델의 전문성 증류: GPT-4와 같은 강력한 모델의 요약 능력을 소규모 모델(Llama2)로 증류한다.
작업 지향 학습: 학생 모델은 후속 작업의 요구 사항에 맞춰 최적화된 요약 모델로, 효율적이고 적합한 요약 결과를 제공한다.
LoRA 튜닝의 활용: 계산 비용을 최소화하면서도 학습 모델을 세밀히 조정하여 요약 품질을 높인다.
3.3.2 Alignment via End-task Feedback
Task-adaptive summarizer가 최종 작업의 요구에 맞춰 요약을 생성하도록 정렬한다. LLM의 응답 품질을 기반으로 요약 모델의 성능을 개선한다. DPO를 활용해 보상 모델 추정 과정을 간소화하고 최적화를 효율적으로 수행한다.
METRAG라는 다층적 사고를 강화한 RAG 프레임워크를 제안한다.
1. 효용성 지향 사고
LLM의 감독을 활용하여 문서의 효용성을 평가한다. 문서의 유사성과 효용성을 결합하여 성능을 향상한다.
2. 간결성 지향 사고
Task-adaptive Summarizer를 통해 검색된 문서의 정보를 통합하고, 가장 관련성이 높은 정보를 추출한다. 이를 통해 LLM의 효율성을 높이고 방해 요소를 줄인다.
3. 지식 증강 생성
이전 단계에서 얻은 다층적 사고를 기반으로 LLM을 활용하여 최종 답변을 생성한다.
한계
효용성 모델의 LLM 의존성
효용성 모델의 성능은 강력한 LLM 감독에 크게 의존한다. 그러나 실험 결과, Llama7B나 13B와 같은 상대적으로 소규모 LLM도 만족스러운 효용성 모델을 훈련하는데 충분함을 확인했다.
복잡한 상황에서의 제한
법률 문서나 의료 문서와 같이 대량의 자료를 읽고 답변을 생성해야하는 복잡한 상황은 여전히 해결되지 않은 과제로 남아있다.