
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
본 논문에서는 domain-adaptive pretraining이 고자원 및 저자원 환경 모두에서 성능 향상을 이끈다는 것을 보여준다. 더 나아가, task-adpative pretraining은 domain-adaptive pretraining 이후에도 성능을 개선한다. 마지막으로, 간단한 데이터 선택 전략을 사용하여 증강된 작업 코퍼스에 적용하는 것이 domain-adaptive pretraining을 할 수 없는 경우에 특히 효과적인 대안임을 보여준다. 전체적으로, 다단계 adaptive pretraining이 작업 성능에 큰 이점을 제공한다는 것을 일관되게 발견한다.
1. Introduction
오늘날의 PLM은 방대한 이질적인 말뭉치에서 학습된다. (RoBERTa는 160GB 이상의 비압축 텍스트로 학습되었다.) 하지만 이러한 모델들이 specific domain에 대해서도 보편적으로 작동하는지, 아니면 특정 도메인에 맞춘 별도의 사전 학습 모델을 구축하는 것이 여전히 도움이 되는지에 대한 의문이 제기된다.
기존 pretrain 연구는 최신의 LM보다 더 작고 덜 다양한 말뭉치에서 pretrain된 LM을 사용했다.
adaptive-pretraining이란, pretrained model을 초기 weight로 지정하고 추가로 pretraining하는 것을 의미한다.
본 실험에서는 이미 해당 도메인에 맞춰지지 않은 RoBERTa를 사용하여, domain-adaptive pretraining(DAPT)는 고자원 및 저자원 환경 모두에서 목표 도메인의 작업 성능을 일관되게 향상시켰다.
작업과 직접적으로 관련된 말뭉치에서 수행되는 tast-adaptive pretraining(TAPT)는 DAPT와 관계없이 RoBERTa의 성능을 크게 향상시킨다.
2. Background: Pretraining
RoBERTa는 BERT와 동일한 Transformer 기반의 아키텍처를 사용한다. RoBERTa의 사전 학습 말뭉치가 여러 출처에서 파생되었음에도 불구하고, 이 출처들이 영어의 대부분의 변화를 일반화할 수 있을 만큼 다양한지는 아직 입증되지 않았다. 따라서, 본 논문에서는 이 LM을 두 가지 범주(DAPT,TAPT)의 비라벨 데이터에 대해 pretraining을 추가로 진행한다.
3. Domain-Adaptive Pretraining
DAPT는 RoBERTa 모델을 대규모의 도메인 특화된 비라벨 텍스트로 추가적인 pretraining을 진행하는 방식이다.
3.1. Analyzing Domain Similarity
DAPT를 수행하기 전에, RoBERTa의 pretrained 도메인과 목표 도메인의 유사성을 평가한다.
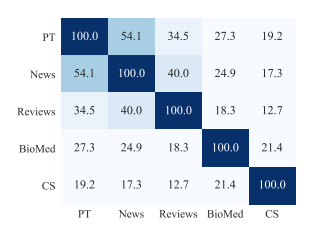
분석 결과 RoBERTa의 pretrained domain은 NEWs와 Reviews domain과 유사성이 높은 반면, CS와 BioMed domain과는 유사성이 낮았다. 이는 도메인이 더 유사하지 않을수록 DAPT에 의해 더 큰 잠재적 성능 향상을 기대할 수 있음을 보여준다.
3.2. Experiments
(Baseline) RoBERTa pretrained model로 각 domain에 대한 masked LM loss를 계산한다.
(DAPT) RoBERTa pretrained model을 초기 weight로 설정하고, 각 domain corpus를 활용해 추가로 pretraining을 진행하여 masked LM loss를 계산한다.

NEWS 도메인을 제외한 모든 도메인에서 masked LM Loss가 감소한 것을 알 수 있다. 특히 PT와 유사도가 낮은 BIOMED와 CS 도메인에서 성능 향상이 높게 나타나는데 이는 도메인 유사도가 낮을수록 DAPT의 잠재력이 높아짐을 시사한다.
(Baseline) Roberta pretrained 모델로 각 도메인의 downstream task에 대한 classification finetuning을 진행한다.
(DAPT) 각 도메인으로 추가 pretraining을 진행한 뒤에, classification finetuning을 진행한다.
(¬DAPT) 해당 task의 도메인과 무관한 도메인으로 추가 pretraining을 진행한 뒤에, classification finetuning을 진행한다.
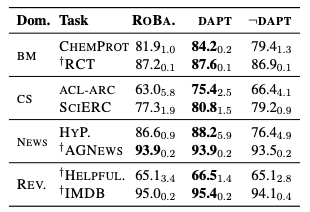
DAPT가 baseline보다 대부분 좋은 성능을 나타냈다. masked LM loss에서 시사했던 것처럼 BioMed와 CS domain에서 효과가 가장 두드러졌다.
3.3. Domain Relevance for DAPT
RoBERTa의 성능향상이 단순히 더 많은 데이터에 노출되었기 때문에 발생했는지, 도메인 관련 데이터의 영향인지 확인하기 위한 실험을 진행했다. 이 실험에서 각 작업에 대해 관련 없는 도메인의 언어 모델을 적용한다. 예를 들어 NEWS 작업에는 CS, REVIEWS 작업에는 BIOMED를 사용한다.
실험 결과, 모든 작업에서 DAPT는 관련 없는 도메인을 적응시킨 것보다 훨씬 우수한 성능을 보여, 도메인 관련 데이터로 pretrain하는 것이 중요하다는 것을 시사한다.
3.4. Domain Overlap
도메인 간 경계는 애매할 수 있다. 예를 들어 REVIEW와 NEWS는 40%의 단어를 공유한다. NEWS에 ROBERTA를 적응시키는 것이 REVIEWS 작업에서 크게 해롭지 않다는 것을 볼 수 있다.

도메인 간 유사도가 높다면, 다른 도메인이라 할지라도 효과적인 DAPT로 이어질 수 있다.
4. Task-adaptive Pretraining
작업 데이터가 넓은 도메인의 좁게 정의된 하위 집합일 때, 작업 데이터셋 자체나 해당 작업과 관련된 데이터로 pretraining하는 것이 유용할 수 있다고 가정한다.
4.1. Experiments
(TAPT) 각 도메인 별 task corpus로 추가 pretraining을 진행한 뒤에, classification finetuning을 진행한다.
(DAPT + TAPT) DAPT 모델에 task corpus를 추가 pretraining을 진행한 뒤에, classification finetuning을 진행한다.
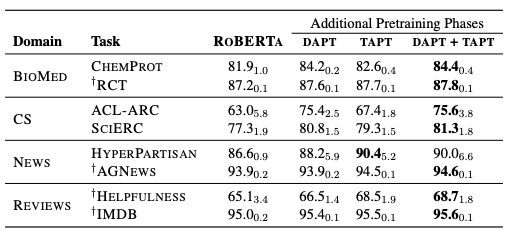
baseline 대비 TAPT가 모든 task에서 성능 개선을 보였다. DAPT 대비 적은 resource임에도 몇 가지 작업에서는 TAPT가 DAPT의 성능을 넘어서는 것을 볼 수 있다.
cross-task transfer

하나의 작업에 adapt시키는 것이 동일한 도메인의 다른 작업에도 transfer되는지 탐구해본다. 예를 들어, RCT의 비라벨 데이터를 사용하여 모델을 추가로 pretraining한 뒤, CHEMPROT의 라벨링 데이터를 사용하여 fine-tuning한다. 이 설정을 Transfer-TAPT라고 부른다.
실험 결과, TAPT는 단일 작업 성능을 최적화하지만, 작업간 transfer에는 부정적인 영향을 미친다.이는 같은 domain일지라도 task 별로 데이터 분포가 다를 수 있음을 시사한다.
5. Augmenting Training Data for Task-Adaptive Pretraining
TAPT에서 훈련 데이터를 증강하는 방법을 다룬다.
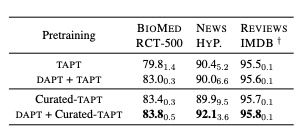
5.1. Human Curated-TAPT
사람이 직접 해당 도메인 내의 비라벨 말뭉치에서 task 관련 말뭉치를 선별한다.
Curated-TAPT를 추가한 것이 더 나은 성능을 보인다.
5.2. Automated Data Selection for TAPT
작업 분포에 맞는 비라벨 텍스트를 대규모 도메인 내 말뭉치에서 검색하는 간단한 비지도 학습 방법이다.
VAMPIRE라는 경량화된 bag-of-words 언어 모델을 사용한다. 도메인에서 중복 제거된 100만개의 문장 샘플에 대해 사전 학습되며, 이를 통해 작업 및 도메인 샘플의 텍스트 임베딩을 생성한다. 이후 각 작업 문장에 대해 도메인 샘플에서 k개의 후보를 선택하는데, 다음 두가지 방법으로 후보를 선택한다.
1. kNN-TAPT: 가장 가까운 이웃을 선택하는 방식
2. RAND-TAPT: 무작위로 선택하는 방식
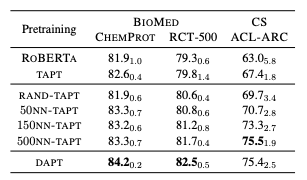
kNN-TAPT는 모든 경우에서 TAPT보다 우수한 성능을 발휘했다.
5.3. Computational Requirements
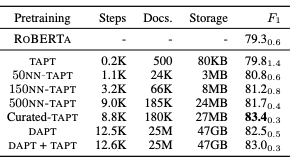
TAPT는 DAPT보다 훨씬 효율적이다.
Curated-TAPT는 가장 높은 비용 대비 성능 비용을 보여주었지만, 자동화된 방법인 kNN-TAPT는 DAPT보다 훨씬 저렴한 비용으로 작업을 수행할 수 있다.
7. conclusion
특정 작업이나 작은 말뭉치에 맞춰 모델을 pretrain하는 것이 큰 이점을 제공할 수 있다.
