[논문] EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
논문

EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
을 읽고 정리한 내용입니다.
abstract
EDA: Easy Data Augmentation, 텍스트 분류 작업에서 성능을 boosting해주는 기술이다.
EDA의 간단하지만 POWERFUL한 4가지 작업은 다음과 같다.
Synonym Replacement (SR)
Random Insertion (RI)
Random Swap (RS)
Random Deletion (RD)
우리 EDA는요,,,
특히 작은 데이터셋에서 강력한 결과를 나타냈다.
EDA를 사용해 훈련한 모델은 전체 데이터셋의 50%만 사용했음에도 불구하고 전체 데이터를 사용한 정상적인 훈련과 동일한 정확도를 달성했다.
Introduction
기계학습과 딥러닝에서 높은 성능은 종종 훈련 데이터와 양과 질에 크게 의존하지만 데이터를 수집하는 과정을 번거롭다.
그리고, 언어 변환을 위한 일반화된 규칙을 만들기 어려워서, NLP에서 보편적인 데이터 증강 기법은 아직 충분히 탐구되지 않았다.
이전에 제안되었던 NLP에서 데이터 증강기법을 소개하자면,
문장을 프랑스어로 번역한 뒤, 다시 영어로 변역하는 방식(새로운 데이터 생성)
데이터 노이징 기법을 사용한 스무딩
동의어 치환을 위한 예측 언어 모델
이 있다.
근데 이 모델들, 구현 대비 성능 향상이 크지 않아서 실무에서는 자주 사용되지 않는다.
그래서, 이 논문은 간단한 보편적인 NLP 데이터 증강 기법을 제안하고 있다. EDA가 텍스트 편집 기술을 데이터 증강에 사용한 최초의 포괄적인 연구라고 말한다. (후훗 내가 처음임)
또한, 특히, 작은 데이터셋에서 EDA가 유용함을 강조한다.
EDA
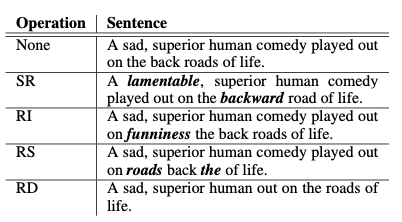
동의어 치환(Synonym Replacement): 랜덤으로 불용어가 아닌 n개의 단어를 선택해서 해당 단어의 동의어로 교체한다.
랜덤 삽입(Random Insertion): 불용어가 아닌 단어들 중에서 랜덤으로 선택하고 그 단어의 동의어를 임의의 자리에 넣는다. n번 반복한다.
랜덤 교체(Random Swap): 문장 내의 두 단어를 무작위로 선택하여 자리를 바꾼다. n번 반복한다.
랜덤 삭제(Random Deletion): 확률 p를 사용해서 문장의 단어를 무작위로 삭제한다.
공식 n=αl을 사용한다.
a는 문장 내 단어의 몇 퍼센트가 변경될지를 나타낸다. (RD에서 p=a)
Experimental Setup
5가지의 텍스트 분류 작업 벤치마크를 실행에서 사용했다.
Text Classification Model = LSTM-RNN, CNNs를 사용했다.
Results
EDA Makes Gains
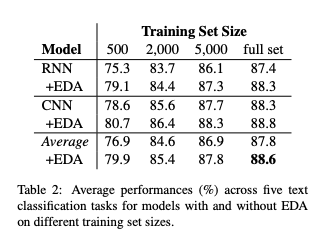
full set의 경우, 평균적으로 0.8%의 성능향상이 나타났다.
N_{train} = 500의 경우, 3.0%의 성능향상이 나타났다.
Training Set Sizing
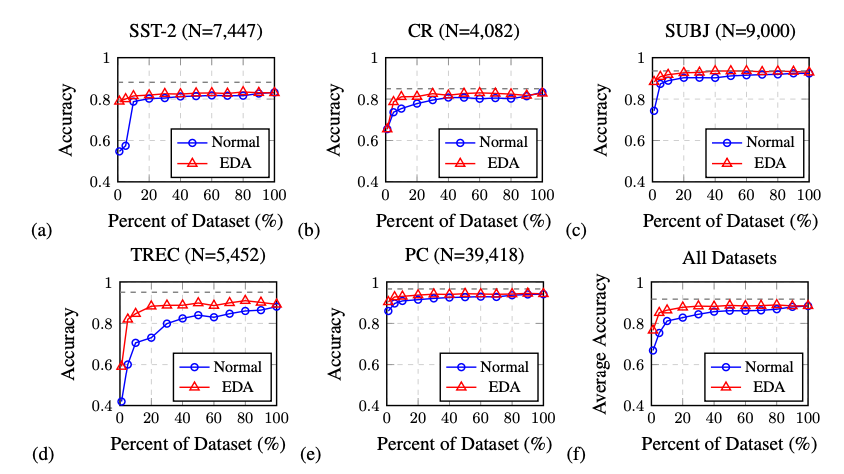
일반 훈련에서 데이터 증강 없이 가장 높은 평균 정확도는 88.3%로, 100%의 훈련 데이터를 사용할 때 달성되었다.
그러나 EDA를 적용한 모델은 전체 데이터의 50%만 사용했음에도 평균 정확도 88.6%를 기록하여, EDA를 사용하면 더 적은 데이터로도 더 좋은 성능을 얻을 수 있음을 보여주었다.
Does EDA conserve true labels?
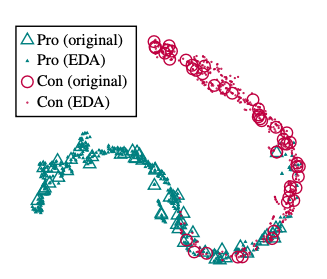
EDA가 원래 클래스 레이블을 유지하나요? 네 유지합니다.
먼저, 데이터 증강 없이 Pro-Con 분류 작업(PC)에서 RNN을 훈련시켰다. 그 후 테스트 세트에 대해 각 원래 문장당 9개의 증강된 문장을 생성하여 EDA를 적용했다. 이러한 증강된 문장과 원래 문장을 RNN에 입력하고, 마지막 밀집층(dense layer)에서 출력 벡터를 추출했다. 그런 다음 t-SNE(Van Der Maaten, 2014)를 사용하여 이 벡터들의 2D 표현을 시각화했다.
결과적으로, 증강된 문장의 잠재 공간 표현(latent space representations)은 원래 문장들의 표현과 밀접하게 군집을 이루는 것을 확인한다. 이는 EDA를 적용한 문장들이 대부분 원래 문장의 레이블을 잘 유지하고 있음을 보여준다,
Ablation Study(요소분석실험): EDA Decomposed
각각의 작업이 전체의 성능에 얼마나 영향을 미치는가?
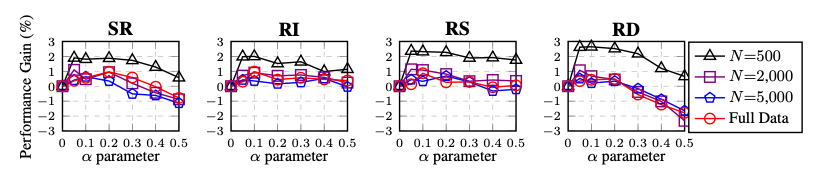
모두 성능향상에 기여를 하지만,
동의어 치환(SR): 작은 α 값에서는 성능이 좋았으나, α 값이 높아지면 성능이 저하된다. 이는 문장에서 너무 많은 단어를 교체하면 문장의 의미가 변질될 수 있기 때문.
랜덤 삽입(RI): 다양한 α 값에서도 성능 향상이 비교적 안정적이다. 이는 원래 문장 내 단어와 그 순서가 유지되기 떄문.
랜덤 교체(RS): α ≤ 0.2에서는 성능이 크게 향상되었으나, α ≥ 0.3에서는 성능이 하락했다. 이는 너무 많은 교체가 문장의 순서를 뒤섞어 문장이 본래 의미를 잃게 하기 때문.
랜덤 삭제(RD): 작은 α 값에서는 성능 향상이 두드러졌으나, α 값이 높아지면 성능이 급격히 떨어진다. 이는 문장의 절반 이상이 삭제되면 문장이 이해 불가능해지기 때문.
작은 데이터셋일수록 더 큰 성능 향상을 보였으며, α = 0.1이 전반적으로 가장 적절한 "sweet spot"이다.
How much augmentation?
한 문장 당 얼마나 증강을 해야하나요?
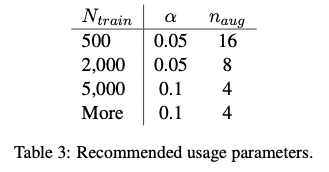
적은 훈련 셋에서는 오버피팅이 발생할 가능성이 높기 때문에, 문장을 많이 생성하면 성능향상을 얻을 수 있다.
많은 훈련 셋에서는 한 문장 당 4개의 증강이 적절하다.
Discussion and Limitations
작은 데이터셋에서는 성능 향상이 분명하지만, 사전 훈련된 모델을 사용할 경우 EDA의 성능 개선이 크지 않을 수 있다. 예를 들어, ULMFit을 사용한 연구에서는 EDA의 성능 향상이 거의 없었으며(Shleifer, 2019), ELMo나 BERT와 같은 모델에서도 유사한 결과가 나올 것이라고 예상하고 있다.
