
KLUE: Korean Language Understanding Evaluation 중 STS와 관련된 부분을 읽고 정리한 내용입니다.
Abstract
KLUE는 주제 분류, 의미적 텍스트 유사도, 자연어 추론, 개체명 인식, 관계 추출, 의존 구문 분석, 기계 독해, 대화 상태 추적 등 8가지 한국어 자연어 이해(NLU) 작업으로 구성된 컬렉션이다.
사전 학습된 언어 모델인 KLUE-BERT와 KLUE-RoBERTa를 공개한다.
Semantic Textual Similarity (STS)
의미적 텍스트 유사도(STS)는 두 문장 간의 의미적 동등성을 측정하는 작업이다. 기계 번역, 요약, 질의응답 등 다른 NLP 작업에 필수적이기 때문에 벤치마크에 포함시켰다.
GLUE의 STS와 마찬가지로, 많은 자연어 이해(NLU) 벤치마크는 의미 유사성, 패러프레이즈(의역) 감지, 단어 의미 구분과 같은 텍스트 조각 간의 의미적 유사성 비교 작업을 포함한다.
우리는 STS를 문장 쌍 회귀 작업으로 공식화하여 두 입력 문장의 의미적 유사성을 0점(의미 중복 없음)에서 5점(의미 동등) 사이의 실수 값으로 예측한다.
모델 성능은 STS-b 평가 체계를 따르며 Pearson 상관 계수를 통해 측정된다. 추가적으로, 실수 값을 임계값 3.0으로 이분화하여 두 가지 클래스로 나누고, F1 점수를 사용해 모델을 평가한다.
Data Construction
문장 쌍의 샘플링 전략
두 설명이 같은 이미지를 묘사하거나, 두 헤드라인이 같은 사건을 언급한다면, 추가 정보를 통해 유사성이 높을 가능성이 크다. 그렇지 않은 경우 유사성이 낮다.
사용 가능한 추가 정보를 활용하여 문장 쌍을 유사하거나 유사하지 않게 매칭했다. 추가 정보가 없을 경우, 유사한 문장 쌍을 얻기 위해 역방향 번역(RTT)를 사용하고, 덜 유사한 쌍을 얻기 위해 탐욕적 문장 매칭(GSM)을 적용했다.
PARAKQC (스마트 홈 발화) 전략
동일한 의도를 가진 두 문장을 유사한 쌍으로, 다른 의도를 가진 문장을 덜 유사한 쌍으로 매칭한다.
예를 들어, “오늘 서울 날씨 어때?”와 “오늘 서울 날씨 아시나요?”는 모두 오늘의 서울 날씨를 묻는 동일한 의도를 갖는다.
AIRBNB 및 POLICY 전략
RTT 기법
의미 유사성을 추정할 만한 의미있는 메타데이터를 찾을 수 없어서, 유사한 문장쌍을 생서하기 위해 NAVER Papago를 사용한 RTT 기법을 채택했다. RTT는 약간 다른 어휘적 표현을 가지면서도 원래 문장의 핵심 의미를 유지하는 문장을 생성한다. 중간 언어로는 영어를 선택했으며, 번역 시 한국어로 다시 변환할 때는 경어 옵션을 사용했다.
GSM(탐욕적 문장 매칭) 기법
덜 유사한 쌍을 만들기 위해, 가능한 모든 문장 쌍의 ROUGE 점수를 계산했다. 높은 점수는 더 높은 의미 유사성과 상관관계가 있다고 가정한다. 그런 다음, 가능한 쌍 중에서 가장 높은 점수를 가진 쌍을 추출하고, 남은 쌍 중에서 동일한 과정을 반복한다. 이 과정이 진행될수록 남은 쌍의 수가 줄어들어 점수가 점차 낮아지며, 덜 유사한 쌍이 생성된다.
Annotation Protocol
SemEval-2015에서 사용된 원래 주석 가이드를 수정했다. 해당 가이드는 두 문장을 청킹한 다음 청크 수준(명사구, 동사 연쇄, 전치사구 등)에서 유사성을 비교하도록 권장하며, 주석자는 이를 문장 수준의 유사성으로 종합해야한다고 제안했다.
하지만, 한국에서는 청킹이 매우 어렵기 떄문에 본 논문에서는 청킹 없이 유사성을 평가하고, 문장 수준 비교에 집중하였다.
문장 수준의 유사성 평가에서 중요한 내용은 문장의 주된 아이디어를 의미한다. 문장이 서술문이라면, 사실이나 설명, 정보를 제공하는 것이 중요하다. 문장이 의문문이나 명령문에서는 요청이나 명령을 전달하는 것이 중요하다. 감탄문에서는 감정이나 의견이 중요하다. 이외의 구성 요소는 중요하지 않은 내용으로 간주된다.
주석자는 아래 기준에 따라 유사성을 점수화한다:
- 5점: 두 문장이 중요하고 중요하지 않은 내용 면에서 완전히 동등함.
- 4점: 두 문장이 거의 동등함. 일부 중요하지 않은 내용에서 차이가 있음.
- 3점: 두 문장이 대체로 동등함. 중요한 내용은 비슷하지만, 중요하지 않은 내용에서의 차이가 무시할 수 없음.
- 2점: 두 문장이 동등하지 않음. 중요한 내용이 서로 비슷하지 않으며, 일부 중요하지 않은 내용만 공유함.
- 1점: 두 문장이 동등하지 않음. 중요한 내용과 중요하지 않은 내용 모두 비슷하지 않으며, 두 문장은 주제만 공유함.
- 0점: 두 문장이 동등하지 않음. 중요한 내용, 중요하지 않은 내용, 심지어 주제도 공유하지 않음.
주석자들은 문장의 맥락을 고려해야한다. 만약 맥락이 두 문장의 의미를 구별하는데 크게 영향을 미친다면, 점수는 낮게 부여되어야 한다.
예를 들어, “체크인은 호스트가 아닌 다른 사람에 의해 완료되었다.”와 “체크인은 누군가에 의해 완료되었다”라는 두 문장이 있을 때, 두 문장의 의미차이는 무시할 수 없게 되므로 3점을 받게 된다.
“체크아웃은 호스트가 아닌 다른 사람에 의해 완료되었다.”와 비교할 경우, 2점이 부여된다.
Evaluation Metrics
Pearson’s correlation coefficient (Pearson’ r)
Pearson의 상관계수는 인간이 레이블한 문장 유사성 점수와 모델이 예측한 점수 간의 선형 상관관계를 측정하는 지표
F1 score
분화된 결과(패러프레이즈됨 / 패러프레이즈되지 않음)를 측정하기 위해 사용. 패러프레이즈된 클래스에 대한 결과를 보고한다.
Sentence Pair Classification / Regression
KLUE-STS는 문장 쌍 분류/회귀 작업이다.
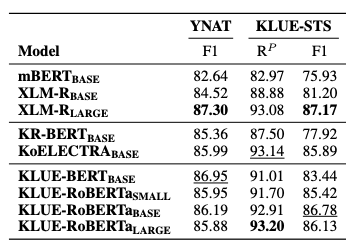
Dev Set Results
Fine-Tuning Configurations
| LOSS | MSE | L1 | ||
|---|---|---|---|---|
| LEARNING RATE | 1e-5 | 2e-5 | 3e-5 | 5e-5 |
| WARM-UP RATIO | 0. | 0.1 | 0.2 | 0.6 |
| weight decay | 0.0 | 0.01 | ||
| BATCH SIZE | 8 | 16 | 32 | |
| EPOCHS | 3 | 4 | 5 | 10 |
