[번역] Fundamentals of Data Visualization - 11 Visualizing nested proportions
Fundamentals of Data Visualization

11 Visualizing nested proportions
데이터셋을 여러 범주형 변수에 따라 동시에 세분화하여 분석하고 싶은 경우도 종종 있습니다. 예를 들어, 의회 의석의 경우, 정당별 의석 비율과 대표자의 성별에 따른 의석 비율에 관심을 가질 수 있습니다. 비슷하게, 사람들의 건강 상태에 대해 이야기할 때, 건강 상태가 결혼 상태에 따라 어떻게 세분화되는지 궁금할 수도 있습니다.
중첩된 비율을 시각화하는 데 적합한 몇 가지 방법이 있으며, 그 중에는 모자이크 플롯(mosaic plot), 트리맵(treemap), 평행 집합(parallel sets) 등이 있습니다.
11.1 Nested proportions gone wrong
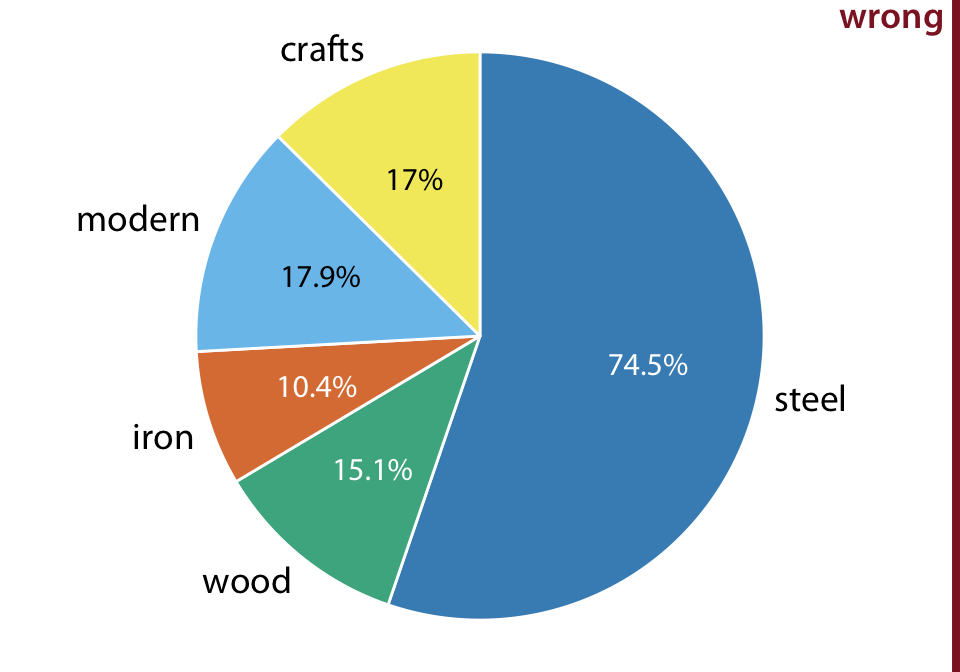
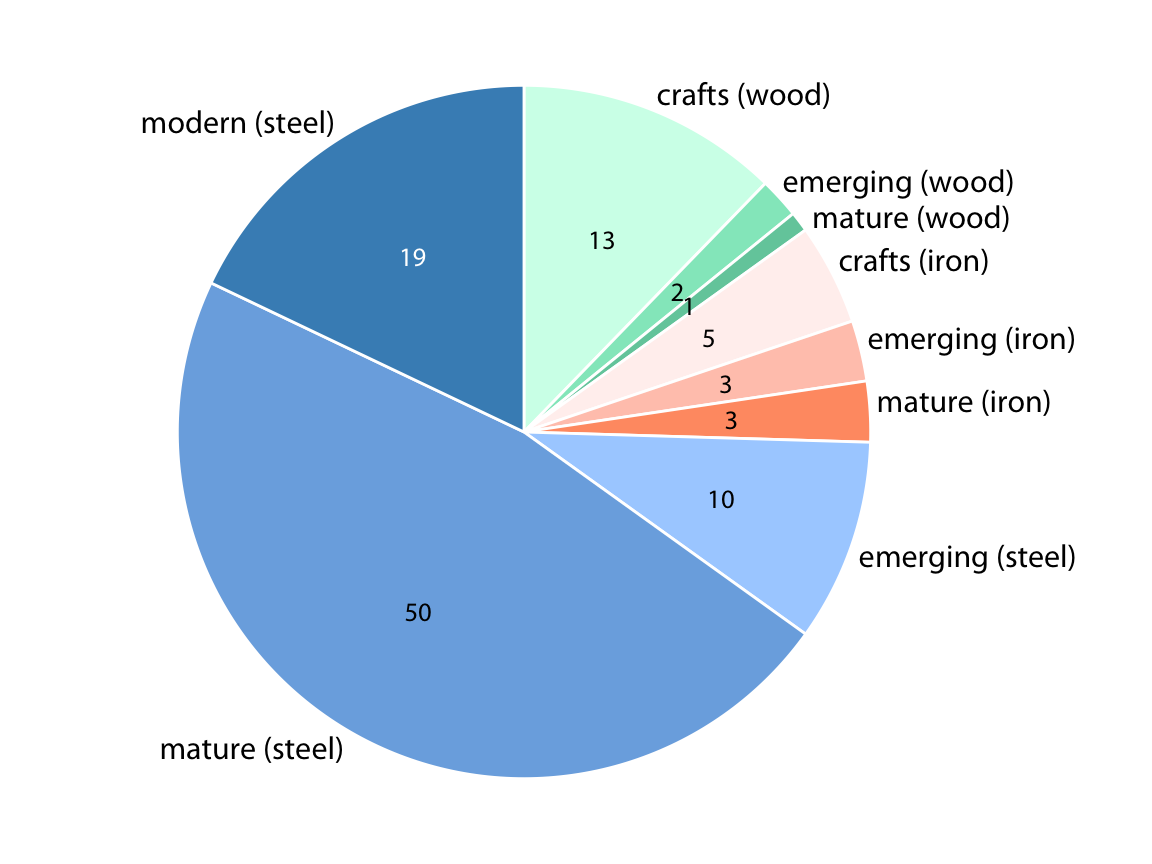
피츠버그의 다리들을 건설 재료(강철, 목재, 철)와 건설 연도(수공예, 1870년 이전; 현대적, 1940년 이후)에 따라 나눈 비율을 파이 차트로 나타낸 것입니다. 각 유형의 다리가 전체 다리에서 차지하는 비율을 숫자로 표시하고 있습니다. 그러나 이 그림은 잘못된 것입니다. 왜냐하면 이 비율들이 100%를 넘기 때문에 유효하지 않기 때문입니다. 건설 재료와 건설 연도 간에 중복이 있기 때문에 이러한 문제가 발생합니다. 예를 들어, 모든 현대적 다리는 강철로 만들어졌고, 대부분의 수공예 다리는 목재로 만들어졌습니다.
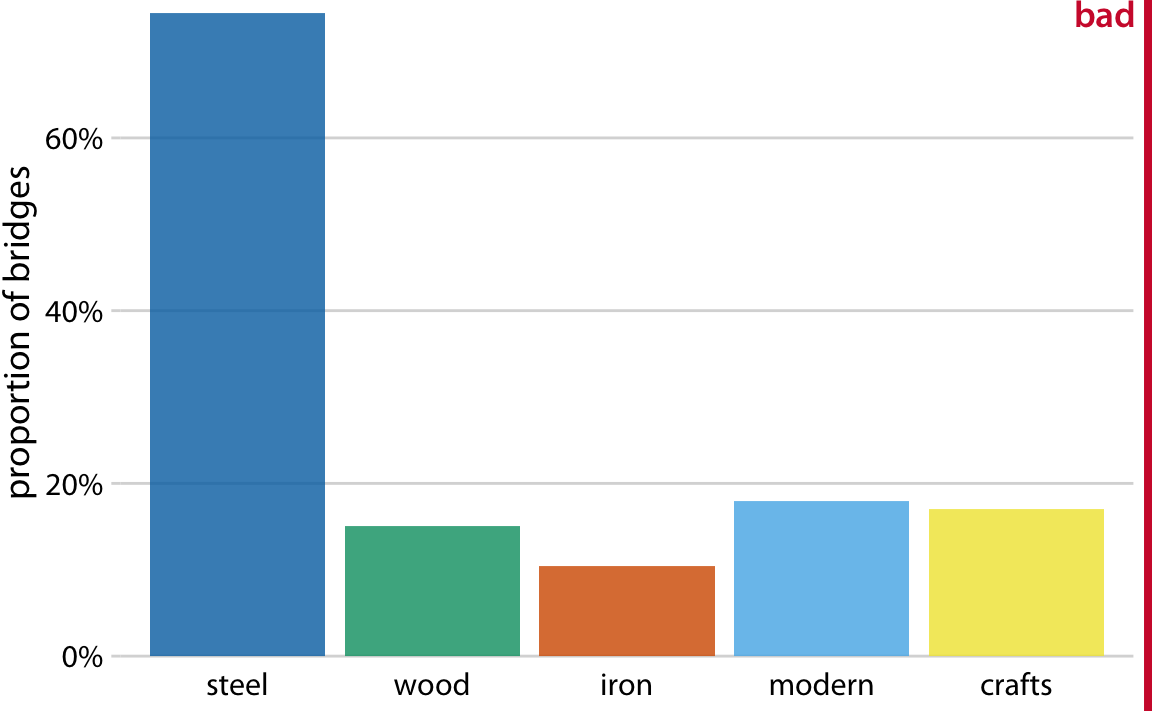
중복 계산이 항상 문제인 것은 아닙니다. 100%로 합산될 필요가 없는 시각화를 선택하면 됩니다. 이전 장에서 논의한 바와 같이, 나란히 배치된 막대 그래프는 이러한 기준을 충족시킵니다. 여러 유형의 다리들을 하나의 플롯에서 막대로 보여줄 수 있으며, 이는 기술적으로 틀린 것은 아닙니다(그림 11.2). 그럼에도 불구하고 이 그림에 "나쁨"이라는 레이블을 붙인 이유는, 일부 범주가 겹친다는 점을 즉시 보여주지 않기 때문입니다. 그림 11.2를 보고 대충 보면, 다섯 개의 별도 범주가 존재한다고 오해할 수 있으며, 예를 들어, 현대적 다리가 강철이나 목재, 철로 만들어지지 않았다고 결론지을 수도 있습니다.
범주가 겹치는 경우에는 서로 어떻게 관련되어 있는지를 명확하게 보여주는 것이 가장 좋습니다. 이를 모자이크 플롯으로 할 수 있습니다.
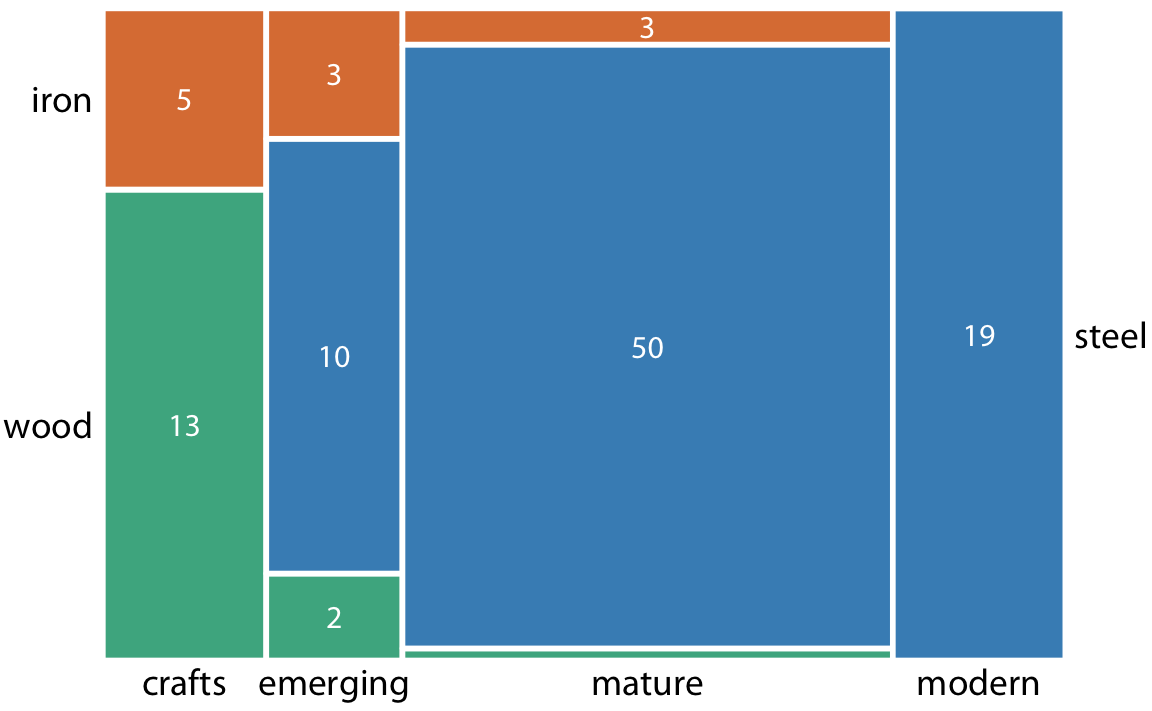
두 개의 추가 건설 시기, 즉 'emerging'(1870년부터 1889년까지)과 'mature'(1890년부터 1939년까지)를 볼 수 있습니다. '수공예'와 '현대적'이라는 시기와 결합하여, 이 건설 시기들은 데이터셋의 모든 다리를 포함하며, 세 가지 건설 재료 역시 마찬가지입니다. 이는 모자이크 플롯의 중요한 조건입니다. 표시된 모든 범주형 변수는 데이터셋의 모든 관측치를 포함해야 합니다.
이 다리 데이터셋은 트리맵이라는 형식으로도 시각화할 수 있습니다. 트리맵에서는 모자이크 플롯과 마찬가지로, 전체 사각형을 비율을 나타내는 더 작은 사각형으로 세분화합니다. 그러나 작은 사각형을 큰 사각형 안에 배치하는 방법이 모자이크 플롯과 다릅니다. 트리맵에서는 사각형들을 서로 안쪽에 재귀적으로 중첩시킵니다. 예를 들어, 피츠버그 다리의 경우, 전체 면적을 먼저 세 가지 건설 재료(목재, 철, 강철)를 나타내는 부분으로 나누고, 그런 다음 각 건설 재료의 면적을 건설 시기에 따라 다시 세분화할 수 있습니다. 이론적으로는 계속해서 더 작은 세분화를 중첩시킬 수 있지만, 그럴 경우 결과가 금세 다루기 힘들거나 혼란스러워질 수 있습니다.

11.3 Nested pies
첫내부 원과 외부 원으로 구성된 파이 차트를 그릴 수 있습니다. 내부 원은 한 변수(여기서는 건설 재료)에 따른 데이터를 보여주고, 외부 원은 내부 원의 각 조각을 두 번째 변수(여기서는 다리 건설 시기)에 따라 나눈 비율을 보여줍니다. 이 시각화는 합리적이지만, 나는 약간의 우려가 있어 이를 "보기 싫음(ugly)"이라고 표시했습니다. 가장 중요한 문제는 두 개의 별도 원이 데이터셋의 각 다리가 건설 재료와 다리 건설 시기를 모두 가진다는 사실을 흐리게 한다는 점입니다. 결과적으로, 여전히 각 다리를 이중으로 계산하고 있습니다. 두 개의 원에 표시된 모든 숫자를 합치면 212가 되는데, 이는 데이터셋에 있는 다리 수의 두 배입니다.
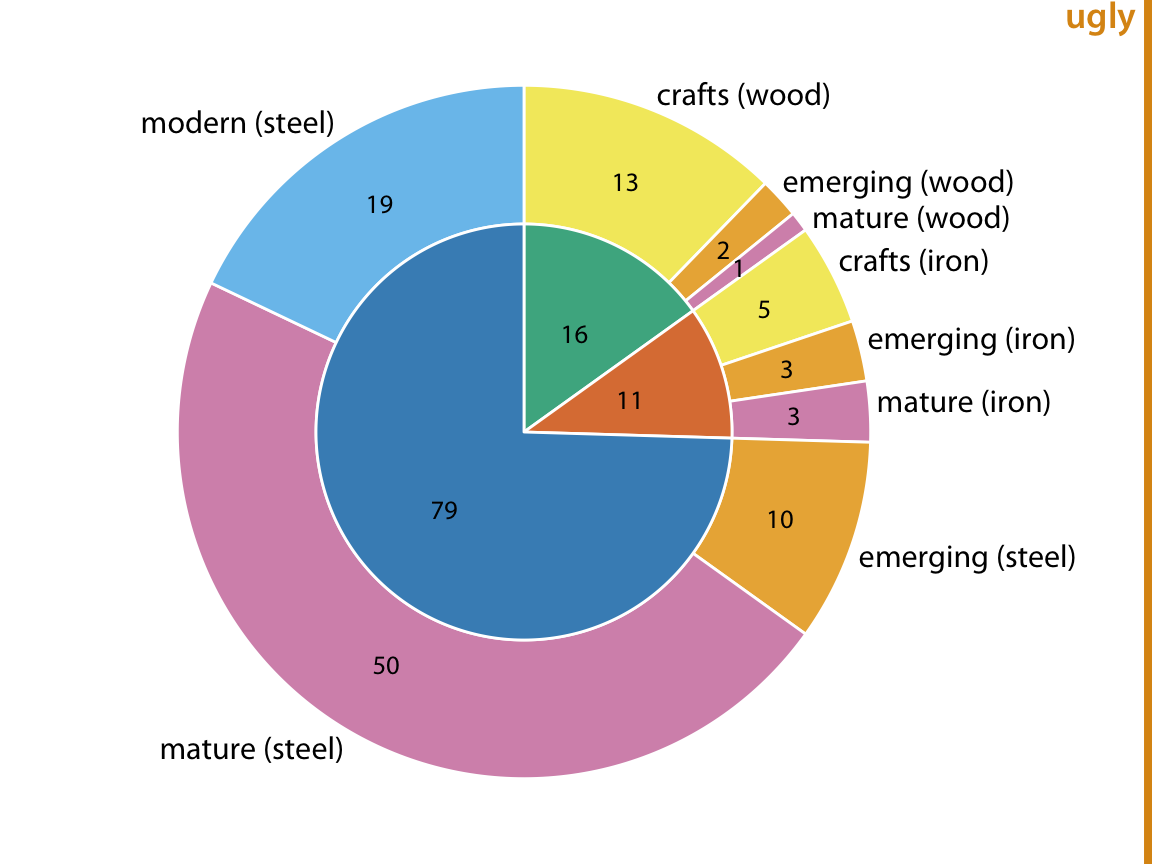
다른 방법으로, 파이를 먼저 한 변수(예: 재료)에 따라 비율로 나누고, 그런 다음 이 조각들을 다른 변수(건설 시기)에 따라 추가로 세분화할 수 있습니다(그림 11.7). 이렇게 하면 결과적으로 많은 작은 파이 조각이 있는 일반적인 파이 차트를 만들게 됩니다. 그러나 색상을 사용하여 파이의 중첩된 특성을 나타낼 수 있습니다.
11.4 Parallel sets
평행 집합 플롯에서는 전체 데이터셋이 각 개별 범주형 변수에 따라 어떻게 나뉘는지를 보여준 다음, 하위 그룹들이 서로 어떻게 연결되는지를 나타내는 음영 밴드를 그립니다.
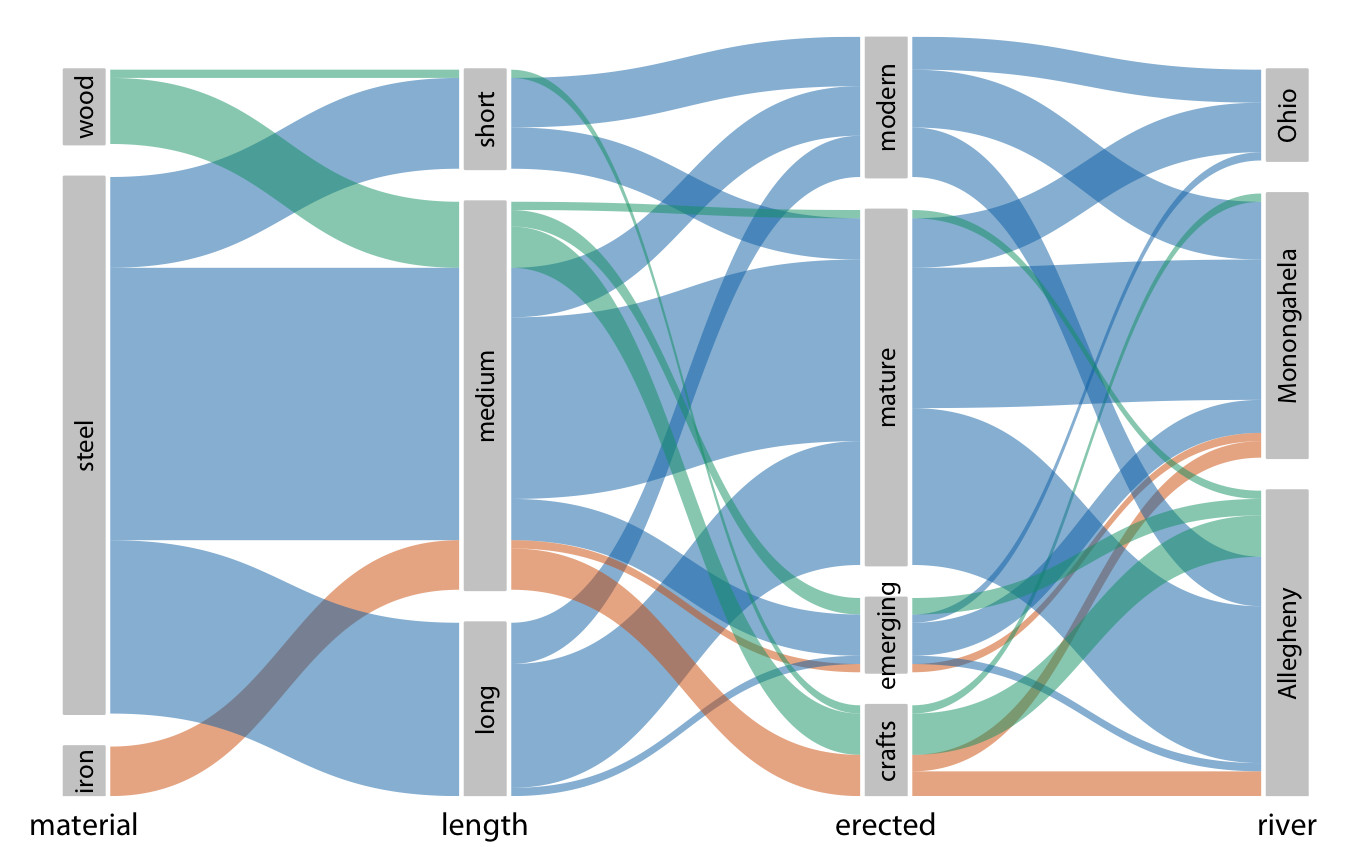
목재 다리들은 대부분 중간 길이이며(짧은 다리 몇 개 포함), 주로 수공예 시기에 건설되었고(몇 개의 중간 길이 다리는 emerging 및 mature 시기에 건설됨), 주로 Allegheny 강에 걸쳐 있다는 것을 보여줍니다(수공예 다리 몇 개는 Monongahela 강에 걸쳐 있음). 반면, 철제 다리는 모두 중간 길이이며, 주로 수공예 시기에 건설되었고, Allegheny와 Monongahela 강에 거의 같은 비율로 걸쳐 있습니다.
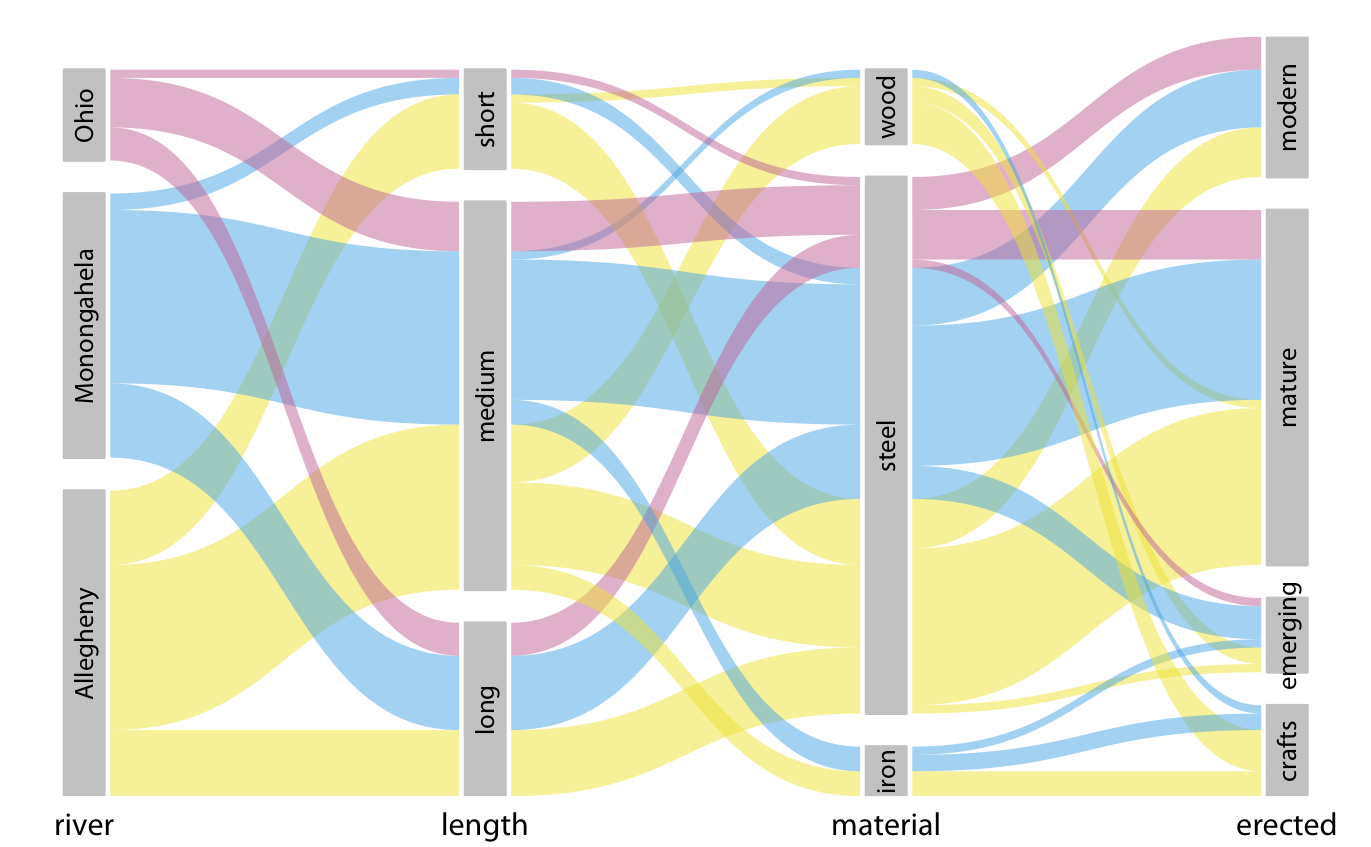
같은 시각화도 색상을 다른 기준, 예를 들어 강에 따라 색칠하면 전혀 다른 모습이 됩니다.
첫째, 우리는 일반적으로 왼쪽에서 오른쪽으로 읽는 데 익숙하기 때문에, 색상을 정의하는 집합은 오른쪽이 아니라 왼쪽에 배치되어야 한다고 생각합니다. 이렇게 하면 색상이 어디에서 시작되는지, 그리고 데이터셋을 통해 어떻게 흐르는지 더 쉽게 볼 수 있습니다. 둘째, 교차하는 밴드의 양을 최소화하기 위해 집합의 순서를 변경하는 것이 좋습니다.
