[번역] Fundamentals of Data Visualization - 2 Visualizing data: Mapping data onto aesthetics
Fundamentals of Data Visualization

2 Visualizing data: Mapping data onto aesthetics
우리가 데이터를 시각화할 때, 데이터 값을 체계적이고 논리적인 방식으로 변환하여 최종 그래픽을 구성하는 시각적 요소로 만듭니다. 데이터 시각화는 위치, 크기, 색상, 모양, 선의 너비 등 미학적 요소를 사용하여 데이터를 시각적으로 표현하는 과정입니다.
2.1 Aesthetics and types of data
모든 그래픽 요소의 중요한 구성 요소는 그 위치입니다. 이는 요소가 어디에 위치하는지를 설명합니다. 다음으로, 모든 그래픽 요소는 모양, 크기, 색상을 가지고 있습니다. 마지막으로, 데이터를 시각화하기 위해 선을 사용할 경우, 이 선들은 다른 너비나 점선–실선 패턴을 가질 수 있습니다.
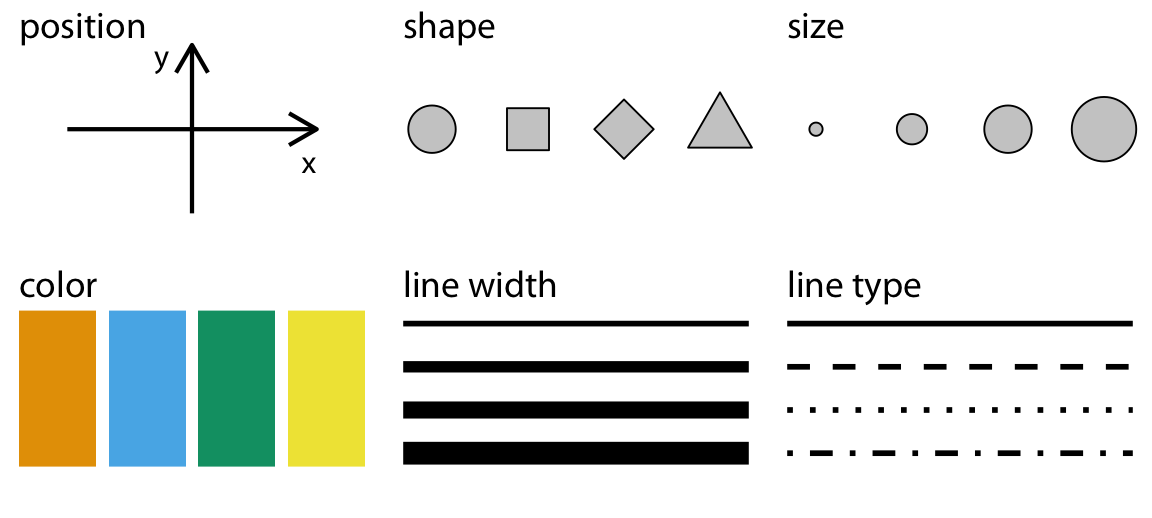
모든 미학적 요소는 연속적 데이터를 표현할 수 있는 것과 그렇지 않은 것, 두 그룹 중 하나에 속합니다. 연속적 데이터 값은 임의로 세분화할 수 있는 중간값이 존재하는 값입니다. 예를 들어, 시간의 지속 시간은 연속적 값입니다. 반면, 방 안의 사람 수는 이산적 값입니다. 위치, 크기, 색상, 선의 너비는 연속적 데이터를 표현할 수 있지만, 모양과 선의 유형은 보통 이산적 데이터만을 표현할 수 있습니다.
다음으로, 시각화에서 표현하고자 하는 데이터 유형을 고려해 보겠습니다.
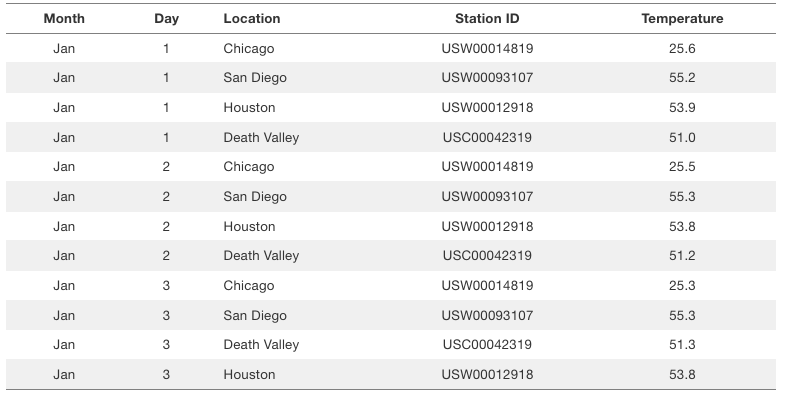
이 표는 미국의 네 지역에 대한 일일 온도 기준값(30년 동안의 평균 일일 온도)을 제공하는 데이터셋의 처음 몇 개의 행을 보여줍니다. 이 표에는 다섯 가지 변수가 포함되어 있습니다: 월, 일, 위치, 측정소 ID, 그리고 온도(화씨 단위). 월(month)은 순서가 있는 요인(ordered factor)이고, 일(day)은 이산적 숫자 값(discrete numerical value)입니다. 위치(location) 는 순서가 없는 요인(unordered factor)이며, 측정소 ID(station ID) 도 마찬가지로 순서가 없는 요인입니다. 마지막으로, 온도(temperature) 는 연속적 숫자 값(continuous numerical value)입니다.
2.2 Scales map data values onto aesthetics
데이터 값을 미학적 요소로 매핑하기 위해서는, 어떤 데이터 값이 특정 미학적 요소 값에 해당하는지 지정해야 합니다. 중요한 점은, 스케일은 일대일 대응이어야 하며, 각 특정 데이터 값에는 정확히 하나의 미학적 요소 값이 대응하고 그 반대도 마찬가지여야 한다는 것입니다. 만약 스케일이 일대일 대응이 아니라면, 데이터 시각화는 모호해지게 됩니다.
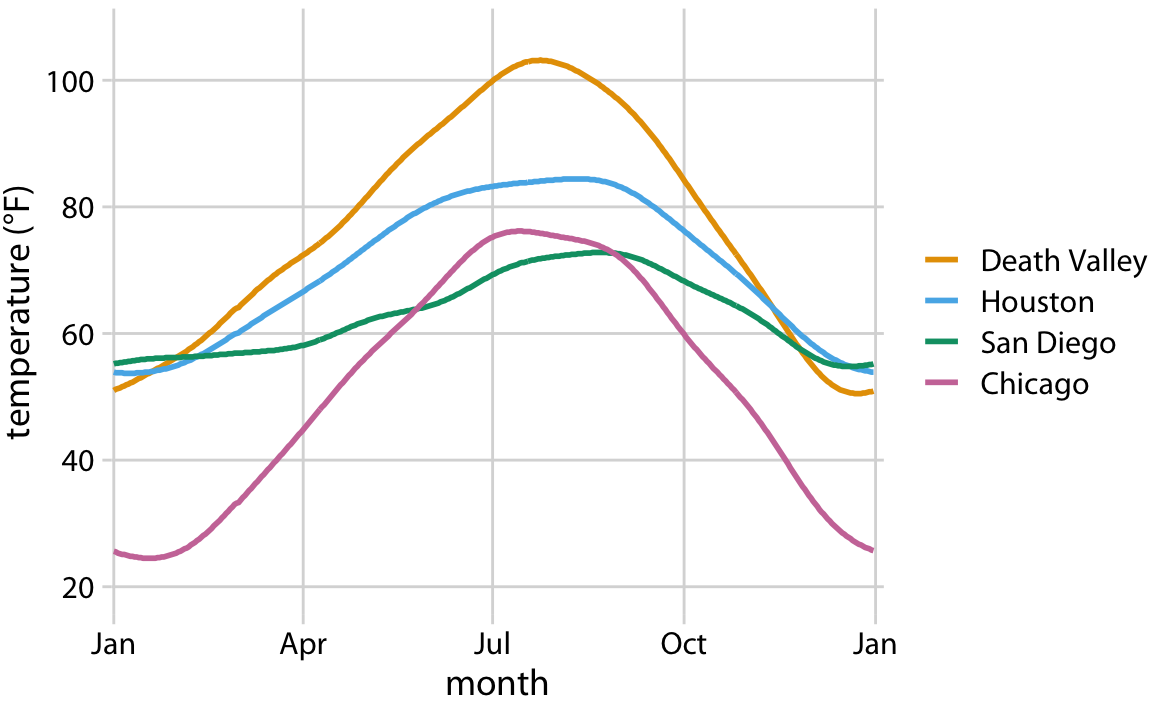
이제 실제로 적용해 봅시다. 온도를 y축에, 연중 날짜(day of the year)를 x축에, 위치(location)를 색상에 매핑하고, 이 미학적 요소들을 실선으로 시각화할 수 있습니다. 그 결과는 한 해 동안 네 지역에서 온도 기준값이 어떻게 변화하는지를 보여주는 표준 선 그래프가 됩니다.
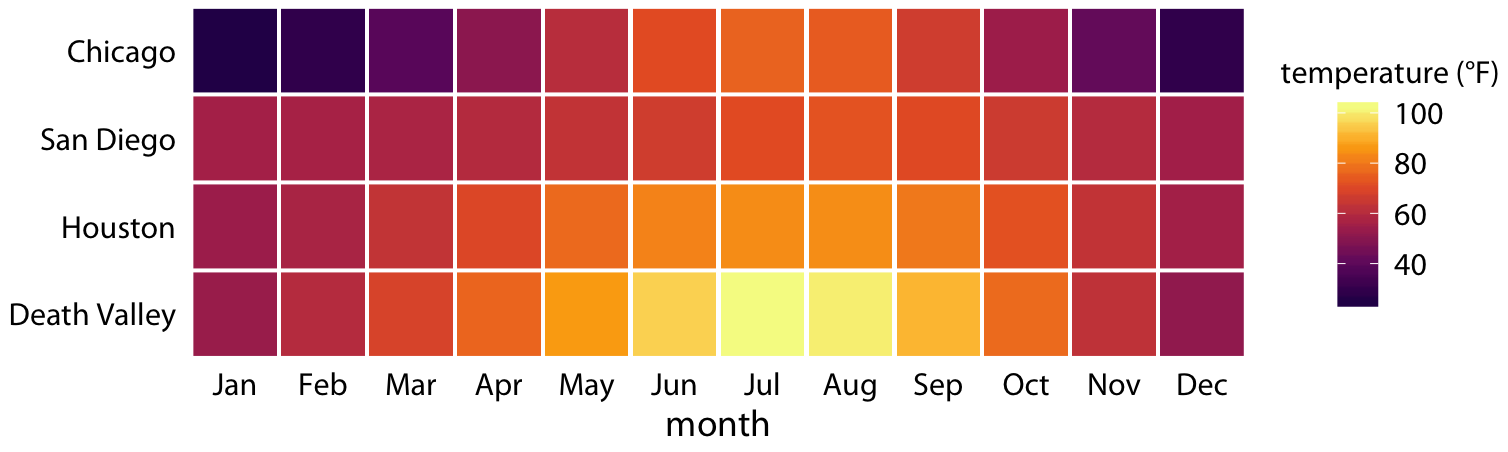
반대로 주요 관심 변수인 온도가 색상으로 표시되므로, 색상이 유용한 정보를 전달할 수 있도록 충분히 큰 색상 영역을 보여줘야 합니다. 따라서 이 시각화에서는 선 대신 각 월과 위치에 하나씩 사각형을 선택했으며, 각 월의 평균 온도 기준값에 따라 색상을 입혔습니다.
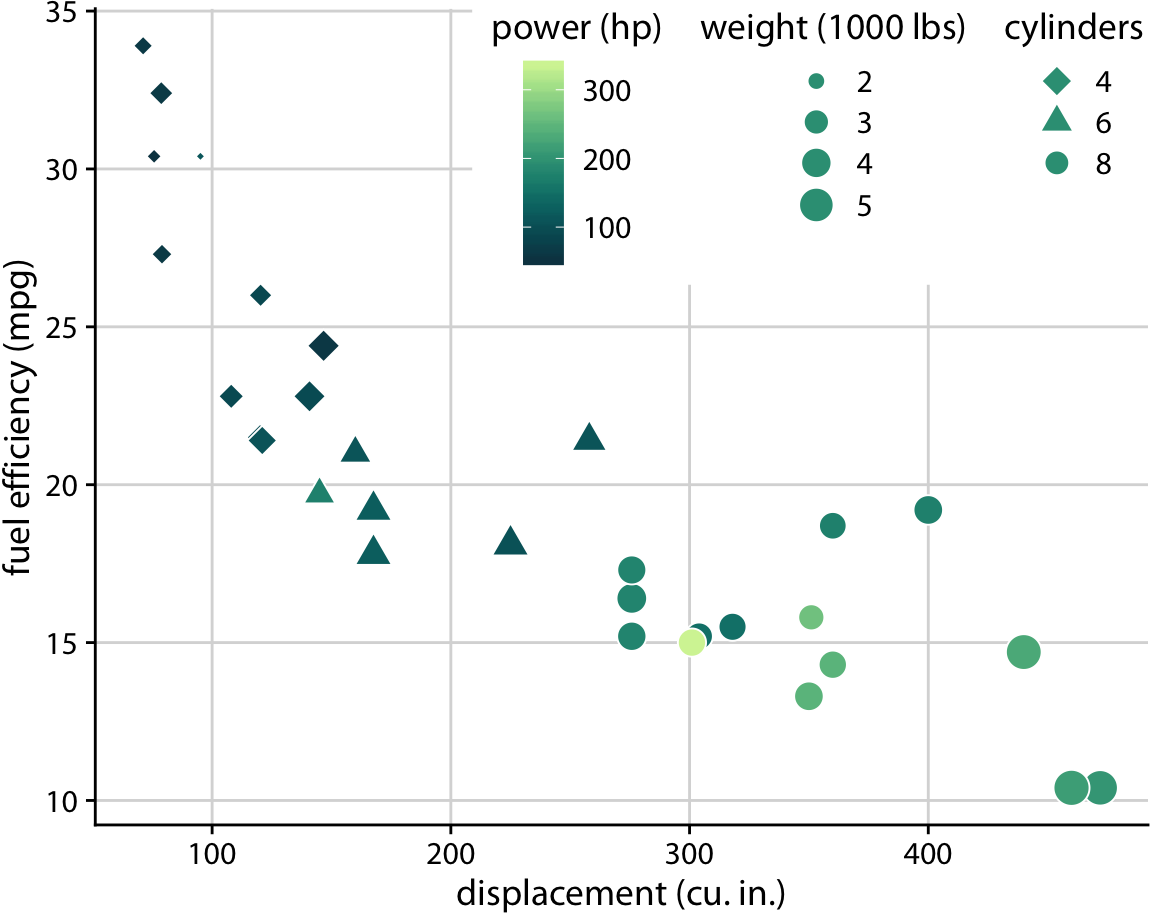
한 번에 세 개 이상의 스케일을 사용할 수도 있습니다. 이 도표는 데이터를 나타내기 위해 다섯 개의 별도 스케일을 사용합니다: (i) x축(displacement,배기량); (ii) y축(fuel efficiency,연비); (iii) 데이터 포인트의 색상(power); (iv) 데이터 포인트의 크기(weight); (v) 데이터 포인트의 모양(cylinders).
