
Real-time machine learning: challenges and solutions
Towards Online Prediction
Continual Learning이 주류로 자리잡기까지는 아직 몇 년이 남았다고 생각하지만, 많은 기업들이 Online Inference로 전환하기 위해 상당한 투자를 하고 있다. 이번 글에서는 Batch Prediction System으로 시작하여 Session-based Adaptation에 유용한 배치 피처를 사용하는 간단한 온라인 예측 시스템을 구축하기 위해 필요한 것들을 살펴본다. (예: 웹사이트나 모바일 앱 내에서 사용자의 활동을 기반으로 한 예측 제공). 그런 다음, 복잡한 스트리밍 피처와 배치 피처(streaming + batch features)를 모두 활용하는 보다 성숙한 온라인 예측 시스템으로 전환하는 방법을 논의한다.
Stage 1. Batch prediction
이 단계에서는 모든 예측이 배치 단위로 사전 계산되며, 일정한 간격(예: 4시간마다 또는 하루 단위)으로 생성된다. 배치 예측의 일반적인 사용 사례는 협업 필터링(Collaborative Filtering), 콘텐츠 기반 추천(Contents-Based Recommendations)이다. 배측 예측을 사용하는 대표적인 기업으로는 2021년 기준 Netflix의 추천 시스템이 있다. 이 글을 작성하는 시점에서 Netflix는 예측 시스템을 온라인 방식으로 전환하고 있다.
배치 예측에는 여러 가지 제한사항이 있다. 예를 들어, 방문자 중 절반이 새로운 사용자이거나 로그인을 하지 않은 상태인 전자상거래 웹사이트를 생각해보자. 이 방문자들은 새로운 사용자이기 때문에 이들에게 개인화된 사전 계산 추천이 없다. 다음 배치 추천이 생성될 때까지 이 방문자들은 이미 구매 없이 사이트를 떠났을 가능성이 높다. 그 이유는 그들에게 적절한 추천이 제공되지 않았기 때문이다.
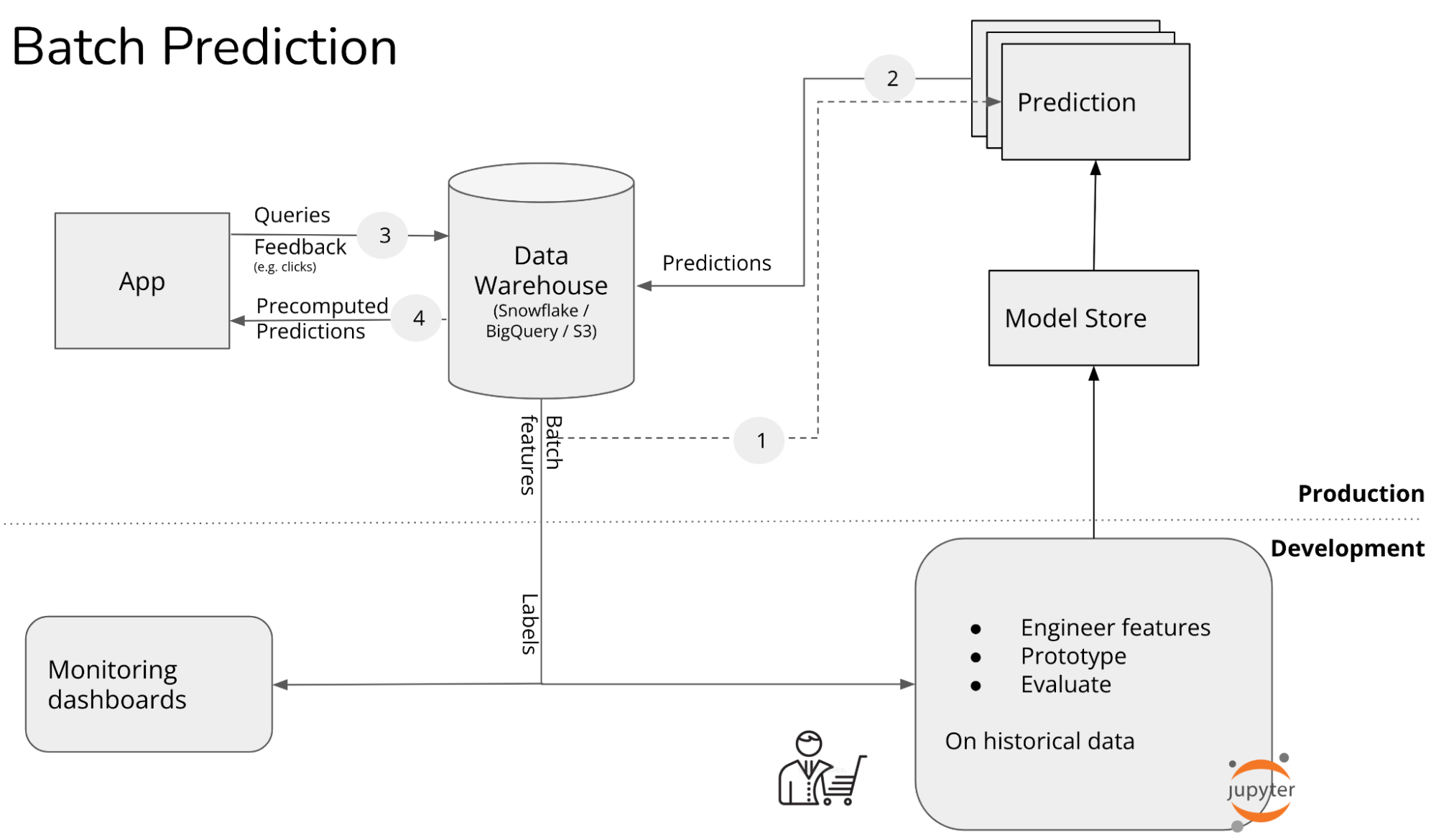
지난 10년동안 빅데이터 처리는 주로 MapReduce나 Spark와 같은 배치 시스템에 의해 지배되었다. 이러한 시스템은 대량의 데이터를 주기적으로 매우 효율적으로 처리할 수 있도록 해준다. 기업들이 머신러닝을 처음 도입했을 때, 기존의 배치 시스템을 활용해 예측 작업을 수행하기 시작했다.
그러나 오늘날 새로운 머신러닝 시스템을 구축한다면, 굳이 배치 예측을 거치지 않고 온라인 예측으로 시작하는 것이 가능하다.
Stage 2. Online prediction with batch features
이 단계에서는 요청이 도착하기 전에 예측을 생성하는 대신, 요청이 도착한 후 예측을 생성한다. 기업들은 앱에서 사용자 활동을 실시간으로 수집하지만, 이러한 이벤트는 사전 계산된 임베딩을 조회하여 세션 임베딩을 생성하는데만 사용된다. 스트리밍 데이터에서 실시간으로 피처를 계산하지는 않는다.
전자상거래 웹사이트를 예시로 들면, 새로운 방문자가 웹사이트를 방문할 때 그들에게 일반적인 아이템을 추천하는 대신, 그들의 활동을 기반으로 아이템을 추천한다.
에를 들어, 방문자가 키보드와 컴퓨터 모니터를 살펴봤다면, 이는 재택 근무 환경을 찾고 있을 가능성을 나타냅니다. 따라서 알고리즘은 HDMI 케이블이나 모니터 거치대와 같은 관련 아이템을 추천해야한다.
실시간 데이터 수집 및 세션 임베딩 생성
이를 구현하려면 방문자의 활동을 발생하는 즉시 수집하고 처리해야한다.
방문자가 아이템1, 아이템10, 아이템20을 살펴봤다면, 데이터 웨어하우스에서 해당 아이템들의 임베딩을 가져온다, 이 임베딩들은 평균값 등으로 결합되어 해당 방문자의 현재 세션 임베딩을 생성한다.
가장 관련성 높은 아이템 찾기
생성된 세션 임베딩을 기반으로 가장 관련성 높은 아이템을 찾아야한다.
단순하게는 모든 아이템을 모델로 점수화하고 가장 높은 점수를 가진 아이템을 방문자에게 보여줄 수 있다. 그러나 웹사이트에 수백만 개의 아이템이 있을 수 있으며, 모든 아이템을 점수화하는데 시간이 오래 걸릴 수 있다. 방문자가 추천 결과를 기다리게 하는 것은 바람직하지 않다.
후보 생성
대부분의 기업은 아이템-아이템 협업 필터링(collaborative filtering)이나 k-nearest neighbors와 같은 알고리즘을 사용하여 소수의 후보 아이템을 생성한다.
이후 이 후보 아이템만 점수화하며 방문자에게 가장 높은 점수의 아이템을 추천한다.
Stage 3. Online prediction with online features
온라인 예측 시스템은 Batch Features와 Online Features를 모두 사용할 수 있다.
Batch Features: 과거 데이터를 기반으로 배치 처리를 통해 추출된 피처. 주기적으로 사전 계산된다. 예측 요청 시 빠르게 조회 가능하다. 오래된 데이터를 기반으로 하므로 최신성이 부족하다.
Online Features: 최신 데이터를 기반으로 추출된 피처. Real-Time Features(예측 시 실시간으로 계산). Near Real-Time Features(사전 계산되며, 최신 데이터를 주기적으로 반영)
Real-Time Features
예측 요청이 생성되는 즉시 계산된다. 최신 데이터 반영, 지연 시간 내에서 결과를 제공한다.
항상 신선한 데이터를 기반으로 예측한다.
확장성 문제(트래픽 증가와 변동성에 따라 계산 지연이 사용자 경험에 영향을 줄 수 있다.)
복잡한 피처는 계산 시간이 길어져 지원하기 어려울 수 있다.
Near Real-Time Features(Streaming Features)
예측 요청 이전에 비동기로 계산된 피처 사용. 최신 값 조회 시 계산 지연이 없으며 복잡한 피처도 지원이 가능하다. 데이터의 신선도가 몇 초 단위로 업데이트된다.
예측 요청 시 빠른 조회 가능하다. 방문하지 않는 사용자를 위한 계산은 수행되지 않아 리소스 낭비를 방지한다.
완전한 실시간 데이터는 아니다.
사용 기술: Flink SQL, KSQL, Spark Streaming 등 스트리밍 처리 엔진
Stage2의 기업이 스트리밍 처리를 거의 사용하지 않았다면, Stage3의 기업은 스트리밍의 이점을 훨씬 더 많아질 수 있다.
예를 들어, DoorDash 사용자가 주문을 넣은 후 배달 시간을 추정하려면 다음과 같은 피처가 필요할 수 있다.
배치 피처: 이 레스토랑의 과거 평균 준비 시간
실시간 피처: 레스토랑 위치와 배달 위치 간의 거리
스트리밍 피처: 현재 레스토랑에 접수된 다른 주문 수, 앞으로 30분 동안 사용 가능한 배달원 수
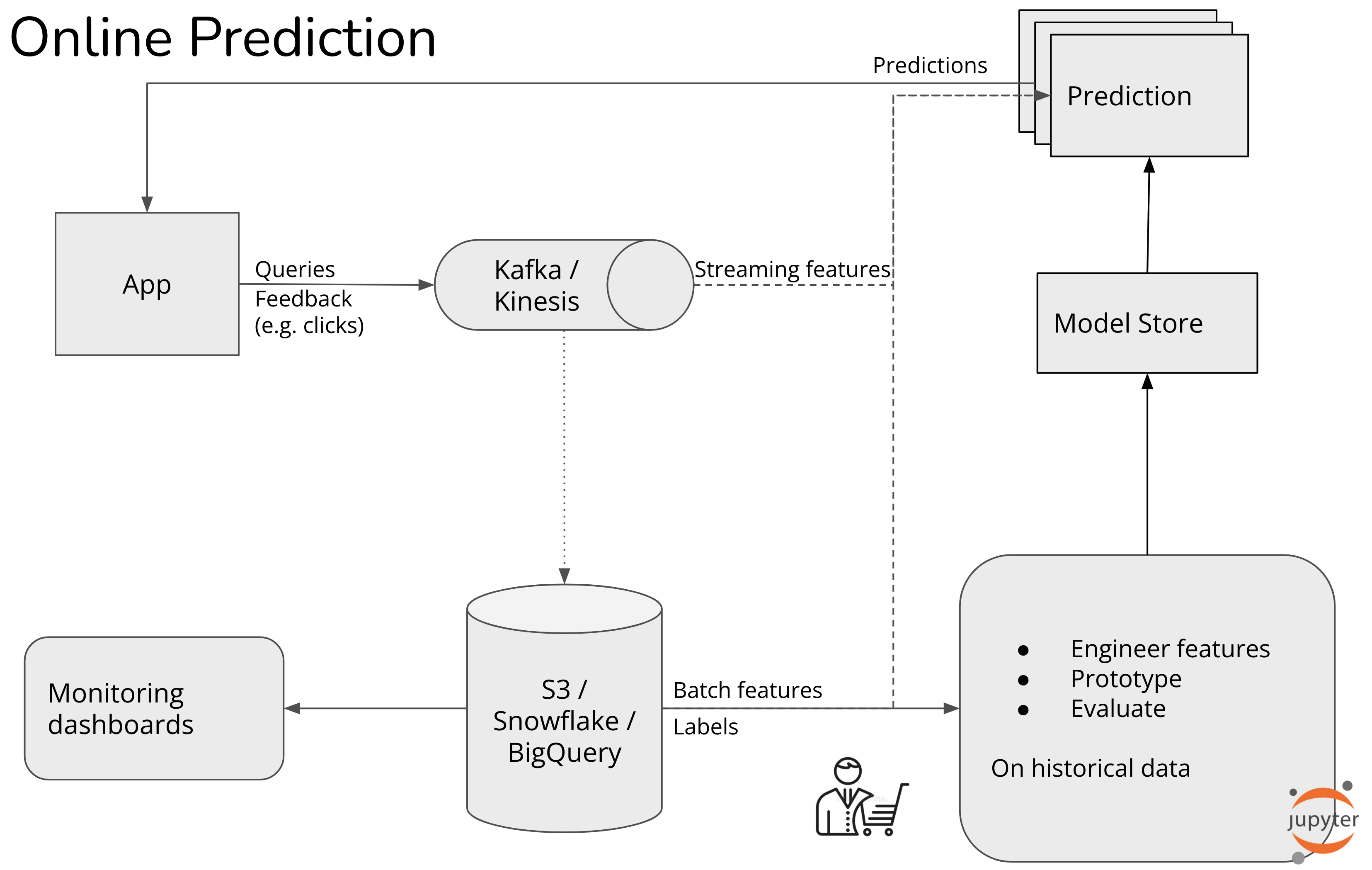
Stripe, Uber, Faire와 같은 기업들이 이 단계에 있으며, 주요 사용 사례는 다음과 같다.
사기 탐지, 신용평가, 운전 및 배달 추정, 추천 시스템
Discussion: Online prediction for bandits and contextual bandits
온라인 예측은 모델이 더 정확한 예측을 할 수 있도록 할 뿐만 아니라, 밴딧 알고리즘을 활용한 온라인 모델 평가를 가능하게 한다.
밴딧 알고리즘은 도박에서 유래되었다. 카지노에는 서로 다른 보상을 주는 여러 슬롯 머신이있다. 슬롯 머신은 "one-armed bandit"으로도 알려져 있으며, 여기서 밴딧이라는 이름이 유래되었다.
슬롯 머신 중 어느 것이 가장 높은 보상을 주는지 알지 못할 때, 실험을 통해 시간이 지나면서 최적의 슬롯 머신을 찾는 동시에 보상을 극대화하려고 합니다.
"multi-armed bandit"은 과거에서 가장 높은 보상을 준 슬롯 머신을 선택하는 활용(exploitation)과 더 높은 보상을 줄 가능성이 있는 다른 슬롯 머신을 선택하는 탐색(exploration) 간의 균형을 맞출 수 있도록 하는 알고리즘이다.
Bandits for model evaluation
현재 업계 표준 온라인 모델 평가 방식은 A/B 테스트이다. A/B 테스트에서는 트래픽을 각 모델로 무작위로 라우팅하고, 실험 종료 시 어떤 모델이 더 나은 성능을 보였는지 측정한다. 상태 비저장(Stateless) 방식으로, 현재 모델의 성능에 대한 정보 없이 트래픽을 라우팅할 수 있다. 배치 예측에서도 A/B 테스트를 수행할 수 있다.
밴딧 알고리즘을 활용하면, 여러 모델을 평가할 때 각 모델을 슬롯 머신으로 간주하고, 보상을 알지 못하는 상태에서 트래픽을 어떻게 라우팅할지 결정하여 최적의 모델을 찾을 수 있다. 밴딧은 상태 저장(Stateful) 방식으로, 요청을 특정 모델에 라우팅하기 전에 모든 모델의 현재 성능을 계산해야한다.
효율성 측면에서 밴딧 알고리즘은 A/B 테스트보다 훨씬 데이터 효율적이라는 점이 학계에서 잘 연구되었다. 많은 경우 밴딧은 최적의 방법으로 간주된다.
데이터 요구량 측면에서도 밴딧은 최적의 모델을 결정하기 위해 더 적은 데이터를 요구하며, 동시에 더 나은 모델로 트래픽을 빠르게 라우팅함으로써 기회 비용을 줄인다.
Contextual bandits as an exploration strategy
모델 평가를 위한 밴딧은 각 모델의 보상을 결정하는데 사용되는 반면, Contextual 밴딧은 각 행동의 보상을 결정하는데 사용된다. 추천 시스템의 경우, 행동은 사용자에게 보여줄 아이템이고 보상은 사용자가 해당 아이템을 클릭할 확률이다.
Contextual 밴딧의 예시로는, 총 10,000개의 아이템이 있는 추천 시스템이 있다고 가정한다. 한 번에 사용자에게 10개의 아이템을 추천할 수 있다. 사용자는 이 10개의 아이템에 대해 클릭 또는 비클릭으로 피드백을 제공한다. 그러나 나머지 9,990개 아이템에 대한 피드백은 받을 수 없다.
사용자가 클릭할 가능성이 가장 높은 아이템만 계속 추천하면, 결국 인기있는 아이템만 계속 추천하게 되고 이로 인해 덜 인기 있는 아이템에 대한 피드백을 받을 기회를 영원히 잃게 된다.
따라서, Contextual 밴딧은 context를 활용하여 사용자가 좋아할만한 아이템을 추천하는 활용과 아직 잘 모르는 아이템을 추천하는 탐색을 균형있게 수행한다. 동시에 최적이 아닌 행동(suboptimal actions)의 비용을 최소화한다.
하지만 구현이 어려우며, 탐색 전략은 머신러닝 모델의 아키텍처에 따라 달라지기 떄문에, 범용성이 낮다.
Towards Continual Learning
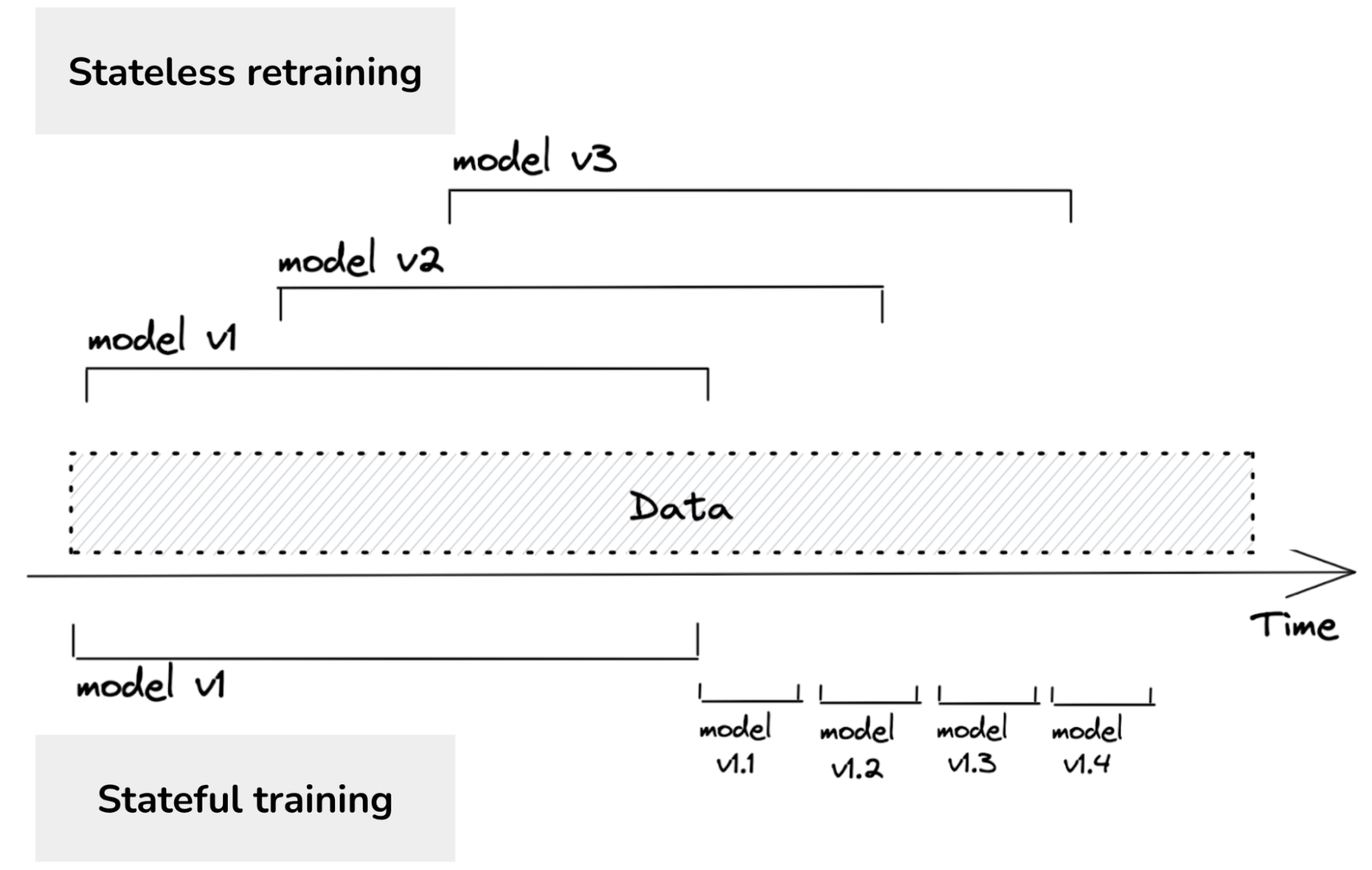
지속학습이라는 용어를 들으면 많은 사람들이 모델을 매우 자주 업데이트하는 것을 상상한다. 예를 들어 5분마다 업데이트를 실행하는 것을 떠올리곤 한다. 그러나 대부분의 사람들은 기업 대다수가 그렇게 빈번한 업데이트가 필요하지 않다고 주장한다. 그 이유는 그 정도의 재훈련 주기를 감당할 만큼의 트래픽이 없고 모델의 성능이 그렇게 빠르게 저하되지 않기 때문이다. 이 주장에 동의하지만, 지속학습은 재훈련 빈도가 아니라 모델이 재훈련되는 방식에 관한 것이다.
기존 방식: 대부분의 기업은 상태 비저장 재훈련을 수행한다. 즉, 모델을 매번 처음부터 다시 학습시킨다.
지속 학습: 상태 저장 재훈련을 하용한다. 즉, 모델이 새로운 데이터로 계속 학습(fine-tuning)을 진행한다.
지속 학습을 위한 인프라를 구축하면, 재훈련 빈도는 단순히 설정 가능한 매개변수(knob)가 된다. 한 시간에 한 번, 하루에 한 번 업데이트하거나 시스템이 데이터 분포의 변화를 감지할 때마다 모델을 업데이트할 수도 있다.
모델 업데이트의 두 가지 유형
모델 반복: 기존 모델 아키텍처에 새로운 피처를 추가하거나 모델 아키텍처 자체를 변경
데이터 반복: 동일한 모델 아키텍처와 피처를 유지하되, 새로운 데이터를 학습
현재 상태 저장학습은 데이터 반복을 의미힌다. 만약 모델 아키텍처를 변경하거나 새로운 피처를 추가한다면, 여전히 처음부터 모델을 다시 학습해야한다.
Stage1. Manual, Stateless Retraining
초기단계: 머신러닝 팀은 사기 탐지, 추천 시스템, 배달 시간 예측 등 가능한 많은 비즈니스 문제를 해결하기 위해 새로운 ML 모델 개발에 집중한다. 기존 모델 업데이트는 우선순위에서 밀려나고 모델이 너무 저조한 성능으로 오히려 부정적인 영향을 미칠 때나 팀이 업데이트 작업을 수행할 시간이 있을 때에만 이루어진다.
모델 업데이트는 수동으로 이루어지며, 임시적(ad-hoc)으로 수행된다.
대부분의 비기술 산업 분야 기업은 이 단계에 머물러있다.
Stage2. Automated Retraining
모델 재훈련이 수동 및 임시 방식에서 스크립트를 통한 자동화로 전환된다. 일반적으로 배치 처리를 통해 이루어지며, Spark와 같은 도구를 사용한다.
Stage 3. Automated, Stateful Training
Stateful Training은 모델을 처음부터 재훈련하지 않고, 새로운 데이터로 기존 모델을 계속 학습(fine-tuning)하는 방식이다.
데이터와 리소스를 효율적으로 활용하면서도 모델의 성능 유지할 수 있다. 하지만 과거 데이터의 영향을 잃을 위험이 있기 때문에 정기적으로 과거 데이터를 포함한 더 큰 데이터로 모델 품징을 검증하거나 재훈련할 필요가 있다.
Stage 4. Continual Learning
지속 학습은 고정된 일정에 따라 모델을 업데이트하는 대신, 데이터 분포의 변화가 발생하거나 모델 성능이 저하되었을 때 즉시 모델을 업데이트하는 방식을 지향한다.
지속학습의 궁극적인 목표는 Edge Deployment와 결합하는 것이다. 이는 모델이 환경에 지속적으로 적응하며, 데이터 프라이버스를 강화하고 비용을 절감하며, 실시간으로 성능을 최적화할 수 있는 새로운 시대를 열 수 있다.
