기존의 LLM 학습 방법론1: The 3 Conventional Feature-Based and Finetuning Approaches
언어모델을 target task에 맞게 adapting하거나 finetuning하는 방법론.
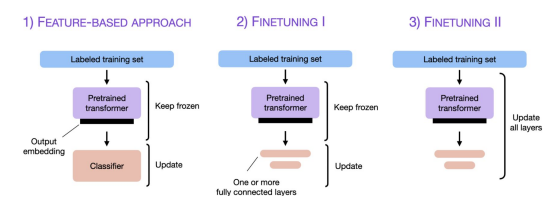
Finetuning Large Language Models
-
Feature-Based Approach
사전 학습된 LLM을 로드한 뒤, 대상 데이터셋에 적용하여 출력 임베딩을 생성한다. 이 임베딩은 이후 분류 모델의 입력 특징으로 사용된다.
BERT처럼 임베딩 중심 모델에서 주로 사용되며 미리 계산한 임베딩을 저장해 사용하기 때문에 실용적인 시나리오에서 편리하다. -
Finetuning1 - Updating The Output Layers
Feature-Based Approach와 유사하게, 사전 학습된 LLM의 매개변수를 Freeze한다. 대신, 모델의 새로 추가된 출력 레이어만 학습한다.
Feature-Based Approach와 모델 성능 및 학습 속도는 동일하지만, 사전 학습된 백본 모델은 고정되므로 효율적이다. -
Finetuning2 - Updating All Layers
사전 학습된 LLM의 모든 레이어를 업데이트하는 방식이다.
훨씬 더 높은 계산 비용을 요구하지만, 일반적으로 더 우수한 성능을 보인다.
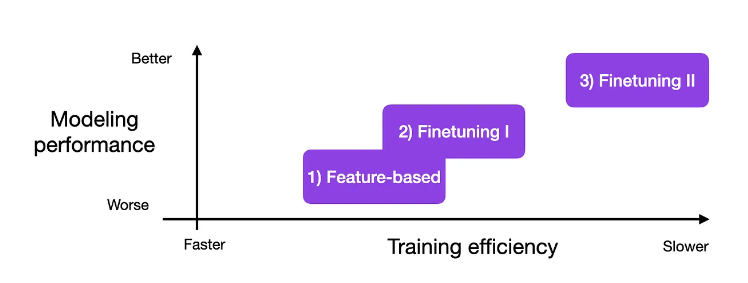
세 가지 방법을 성능(Y축)과 학습 효율(X축)로 나누어 살펴볼 때, 모든 파라미터를 학습하는 경우 가장 높은 성능을 기록하는 것을 확인할 수 있다.
기존의 LLM 학습 방법론2: In-Context Learning

Language Models are Few-Shot Learners
Target Task에 대해 몇 가지 예시를 모델에 입력해주면 모델을 튜닝하지 않고 쉽게 문제를 풀 수 있다. (few-shot prompting)
하지만, 한 논문에서는 정확한 레이블(ground truth)이 반드시 필요하지 않다는 것을 보여준다. 데모에서 레이블을 무작위로 대체해도 분류 및 다중 선택 작업에서 성능이 거의 떨어지지 않는다.
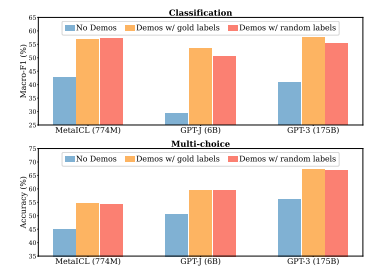
Rethinking the Role of Demonstrations:What Makes In-Context LearningWork?
PEFT
자연어처리의 중요한 패러다임 중 하나는 일반 도메인 데이터에 대한 대규모 사전 학습과 특정 task 또는 도메인에 대한 adaptation으로 구성된다. 더 큰 모델을 사전 학습할수록 모든 모델 매개변수를 다시 학습시키는 full fine-tuning은 점점 더 비현실적이 된다.
Parameter-Efficient Fine-Tuning은 파라미터 수가 많은 LLM을 효울적으로 학습할 수 있는 방법이다.
다음은 가장 대표적인 네가지 접근 방식이다.
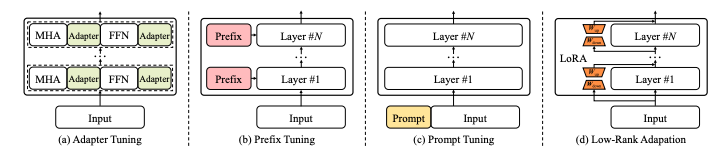
A Survey of Large Language Models
LoRA
Low-Rank Adaptation은 PEFT methods 중 가장 널리 쓰이는 방법론이다. 사전 학습된 모델의 가중치를 고정하고, 각 Transformer 아키텍처 레이어에 학습 가능한 저차원(rank decomposition) 행렬을 삽입하여 다운스트림 작업을 위한 학습해야 할 매개변수 수를 크게 줄인다.
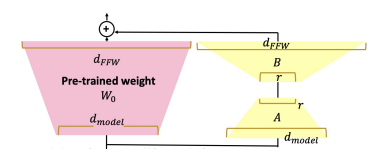
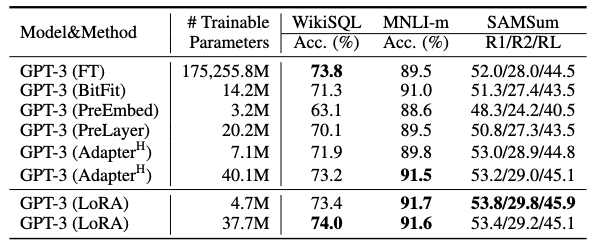
LoRA는 세 가지 데이터셋 모두에서 파인튜닝 기준 성능을 맞추거나 초과한다.
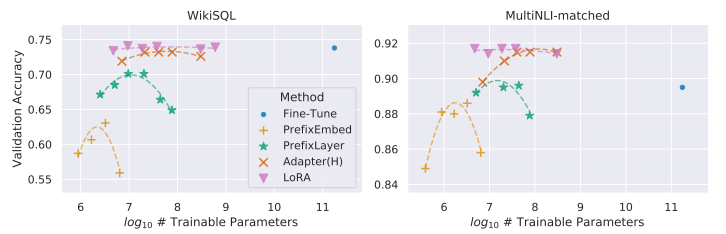
LoRA는 더 우수한 scalability와 task performance를 보여준다.
LoRA: Low-Rank Adaptation of Large Language Models
(IA)^3
