
네이버 지도 크롤링?
진행하는 프로젝트에서 데이터 수집을 위해 네이버 플레이스 방문자 리뷰를 스크래핑을 해야했다.
API가 아닌 selenium으로 스크래핑하기 위해 여러 가지를 고려하고 수많은 검색을 진행하여 스크래핑 코드를 완성하였다.
수집한 데이터
- 식당 이름
- 식당별 별점 (별점이 있는 경우만 수집)
- 영수증 리뷰 (키워드 리뷰가 아닌 방문자 텍스트 리뷰)
고려해야 했던 부분
네이버 지도 홈에서는 구동되지 않는 스크래핑
- 네이버 지도 링크만 가져오면 전혀 스크래핑이 되지 않아 url을 따로 추출해주어야 했다.
바뀌는 선택자
- 네이버는 셀렉터를 일정 기간이 지나면 바꿔버린다.
자주 바뀌는 ui
- ui를 바꿔버림에 따라 이전에 다른 분들이 네이버 지도 스크래핑에 사용한 코드는 사용할 수 없었다.
장소, 연도마다 다른 것 같은 셀렉터
- 식당이 바뀌면 동일한 셀렉터와 코드임에도 작동되지 않아서 범용적인 코드를 찾거나 그 식당에 맞게 코드를 바꿔주어야 했다.
- 리뷰 작성 연도가 다른 경우 셀렉터가 아예 달라져 리뷰 작성 날짜를 수집하는 것은 포기했다.
셀렉터를 찾지 못한 경우 멈추는 코드
- 내가 찾고자 하는 셀렉터가 존재하지 않는 경우 코드가 그대로 에러를 내고 멈춰버려 이에 대한 예외 처리를 진행해주어야 했다.
전체 코드
주의사항
이 코드는 네이버 지도에서 식당 검색 후
- 검색 결과가 존재할 때 (네이버 지도에 등록된 식당만 가능)
- 유일하게 나오는 결과가 있을 때,
- 검색 결과가 매번 달라지지 않을 때,
- 방문자 텍스트 리뷰가 있을 때
만 구동된다.
이외의 결과가 있는 경우 코드 진행이 안될 가능성이 높으며,
네이버가 ui나 셀렉터를 바꾸는 경우 스크래핑이 진행되지 않을 가능성이 매우 높다.
앞서 언급했듯이 네이버는 ui와 셀렉터를 자주 바꾸며 페이지 링크도 바꾸므로 얼마 지나지 않아 이 코드가 작동되지 않을 확률이 매우 높다.
코드 셀렉터에 CSS, xpath, JSselector가 섞여있다.
CSS를 선호했으나 먹히지 않는 경우 xpath로 바꿔주거나 최후의 경우 JS를 이용했다.
더 간편하게 쓰는 방법이 있을 것으로 생각된다.
import pandas as pd
import openpyxl
import os
import sys
import time
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from pyparsing import col
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from tqdm import tqdm
import re
# 식당 데이터 임포트
name_data = pd.read_csv('마포구.csv', encoding='utf-8-sig')
print(name_data)
#지역명이 포함된 식당명을 변수로 지정
items = name_data['name']
print(items)
#검색할 식당 데이터와 url을 담을 데이터 프레임 생성
df = pd.DataFrame(columns=['name', 'naverURL'])
#데이터 프레임이 잘 만들어졌는지 확인
df['name'] = items
df
# 식당 url 얻기
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
res = driver.page_source # 페이지 소스 가져오기
soup = BeautifulSoup(res, 'html.parser') # html 파싱하여 가져온다
# frame 변경 메소드
def switch_frame(frame):
driver.switch_to.default_content() # frame 초기화
driver.switch_to.frame(frame) # frame 변경
res
soup
for i, keyword in enumerate(df['name'].tolist()):
# 검색 url 만들기
naver_map_search_url = f'https://map.naver.com/v5/search/{keyword}/place'
# 검색 url 접속 = 검색하기
driver.get(naver_map_search_url)
time.sleep(2)
# 검색 프레임 변경
driver.switch_to.frame("searchIframe")
time.sleep(1)
try:
#식당 정보가 있다면 첫번째 식당의 url을 가져오기
if len(driver.find_elements(By.XPATH, '//*[@id="_pcmap_list_scroll_container"]/ul/li')) != 0:
#식당 정보 클릭
driver.execute_script('return document.querySelector("#_pcmap_list_scroll_container > ul > li:nth-child(1) > div.ouxiq > a:nth-child(1) > div").click()')
time.sleep(2)
# 검색한 플레이스의 개별 페이지 저장
tmp = driver.current_url
res_code = re.findall(r"place/(\d+)", tmp)
final_url = 'https://pcmap.place.naver.com/restaurant/'+res_code[0]+'/review/visitor#'
print(final_url)
df['naverURL'][i]=final_url
except:
df['naverURL'][i]= ''
print('none')
driver.close()
#식당명과 url이 잘 얻어져왔는지 확인하기
print(df)
#url을 얻어오지 못한 식당 확인
print(df.loc[df['naverURL']==''])
#결측치로 입력된 식당 확인
print(df.loc[df['naverURL'].isna()])
## 식당 리뷰 url이 들어가있지 않은 경우 직접 검색하여 데이터에 넣어주기!!! ##
# csv 파일로도 저장하여 url이 빈 값이 있는지 반드시 확인할 것 !
#url이 없으면 코드 실행이 중단되므로 반드시 url 데이터를 확인할 것!!
df.to_csv('마포구url.csv', encoding='utf-8-sig')
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.maximize_window()
count = 0 #
current = 0 #현재 진행 상황
goal = len(df['name']) #총 식당 수
#데이터 프레임으로 만들 빈 리스트 생성
rev_list=[]
for i in range(len(df)):
current += 1
print('진행상황 : ', current,'/',goal,sep="")
# 식당 리뷰 개별 url 접속
driver.get(df['naverURL'][i])
thisurl = df['naverURL'][i]
time.sleep(2)
print('현재 수집중인 식당 : ', df['name'][i])
#리뷰 더보기 버튼 누르기
while True:
try:
driver.find_element(By.CSS_SELECTOR, '#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.lcndr > div.lfH3O > a')
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
time.sleep(1)
driver.execute_script('return document.querySelector("#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.lcndr > div.lfH3O > a").click()')
time.sleep(2)
except NoSuchElementException:
print("-모든 리뷰 더보기 완료-")
break
#식당 평균 별점 수집
try:
rating = driver.find_element(By.CSS_SELECTOR, '#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.no_margin.mdJ86 > div.place_section_content > div > div.Xj_yJ > span.m7jAR.ohonc > em').text
print('식당 평균 별점 : ', rating)
rev_list.append(
[df['name'][i],
rating
]
)
except:
pass
#리뷰 데이터 스크래핑을 위한 html 파싱
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
try:
#키워드 리뷰가 아닌 리뷰글 리스트 검색
review_lists = soup.select('#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.lcndr > div.place_section_content > ul > li')
print('총 리뷰 수 : ', len(review_lists))
#리뷰 수가 0이 아닌 경우 리뷰 수집
if len(review_lists) > 0 :
for j, review in enumerate(review_lists):
try:
#내용 더보기가 있는 경우 내용 더보기를 눌러주기
try:
review.find(' div.ZZ4OK > a > span.rvCSr > svg')
more_content = review.select(' div.ZZ4OK > a > span.rvCSr > svg')
more_content.click()
time.sleep(1)
#리뷰 정보
user_review = review.select(' div.ZZ4OK > a > span')
#리뷰 정보가 있는 경우 식당 이름, 평점, 리뷰 텍스트, 작성 시간을 가져와서 데이터 프레임으로 만들기
if len(user_review) > 0:
rev_list.append(
[
df['name'][i],
'',
user_review[0].text
]
)
time.sleep(1)
except:
#리뷰 정보
user_review = review.select(' div.ZZ4OK.IwhtZ > a > span')
#리뷰 정보가 있는 경우 식당 이름, 평점, 리뷰 텍스트, 작성 시간을 가져와서 데이터 프레임으로 만들기
if len(user_review) > 0:
rev_list.append(
[
df['name'][i],
'',
user_review[0].text
]
)
time.sleep(1)
except NoSuchElementException:
print('리뷰 텍스트가 인식되지 않음')
continue
else:
print('리뷰 선택자가 인식되지 않음')
time.sleep(1)
# 리뷰가 없는 경우
except NoSuchElementException:
rev_list.append(
[
df['name'][i],
rating,
]
)
time.sleep(2)
print("리뷰가 존재하지 않음")
#검색한 창 닫고 검색 페이지로 돌아가기
# driver.close()
# driver.switch_to.window(tabs[0])
print("기본 페이지로 돌아가기")
driver.close()
#스크래핑한 데이터를 데이터 프레임으로 만들기
column = ["name", 'rate', "review"]
df2 = pd.DataFrame(rev_list, columns=column)
df2 코드 설명
식당명 데이터 임포트 및 url을 얻을 데이터프레임 생성
# 식당 데이터 임포트
name_data = pd.read_csv('마포구.csv', encoding='utf-8-sig') #한국어이므로 인코딩을 설정해주었음
print(name_data)
#지역명이 포함된 식당명을 변수로 지정
items = name_data['name']
print(items)
#검색할 식당 데이터와 url을 담을 데이터 프레임 생성
df = pd.DataFrame(columns=['name', 'naverURL'])
#데이터 프레임이 잘 만들어졌는지 확인
df['name'] = items
df네이버 지도에 검색하고자 하는 식당명 데이터가 있어야 가능하다.
이 코드는 방문자 리뷰 탭이 있는 페이지를 따로 추출하여 스크래핑을 진행하므로, 식당명과 추출 url을 담을 데이터 프레임이 사전에 생성되어야 한다.
방문자 리뷰 URL 추출
# 식당 url 얻기
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
res = driver.page_source # 페이지 소스 가져오기
soup = BeautifulSoup(res, 'html.parser') # html 파싱하여 가져온다
# frame 변경 메소드
def switch_frame(frame):
driver.switch_to.default_content() # frame 초기화
driver.switch_to.frame(frame) # frame 변경
res
soup
for i, keyword in enumerate(df['name'].tolist()):
# 검색 url 만들기
naver_map_search_url = f'https://map.naver.com/v5/search/{keyword}/place'
# 검색 url 접속 = 검색하기
driver.get(naver_map_search_url)
time.sleep(2)
# 검색 프레임 변경
driver.switch_to.frame("searchIframe")
time.sleep(1)
try:
#식당 정보가 있다면 첫번째 식당의 url을 가져오기
if len(driver.find_elements(By.XPATH, '//*[@id="_pcmap_list_scroll_container"]/ul/li')) != 0:
#식당 정보 클릭
driver.execute_script('return document.querySelector("#_pcmap_list_scroll_container > ul > li:nth-child(1) > div.ouxiq > a:nth-child(1) > div").click()')
time.sleep(2)
# 검색한 플레이스의 개별 페이지 저장
tmp = driver.current_url
res_code = re.findall(r"place/(\d+)", tmp)
final_url = 'https://pcmap.place.naver.com/restaurant/'+res_code[0]+'/review/visitor#'
print(final_url)
df['naverURL'][i]=final_url
except:
df['naverURL'][i]= ''
print('none')
driver.close()네이버 지도에 바로 검색해서 방문자 리뷰 탭을 누르고 리뷰를 스크래핑하는 것은 불가능했다.
이에 다른 분께서 올려주신 코드를 참고하여 네이버 지도의 리뷰 탭 페이지를 식당별로 추출했다.
가져오지 못한 식당 리뷰 url 수정, 추가
#url을 얻어오지 못한 식당 확인
print(df.loc[df['naverURL']==''])
#결측치로 입력된 식당 확인
print(df.loc[df['naverURL'].isna()])
## 식당 리뷰 url이 들어가있지 않은 경우 직접 검색하여 데이터에 넣어주기!!! ##
#필요한 경우 검색이 되지 않거나 식당 이름이 이상한 경우 바꿔주기#
#식당 삭제 코드
df = df.drop(index=df.loc[df.name == '마포 밤샷'].index)
#식당 이름 변경 코드
df.loc[39, 'name']=='마포 연남토마'
# url을 얻어오지 못한 식당의 리뷰 url 추가 #
#네이버지도에 식당 검색 후 뜨는 map.naver.com/place/고유번호
#고유번호를 'https://pcmap.place.naver.com/restaurant/고유번호/review/visitor# 형식으로 추가해줄 것
#url을 추가해야할 인덱스 번호는 위 코드에서 확인 가능
#df['naverURL'][인덱스 번호]='https://pcmap.place.naver.com/restaurant/고유번호/review/visitor#' 형식
# url을 얻어오지 못한 식당의 url 추가
df['naverURL'][1]='https://pcmap.place.naver.com/restaurant/1609583532/review/visitor#'
#인덱스 리셋
df=df.reset_index()
#데이터 확인
print(df.loc[df['naverURL']==''])
print(df.loc[df['name'].isna()])
# csv 파일로도 저장하여 url이 빈 값이 있는지 반드시 확인할 것 !
#url이 없으면 코드 실행이 중단되므로 반드시 url 데이터를 확인할 것!!
df.to_csv('마포구url.csv', encoding='utf-8-sig')생각보다 추출이 제대로 되지 않는 경우가 많아 추출된 url 데이터의 결측치를 확인하고
- 네이버 지도에 등록된 식당이 맞는지
- 식당명이 정확한지
- 업체가 폐업하여 정보가 없는것인지
- 등록은 되어있으나 url 정보를 가져오지 못한 것인지
확인하여 url 데이터를 수정하였다.
데이터를 확인하였음에도 결측치가 존재하는 경우가 있어 csv로 저장 후 추출된 url 데이터를 다시 살펴보았다.
네이버 지도 리뷰 정보 스크래핑
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.maximize_window()
count = 0 #
current = 0 #현재 진행 상황
goal = len(df['name']) #총 식당 수
#데이터 프레임으로 만들 빈 리스트 생성
rev_list=[]
for i in range(len(df)):
current += 1
print('진행상황 : ', current,'/',goal,sep="")
# 식당 리뷰 개별 url 접속
driver.get(df['naverURL'][i])
thisurl = df['naverURL'][i]
time.sleep(2)
print('현재 수집중인 식당 : ', df['name'][i])
#리뷰 더보기 버튼 누르기
while True:
try:
driver.find_element(By.CSS_SELECTOR, '#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.lcndr > div.lfH3O > a')
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
time.sleep(1)
driver.execute_script('return document.querySelector("#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.lcndr > div.lfH3O > a").click()')
time.sleep(2)
except NoSuchElementException:
print("-모든 리뷰 더보기 완료-")
break
#식당 평균 별점 수집
try:
rating = driver.find_element(By.CSS_SELECTOR, '#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.no_margin.mdJ86 > div.place_section_content > div > div.Xj_yJ > span.m7jAR.ohonc > em').text
print('식당 평균 별점 : ', rating)
rev_list.append(
[df['name'][i],
rating
]
)
except:
pass
셀레니움을 이용하기 위해 크롬 드라이버를 세팅하고 접속할 url을 인풋 데이터로 지정했다.
현재 진행중인 상황을 알아보기 위해 현재까지 스크래핑된 식당 수는 몇개인지, 현재 스크래핑 진행중인 식당은 무엇인지, 리뷰 더보기 버튼을 계속 눌렀는지 출력하도록 코드를 작성했다.
현재 수집중인 식당에 별점이 있다면 별점 정보를 수집하고, 별점이 없다면 넘어가도록 작성하였다.
#리뷰 데이터 스크래핑을 위한 html 파싱
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
try:
#키워드 리뷰가 아닌 리뷰글 리스트 검색
review_lists = soup.select('#app-root > div > div > div > div:nth-child(7) > div:nth-child(2) > div.place_section.lcndr > div.place_section_content > ul > li')
print('총 리뷰 수 : ', len(review_lists))
#리뷰 수가 0이 아닌 경우 리뷰 수집
if len(review_lists) > 0 :
for j, review in enumerate(review_lists):
try:
#내용 더보기가 있는 경우 내용 더보기를 눌러주기
try:
review.find(' div.ZZ4OK > a > span.rvCSr > svg')
more_content = review.select(' div.ZZ4OK > a > span.rvCSr > svg')
more_content.click()
time.sleep(1)
#리뷰 정보
user_review = review.select(' div.ZZ4OK > a > span')
#리뷰 정보가 있는 경우 식당 이름, 평점, 리뷰 텍스트, 작성 시간을 가져와서 데이터 프레임으로 만들기
if len(user_review) > 0:
rev_list.append(
[
df['name'][i],
'',
user_review[0].text
]
)
time.sleep(1)
except:
#리뷰 정보
user_review = review.select(' div.ZZ4OK.IwhtZ > a > span')
#리뷰 정보가 있는 경우 식당 이름, 평점, 리뷰 텍스트, 작성 시간을 가져와서 데이터 프레임으로 만들기
if len(user_review) > 0:
rev_list.append(
[
df['name'][i],
'',
user_review[0].text
]
)
time.sleep(1)
except NoSuchElementException:
print('리뷰 텍스트가 인식되지 않음')
continue
else:
print('리뷰 선택자가 인식되지 않음')
time.sleep(1)
# 리뷰가 없는 경우
except NoSuchElementException:
rev_list.append(
[
df['name'][i],
rating,
]
)
time.sleep(2)
print("리뷰가 존재하지 않음")
#검색한 창 닫고 검색 페이지로 돌아가기
# driver.close()
# driver.switch_to.window(tabs[0])
print("기본 페이지로 돌아가기")
driver.close()방문자 리뷰중 키워드 리뷰가 아닌 텍스트가 존재하는 리뷰만 수집하도록 셀렉터를 조정하였다.
리뷰 더보기를 다 누른 후에 인식된 총 리뷰 수는 몇 개인지 출력하고 리뷰를 인식하지 못했거나 셀렉터가 제대로 인식되지 않은 경우 에러 메세지를 출력하도록 작성하였다.
리뷰에서 내용 더보기(토글 버튼 : >)이 있는 경우 토글을 누르고 그 다음에 리뷰 정보를 스크래핑하고, 토글이 없는 경우 그대로 내용을 스크래핑했다.
리뷰에 사진만 있어 텍스트가 존재하지 않는 경우 넘어가도록 예외 처리를 진행했다.
수집된 리뷰 텍스트는 리스트 안에 저장했다.
스크래핑한 데이터를 데이터 프레임으로 생성
#스크래핑한 데이터를 데이터 프레임으로 만들기
column = ["name", 'rate', "review"]
df2 = pd.DataFrame(rev_list, columns=column)
df2 스크래핑이 정상적으로 되었는지 확인 후 스크래핑한 리뷰 데이터를 데이터 프레임으로 만들었다.
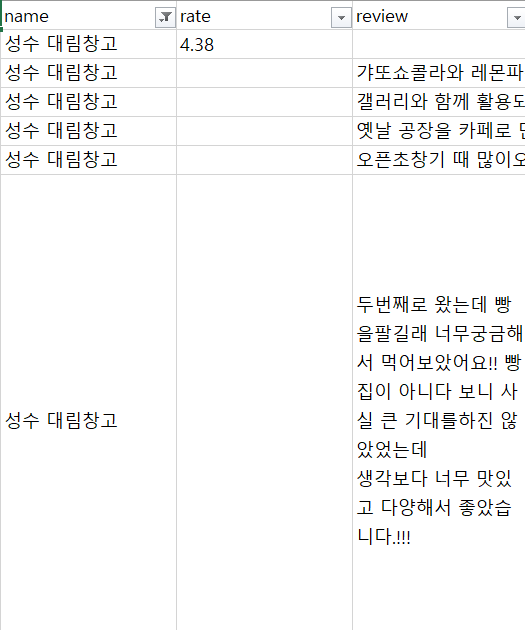
출력 데이터 예시
참고 링크
[Python/Crawling] 네이버 플레이스(네이버 지도) 리뷰 크롤링
네이버 맵 크롤링 (selenium,bs4,re) - 키워드 리뷰

안되는거 같은데...어떻게 수정해야하나요?