NLP
1.자연어처리 task

NLP 주요학회( ACL, EMNLP, NAACL ) low level parsing tokenization - 단어단위로 쪼갬 stemming - 어근추출 word and phrase(구문) level Named entity recognition(NER) - 단
2022년 3월 7일
2.Bag of Words
bag of word - 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법 단어사전 구축 “John really really loves this movie“, “Jane really likes this song” {“John“, “really“, “loves“, “this“, “movie“, “Jan...
2022년 3월 7일
3.word embedding
https://wikidocs.net/33520 word embedding = 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환 중심단어의 주위의 단어를 예측하도록 학습한다 https://ronxin.github.io/wevi/
2022년 3월 7일
4.vanilla RNN
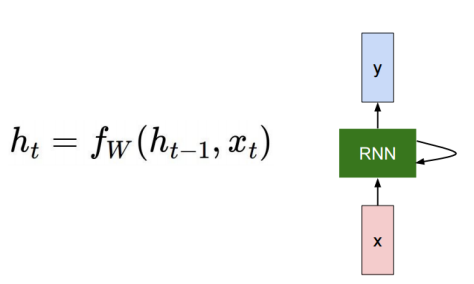
이전의 h벡터를 입력에 사용한다
2022년 3월 17일
5.LSTM
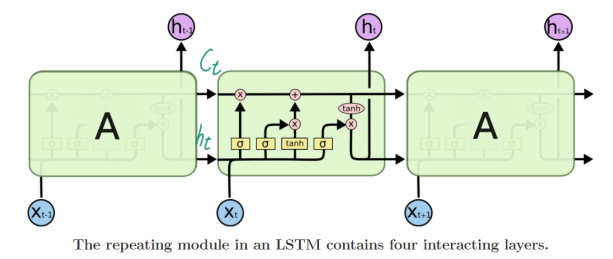
cell state로 이전단계의 정보의 소실이나 변형을 줄임
2022년 3월 17일