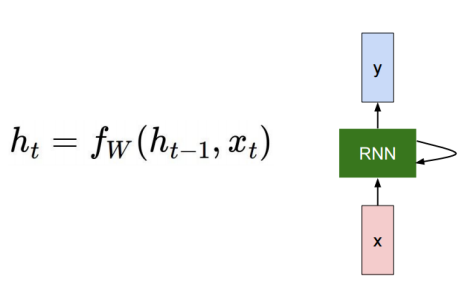
RNN
이전의 h벡터를 입력에 사용한다
 출처 : http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
출처 : http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
와 를 현재 time step의 입력으로 사용한다
y의 경우 task마다 다르다
- 품사 tagging일 경우 매 input(time step) 마다 결과가 나와야한다
- 긍 부정 일 경우 마지막 time step에서만 예측
RNN은 매 time step마다 같은 파라미터를 공유한다
- 매번 output의 shape이 같다
RNN 연산
forward
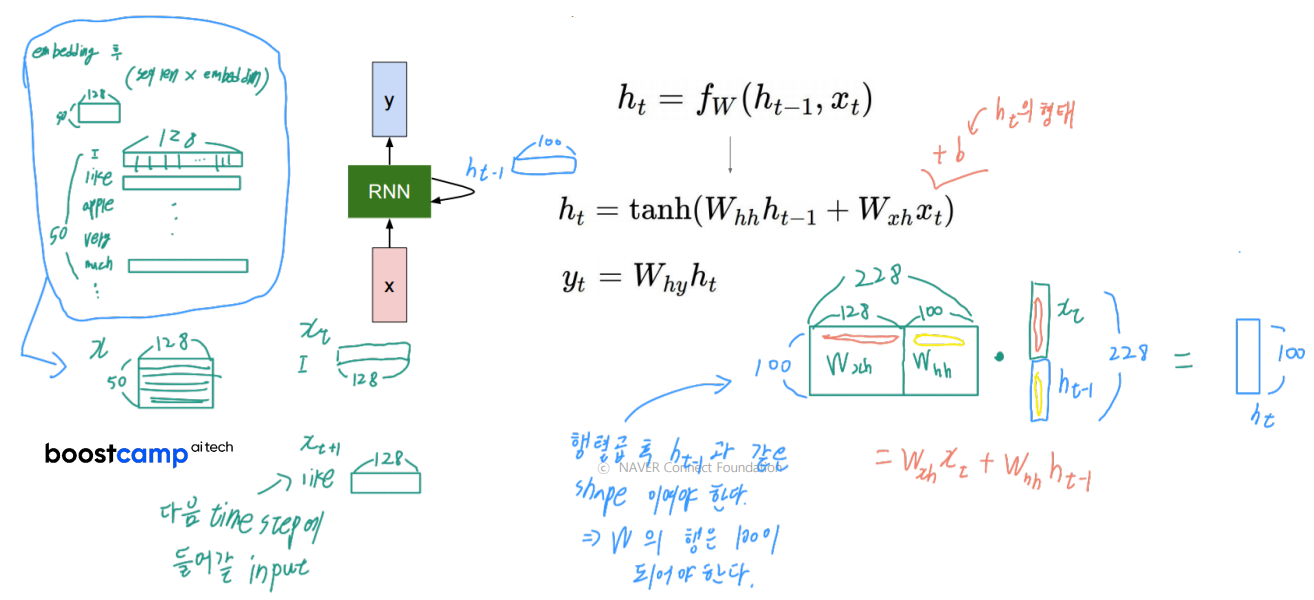
자연어를 임베딩한 후의 벡터가 RNN의 입력으로 들어온다고 가정해보겠다
50 128(seq len embedded dim)의 입력 데이터는 매 time step마다 한 행씩 들어온다.
(step1: I -> step2: like -> step3: apple -> step4: very ....)
매 time step에 들어오는 는 (1 128) 차원이다
이전 time step의 도 현재 time step의 를 구할때 사용된다.
이 h벡터들의 차원은 하이퍼파라미터로 우리가 지정해주는 값으로 정해진다.
예시로 100 이라고 해보자 -> 의 shape : (1 100)
로 현재 time step의 h벡터가 구해진다.
연산은 그림과 같은 형태로 수행된다. 와 를 concat 하고 와 를 concat하여 행렬곱을 수행한다.
위 행렬곱 연산을 잘 보면 의 내적과 의 내적은 각각 독립적으로 수행한 결과를 더해주는 것 과 차이가 없다.
결과적으로 의 형태는 이다
이 h벡터들 이나 마지막 h벡터를 사용해서 logit인 y를 출력한다.
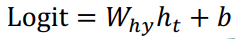
backpropagate
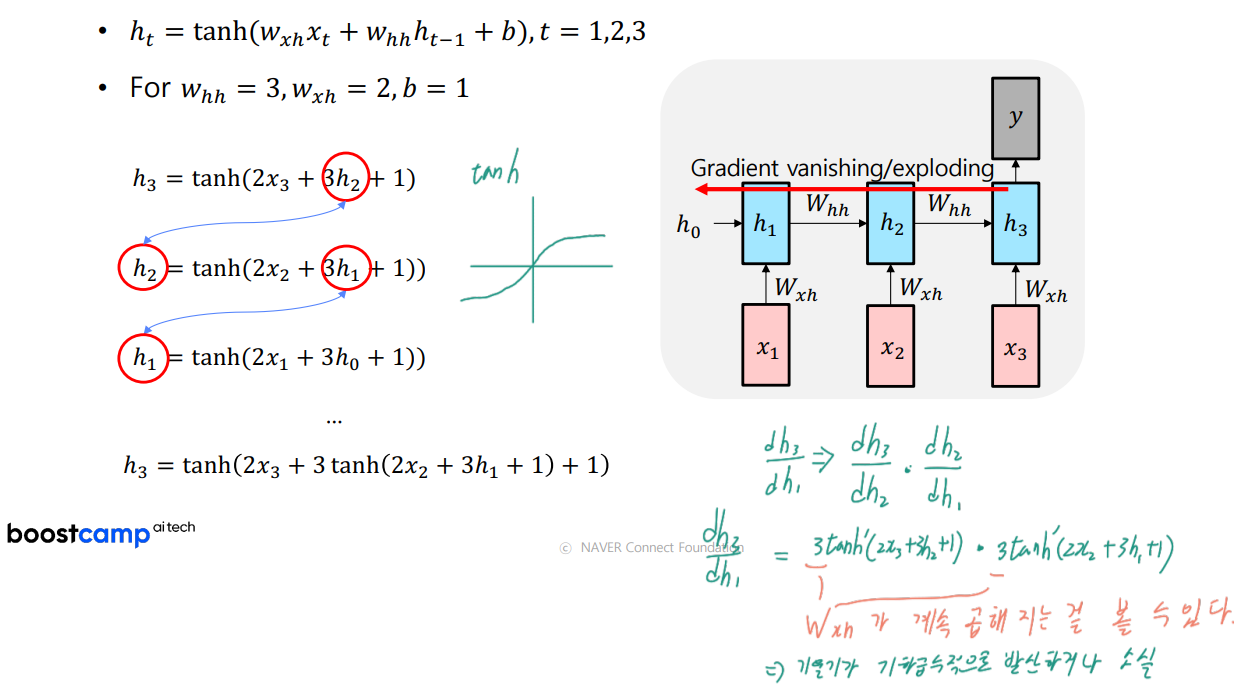
rnn의 backpropagation은 BBTT(Backpropagation through time) 이라고 한다.
time step을 거슬러 올라가면서 편미분을 수행한다.
계산 과정을 보면 가중치인 W들이 계속 곱해지는 것을 볼 수 있는데 이로인해 기울기가 기하급수적으로 발산하거나 소실된다.
LSTM(Long Short Term Memory) 이 문제를 완화 시켜준다.
